Zustand-хранилища vs машины состояний для экранов рабочих процессов
Zustand-stores и машины состояний подходят для разных задач в UI рабочих процессов. Смотрите на количество правил, повторных попыток и путей ошибок, чтобы выбрать более простой вариант.
Содержание
Почему этот выбор быстро становится запутанным
Большинство экранов рабочих процессов сначала не кажутся сложными. У вас есть форма, кнопка отправки, состояние загрузки и один ответ от сервера. Простой стор выглядит вполне нормально.
Потом правила начинают накапливаться. Product добавляет повторные попытки. Support просит ручной обходной путь. Бэкенд возвращает "try again later" вместо аккуратного успеха или ошибки. Кто-то просит отмену, обработку таймаута и предупреждение, если пользователь уходит на полпути.
Вот здесь вопрос «store или machine» перестаёт быть спором о стиле и становится задачей моделирования. Проблема не в состоянии как таковом. Проблема в том, сколько правил управляет этим состоянием и сколько веток ошибок расходится от основного потока.
Store позволяет легко добавить один флаг, потом ещё один. Вскоре у вас есть isLoading, isRetrying, hasTimedOut, canCancel, showError и несколько вычисляемых проверок, разбросанных по компонентам. Код по-прежнему работает, но он уже не показывает, какие комбинации действительно допустимы. И это важно.
Пропустите одно состояние — и UI начинает вести себя странно. Экран может показать устаревший успех после неудачной повторной попытки. Кнопка cancel может остаться активной уже после завершения запроса. Баннер ошибки может дожить до следующей попытки, потому что никто не сбросил одно поле в нужный момент.
Пользователи не называют это «проблемами моделирования состояния». Они говорят, что экран странный. Они нажимают один раз, а ничего не происходит. Видят не то сообщение. Обновляют страницу, потому что не доверяют тому, что видят.
Команды обычно реагируют заплатками в сторе. Добавляют ещё одно условие, ещё один reset, ещё одно небольшое исправление в компоненте. На неделю это помогает. Но поток почти никогда не становится понятнее.
Хорошо это видно на примере экрана возврата денег. Сначала там три исхода: pending, approved, rejected. Потом добавляются загрузка документа, ожидание проверки, таймаут, повтор после сетевой ошибки и отмена во время загрузки. Исходный стор всё ещё справляется с простым путём, поэтому беспорядок и подкрадывается к командам незаметно. Сломанные части живут в ветках, которые никто не описал ясно.
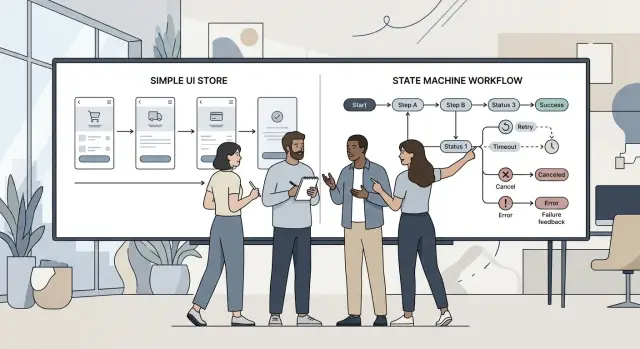
Что хорошо делает простой стор
Обычный Zustand-store отлично подходит, когда на экране всего несколько движущихся частей. Если пользователь заполняет небольшую форму, нажимает save и видит либо успех, либо одну понятную ошибку, машина состояний обычно не нужна. Логика остаётся читаемой, и один разработчик может изменить её, не распутывая длинную цепочку событий.
Модальное окно редактирования профиля — хороший пример. Вы можете хранить name, email, isOpen, isSaving и saveError в одном сторе, плюс действия вроде updateField и saveProfile. Это легко понять и быстро собрать.
Краткоживущие UI-флаги тоже хорошо подходят под эту модель. Панель открыта или закрыта. Запрос загружается или завершён. Тост виден или скрыт. Когда эти флаги почти не влияют друг на друга, стор выглядит естественно, потому что каждая часть состояния делает одну работу.
Небольшие локальные правки тоже сюда относятся. Подумайте о странице настроек, где пользователь переключает тумблер, выбирает вкладку или правит черновую заметку перед уходом со страницы. Если такие правки не распадаются на множество веток, стор держит код рядом с UI вместо того, чтобы превращать его в схему.
Типичные примеры: панель фильтров поиска с несколькими контролами, модалка с одной кнопкой отправки, шаг оформления заказа с базовой валидацией полей или виджет дашборда с состояниями загрузки и обновления.
Скорость тоже важна. Если экраном владеет один человек, стор позволяет за минуты настроить состояние, проверить очевидные случаи и двигаться дальше. На раннем этапе продукта такой компромисс часто нужен.
Правило очень простое. Если вы можете объяснить состояние экрана на стикере, стор, скорее всего, подходит. Когда для того, чтобы понять, что может произойти дальше, уже нужна доска, простые сторы начинают проигрывать.
Что добавляют машины состояний
Машина состояний начинается с более строгой идеи: экран может находиться только в одном из небольшого числа именованных состояний. Вместо того чтобы жонглировать булевыми значениями isLoading, hasError, canRetry и isLocked, вы сначала перечисляете состояния: editing, submitting, waiting for review, failed, canceled, done.
Это звучит дотошно. Но как только поток становится длиннее нескольких простых шагов, это сильно уменьшает путаницу.
Названия важны, потому что разные люди читают один и тот же экран по-разному. Дизайнер думает о том, что видит пользователь. Инженер — о событиях и побочных эффектах. Продакт-менеджер — о правилах. Машина даёт им одну общую карту. Когда кто-то спрашивает: «Что будет, если пользователь закроет модалку после неудачной отправки и вернётся позже?», команда может показать текущее состояние и разрешённый следующий шаг вместо того, чтобы гадать.
Следующее преимущество — более жёсткое движение. В сторе почти любая часть приложения может записать почти любое значение, если команда не держит строгую дисциплину. Машина состояний сужает это пространство. Поток идёт через явные переходы вроде submit, fail, retry, cancel или timeout. Если экран никогда не должен прыгать из "draft" сразу в "approved", машина блокирует такой прыжок по умолчанию.
Именно здесь начинают исчезать невозможные состояния. Вы перестаёте видеть комбинации вроде loading = true, error = true и success = true одновременно. Перестаёте чинить странные баги дополнительными флагами. Модель сама несёт правило: сейчас одно состояние, и отсюда доступен один разрешённый следующий шаг.
Для управления состоянием UI рабочих процессов это особенно важно, когда ветки ошибок множатся. Happy path легко удержать в голове. Добавьте повторные попытки, частичные сохранения, истёкшие токены, двойные клики и отмену пользователем — и обычный стор начинает казаться скользким.
Команды часто сразу замечают одно преимущество: ревью кода становится проще. Логика читается больше как карта и меньше как куча обновлений. Машины состояний не лучше для каждого экрана. Но им проще доверять, когда у потока много правил и несколько способов пойти не так.
Как выбрать с помощью количества правил и веток ошибок
Начинайте с самого flow, а не с инструмента. Опишите путь пользователя простыми шагами от первого экрана до финального подтверждения. Если путь выглядит как короткий чек-лист, стор обычно подходит. Если на бумаге он уже похож на дерево решений, стоит насторожиться.
Потом посчитайте правила на каждом шаге. Правило — это всё, что меняет, что пользователь может делать или видеть: возрастные ограничения, недостающие документы, просроченные коды, заблокированные аккаунты, лимиты запросов, ручная проверка или проверки по стране. Одно-два правила на шаг обычно ещё можно спокойно держать в простом сторе. Но когда несколько шагов подряд несут по четыре-пять правил, логика начинает расползаться по флагам, эффектам и условиям.
Затем выпишите все ветки ошибок, а не только happy path. Команды часто недооценивают, сколько сложности скрыто в retry, cancel, timeout, partial save, refresh и поведении кнопки назад. Поток с одним сообщением об ошибке всё ещё прост. Поток, где пользователь может ошибаться разными способами и восстанавливаться разными способами, — это уже место, где машина начинает иметь смысл.
Полезен быстрый тест:
- Перечислите каждый шаг по порядку.
- Запишите правила, привязанные к этому шагу.
- Добавьте все ветки fail, retry, cancel и timeout.
- Отметьте состояния, которые не могут существовать одновременно.
- Посчитайте, сколько веток потом снова сходятся.
Четвёртый пункт важнее, чем многие ожидают. Если ваш UI может быть одновременно "submitting" и "editable", или "verified" и "needs more documents" из-за гонки двух async-запросов, модель уже слабая. Машина состояний заставляет вас прямо сказать, какие состояния валидны, а какие невозможны.
Представьте пятишаговую проверку аккаунта. Пользователь вводит данные, загружает ID, ждёт проверки, получает результат, а потом либо завершает процесс, либо повторяет его. Если проверка может истекать по таймауту, загрузка может падать, пользователь может отменить действие, support может запросить ещё файлы, а для некоторых стран нужен дополнительный контроль, то стор всё ещё может хранить данные. Но он уже с трудом объясняет допустимые переходы.
Вот практическая граница. Используйте стор, когда поток короткий, правила локальные, а ошибки редкие. Используйте машину, когда ветки множатся, появляются недопустимые комбинации, а пути восстановления важны не меньше основного пути.
Реальный пример: поток проверки аккаунта
Экран проверки аккаунта на первый день выглядит просто. Пользователь вводит email, получает код, вводит его и выбирает запасной вариант, если письмо не приходит. Большинство команд начинают с небольшого Zustand-store, и это разумный выбор.
В сторе могут лежать поля вроде email, code, step, attemptsLeft, resendAt и error. Сначала вы просто переключаетесь между несколькими экранами: введите email, введите код, подтверждено.
Потом появляются реальные правила. Бэкенд может отправлять код несколько секунд. Пользователь может попросить повторную отправку. Код может истекать через 10 минут. Слишком много неудачных попыток может заблокировать процесс. Запасной вариант, например второй email или ручная проверка support, может позже снова открыть flow.
Вот тут обычный стор начинает выглядеть неуклюже. Команды добавляют флаги вроде isSending, isWaiting, canResend, isExpired, isLocked, needsReview и reviewReopened. Сами по себе эти флаги не ошибочны. Проблема в том, что они начинают накладываться друг на друга.
Экран может оказаться в таких состояниях:
- таймер повторной отправки доходит до нуля уже после того, как попытка заблокирована
- support снова открывает кейс, но старый timeout всё ещё помечает код как просроченный
- UI показывает баннер ошибки и шаг успеха одновременно
- запасной вариант появляется ещё до того, как первая попытка отправки действительно провалилась
Машина состояний обрабатывает тот же поток чище, потому что держит состояния отдельно. "Waiting for code" — это не то же самое, что "expired". "Locked" — не то же самое, что "under review". "Reopened" — это свежее состояние со своими правилами, а не просто ещё один булев флаг в куче.
С машиной экран проходит через именованные состояния вроде sending, waiting, resend ready, expired, locked, under review, reopened и verified. У каждого события есть понятный результат. Timeout не может тихо жить рядом с success. Кнопка resend не останется активной внутри заблокированного flow, если вы не разрешили это специально.
Вот почему управление состоянием UI рабочих процессов оказывается сложнее, чем кажется сначала. Если flow может ждать, ломаться, повторяться, истекать и позже открываться снова, стор часто превращается в мешок флагов. Машина даёт этим веткам ошибок форму, которую можно понять.
Признаки, что вашему Zustand-store уже тесно
Простой Zustand-store обычно начинается аккуратно. Вы храните несколько полей, добавляете пару actions, и экран легко читать. Потом workflow растёт. Появляется повторная попытка, один шаг может истекать, другой можно пропустить, и стор начинает собирать маленькие исправления.
Один из первых тревожных сигналов — разрастание булевых флагов. Вы добавляете isLoading, потом isRetrying, потом hasError, потом needsReview, потом ещё один флаг, чтобы закрыть сломанную пограничную ситуацию. Через какое-то время экран может быть "loading", "failed" и "ready" в комбинациях, которые не имеют смысла. Тесты обычно ловят это раньше людей, потому что смешанные состояния создают странные экраны: спиннер остаётся включённым, пока показывается баннер ошибки, или кнопка next разблокируется ещё до завершения проверки.
Ещё один признак — повторная проверка одних и тех же правил. Если несколько обработчиков спрашивают одно и то же — "код истёк?", "пользователь уже отправил?", "можно ли уже повторить?" — значит правила больше не живут в одном понятном месте. Они расползаются по обработчикам кликов, эффектам, API-callback и компонентным защитам. Маленькие правки начинают казаться рискованными, потому что одна пропущенная проверка создаёт ветку, которую никто не ожидал.
Команды обычно чувствуют следующий симптом раньше, чем могут его назвать: людям становится страшно трогать flow. Разработчик меняет одну ветку и переживает за четыре других. Ревью замедляется. Никто уже не уверен, какие состояния валидны.
Стор, вероятно, уже слишком тесный, если вы видите флаги, которые нужны только для блокировки невозможных комбинаций, actions, которые сбрасывают три-четыре несвязанных поля, одни и те же бизнес-правила, скопированные в несколько обработчиков, баг-репорты со словами «иногда» или «только после возврата назад», а также тесты, которые проходят на лёгких путях, но падают на повторных попытках, таймаутах или частичном успехе.
Простое правило помогает. Если ваш стор в основном описывает данные, Zustand часто достаточно. Если стор ещё должен описывать разрешённые переходы, запрещённые переходы и пути ошибок, вы уже близко к точке, где машина — более удачный выбор.
Ошибки, которые допускают команды
Команды часто выбирают не тот инструмент, потому что судят об экране по тому, как он начинается, а не по тому, как он ломается. Двухшаговой форме с одной кнопкой отправки машина не нужна. Небольшого Zustand-store обычно хватает, когда пользователь может идти вперёд, возвращаться назад и видеть одну-две ошибки.
Обратная ошибка не менее распространена. Команда начинает с простого стора, а потом продолжает латать его, когда правила расползаются по нескольким экранам. Вскоре один флаг управляет другим флагом, одно действие сбрасывает три поля, и никто уже не может сказать, какие состояния допустимы. Обычно именно в этот момент стор перестал быть простым, даже если код по-прежнему выглядит коротким.
Много путаницы начинается, когда правила workflow живут внутри component effects. Один экран делает redirect, если запрос падает. Другой заново открывает модалку после retry. Третий очищает локальное состояние, когда пользователь отменяет действие. Каждый эффект по отдельности имеет смысл. Вместе они образуют скрытый workflow, а скрытые workflow трудно отлаживать.
Одна пропущенная вещь создаёт больше проблем, чем ожидают команды: они никогда не рисуют ветки retry и cancel. Они описывают happy path, а потом дополняют остальное уже во время разработки. Именно там и появляются баги. Пользователи повторяют действие после таймаута. Закрывают вкладку и возвращаются. Отменяют на полпути, а потом начинают заново, но старые данные всё ещё висят в состоянии.
Помогает быстрый чек. Посчитайте, сколько бизнес-правил определяют следующее UI-состояние, сколько веток ошибок требуют отдельной реакции, сколько экранов могут менять один и тот же workflow и как часто пользователь может повторить, отменить, поставить на паузу или продолжить процесс.
Если эти числа остаются маленькими, стор подходит. Если они растут, машина обычно даёт более чёткие границы и меньше сюрпризов.
Ещё одна частая ошибка — смешивать server state и state потока как будто это одно и то же. Результаты запросов, свежесть кэша и статус запроса относятся к инструментам для server state. А вещи вроде "user is waiting for code", "user can retry in 30 seconds" или "verification is locked after three failures" относятся к самому workflow. Когда команды смешивают это в одном сторе, UI начинает реагировать на сетевые детали вместо бизнес-правил.
Оставляйте Zustand для локального состояния приложения, когда оно остаётся простым. Переходите к машине, когда команде нужна явная карта того, что может произойти дальше, особенно если пути ошибок важны не меньше happy path.
Быстрые проверки перед тем, как писать код
Большинство плохих решений о состоянии принимаются ещё до того, как кто-то напишет код. Инструмент редко бывает первой проблемой. Главная проблема в том, что команда ещё не сделала workflow достаточно понятным, чтобы увидеть, где он может сломаться.
Начинайте с бумаги или доски. Если вы не можете нарисовать весь flow на одной странице, включая happy path и неприятные части, сбавьте темп. Обычно это значит, что правила ещё расплывчаты, а расплывчатые правила превращаются в беспорядочные сторы, беспорядочные машины или в то и другое сразу.
Несколько проверок упрощают выбор:
- Посчитайте, сколько бизнес-правил меняют то, что пользователь может сделать дальше.
- Отметьте каждую точку, где одно действие может привести к двум и более исходам.
- Запишите, что происходит после ошибки: retry, rollback, wait или manual review.
- Попросите коллегу прочитать flow и пересказать его вам через неделю.
Последняя проверка важнее, чем кажется. Если другой разработчик не сможет понять правила в следующем месяце, вашему будущему «я» этот код тоже не понравится. Небольшой Zustand-store может оставаться чистым, когда изменения состояния прямые и легко отслеживаются. Как только действия начинают ветвиться в нескольких направлениях, скрытые предположения накапливаются очень быстро.
Ошибки — сильный сигнал. Логин-форма с одним сообщением об ошибке — это просто. Поток проверки аккаунта с лимитами на повторную отправку, просроченными токенами, fraud-проверками и ручной проверкой — уже нет. Когда у ошибок есть собственные пути, а не только собственные сообщения, машина состояний часто даёт более чёткие границы.
То же самое относится к действиям, которые могут вести к разным следующим состояниям. Если нажатие "Submit" всегда приводит к одному известному результату, стор может быть достаточен. Если "Submit" может привести к успеху, ожиданию проверки, частичному успеху, блокировке или повторной попытке, вы уже описываете машину, даже если сами её не используете.
Если после этого упражнения flow всё ещё кажется туманным, не пишите код сразу. Сначала пересмотрите workflow, уточните правила и уберите догадки.
Что делать дальше
Начинайте с бумаги. Карта flow говорит больше, чем новый файл в кодовой базе. Нарисуйте состояния, в которые может войти пользователь, события, которые двигают его дальше, и все места, где он может застрять, повторить действие, подождать или выйти по таймауту.
Это упражнение обычно делает выбор намного яснее. В небольшом потоке стор кажется естественным, потому что состояние — это в основном данные плюс несколько UI-флагов. Как только на карте появляются случаи отказа, cooldown, ручная проверка, частичный успех и шаги восстановления, проблема перестаёт быть вопросом хранения и становится вопросом управления.
Практичный способ принять решение простой: посчитайте разные бизнес-правила, отдельно посчитайте пути ошибок и восстановления, отметьте таймеры, polling, retries и внешние callbacks, а также обведите любые комбинации состояний, которых не должно существовать.
Если у вашей команды это постоянно всплывает на product-heavy экранах, может помочь внешний взгляд до того, как код станет слишком тяжело распутывать. Oleg Sotnikov на oleg.is делает именно такую работу в формате Fractional CTO и product architecture, особенно для команд, которые приводят в порядок запутанные workflow и переходят к более ясным процессам разработки с поддержкой ИИ.
Если вы набросали flow проверки аккаунта, и ветвление уже выглядит перегруженным на бумаге, вот и ответ. Workflow просит более строгих правил, а не ещё одного флага.
Часто задаваемые вопросы
Когда обычного Zustand-стора достаточно?
Используйте Zustand, когда у экрана короткий путь, немного полей и один понятный результат отправки. Модальное окно формы, небольшой блок настроек или простой flow сохранения обычно подходят хорошо, потому что состояние в основном хранит данные и пару UI-флагов.
Когда стоит использовать машину состояний?
Переходите на машину состояний, когда правила и пути ошибок начинают управлять экраном сильнее, чем сами данные. Если в flow есть повторные попытки, таймауты, отмена, ручная проверка, повторное открытие или заблокированные состояния, машина даёт именованные состояния и понятные переходы между ними.
Можно ли использовать Zustand и машину состояний вместе?
Да, это часто хороший вариант. Храните локальные данные формы или общие данные приложения в Zustand, а машиной управляйте состояниями workflow вроде editing, submitting, failed или done.
Какие признаки показывают, что стор уже становится запутанным?
Следите за разрастанием булевых флагов. Если вы постоянно добавляете isLoading, isRetrying, isExpired и needsReview, стор начинает скрывать невозможные комбинации вместо того, чтобы не допускать их.
Меняют ли retry и timeout выбор инструмента?
Обычно да. Путь повторной попытки означает, что пользователь может выйти из happy path и вернуться позже. Таймауты, cooldown и действия отмены добавляют новые ветки, и именно они чаще всего ломают простые сторы на флагах.
Не слишком ли машины состояний сложны для маленьких форм?
Да, для небольших экранов они часто избыточны. Если пользователь заполняет форму, отправляет её один раз и видит успех или одну ошибку, машина может добавить структуру, которая пока не нужна. Начинайте просто, пока правила остаются простыми.
Как понять это до написания кода?
Сначала запишите flow на бумаге. Посчитайте шаги, затем бизнес-правила и все ветки fail, retry, cancel, timeout и resume. Если схема уже похожа на дерево решений, выбирайте машину.
Какие баги помогают предотвратить машины состояний?
Они убирают невозможные состояния экрана. Вы не увидите одновременно success и error, не оставите кнопку cancel активной после завершения запроса и не забудете старый timeout-флаг после повторной попытки.
Что не стоит помещать в мой workflow-store?
Не смешивайте server state и workflow state в одну кучу. Статус запроса, свежесть кэша и полученные данные относятся к инструментам для server state, а состояния вроде waiting for code или locked after three tries — к модели workflow.
Можно ли начать с Zustand, а потом перейти на машину состояний?
Можно, и это часто удобно. Переходить лучше до того, как стор превратится в набор заплаток. Миграция проходит легче, когда вы уже понимаете реальные состояния, события и заблокированные переходы. Сначала опишите их, потом переносите логику flow шаг за шагом.


