Затраты холодного старта serverless в продуктах с пиковым трафиком
Затраты холодного старта в serverless могут вредить пользовательским потокам при всплесках трафика. Узнайте, что измерять перед переносом запросов в функции.
Содержание
Что идёт не так с холодными стартами при всплесках трафика
Холодный старт происходит, когда провайдер облака должен «разбудить» функцию до того, как она сможет обработать запрос. Если готового тёплого экземпляра нет, платформа загружает ваш код, запускает рантайм, подтягивает секреты, открывает сетевые соединения и только затем выполняет задачу. Эта дополнительная работа может добавить короткую паузу или длинную задержку.
При ровном трафике вы вряд ли заметите проблему. Всплески трафика делают её очевидной. Начинается распродажа, приходит письмo-кампания или мобильное приложение шлёт уведомление. Много запросов попадает одновременно, но готовых тёплых экземпляров немного. Платформа создаёт новые, и каждый новый экземпляр добавляет время старта.
Пользователи замечают эту задержку в тех местах, где они ожидают мгновенной реакции. Вход — частая проблема. Человек вводит код, ждёт, а затем снова нажимает, потому что экран кажется зависшим. Оформление заказа ещё менее терпимое: пауза в пару секунд прямо перед оплатой заставляет пользователей думать, обновить страницу или уйти. Поиск страдает быстро, потому что каждый медленный запрос делает продукт вялым.
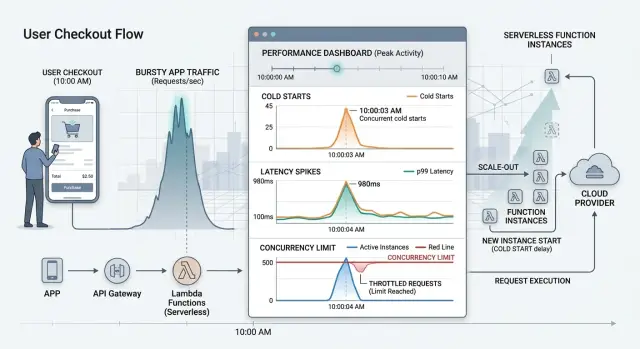
Холодный старт — лишь часть проблемы. Всплеск трафика часто вызывает сразу несколько маленьких ожиданий. Функция должна запуститься, база данных принять новые подключения, секреты и конфигурация загрузиться, а другой сервис может начать троттлить запросы. Ограничения конкурентности платформы усугубляют проблему. Функция, которая выглядит нормально в одиночном тесте, может сильно тормозить, когда одновременно приходит пятьдесят или пятьсот пользователей.
В какой-то момент это перестаёт быть инженерной побочной заметкой и становится продуктовой проблемой. Платите вы платите не только за вычисления: это брошенные корзины, повторные клики, обращения в поддержку и утраченный доверие.
Переводить пользовательский поток на функции всё ещё имеет смысл, но средние значения вас введут в заблуждение. Измерьте сценарий всплеска сначала, смотрите на самые медленные запросы и тестируйте полный путь вокруг функции. Мигрируйте только после того, как цифры будут безопасны.
Важные метрики перед тестированием
Задержка — это время, которое человек ждёт после нажатия, клика или отправки. Если страница отвечает за ~200 мс, это кажется мгновенным. Если это 3 секунды, пользователи начинают сомневаться, работает ли что-то. В serverless-потоке ожидание может включать время холодного старта, сетевую передачу, ваш код и любые вызовы баз данных или API.
Среднее время ответа полезно, но может вас обмануть. Поток может иметь среднее 400 мс и при этом ощущаться медленным, если небольшая доля запросов занимает 4–5 секунд. Такие медленные запросы обычно проявляются при всплесках — именно тогда задержки старта становятся заметны.
Пара метрик важнее среднего:
- типичное время ответа при обычном трафике
- p95 и p99 задержки
- худшая задержка во время короткого всплеска
- уровень ошибок во время всплеска
Это даёт гораздо яснее картину, чем одно среднее число.
Конкурентность проще, чем кажется — это просто перекрытие запросов во времени. Если 300 человек попадают на один и тот же endpoint за несколько секунд, система не обрабатывает их по одному аккуратно в очереди. Многие приходят одновременно, и платформе, возможно, придётся стартовать множество экземпляров сразу. Именно здесь всплески создают проблемы.
Нужно отделять лимиты платформы от лимитов приложения. Лимиты платформы задаёт серверless-провайдер: он может ограничивать скорость старта новых экземпляров, количество одновременных инстансов или ресурсы на экземпляр. У приложения есть свои пределы: база данных может принимать ограниченное количество соединений, сторонний API троттлит вызовы, служба аутентификации может замедлиться задолго до того, как платформа начнёт троттлить.
Поток входа хорошо это иллюстрирует. Сама функция может стартовать меньше чем за секунду, но весь запрос всё равно задержится, если десятки новых экземпляров одновременно открывают соединения с базой. Измеряя только время выполнения функции, вы пропускаете ту часть задержки, которую чувствует пользователь.
Тестируйте весь путь, а не только функцию. Именно там живёт реальная задержка.
Где холодные старты бьют сильнее всего
Пользователи сильнее всего ощущают холодные старты в действиях, где они ожидают мгновенного ответа. Пауза в 2–3 секунды кажется сломанной, когда человек пытается войти, оплатить, выполнить поиск или открыть дашборд.
Эти потоки оцениваются по первому изменению на экране. Если первая функция просыпается медленно, весь продукт кажется медленным, даже если остальная часть стека в порядке.
Самые рискованные места: вход и обновление сессии, подтверждение оплаты и оформление заказа, поисковые запросы, отправка форм с ожидаемым быстрым сообщением об успехе и API-вызовы, которые строят первую страницу после входа.
Фоновые задачи — другое дело. Если отчёт генерируется 20 секунд в фоне, большинство пользователей примет это, если приложение показывает прогресс и надёжно завершает задачу. Если та же задержка появляется после нажатия кнопки без обратной связи, люди уходят или нажимают снова.
Ретраи усугубляют проблему. Медленная пользовательская функция может вызвать повторные попытки со стороны клиента, шлюза или апстрима. Это превращает один холодный старт в всплеск, создаёт больше холодных стартов и повышает конкурентность в самый худший момент.
Одна медленная стадия может задержать всё, что идёт за ней. Представьте оформление заказа, где первая функция загружает правила ценообразования, затем вызывает налоговый сервис, проверяет склад и создаёт платёжную сессию. Если первый шаг стартует холодно, все последующие вызовы стартуют позже, и пользователь ждёт всю цепочку.
То же самое происходит при регистрации. Запрос на новый аккаунт может создать запись пользователя, отправить код, начать профиль и записать событие аудита. Если первая функция тормозит, пользователь видит спиннер, нажимает снова, и теперь у вас дубликаты запросов, которые мешают друг другу.
Поэтому холодные старты важны там, где пользователь взаимодействует вживую, а не в тихой фоновой работе. Измеряйте шаги, которые чувствует пользователь, особенно первый, и учитывайте ретраи как часть реальной задержки.
Как пошагово измерить влияние холодных стартов
Используйте один реальный пользовательский сценарий, а не общий тестовый endpoint. Выберите путь, где задержку легко почувствовать: вход, оформление заказа, загрузка файла или генерация отчёта. Задержка старта важна только тогда, когда она замедляет то, чего реально ждёт пользователь.
Установите бюджет задержки до запуска тестов. Решите, сколько дополнительной задержки поток может выдержать, прежде чем казаться сломанным. Например, письмо для сброса пароля может терпеть лишнюю секунду, а страница подтверждения оплаты обычно — нет.
Затем тестируйте поток так, чтобы он соответствовал реальным всплескам:
- Определите точные начало и конец пути, который будете измерять.
- Установите общий бюджет задержки и определите, сколько из него может занять функция.
- Создайте всплеск трафика, похожий на реальность, например 40 запросов за 10 секунд после простоя.
- Записывайте холодные и тёплые прогоны отдельно.
- Отслеживайте p95, p99, уровень ошибок и конкурентность во время всплеска.
Держите данные по холодным и тёплым прогонaм раздельно. Если их смешать, среднее будет лучше, чем реальный опыт. Тёплый прогон может завершаться за 150 мс, а холодный — за 1.6 с. Среднее скроет всплеск, но человек всё равно его почувствует.
Смотрите на хвост распределения, а не только на медиану. P95 и p99 покажут, получает ли малый, но болезненный кусок пользователей ожидание из‑за старта, очередей или троттлинга. Уровень ошибок тоже важен — некоторые платформы сначала падают, прежде чем явно затормозить.
Прогоняйте тесты несколько раз. Тихие часы, пиковые периоды и времена рядом с плановыми заданиями дают разные результаты. Если у вас всплесковый трафик, одного чистого теста в полдень недостаточно.
Простой пример делает это осязаемым. Допустим, flash-sale отправляет 200 человек на оформление заказа после 15 минут простоя. Протестируйте именно такую схему. Если холодные запросы толкают p99 оформления заказа с 700 мс до 2.5 с, у вас есть реальный риск для пользователей, даже если тёплые запросы в порядке.
Хорошие измерения скучны — и в этом их преимущество. Чёткие бюджеты, реалистичные всплески и раздельные холодные и тёплые результаты дают надёжные числа.
Скрытые лимиты, которые меняют результат
Тест холодного старта может выглядеть хорошо в отрыве и всё равно провалиться в продакшне. Функция может стартовать быстро, но другой лимит задержит ответ до того, как пользователь что‑то увидит.
Первый лимит — квоты аккаунта или региона. Многие команды тестируют одну функцию с десятью запросами, получают приемлемые числа и думают, что всё в порядке. Пока не приходит настоящий всплеск, когда масштабируются несколько функций и платформа начинает троттлить новую работу.
Настройки таймаута и памяти меняют результат больше, чем ожидают. Низкая память часто означает медленнее CPU, и старт занимает дольше. Таймаут, который кажется щедрым при тёплом прогонах, может оказаться слишком коротким, когда функция должна загрузиться, подтянуть секреты и открыть соединения.
Часто потолком становятся внешние сервисы. Функция может масштабироваться до сотен одновременных вызовов, а вот база, очередь, сервис аутентификации или сторонний API — нет. Эта разница превращает небольшую задержку в сломанный вход, оформление заказа или поиск.
Пулы соединений — распространённая ловушка. Если каждый новый экземпляр открывает свежие соединения с базой во время всплеска, база может тратить время на отказы, а не на ответы. Лёгкие тесты это пропускают, потому что проблема проявляется только при одновременном старте многих холодных экземпляров.
Пересчитайте стартовую работу по шагам. Большие импорты, инициализация SDK, парсинг конфигурации, загрузка секретов и сетевые вызовы до запуска обработчика — всё это добавляет задержку. Функция, которая в лаборатории делает 400 мс стартапа, под нагрузкой может тратить гораздо больше, если замедлятся хранилища секретов, DNS или общие сервисы.
Быстрый ревью обычно ловит главные риски. Проверьте общий cap конкурентности, сравните время холодного старта с общим таймаутом запроса, измерьте, сколько новых соединений создаёт всплеск. Протестируйте базу, очередь и API под нагрузкой вместе с функцией. Обрежьте стартовый код до минимума на горячем пути.
Простой пример: flow для входа без пароля получает всплеск после рассылки. Функция масштабируется, но загрузка секретов добавляет задержку, auth API даёт rate limit, а база достигает лимита соединений. Пользователю всё равно, какой лимит упал — он видит просто зависший экран входа.
Простой пример с пользовательским потоком
Flash-sale оформление заказа — плохое место учиться на холодных стартах. Трафик тих для большей части дня, затем начинается акция и 2,000 человек попадают в один поток оформления за минуту. На бумаге serverless выглядит дешёво, потому что вы платите только при приходе запросов. На практике первая волна может быть настолько медленной, что это вредит продажам.
Представьте оформление, собранное как цепочка функций. Одна функция валидирует корзину, другая считает доставку и налоги, третья читает инвентарь из базы, четвёртая создаёт платёжную сессию с внешним API. Если у платформы мало тёплых инстансов, первые запросы ждут, пока новые воркеры стартуют.
Разница быстро проявляется в цифрах. Тёплый запрос может выполнить шаг корзины за 120 мс, получить инвентарь за 80 мс и получить ответ платежа за 300 мс. Полный путь ~700–900 мс. Холодный запрос может добавить 400 мс–1.5 с до начала реальной работы. Если два или три функции в одном пути стартуют холодно, клиент может ждать 2–4 секунды, прежде чем увидеть форму оплаты.
Поздние запросы выглядят гораздо лучше. Как только платформа развернёт достаточно воркеров, тот же поток стабилизируется около 800 мс. Поэтому средняя задержка скрывает проблему. Первые 50–100 покупателей получат худший опыт, чем все последующие.
Дизайн «только функции» увеличивает риск, потому что каждый шаг может стартовать самостоятельно. Также это добавляет сетевых переходов между шагами. Вызовы к базе и платёжному API остаются такими же, но промежутки между ними растут.
Смешанный подход обычно лучше для таких сценариев. Держите публичный endpoint оформления на небольшом всегда-готовом сервисе, а фоновые всплесковые задачи — в функциях. Сервис может держать тёплые подключения к базе, управлять сессией и вызывать платёжный API без задержки старта. Функции оставьте для fraud checks, отправки писем или экспорта заказов, которые идут после оплаты.
Такой разрыв стоит немного дороже в простое, но оформление заказа — одна из тех зон, где экономия за счёт неопределённости редко оправдана.
Ошибки, которые дают неверный результат
Большинство неверных тестов — результат идеальных лабораторных условий, которых не бывает в продакшне. Команды шлют пару запросов, смотрят среднее и считают дело закрытым. Это скрывает боль пользователей при всплесках.
Средняя задержка — первая ловушка. Поток может выглядеть нормально при 250 мс в среднем, в то время как худшие 5% занимают 2–4 секунды из‑за одновременного старта новых инстансов. Для реалистичной оценки смотрите p95 и p99, а не только mean.
Тестирование только тёплых функций — следующая ошибка. Если инструмент шлёт равномерный трафик десять минут, вы в основном меряете горячие функции. Рынок с пиковым трафиком наоборот: он сидит тихо, а затем получает всплеск от push-уведомления, рекламы, запланированной задачи или волны логинов после обеда.
Полезный тест должен включать «уродливые» условия: 15 минут простоя, затем 200 запросов за 30 секунд; несколько близких всплесков, чтобы конкурентность выросла; реалистичные размеры payload; и реальные вызовы аутентификации, базы, кеша и сторонних сервисов.
Внешние лимиты меняют результат больше, чем многие ожидают. Функция может стартовать быстро, но база может отказать новым соединениям, провайдер аутентификации — дать rate limit, или сторонний API — замедлиться при параллельных вызовах. Тогда люди винят холодные старты за задержки, которые на самом деле начинаются глубже.
Стартовый код — ещё одна слепая зона. Многие функции тратят большую часть холодного старта на собственный код: большие пакеты, медленная загрузка конфигурации, тяжёлая инициализация SDK и раннее открытие соединений добавляют сотни миллисекунд до запуска обработчика. Профилируйте старт отдельно от обработки запроса, иначе смешаете две проблемы в одном графике.
Последняя ошибка — переносить весь пользовательский поток сразу. Тогда трудно понять, какой шаг ломается при всплеске. Переносите одну границу сначала, например обработку изображений или генерацию PDF, и снова меряйте. Оставьте первый пользовательский шаг на предсказуемой платформе, если холодные старты портят вход, оформление заказа или поиск.
Небольшие изменения в дизайне теста могут перевернуть вывод. Если тест слишком чистый, скорее всего он таким и является.
Короткий чек-лист перед переносом потока
Функция может выглядеть дешёвой и быстрой в спокойном тесте, а затем развалиться при 200 запросах за пять секунд. Прежде чем переводить шаги регистрации, оформления или входа в функции, ответьте на несколько простых вопросов:
- Какой всплеск вы ожидаете в худший день, а не в среднем час?
- Как выглядят самые медленные запросы: p95, p99, таймауты и упавшие вызовы?
- Тестируете ли вы с реальными зависимостями, а не с тёплыми моками?
- Проверили ли вы квоты провайдера, пределы соединений и rate limits до начала теста?
- Сравнивали ли вы дизайн на функциях с небольшим контейнерным сервисом или гибридом?
Список намеренно короткий. Если хотя бы один ответ отсутствует, тест не закончено.
Простое правило: если человек ждёт на экране — тестируйте так, как будто человек ждёт на экране. Считывайте холодные старты, ретраи, задержки в очереди и все внешние вызовы по полному пути. Именно там всплесковый трафик обычно бьёт сильнее.
Вам не нужна огромная лаборатория. Нужен один реалистичный сценарий, один всплеск трафика, соответствующий спросу, и чёткие критерии «прошёл/не прошёл». Если поток по‑прежнему шаткий, держите горячий путь на контейнерах и переносите только асинхронную работу в функции.
Что делать дальше, если цифры рискованные
Если тест показывает медленные первые запросы при всплесках — воспринимайте это как продуктовую проблему, а не мелкую настройку. Для входа, оформления, поиска и других пользовательских шагов задержки ощущаются сразу.
Самое безопасное решение часто простое: оставьте эти шаги на всегда-готовых вычислениях. Небольшой сервис, контейнер или зарезервированный инстанс обычно дороже, чем функция на бумаге, но они защищают поток, который приносит деньги.
Serverless по‑прежнему хорош для задач, которые не требуют мгновенного отклика. Ставьте отправку писем, конвертацию файлов, генерацию отчётов, вебхуков и другие бурстовые работы за очередь. Пользователь получает быстрое подтверждение, а тяжёлая работа выполняется через секунду без блокировки страницы.
Многие команды также держат слишком много кода в критическом пути запроса. Если тяжёлые библиотеки, крупные SDK, загрузка моделей или медленная настройка происходят до каждого холодного старта, выделите их. Сделайте быстрый путь минимальным и предсказуемым. Переместите дорогую инициализацию в другой воркер или сервис, чтобы она не замедляла первый клик.
Короткое архитектурное ревью полезно перед дальнейшей миграцией. Посмотрите на холодную и тёплую задержку, размер всплесков, конкурентность, внешние лимиты (соединения с базой, rate caps) и то, что реально ждёт пользователь. Ревью часто меняет решение. Иногда не нужен полный рефакторинг: можно держать пару endpointов всегда тёплыми, поставить медленные части в очередь и оставить остальное на функциях.
Проблема часто читается неверно потому, что средняя задержка выглядит нормально, но опыт в пиковую минуту плох. Если 500 пользователей приходят одновременно, худший случай важнее медианы.
Если нужна вторая точка зрения, Oleg Sotnikov на oleg.is работает со стартапами и небольшими командами в роли Fractional CTO и может оценить, нужен ли горячий путь на функциях, контейнерах или гибридной архитектуре, прежде чем решение станет дорого отматывать.
Часто задаваемые вопросы
What is a serverless cold start?
Холодный старт — это ситуация, когда платформа не имеет готового экземпляра функции для обработки запроса. Сначала она должна загрузить ваш код, запустить рантайм, получить конфигурацию или секреты и открыть соединения, после чего вызовёт обработчик. Это стартовое время добавляет задержку, которую чувствуют пользователи.
Why do cold starts get worse during traffic spikes?
При всплесках трафика платформе приходится создавать много новых экземпляров одновременно. Небольшой запас "тёплых" инстансов покрывает не весь поток, и оставшиеся запросы ждут завершения стартовой работы. Именно тогда задержки становятся заметны в тех местах, где пользователи ждут быстрый отклик.
Which parts of a product suffer most from cold starts?
Чаще всего страдают вход в систему, оформление заказа, поиск и первая страница после входа — в этих местах даже короткая пауза сильно портит впечатление. Пользователи могут снова нажать, обновить страницу или уйти. Фоновые задания обычно переносят большие задержки лучше, если приложение показывает прогресс.
Is average latency enough to judge serverless performance?
Нет. Среднее значение может скрывать то, что небольшая часть пользователей ждёт несколько секунд во время всплеска. Смотрите p95, p99, самые медленные запросы в коротком всплеске и уровень ошибок — так вы увидите реальный пользовательский опыт.
How should I test a user-facing flow for cold start risk?
Выберите реальный пользовательский путь, установите допустимый бюджет задержки, дайте системе посидеть в тишине, а затем отправьте всплеск трафика, соответствующий реальности. Разделяйте холодные и тёплые прогоны, измеряйте полный путь от действия пользователя до финального ответа — тогда вы получите полезный результат.
What hidden limits can break a function flow even if startup looks okay?
Ограничения на соединения с базой, квоты провайдера, загрузка секретов, DNS-lookup, настройки памяти и общие лимиты конкурентности часто решают исход. Функция может запускаться быстро, но если эти зависимости не выдерживают параллельного натиска, весь запрос замедлится. Измеряйте их под нагрузкой, а не по отдельности.
Can retries make cold start problems worse?
Да. Когда медленный запрос провоцирует повторное нажатие пользователя или клиент/шлюз автоматически делает ретраи, в систему приходит дополнительный всплеск в наихудший момент. Больше запросов повышает конкурентность, что рождает ещё больше холодных стартов и дедлайнов.
How can I reduce cold start impact without a full rewrite?
Уменьшите критическую часть кода. Уберите тяжёлые импорты, отложите несущественную инициализацию, сократите работу SDK и не открывайте новые соединения в каждом инстансе без нужды. Если шаг, видимый пользователю, всё ещё небезопасен — перенесите его на всегда-готовую вычислительную единицу, а асинхронную работу оставьте на функциях.
When does a small container service make more sense than functions?
Используйте контейнеры или другой always-on-сервис, когда человек ждёт на экране и поток защищает доход. Оформление заказа, вход, подтверждение оплаты и поиск обычно попадают в эту категорию. Немного переплачивая за предсказуемое время отклика, вы часто спасаете больше дохода, чем экономите на serverless.
What is the safest way to migrate to serverless in a spiky product?
Перемещайте границы по одной. Начните с асинхронной работы: письма, конвертация файлов, отчёты — затем тестируйте снова перед переносом входа, оформления заказа или поиска. Гибридный подход часто лучше: оставляйте первый пользовательский шаг предсказуемым, а бурстовую фоную работу отдавайте функциям.


