Замените авторизацию, биллинг и потоки данных без полного переписывания
Узнайте, как поэтапно заменить авторизацию, биллинг и потоки данных, не останавливая прототип, и снизить риски во время перестройки ядра.
Содержание
Почему команды застревают, когда прототип уже работает
Прототип может жить намного дольше, чем кто-либо ожидал. Он начинает обслуживать реальных пользователей, реальные платежи и реальные сроки, поэтому команда продолжает его латать вместо того, чтобы разобрать и перестроить. Через какое-то время продукт снаружи все еще работает, но внутри уже превращается в узел.
Обычно этот узел начинается с удобства. Логика входа оказывается внутри страниц аккаунта. Проверки платежей расползаются по фичам. Правила обработки данных прячутся в обработчиках, у которых и так еще пять задач. Потом одно небольшое изменение ломает что-то далеко отсюда. Исправление в доступе внезапно задевает оформление заказа, отчеты и фоновые задачи в ту же неделю.
Команде кажется, что оба варианта плохие. Полное переписывание может съесть месяцы, принести новые баги и остановить продуктовую работу. Но и ничего не делать тоже небезопасно. Расходы растут, скорость релизов падает, а каждое изменение кажется рискованным.
Давление только усиливается, когда пользователи уже каждый день зависят от продукта. Нельзя на месяц остановить входы в систему. Нельзя просить платящих клиентов подождать, пока меняется биллинг. И нельзя заморозить отчеты или внутренние процессы только потому, что поток данных нужно привести в порядок.
Обычно снова и снова всплывают несколько предупреждающих признаков:
- Одно исправление растекается по многим файлам
- Новым инженерам нужны дни, чтобы отследить простой сценарий пользователя
- Команда избегает авторизации и биллинга, если только уже все не горит
Замена авторизации, биллинга и потоков данных кажется опасной, потому что эти части лежат подо всем остальным. Они вплетены в приложение, админские инструменты, отчеты и часто даже в привычки самой команды.
Вот почему так много команд застревают после стадии прототипа. Продукт живой, пользователям он нужен прямо сейчас, а код больше не дает чистых мест для работы. Дело не в лени. Система росла так, что каждое важное изменение кажется больше, чем должно быть.
Что оставить, а что перестроить
Первая ошибка при перестройке — выбрасывать то, что уже работает для пользователей. Если клиенты могут входить в систему, завершать оплату и находить то, что им нужно, оставьте эти экраны и шаги знакомыми. Люди намного быстрее замечают сломанные привычки, чем более чистый бэкенд.
Начинайте с боли, а не с гордости. Запишите части, которые ломаются чаще всего, создают обращения в поддержку или заставляют делать ручные исправления. Этот список обычно и показывает настоящий объект перестройки: двойные списания, путаные роли пользователей или данные, которые попадают в три места и не совпадают ни в одном.
Некоторые системы какое-то время все равно останутся на месте, хотите вы этого или нет. Ваш платежный провайдер, ERP, CRM, биллинг в магазине приложений или партнерский API могут быть закреплены контрактами, требованиями комплаенса или обычным бизнес-риском. Отметьте эти ограничения заранее. Поэтапная перестройка работает вокруг фиксированных систем, а не делает вид, что их не существует.
Выберите одну цель на первый этап и сформулируйте ее конкретно. «Более безопасный биллинг» — достаточно понятно. «Более чистая запись данных» — тоже нормально. А вот «модернизировать платформу» слишком расплывчато и обычно превращается в дорогой крюк в сторону.
Здесь хорошо работает простое правило: оставьте то, что пользователи уже понимают, перестройте то, что ломается часто или тормозит команду, отложите изменения во внешних системах, которые вы не контролируете, и оценивайте каждый шаг по одной бизнес-цели.
Oleg Sotnikov часто советует компаниям именно в этот момент, еще до того как двинется код. Спокойный подход обычно оказывается правильным: защищать пользовательский опыт, чинить рискованное ядро и оставлять приятную, но необязательную уборку на потом.
Если ваш прототип вырос в настоящий продукт, это уже важный сигнал. Интерфейс может быть грубым, но он уже научил пользователей, каким должен ощущаться продукт. Сохраните этот урок. Перестраивайте те части под ним, которые не дают команде спать по ночам.
Найдите швы до того, как трогать код
Если хотите заменить ядро системы без полного переписывания, начинайте с поведения, а не с кода.
Возьмите три обычных действия: пользователь входит в систему, клиент оплачивает покупку, а кто-то создает или обновляет данные. Затем проследите каждый шаг от браузера или приложения до последней записи в базе. Большинству команд кажется, что они и так знают эти потоки. Но когда они рисуют их на бумаге, почти всегда находятся сюрпризы.
Нарисуйте все части, которые участвуют в пути: экраны, API-эндпоинты, провайдеры авторизации, хранилище сессий, сервисы биллинга, вебхуки, логику повторных попыток, таблицы, очереди, запланированные задачи и любые отчеты или downstream-системы, которые читают те же данные.
Вот где обычно и проявляется настоящий риск. Поток входа может выглядеть как одна форма логина, но на деле часто затрагивает отправку email, обновление токена, таблицы пользователей, проверку ролей, audit logs и инструменты поддержки. Биллинг обычно еще сложнее. Неудачные платежи, возвраты и дублирующиеся события вебхуков оставляют следы сразу в нескольких местах.
Когда вы видите весь путь целиком, ищите швы. Шов — это место, куда можно вставить обертку, адаптер или тонкий внутренний API, не меняя весь продукт сразу. Для авторизации это может быть сервис сессий, который говорит и со старым провайдером, и с новым. Для биллинга — внутренний слой платежей, который сохраняет стабильность оформления заказа, пока вы меняете провайдера под ним.
Хорошие границы позволяют старому и новому коду какое-то время работать рядом. Это важнее, чем аккуратная схема. Если оба пути могут работать одновременно, вы можете сначала перевести одну группу пользователей, один тариф или один тип события, посмотреть, что происходит, и двигаться дальше.
Если граница требует одновременного перехода для всех пользователей в один день, скорее всего, это неправильная граница. Выбирайте швы, которые дают вам перекрытие, логи и простой откат.
Заменяйте по одному кусочку за раз
Не переносите все в одном релизе. Выберите одну границу, которую люди уже понимают, например вход в систему, создание счета или шаг, который записывает данные заказа после оформления покупки. Четкая граница дает команде одно место, где можно тестировать, измерять и откатывать изменения.
Прежде чем строить новый путь, оберните старый простыми проверками. Логируйте, кто вошел в поток, завершился ли он, сколько заняло времени и какую ошибку увидел пользователь. Пишите проверки простыми фразами: «вход успешен», «счет сохранен», «платеж сопоставлен с заказом». Если вы не видите текущее поведение, вы потратите время на споры о том, что именно сломалось.
Соберите замену за переключателем, который команда сможет быстро выключить. Это может быть фича-флаг, заголовок или конфигурационное правило. Важнее не сам механизм, а скорость реакции. Если поддержка начинает видеть неудачные входы или пропавшие счета, команда должна отключить новый участок за секунды, а не после полного деплоя.
Осторожный запуск обычно идет по короткому пути:
- Сначала пустите внутренних пользователей через новый участок
- Потом отдайте ему небольшую часть реального трафика
- Сравните процент успеха, ошибки, обращения в поддержку и платежные события
- Увеличивайте трафик только тогда, когда показатели остаются стабильными
Это особенно важно в потоках, которые затрагивают деньги или личность пользователя. Если вы заменяете создание счетов, проверьте суммы и налоговые строки до того, как новый путь начнет создавать живые списания. Если меняете вход в систему, следите за сбросом паролей и созданием сессий не менее внимательно, чем за успешными логинами.
Маленькие переключения кажутся медленнее в первый день. Зато потом они экономят недели. Когда один участок уже работает, у команды появляется повторяемый способ переносить следующую границу, не замораживая весь продукт.
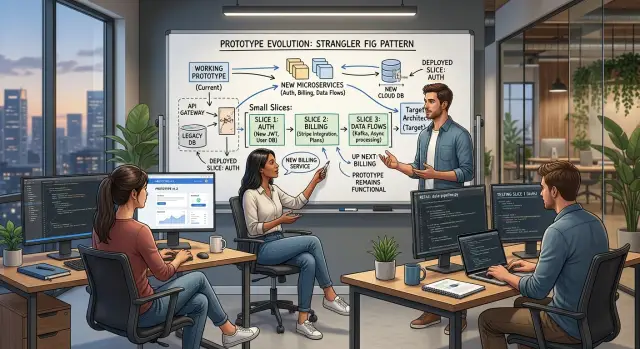
Простой пример из живого продукта
Представьте SaaS-приложение, которое выросло из прототипа. Клиенты пользуются им каждый день, экраны уже привычны, и команда не хочет этого лишаться. Поэтому они оставляют интерфейс и перестраивают то, что вызывает боль: вход, платежи и отчеты.
Они двигаются в фиксированном порядке, и у каждого шага своя узкая цель.
Сначала они переводят вход в систему на новый сервис авторизации. Пользователи по-прежнему видят ту же страницу входа, но приложение проверяет личность через новую систему. Команда сопоставляет старые учетные записи с новыми ID и сохраняет текущие сессии активными, чтобы люди не оказались заблокированы.
Потом они меняют биллинг только для новых продаж. Любой, кто оформляет новую подписку, проходит через новый путь оплаты и оформления заказа. Текущие подписчики пока остаются там, где были.
Затем они ждут продлений. По мере того как старые подписки подходят к обычной дате продления, команда переводит этих клиентов на новый путь биллинга. Так они избегают рискованной массовой миграции и дают поддержке время заметить пограничные случаи.
В конце они переводят данные отчетов на новый поток. Страница отчетов не меняется. Люди по-прежнему открывают тот же экран, но числа теперь приходят из нового потока данных под ним.
Это работает, потому что ограничивает радиус поражения. Если с входом что-то не так, биллинг и отчеты продолжают работать. Если проблема в биллинге, старые подписчики все еще продлеваются по старому пути, пока команда не исправит неполадку.
Некоторое время приложение может писать данные и в старую, и в новую систему, чтобы команда сравнивала итоги и находила расхождения. Эта дополнительная работа того стоит. Можно заменить ядро системы, не останавливая продуктовую работу и не заставляя клиентов заново учиться пользоваться приложением.
Замените авторизацию и не закройте пользователям вход
Авторизация часто оказывается самым рискованным этапом. Один неудачный релиз может заблокировать сразу всех пользователей. Самый безопасный ход — оставить старую систему входа жить достаточно долго, чтобы люди прошли через изменения и даже не заметили их.
Не переводите все учетные записи в новую систему личности в первый же день. Дайте существующим сессиям работать, пока они не истекут. Если кто-то вошел вчера, он должен попасть в приложение и сегодня, даже если ночью вы поменяли бэкенд. Это дает время и быстро снижает число обращений в поддержку.
Вам также нужна понятная связь между старым ID пользователя и новой записью личности. Храните оба ID в одном месте и считайте это частью миграции, а не мелкой деталью. Если биллинг, права доступа, audit logs или отчеты все еще ссылаются на старый ID, эта связь помогает сохранить все части привязанными к нужному человеку.
Небольшой план тестирования ловит большую часть неприятных сбоев:
- Создать новую учетную запись
- Войти с существующей учетной записью
- Сбросить пароль
- Принять приглашение от другого пользователя
- Использовать старую сессию после переключения
Админские сценарии обычно превращаются в кашу. У некоторых пользователей записи могут оказаться в обеих системах: кто-то зарегистрировался дважды, позже вошел через рабочую почту или пришел по приглашению. До запуска решите, кто будет объединять такие записи, какие данные главнее и что админы смогут править вручную. Если оставить это расплывчатым, поддержка начнет принимать решения по каждому случаю отдельно и создаст еще больше уборки.
Напишите откат, который занимает минуты, а не часы. Если число ошибок при входе растет, верните новые логины на старую систему, сохраните таблицу сопоставления ID и логируйте каждую неудачную попытку с email, провайдером и шагом, на котором все сломалось. Хороший откат не чинит баг. Он просто дает пользователям рабочую дверь, пока команда исправляет проблему.
Команды, которые хорошо справляются с авторизацией, относятся к ней как к пограничному пункту. Они на время держат открытыми обе стороны, проверяют каждого проходящего и закрывают старые ворота только после того, как поток идет чисто.
Меняйте биллинг, не теряя заказы
С биллингом обычно что-то идет не так, когда команда пытается перенести все списания, все подписки и все счета в один день. Так заказы теряются, возвраты превращаются в хаос, а финансы очень быстро перестают доверять системе.
Более безопасный шаг — сначала направить через новый путь только новые покупки. Старые подписки оставьте там, где они есть, пока не докажете, что новый поток работает. Новый checkout, новые счета, новые платежные события. Старые продления могут еще какое-то время продолжать идти в старой системе. Это менее изящно, но резко снижает риск.
Небольшая ежедневная проверка помогает сильнее, чем большой ежемесячный аудит. Каждый день сравнивайте итоги старого и нового потока счетов: продажи, налоги, скидки и неудачные платежи. Если на второй день новая система отстает на несколько заказов, вы можете исправить это до того, как на десятый день поддержку завалят обращениями.
Возвраты и споры по списаниям должны жить в одном месте. Если клиентам и поддержке приходится гадать, где находится платеж, значит, изменение биллинга уже провалилось. Оставьте одно внутреннее место, где команда смотрит статус платежа, историю возвратов и заметки по спорам, даже если под капотом еще недолго работают две системы биллинга.
Если изменилась логика цен, заморозьте редактирование тарифов на короткое время. Апгрейды, даунгрейды, prorations и странные случаи с купонами ломаются чаще, чем первая покупка. Пауза на 24–72 часа обычно проще, чем потом разгребать неправильные счета.
Поддержке тоже нужен короткий чек-лист, когда платеж выглядит неправильно:
- Проверьте, какая система создала счет
- Проверьте тариф, скидку и налог в этом счете
- Проверьте, списали деньги один раз или дважды
- Проверьте, где должен быть оформлен возврат
- Проверьте, не изменился ли срок продления во время миграции
Простой пример: если SaaS-продукт переносит логику Stripe в новый сервис, сначала направьте туда только совершенно новых клиентов. Каждый день смотрите на цифры. Когда итоги совпадают, а тикеты в поддержку не растут, двигайте следующий кусок.
Переносите потоки данных, не ломая отчеты
Отчеты обычно ломаются по простой причине: команда меняет место, где лежат данные, но никто не отслеживает, каким цифрам бизнес еще доверяет. Относитесь к отчетности как к отдельной миграции. Не ждите конца, чтобы проверить, совпадают ли суммы.
Сначала копируйте данные в новый поток, пока старый все еще кормит дашборды и выгрузки. Это дает время сравнить записи, исправить ошибки сопоставления и заметить пропавшие события до того, как кто-то начнет полагаться на новые цифры. После этого переключайте по одному пути чтения или по одному отчету за раз. Записи переносите позже, маленькими кусками.
Обычная таблица ответственности полезнее красивой схемы. Перечислите каждое поле, важное для отчетности, например customer ID, название тарифа, статус счета, сумму возврата и дату продления. Для каждого этапа назначьте один источник владельцем. Если две системы обе пишут в subscription_status, а никто не знает, какая из них главнее, отчеты быстро начнут расходиться.
Проверяйте цифры каждый день, пока работают оба пути. Сравнивайте количество строк, денежные суммы, группы статусов вроде paid, failed и refunded, а также любые отсутствующие или дублирующиеся ID.
Ежедневные проверки ловят мелкие дыры, пока логи еще свежие и люди помнят, что изменилось. Если вчерашний отчет показывает 1 204 оплаченных счета, а новый поток — 1 191, остановитесь и найдите недостающие 13, прежде чем двигать дальше что-либо еще.
Старые выгрузки лучше оставить на время, даже если новые отчеты уже выглядят правильно. Финансам и операционным командам нужны повторные подтверждения, а не один идеальный тест. Многие команды расслабляются после одного хорошего дня, а потом сталкиваются с проблемами во время зарплат, закрытия месяца или проверки возвратов.
Дублирующиеся записи убирайте последними. Подождите, пока команда увидит стабильные цифры и в обычные дни, и в загруженные. Это кажется медленнее, но на самом деле сокращает переделки и дает чистый откат, если новый поток что-то пропустит.
Ошибки, которые создают переделки
Переделки появляются, когда команды относятся к поэтапной перестройке как к чистому rewrite. Смысл как раз в том, чтобы снизить риск. Если менять авторизацию, биллинг и потоки данных в одном релизе, эта защита исчезает.
Одно изменение может скрыть другое. Ошибка входа может выглядеть как проблема с биллингом, потому что пользователь не может дойти до checkout. Пробел в отчетах может выглядеть как плохие данные, хотя настоящая проблема сидит в новом потоке событий. Когда команды складывают три больших замены вместе, они тратят дни на то, чтобы распутать, что именно сломалось.
Еще одна частая ловушка живет в модели данных. Команды переделывают таблицы и поля раньше, чем поймут, как люди пользуются продуктом. Потом поддержке нужен экран истории возвратов, финансовой команде — старые статусы счетов, а операционка все еще зависит от странной выгрузки, которую никто не документировал. Модель выглядит чище на бумаге, но команде все равно приходится добавлять заплатки, чтобы вернуть поведение, которое старая система уже умела.
Тренировки отката важнее, чем ожидает большинство команд. Если вы не можете быстро вернуться назад, вы не готовы к переключению. Проведите тренировку до дня релиза. Засеките время. Решите, кто принимает решение, кто нажимает на переключатель и как вы подтвердите, что после отката заказы, сессии и отчеты продолжают работать.
Небольшие внутренние инструменты тоже наносят удивительно много вреда. Фоновые задания, админ-панели, ручные возвраты, проверки мошенничества, CSV-выгрузки и скрипты поддержки часто завязаны на старую логику авторизации или биллинга. Пользователи могут никогда не увидеть эти части, но ваша команда пользуется ими каждый день. Если они ломаются, работа замедляется именно тогда, когда вам особенно нужно ясное мышление.
Команды еще и слишком рано выключают старую систему. Держите ее живой, пока поддержка не закроет открытые тикеты, финансы не разберут спорные случаи, а команда не подтвердит, что отложенные задания и поздние вебхуки больше не зависят от старого пути.
Поэтапная перестройка лучше всего работает, когда каждый кусок может жить сам по себе, ломаться сам по себе и откатываться сам по себе. Если изменение не соответствует этому стандарту, оно, скорее всего, слишком велико.
Быстрые проверки перед каждым переключением
Для переключения нужен четкий критерий успеха или провала. Если команда не может сказать, как выглядит успех именно для этого участка, подождите. Расплывчатые цели скрывают мелкие поломки, пока пользователи не начинают писать раздраженные письма.
Запишите одну или две цифры, которые докажут, что новый путь работает. Для авторизации это может быть процент успешных входов и завершение сброса пароля. Для биллинга — количество оплаченных заказов и корректно записанных возвратов. Выбирайте метрики, которые можно проверить в тот же день.
Вам также нужен путь к отступлению. Если новый поток начинает ломаться, команда должна выключить его за минуты. Конфигурационный переключатель, feature flag или разделение трафика обычно достаточно. Если для отката нужны правки кода и новый деплой, переключение слишком рискованно.
Используйте короткий список перед запуском:
- Назовите метрику успеха и число, при котором нужен откат
- Проверьте не только чистый демо-путь, но и сбойные сценарии
- Убедитесь, что поддержка видит нужного пользователя, заказ или событие
- Подтвердите, кто следит за логами и бизнес-итогами после запуска
- Поставьте время ревью в календарь до начала переключения
Проблемным сценариям нужно уделять особое внимание, потому что они первыми бьют по реальным пользователям. Проверьте истекшие токены, двойные списания, пропавшие вебхуки, неполные импорты и всплески повторных попыток. Участок может выглядеть идеальным в staging и все равно ломаться на плохих данных, медленных ответах стороннего сервиса или старых записях с грязной структурой.
Командам поддержки тоже нужна видимость. Если клиент не может войти или счет исчез, поддержка должна видеть достаточно контекста, чтобы объяснить, что произошло и кто отвечает за исправление. Простой дашборд или заметка в админке часто экономят часы.
Назначьте дату ревью до запуска, а не после. Потом сравните логи, итоги и отчеты пользователей со старой системой. Поэтапная перестройка работает потому, что каждое переключение остается маленьким, наблюдаемым и обратимым.
Что делать дальше при поэтапной перестройке
Большинству команд нужна одна страница, а не гигантская дорожная карта. Запишите порядок участков, кто отвечает за каждое переключение, как выглядит успех и что делать, если что-то пойдет не так. Потом заранее покажите эту страницу продукту, поддержке и финансам. Поддержке нужно знать, что могут заметить клиенты. Финансам нужно знать, когда счета, возвраты или отчеты могут выглядеть иначе.
Первый участок выбирайте по риску, а не по любопытству. Самая интересная часть часто оказывается худшим местом для старта. Если ошибки входа каждую неделю создают тикеты, авторизации может понадобиться внимание раньше, чем редизайну биллинга. Если реальный ущерб наносят дублирующиеся списания или сломанные выгрузки, сначала идти может именно биллинг или поток данных.
Короткий список планирования помогает оставаться честными:
- Назовите каждый участок в порядке запуска
- Задайте одну понятную метрику успеха для каждого переключения
- Определите триггер отката и кто может его запустить
- Отметьте, каким командам нужно предупреждение заранее
- Оставьте место для продуктовой работы между участками
Последний пункт особенно важен. Поэтапная перестройка не должна замораживать дорожную карту на три месяца. Небольшие команды обычно работают лучше, когда выпускают один участок, смотрят на него в продакшене, исправляют шероховатости, а потом переходят к следующему.
Если команда не уверена в порядке шагов, правилах отката, выборе инфраструктуры или в том, как безопасно разделить старую и новую системы, внешний обзор может сэкономить недели переделок. Oleg Sotnikov на oleg.is работает со стартапами и небольшими компаниями как fractional CTO и advisor, помогая командам планировать такие миграции, не останавливая продуктовую работу.
План не обязан выглядеть впечатляюще. Ему достаточно быть достаточно ясным, чтобы все понимали, что меняется в следующий понедельник, что может сломаться и что вы сделаете, если это произойдет.
Часто задаваемые вопросы
Нужен ли нам полный rewrite, чтобы исправить неаккуратный прототип?
Нет. Если экраны и шаги, к которым уже привыкли пользователи, работают достаточно хорошо, оставьте их. Перестраивайте то, что часто ломается, тормозит команду или создает риск для денег и доступа.
Что нужно спланировать, прежде чем трогать код?
Начните с поведения, а не с кода. Проследите несколько обычных действий — вход в систему, оплату и обновление данных — от интерфейса до последней записи в базе, чтобы увидеть, где системы реально связаны.
Как понять, что стоит перестраивать в первую очередь?
Выберите ту область, которая сейчас доставляет больше всего проблем. Тикеты в поддержку, ручные исправления, дублирующиеся платежи, сломанные роли или некорректные данные в отчетах обычно подсказывают лучший первый шаг.
Как заменить авторизацию и не заблокировать пользователей?
Оставьте старый путь входа в систему работать какое-то время и дайте текущим сессиям завершиться естественно. Сопоставьте старые ID пользователей с новыми записями, проверьте сброс пароля и приглашения и держите быстрый переключатель назад на старую систему, если ошибки вырастут.
Как безопаснее всего менять биллинг?
Сначала переведите только новые покупки и оставьте существующие подписки там, где они есть, пока новый поток не докажет свою надежность. Каждый день сравнивайте суммы, дайте поддержке одно место для проверки истории платежей и не пытайтесь перенести весь биллинг сразу.
Как перенести потоки данных, не сломав отчеты?
Относитесь к отчетам как к отдельной миграции. Сначала копируйте данные в новый поток, каждый день сравнивайте количество записей и суммы, а затем переключайте отчеты по одному, прежде чем убрать старые записи.
Какие метрики важны во время каждого переключения?
Следите за небольшим набором показателей, которые можно проверить в тот же день. Успешные входы, завершение сброса пароля, оплаченные заказы, точность возвратов, уровень ошибок и обращения в поддержку быстро покажут, работает ли новый участок.
Когда лучше сделать откат, а не продолжать?
Откатывайтесь, если новый путь не достигает заранее заданной цели. Если входы в систему не проходят, счета пропадают или суммы расходятся, быстро отключите новый участок и исправьте проблему, пока пользователи продолжают работать через старый путь.
Можно ли продолжать выпускать продукт во время поэтапной перестройки?
Да, если каждый шаг остается небольшим. Команды обычно работают лучше, когда выпускают один участок, смотрят на него в продакшене, исправляют шероховатости и только потом возвращаются к обычной продуктовой работе перед следующим шагом.
Когда есть смысл обратиться к fractional CTO за помощью?
Привлекайте внешнюю помощь, когда команда не может договориться о порядке шагов, границах, правилах отката или компромиссах по инфраструктуре. Короткий обзор от опытного CTO может сэкономить недели переделок и помочь защитить пользователей, пока вы меняете ядро.


