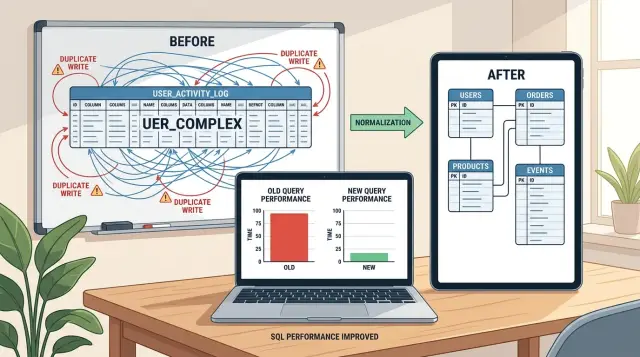
Высокий счёт в облаке? Виной может быть модель данных
Высокий счёт в облаке часто начинается с широких таблиц, множества мелких запросов и неудобных джоинов. Узнайте, как выбор схемы увеличивает расходы ещё до роста трафика.
Содержание
Почему расходы растут ещё до роста трафика
Большой счёт за облако не всегда означает, что у вас внезапно появилось больше пользователей. Многие команды видят, как расходы растут при почти неизменном трафике. Обычно причина проста: каждый запрос теперь выполняет больше работы, чем раньше.
Эта дополнительная работа быстро накапливается. Страница, которая раньше требовала одного аккуратного запроса, может теперь делать десять вызовов к базе, тянуть гораздо больше колонок, чем использует экран, и джойнить таблицы, которые плохо подходят под запрос. Вы платите за это в виде вычислений, памяти, сетевого трафика и дисковых операций задолго до того, как трафик достигнет следующего шага роста.
Одна медленная страница может заметно сдвинуть счёт сама по себе. Пользователь открывает панель, и приложение подтягивает аккаунт, участников команды, права доступа, недавнюю активность, статус оплаты, feature-флаги и пару счётчиков. Если код запрашивает каждую часть отдельно, один клик превращается в всплеск запросов к базе. Пользователь видит небольшую задержку. Ваш провайдер облака видит лишние чтения, больше CPU и больше пропаривания кэша.
Само хранение часто недорогое. Дорого читать и обрабатывать данные. Команды иногда фокусируются на размере базы и пропускают реальную статью расходов: повторяющиеся сканирования, чрезмерно большие наборы результатов и запросы, которые заставляют базу много работать при каждом вызове. База на 200 ГБ может быть дёшейво храниться и дорого обрабатываться, если запросы написаны плохо.
Именно поэтому высокий счёт часто появляется на ранних стадиях продукта. Приложение всё ещё кажется небольшим, но стоимость одного запроса уже выросла.
Куда уходит деньги
Когда расходы растут, первым часто смотрят на слой базы данных. Вы платите за CPU, память, чтения с диска и сетевой трафик, и слабая модель данных может поднять все четыре одновременно.
CPU растёт, когда запросы сортируют, фильтруют, джойнят и сканируют больше строк, чем нужно. Память растёт, когда базе нужны большие рабочие наборы, большие кэши или место для временных результатов. Появляются дисковые расходы, когда таблицы настолько широки, что каждое чтение вытягивает гораздо больше данных, чем нужно экрану или API. Сетевой трафик растёт, когда приложение перемещает большие наборы результатов между базой, репликами, уровнями кэша и инструментами отчётности.
Последняя часть легко ускользает от внимания. Команды смотрят на основную статью расходов по базе, но реплики, ноды кэша и стек отчётности часто дорожают по той же причине. Расточительные запросы создают нагрузку на всё вокруг.
Графики трафика могут обмануть. Плоская линия трафика не значит плоскую работу базы, потому что одна новая панель, задача экспорта или фоновой синхронизации может удвоить объём запросов без заметного увеличения числа пользователей.
Посмотрите на экраны, которые люди открывают чаще всего, на плановые задания и отчёты, которые тянут большие наборы данных. Страница, которая на каждой загрузке делает двенадцать мелких запросов, может стоить дороже, чем редко используемая страница с одним тяжёлым запросом.
Часы пик важны, но логи запросов обычно рассказывают правду. Сравните всплески CPU с конкретными запросами, которые выполнялись в это время. Часто вы обнаружите отчёт, который стартует в 9:00, задачу синхронизации, выполняющуюся каждые пять минут, или виджет на главной, который тихо раздувается в множество чтений.
Если хотите быстро найти расточительство, ищите повторяющиеся чтения одних и тех же данных, запросы, возвращающие колонки, которыми никто не пользуется, и джоины, которые постоянно проходят по большим таблицам. Эти паттерны поднимают расходы ещё до роста трафика.
Широкие таблицы читают больше, чем нужно
Высокий счёт в облаке часто начинается с байтов, а не с трафика. Многие приложения просят из базы маленький срез информации, но строка таблицы хранит куда больше. Каждое чтение подтягивает лишние данные в память, кэш и на диск, и вы платите за работу, которую страница никогда не использует.
Это случается постоянно в растущих продуктах. Для дашборда может быть нужно имя пользователя, тариф, статус, время последнего входа и один флаг. Но в той же строке лежит длинное био, JSON с настройками, заметки поддержки, история экспортов и другие текстовые поля, которые редко нужны на этом экране.
Большие колонки обычно причина. JSON, текст и сериализованные настройки могут сделать строку намного тяжелее, чем кажется по схеме. Даже если запрос выбирает лишь несколько полей, широкие таблицы вредят, потому что базы читают данные блоками, кэши хранят меньше строк, а реплики передают больше байт.
Результат предсказуем. Хиты кэша падают, потому что каждая кэшированная строка занимает больше места. Память заполняется быстрее, и база чаще читает с диска. Реплики и бэкапы перемещают большие куски данных. Простые страницы обходятся дороже за каждое обращение, чем должны.
Трафик может выглядеть нормально, но счёт растёт. Поэтому «модель данных — стоимость в облаке» часто важнее, чем простой подсчёт запросов.
Разделяйте горячие данные и холодные
Если большинство чтений остаются узкими, держите часто используемые поля вместе и вынесите редко используемые в другое место. Поместите базовую информацию профиля в одну таблицу, а громоздкие метаданные, аудиторские заметки и большие JSON-документы — в отдельную таблицу или стор.
Практическое правило простое: если один экран требует пять полей и пропускает восемьдесят колонок, таблица делает слишком много. Широкие таблицы также делают более дорогими мелкие запросы и неудобные джоины позже, потому что каждый шаг перемещает лишние данные.
Не обязательно полностью переделывать всё с первого дня. Начните с самого загруженного пути чтения, измерьте размер строки и вынесите холодные поля первыми. Это часто сокращает стоимость чтений до того, как вы коснётесь трафика.
Много мелких запросов (chatty queries) тратят деньги по одному запросу
Рост трафика — не единственная причина роста облачных затрат. Один API-вызов может разветвиться на десять, двадцать или сто маленьких запросов к базе. Каждый запрос по отдельности кажется безобидным, но повторение и есть то, что толкает счёт вверх. Каждый лишний вызов добавляет сетевое время, работу с подключениями, парсинг и загрузку CPU.
Причина обычно в приложении, а не в базе. Запрос загружает список записей, а затем в цикле запрашивает связанные данные по одному элементу. Так появляется паттерн N+1. Пользователь открывает страницу, но приложение выполняет один запрос для страницы, затем ещё пятьдесят для пользователей, затем ещё пятьдесят для статусов или прав.
Возьмите страницу команды, где показывают сорок проектов. Сначала загружаются проекты. Потом для каждого проекта отдельно запрашивают владельца, последний счёт и последнюю активность. Одна страница может инициировать более 120 вызовов к базе до того, как пользователь нажмёт ещё что‑то.
Мелкие запросы всё равно стоят денег. Они держат соединения занятыми, тратят CPU на повторяющиеся операции и повышают I/O при получении мало полезных данных. В управляемых облачных решениях это часто подталкивает команды к покупке более крупного инстанса базы или дополнительных реплик.
Батчинг решает большую часть этих проблем. Если один запрос нуждается в связанных данных, подтяните их в одном спланированном батче, вместо того чтобы задавать один и тот же вопрос снова и снова. Предзагружайте отношения, которые всегда нужны странице. Кэшируйте повторяющиеся lookup’и в пределах одного запроса. Считайте количество запросов на endpoint, а не только время ответа.
Это часто экономит больше, чем низкоуровневый тюнинг запросов. Если один endpoint сократит количество запросов с 120 до 4, база будет делать меньше работы на каждом запросе весь день.
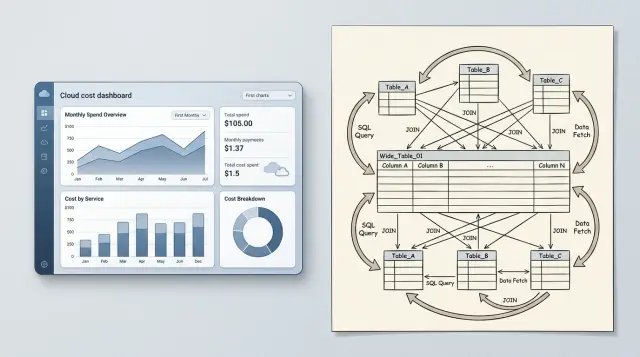
Неудобные джоины умножают работу
Джоины — нормальная вещь. Проблема начинается, когда для одного простого ответа требуется соединить пять или шесть таблиц при каждом открытии страницы.
Это обычно случается, когда базовые факты разделены слишком далеко. Запись клиента в одной таблице, детали тарифа в другой, лимиты функций в третьей, статус счёта в четвёртой и роли в сопоставительной таблице. Запрос всё ещё возвращает данные для одного экрана, но базе приходится делать гораздо больше работы, чем видит пользователь.
Растущему SaaS-продукту часто рано приходится столкнуться с этим. Дашборд запрашивает двадцать строк, но база читает тысячи, потому что ей нужно сопоставить каждую таблицу, отфильтровать и отсортировать результат. Расходы растут, даже если рост пользователей едва заметен.
Отсутствующие индексы усугубляют ситуацию. Если столбцы для джоинов не индексированы, база не может быстро найти совпадающие строки — она сканирует большие таблицы, строит временные структуры в памяти и иногда сбрасывает работу на диск. В управляемой базе это превращается в больше CPU, I/O и денег.
Многие‑к‑многим джоины могут быстро стать дорогими. Один пользователь может принадлежать пятнадцати проектам и иметь восемь прав. Джойните такие таблицы с логами активности или платёжными элементами, и количество промежуточных строк может взорваться до того, как финальный фильтр оставит лишь небольшую часть. Вы платите за промежуточную работу, а не только за финальный результат.
Когда денормализация помогает
Если один горячий запрос постоянно пересекает одни и те же таблицы, строгая нормализация может стать дорогой. В таком случае дешевле хранить несколько стабильных фактов поближе к месту чтения.
Это не значит копировать всё повсеместно. Обычно речь идёт о добавлении таблицы-сводки, кэшируемой модели чтения или материализованного представления для полей, которые редко меняются — например, текущий тариф, статус аккаунта или состояние последнего счёта. Тогда база отвечает на частый запрос одним чтением вместо длинной цепочки джоинов.
Если база тратит больше времени на объединение таблиц, чем на возврат результатов, схема — часть вашей статьи расходов.
Простой пример из растущего SaaS
Представьте SaaS с несколькими тысячами активных аккаунтов и дашбордом, который клиенты открывают много раз в день. Трафик почти не меняется из месяца в месяц, но счёт за базу постепенно ползёт вверх.
Команда хранит почти всё в одной большой таблице аккаунтов: данные пользователя, текущий план, месячные итоги использования, лимиты функций, состояние счёта, даты триала и куча флагов. По‑своему удобно: одна строка вроде бы держит всю историю аккаунта. Проблема в том, что большинство экранов требует лишь мелкой части этой строки, но база всё равно читает намного больше данных, чем реально используется.
Потом дашборд добавляет ещё расточительства. Один виджет просит использование, другой — лимиты плана, третий — статус счёта, четвёртый — флаги аккаунта. Вместо одного хорошо спланированного запроса страница делает отдельные вызовы для каждого виджета. Один визит клиента может превратиться в восемь–десять запросов, хотя все они опираются на одни и те же данные аккаунта.
Отчёты усугубляют ситуацию. Команда делает живой админ‑отчёт, который при каждом обновлении джойнит события, пользователей, тарифы и счета. Саппорт открывает его. Финансы открывают. Продукт открывает. Никто не хочет вредить, но каждое обновление заставляет базу снова сортировать, джойнить и сканировать большие куски данных.
И вот странность: трафик остаётся ровным. Приложение по‑прежнему имеет примерно столько же ежедневных пользователей. Но время вычислений растёт, чтения с диска растут, промахи кэша растут — и счёт следует за ними.
Этот паттерн типичен для ранних SaaS‑продуктов. Команды сосредоточены на фичах, поэтому широкие таблицы, много мелких запросов и неудобные джоины незаметно просачиваются в систему. Приложение сначала кажется нормальным. Счёт замечает это раньше всех.
Как по шагам проверить систему
Если у вас высокий счёт в облаке, не начинайте сразу с ревизии всего приложения. Начните с одного пути, по которому люди ходят весь день: страницы дашборда, задачи синхронизации или API‑роут, который используют все клиенты.
Узкая проверка лучше широкой, потому что вы можете проследить весь путь, увидеть, что база читает, и связать эту работу с реальными деньгами.
- Выберите один дорогой путь. Берите что‑то загруженное или медленное, а не редкое. Страница, которая загружается каждое утро у всех клиентов, обычно лучше, чем ежемесячный админ‑отчёт.
- Перечислите все запросы, которые запускает этот путь. Включите первый запрос, повторные попытки, фоновые вызовы и всё, что страница тянет после рендера. Посчитайте, как часто каждый запрос выполняется на одно действие пользователя.
- Измерьте, что делает каждый запрос. Проверьте прочитанные строки, прочитанные колонки, глубину джоинов, время ответа и сколько данных уходит обратно в приложение. Запрос, который возвращает двадцать строк, может быть расточительным, если он сканирует 200 000 и тянет сорок колонок.
- Перепишите худшую часть в первую очередь. Удалите неиспользуемые колонки, сократите лишние круги запросов или замените сложную цепочку джоинов на простую модель чтения. Затем сравните стоимость, латентность и нагрузку на базу до и после.
- Повторите для следующего загруженного пути. Маленькие победы быстро складываются, если один и тот же запрос выполняется тысячи раз в день.
Короткий пример: страница клиента делает двенадцать запросов для деталей аккаунта, участников команды, счетов, использования, feature‑флагов и уведомлений. Каждый запрос по отдельности кажется безобидным. Вместе они читают намного больше, чем экран использует, и заставляют базу работать при каждом клике.
Команды, которые держат инфраструктуру в узде, обычно действуют так: измеряют один горячий путь, сокращают расточительство и переходят к следующему. Если нужна вторая пара глаз, Oleg Sotnikov at oleg.is делает такие пошаговые архитектурные ревью в рамках своей работы по Fractional CTO и консультациям стартапам.
Ведите заметки в небольшой таблице или документе. После трёх‑четырёх проходов вы обычно увидите повторяющиеся шаблоны. Одни и те же широкие таблицы, много мелких запросов и неудобные джоины проявляются во многих местах.
Ошибки команд, когда они гонятся за неверным решением
Высокий счёт часто подталкивает команды к самым крупным инструментам сначала. Они апгрейдят базу, добавляют реплики или переходят на более дорогой уровень сервиса. Это кажется безопасным, но обычно не решает реальную проблему. Приложение по‑прежнему запрашивает слишком много данных слишком часто в самом дорогом виде.
Более мощная база может на время скрыть плохую форму запросов. Если одна страница делает десять тяжёлых запросов, более сильный инстанс может снизить латентность, но при этом делает каждое расточительное чтение ещё дороже. Счёт растёт тихо, потому что приложение продолжает читать широкие строки, сканировать большие индексы и повторять работу при каждом запросе.
Кэши — ещё одно распространённое отвлечение. Они помогают, но многие команды добавляют их до того, как понимают, что именно скрывают. Система становится сложнее. Вы платите за кэш, всё ещё платите за промахи в базе, и дополнительно тратите инженерное время на баги из‑за несвежих данных.
Ранний шардирование — классический пример. Команды дробят данные по нодам, потому что база выглядит загруженной, но паттерн доступа остаётся тем же. Если каждый запрос всё ещё раздувается по множеству записей или всё ещё запускает цепочку мелких запросов, шардирование просто распределяет боль, а не решает её.
Чрезмерная нормализация создаёт другой вид затрат. На бумаге схема выглядит аккуратно. В проде один запрос может джойнить полсхемы, чтобы отрисовать карточку дашборда или страницу аккаунта. База делает больше работы, приложение ждёт дольше, и каждый дополнительный джоин добавляет CPU, давление на память и I/O. Проще модель чтения часто дешевле идеально чистой схемы.
Команды также слишком быстро винят трафик. Иногда трафик — не главный фактор. Одна cron‑задача, которая запускается каждые пять минут, может сделать больше вреда, чем тысячи пользовательских запросов, если она сканирует большие таблицы, перестраивает отчёты с нуля или тянет колонки, которыми никто не пользуется. Фоновые задачи могут съедать в день больше вычислений, чем клиентская часть.
Паттерн прост: команды платят за сохранение плохих привычек. Больше серверов, дополнительные уровни кэша и раннее шардирование не исправят расточительные чтения. Сначала исправьте паттерн доступа: обрежьте колонки, уменьшите круги запросов и перестаньте джойнить данные, которые странице не нужны.
Быстрая проверка перед масштабированием
Прежде чем добавлять мощность, просмотрите самые загруженные страницы, самые тяжёлые задания и запросы, которые выполняются весь день.
Проверьте горячие запросы в первую очередь. Если странице нужны только имя, статус и дата, она не должна читать сорок колонок только потому, что они лежат в одной широкой таблице. Считайте вызовы базы на распространённых экранах. Дашборд, который вызывает двадцать пять мелких запросов, часто стоит дороже, чем один аккуратный запрос, даже при умеренном трафике.
Внимательно посмотрите на таблицы джоинов в фильтрах и отчётах. Если они быстро растут и у них нет нужных индексов, каждое обращение становится медленнее и дороже. Проверяйте фоновые задания с тем же скепсисом, что и пользовательский трафик. Синхронизация, которая читает пять миллионов строк ради обновления двадцати тысяч, делает слишком много сканирований.
Полезно взять топ‑10 запросов по стоимости или частоте и объяснить каждый простыми словами. Если команда не может сказать, что делает запрос, зачем он запускается и какие данные нужны — этот запрос рискован.
Небольшие примеры делают это очевидным. Страница биллинга может тянуть полные записи клиентов, полные счета и несколько джоинов ради данных, которые на экране вообще не появляются. Или ночная задача может сканировать всю таблицу событий, чтобы найти изменения за вчера. Ни одному из этих проблем не нужен огромный трафик, чтобы ударить по счёту.
Что делать дальше
Купите меньше мощности позже. Сначала проверьте схему и самые загруженные пути запросов.
Высокий счёт в облаке часто начинается с проектировочных решений, которые казались безобидными при маленьком продукте. Одна таблица набрала сорок колонок «про запас». Одна страница стала делать шесть вызовов вместо одного. Один отчёт добавил пару джоинов, затем ещё пару. Ничто из этого по отдельности не кажется дорогим. Вместе они превращают нормальный рост в проблему затрат.
Начните с частей продукта, которые работают весь день: входы в систему, загрузки дашборда, поиск, страницы биллинга, синхронизаторы и фоновые воркеры. Эти пути формируют счёт гораздо сильнее, чем редко используемые админ‑экраны.
Используйте простой бюджет для каждого пути. Отслеживайте стоимость на запрос, стоимость на загрузку страницы, стоимость фоновой задачи, чтения базы, прочитанные строки и количество запросов на действие. Вам не нужен идеальный расчёт с первого дня. Грубый бюджет достаточно, чтобы найти худшие участки.
Делайте работу маленькой и регулярной. Выбирайте каждый week по одному дорогому пути. Убирайте колонки, которыми никто не пользуется. Объединяйте мелкие вызовы. Убирайте джоины, которые появились только потому, что схема росла без плана. Измеряйте счёт после каждого изменения. Маленькие правки быстро складываются, когда они касаются общих путей.
Если команде нужна внешняя помощь, Oleg Sotnikov at oleg.is работает со стартапами и малыми бизнесами по архитектуре, инфраструктуре и облачным расходам. Польза не в том, чтобы быстрее купить больше железа, а в том, чтобы найти чтения, джоины и паттерны запросов, которые изначально не должны были быть дорогими.
Если вы сделаете только одно дело в этом месяце, сделайте следующее: проследите самое дорогое пользовательское действие от загрузки страницы до базы и выпишите все чтения, джоины и фоновые задачи, которые оно запускает. Эта карта обычно показывает, куда уходят деньги.