Выделенные серверы с облачным резервом мощности для пиков запуска
Узнайте, как схема bare metal с облачным резервом мощности помогает держать постоянные нагрузки дешёвыми и при этом быстро расширяться для запусков, акций и всплесков трафика.
Содержание
Какую проблему решает эта схема
У большинства продуктов нагрузка не находится на пике каждый день. Почти весь месяц трафик держится в обычных пределах, а потом резко вырастает после запуска, кампании или выхода новой функции. Если рассчитать инфраструктуру под этот пик и платить за неё круглый год, спокойные дни быстро становятся слишком дорогими.
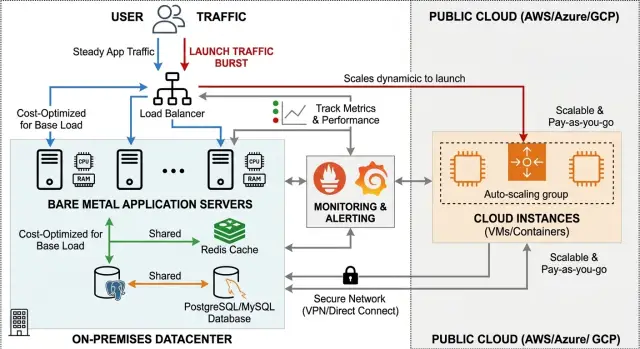
Гибридная схема решает это за счёт разделения задач на две части. Постоянную нагрузку вы держите на bare metal, где ежемесячные расходы проще предсказать и обычно ниже для стабильных вычислений. А дополнительную облачную мощность арендуете только тогда, когда спрос растёт.
Это особенно хорошо работает для стартапов и растущих продуктовых команд, у которых типичный сценарий такой: стабильный трафик большую часть недель и лишь несколько часов или дней сильной нагрузки. Если купить инфраструктуру под самый большой возможный пик, большую часть времени вы платите за простой. Если держать всё слишком экономно, можно получить медленные страницы, таймауты или неудачные оплаты именно тогда, когда внимание максимально.
Полностью облачная схема убирает один вид перерасхода, но компромисс часто заметен в ежемесячном счёте. Полностью bare metal избегает высоких облачных ставок, но даёт меньше пространства, если релиз окажется успешнее ожиданий. Гибридная схема стоит посередине. Она даёт более дешёвую базу для повседневного трафика и дополнительный запас, когда он нужен.
Обычно становится понятно, что модель подходит, если дневной трафик остаётся в обычном диапазоне, пики короткие и связаны с запусками, приложение может масштабироваться на большее число серверов без серьёзной переработки, а команде нужен меньший постоянный расход без ставки на простой.
Простой пример хорошо показывает математику. Если продукту нужно 12 ядер каждый день, но 60 ядер на 36 часов после запуска, платить за пиковую цену весь месяц просто не имеет смысла. Держите дешёвую базу на 12 ядер и арендуйте дополнительные 48 только тогда, когда они действительно помогают.
Что лучше оставить на bare metal
Стабильная часть системы должна жить на bare metal. Если сервис работает весь день, каждый день, и его нагрузка меняется медленно, то машины с фиксированной стоимостью обычно оказываются для него дешевле и проще.
Начните с предсказуемых app-серверов. Они обслуживают обычный дневной трафик, а не дополнительную волну, которая приходит во время запуска. Если в обычную неделю продукту нужно четыре app-сервера, держите эти четыре на контролируемом вами железе и считайте облако запасным вариантом, а не основным местом работы.
Базы данных тоже часто подходят под эту модель. Когда запросы на чтение и запись остаются в понятных пределах, bare metal даёт стабильную производительность и меньше сюрпризов в счёте. Команда также получает прямой контроль над хранилищем, резервными копиями и настройками. Базы данных не любят резких переездов, поэтому обычно им место в самой стабильной части стека.
Фоновые задачи тоже могут остаться там, если они не дают больших всплесков. Ночные синхронизации, генерация отчётов, пакетная отправка писем и задачи на очистку часто идут по уже знакомому графику. Если очередь растёт медленно и очищается в нормальном темпе, нет причин переводить её в более дорогую burst-мощность.
Держите сервисы, чувствительные к задержкам, рядом с базой данных. Если API несколько раз обращается к базе в ходе одного запроса, расстояние имеет значение. Даже несколько лишних миллисекунд между cloud-инстансами и основным хранилищем данных могут превратить быструю страницу в вялую.
Хорошее правило простое: базовую нагрузку держите на bare metal, а в облако выносите только то, что можно добавить или убрать, не трогая основной путь данных. Так запуск не превращает всю систему в движущуюся цель.
Что лучше отправлять в облако
Начните с web- и API-серверов, которые не хранят состояние пользователя на самой машине. Если один экземпляр исчезнет, другой сможет принять тот же трафик. Это делает их самым безопасным первым кандидатом, когда запуск поднимает посещаемость в 5 или 10 раз выше нормы.
Workers очередей — ещё один простой и полезный вариант. Обработка изображений, отправка писем, импорт данных, генерация отчётов и AI-задачи могут поработать в облаке час, убрать накопившуюся очередь и потом снова выключиться. Часто достаточно простого триггера: если возраст очереди или её размер превысили лимит, добавьте cloud workers. Если одна задача занимает две минуты, а очередь внезапно выросла до 4000, у пользователей может сложиться впечатление, что всё сломалось, ещё до появления страницы ошибки.
Preview-окружения тоже хорошо подходят для burst-слоя во время крупных релизов. Командам продукта и QA могут понадобиться десятки временных окружений на несколько дней, а не на весь месяц. Платить за них только в релизную неделю обычно дешевле, чем держать лишний bare metal наполовину пустым.
Практичный первый burst-слой обычно включает web- и API-реплики за load balancer, workers для коротких фоновых задач, временные preview-окружения и batch-задачи, которые можно безопасно останавливать и запускать заново.
Стейтовые сервисы не стоит включать в первую волну, если вы заранее не продумали поток данных. Базы данных, файловое хранилище, session store и message broker могут ломаться неожиданно, когда меняется задержка или записи попадают не туда. Многие команды получают лучший результат, если оставляют базу данных на bare metal, а в облако выносят только слой приложения и пул workers.
Такой подход часто используют в lean operations: сложно переносимую основу оставляют стабильной, а эластичный трафик уходит наружу. Oleg Sotnikov применяет ту же логику в Fractional CTO работе на oleg.is: держать ядро стабильным и масштабировать stateless-край, когда спрос растёт.
Настройте правила трафика шаг за шагом
Используйте одну публичную точку входа, например nginx, Cloudflare или load balancer, и держите всю логику маршрутизации там. Если запросы могут приходить разными путями, failover быстро становится запутанным, и команда теряет понимание, куда идёт трафик.
Обычный трафик по умолчанию должен идти на bare metal. Именно отсюда и берётся более низкая базовая стоимость. Облачная сторона должна ждать в фоне, пока спрос не вырастет, а не сжигать деньги весь день.
Заранее, ещё до дня запуска, задайте overflow по точным цифрам. Хорошие триггеры — это CPU выше 70–80 процентов в течение нескольких минут, превышение заданного времени ожидания в очереди запросов или выход времени ответа за целевой показатель. Выберите два или три сигнала и сделайте их настолько простыми, чтобы каждый в команде мог понять их с первого взгляда.
Когда эти лимиты срабатывают, отправляйте в облако только лишний трафик. Новые запросы могут идти туда первыми, а работа, которая уже началась, остаётся там, где стартовала. Это уменьшает проблемы с сессиями и упрощает откат, если что-то выглядит странно.
Не ждите начала пика, чтобы создавать облачные мощности. Поднимите эти инстансы заранее, до публичного окна запуска, прогоните health checks, прогрейте кэши и убедитесь, что они могут достучаться до базы данных, файлового хранилища и workers, которые им нужны. Холодный burst-путь часто ломается в самый неподходящий момент.
Потом протестируйте всю схему. Смоделируйте трафик выше ожидаемого пика и посмотрите, переключается ли маршрутизация на заданном пороге. После этого уменьшите нагрузку и убедитесь, что система чисто возвращается на bare metal без зависших сессий, длинных очередей и недоделанных задач.
Ещё одно правило помогает при возврате обратно: снижайте нагрузку медленно. Если вы переведёте 30 процентов облачного трафика сразу в ноль, можно получить второй пик уже на bare metal-серверах. Переводите трафик маленькими шагами и продолжайте следить за временем очереди и временем ответа.
Команды часто усложняют это лишними деталями. На практике несколько понятных порогов и одна протестированная точка входа работают лучше, чем хитрые политики трафика, в которые никто не верит под давлением.
Держите под контролем данные, файлы и сессии
Гибридная схема ломается, когда каждая сторона хранит своё состояние. App-серверы могут работать на bare metal и burst-иться в облако, но сессии, загрузки и записи нуждаются в одном общем плане.
Начните с сессий. Если пользователь вошёл в систему на узле bare metal, а следующий запрос пришёл на cloud-узел, сессия всё равно должна существовать. Держите сессии в общем Redis или другом центральном хранилище. Не храните их в локальной памяти или на локальном диске, если не хотите случайных выходов из аккаунта во время пика.
Загрузки нужно обрабатывать так же. Если один узел сохраняет файлы только на свой диск, остальные серверы их не увидят. Храните пользовательские загрузки, сгенерированные отчёты и медиа в object storage, чтобы каждый узел видел одни и те же файлы. Это ещё и сильно упрощает масштабирование, потому что новым cloud-узлам не нужен job на синхронизацию файлов перед стартом работы.
Записи в базу требуют особого внимания. По возможности оставляйте один источник истины для записи. Обычно это значит одна primary database, чаще всего на стороне bare metal, если именно там живёт стабильная нагрузка. Для чтения можно добавить replicas ближе к cloud-узлам, но отправлять записи в несколько мест — это уже большой шаг к усложнению.
Именно задержка репликации часто ломает планы на запуск. Если cloud-узлы начнут обслуживать трафик до того, как реплики догонят основную базу, пользователи увидят устаревшие данные или сломанные действия. Задайте простое правило: cloud-узлы могут обслуживать в основном запросы на чтение только после того, как задержка репликации держится ниже лимита несколько минут.
Если cloud-сторона потеряет доступ к базе данных
Решите это ещё до дня запуска. Большинству команд стоит выбрать один понятный fallback: перестать отправлять трафик на cloud-узлы, показывать только кэшированные или read-only страницы, отключить действия на запись вроде входа или оплаты, либо показать временную ошибку и вернуть пользователей обратно на bare metal. Выберите один сценарий и отрепетируйте его.
Небольшой пример помогает увидеть суть. Если вы весь месяц держите три app-сервера на bare metal и добавляете четыре cloud-узла на запуск, все семь должны использовать один и тот же Redis, одно и то же object storage и одни и те же правила для базы данных. Это менее изящно, но ломается реже.
Следите за правильными метриками во время пика
Во время запуска CPU может выглядеть нормально, а пользователи всё равно будут ждать страницу шесть или восемь секунд. Время ответа показывает, что люди ощущают на самом деле, поэтому именно оно должно влиять на первые решения о масштабировании сильнее, чем сырая загрузка сервера.
Смотрите на медленный край распределения, а не только на среднее значение. Если signup, login, checkout или основные API-запросы становятся медленными у самых загруженных 5 процентов запросов, пользователи это уже замечают.
Глубина очереди тоже помогает заметить проблему раньше. Фоновые задачи часто отстают ещё до того, как падает основное приложение. Письма, импорты, обработка изображений, webhooks и отчёты могут незаметно накапливаться, а потом выливаться в задержки для клиентов.
Сделайте launch-dashboard достаточно маленьким, чтобы его можно было просмотреть за несколько секунд. Время ответа для загруженных страниц и endpoint-ов, уровень ошибок, неудачные health checks, глубина очереди, возраст самой старой задачи, медленные запросы к базе, число соединений и текущие расходы на облако — обычно этого хватает.
Задайте жёсткий облачный бюджет до начала события. Определите потолок, который вы готовы принять за день, а затем решите, что делать, когда расходы достигнут 50, 75 и 100 процентов. Команды, которые пропускают этот шаг, часто продолжают добавлять инстансы только потому, что трафик кажется срочным, а на следующее утро об этом жалеют.
Алерты по базе данных не менее важны, чем алерты по приложению. Несколько медленных запросов могут сделать и bare metal, и cloud-узлы слабыми на вид, хотя настоящая проблема — это одна таблица, один отсутствующий индекс или один шумный отчётный job.
Нужны и health checks. Если cloud-узлы поднялись, но не проходят проверку, autoscaling только увеличивает расходы. Запишите, кто может включать burst capacity, и кто её выключает. Одного ответственного и одного резервного человека достаточно. Правило должно быть простым: когда время ответа или возраст очереди превышает лимит, этот человек добавляет мощность. Когда трафик успокаивается и очереди очищаются, тот же человек уменьшает её обратно.
Если вы уже используете Grafana, Prometheus или Sentry, держите открытую одну launch-страницу. Короткая панель с понятными лимитами работает лучше, чем двадцать графиков, которые невозможно прочитать в стрессе.
Простой пример дня запуска
Небольшая SaaS-команда получает стабильный трафик каждый день, поэтому они запускают продукт на двух app-серверах bare metal. Этого хватает для обычной нагрузки при более низкой ежемесячной стоимости, и серверы достаточно загружены, чтобы оправдать расходы.
За неделю до запуска команда узнаёт, что упоминание в прессе может выйти в то же утро, что и обновление продукта. Они не переносят всё в облако. Это стоило бы дороже, чем нужно. Вместо этого они выносят в burst только шумный трафик у входа.
Они добавляют несколько cloud web-узлов и направляют их на страницы, которые обычно растут первыми: signup, login, docs и маркетинговые страницы. Это помогает сохранить стабильность основного продукта. Новые посетители могут читать docs, создавать аккаунты и входить в систему, не перегружая два основных сервера, которые обслуживают обычную клиентскую активность.
Основная база данных остаётся на bare metal. Команде нужен один источник истины, предсказуемая стоимость хранилища и отсутствие спешного переноса базы прямо перед запуском. Они используют общее cache и session data для обеих сред, поэтому пользователь, который зарегистрировался на cloud-узле, всё равно может попасть в приложение без сломанного состояния входа.
Утром в день запуска трафик быстро растёт. Cloud-узлы принимают волну новых посетителей, а bare metal-серверы продолжают обслуживать существующих клиентов и запросы приложения. Если один cloud-узел перегревается, команда запускает ещё один. Это занимает минуты, а не заказ нового железа.
К вечеру пик спадает. Команда уменьшает количество cloud-узлов и возвращается к дешёвой базовой схеме, которую использует каждый день. Они платят за дополнительное пространство только в короткое окно, когда оно действительно нужно.
Для запусков, email-рассылок и упоминаний в прессе этого часто достаточно. Стабильную нагрузку вы держите на контролируемом вами железе, а временный запас мощности арендуете только тогда, когда приходит внимание.
Ошибки, которые увеличивают расходы или ломают failover
Многие команды строят дешёвую базу на bare metal, а потом сами уничтожают экономию одной ошибкой: думают, что можно в последний момент перенести в облако вообще все части приложения. Так почти никогда не работает. Самые серьёзные сбои обычно начинаются со stateful-частей системы.
База данных — первая ловушка. Если burst-ятся app-серверы, но не база данных, cloud-инстансы могут половину времени ждать медленное соединение через сеть. Если же переносить и базу, нужна реальная схема репликации, проверенная под нагрузкой, с понятными правилами для записи, задержки и восстановления. Фраза «мы как-нибудь синхронизируем» — это не план.
Пользовательские сессии создают такую же проблему. Если каждый bare metal-сервер хранит сессии в локальной памяти, пользователь может войти на одной машине и выглядеть сломанным на другой. Храните сессии в общем хранилище, базе данных или cache, к которым могут обратиться обе стороны. Иначе failover превратится в случайные выходы из аккаунта и потерянные корзины.
Ещё одна распространённая ошибка — ждать полного отказа, прежде чем переводить трафик. К этому моменту очереди уже переполнены, таймауты распространяются, а cloud-сторона стартует холодной и под нагрузкой. Переводите трафик раньше — когда растёт задержка, увеличивается уровень ошибок или CPU несколько минут держится на максимуме. Ранний переход дешевле, чем спасательная операция.
Сюрпризы по стоимости обычно прячутся в исходящем трафике, в хранилище для снимков и логов, в репликации между зонами или регионами и в cloud-инстансах, которые забыли выключить после окончания пика.
Команды также пропускают единственный тест, который действительно важен: тренировку failover. Они проверяют резервные копии, проверяют масштабирование и считают, что остальное само заработает. Потом наступает день запуска, правила DNS запаздывают, health checks мигают, и одна забытая firewall rule блокирует весь путь.
Проведите одну спокойную репетицию и одну неприятную. В спокойном тесте переведите небольшую долю трафика и посмотрите на время ответа. В неприятном тесте уберите один узел, заставьте сессии переехать и убедитесь, что приложение всё ещё работает для вошедших пользователей. Если этот тест вызывает дискомфорт, значит, он выполняет свою работу.
Быстрые проверки перед днём запуска
Эта схема лучше всего работает, когда передача нагрузки проходит скучно и предсказуемо. Перед запуском убедитесь, что весь публичный трафик входит через одну стабильную точку. Один hostname и одна front door сильно упрощают маршрутизацию, когда нужно быстро добавить cloud-узлы.
Не считайте health checks нормальными только потому, что на прошлой неделе всё работало. Специально выключите один app-узел и посмотрите, что делает load balancer. Он должен быстро перестать отправлять туда трафик, не реагируя чрезмерно на короткий всплеск CPU или медленный прогрев.
Проверьте сессии и файлы по-настоящему. Войдите в систему на bare metal-узле, а затем заставьте следующий запрос прийти на cloud-узел. Загрузите файл, обновите страницу и откройте его снова с другой стороны. Если ломается вход или пропадают файлы, исправьте это до начала любой маркетинговой активности.
Храните runbook в одном месте и сделайте его достаточно коротким, чтобы им можно было пользоваться, когда люди устали. В нём должно быть написано, когда включать burst, сколько облачных расходов вы допускаете, кто может это одобрить и как именно откатиться, если дополнительная мощность создаёт проблемы.
Есть и последнее правило, которое важнее, чем многие думают. В день запуска решение должен принимать один конкретный человек. Это не значит, что он делает всю работу. Это значит, что именно он решает, когда включать burst, когда останавливать расходы и когда делать откат. Без такого владельца команда теряет время в чате, пока уровень ошибок растёт.
Если нужен ещё один последний контроль, смоделируйте небольшой пик за час до запуска. Дайте немного больше трафика, посмотрите, как подключаются первые cloud-узлы, и убедитесь, что пользователи остаются в системе, пока запросы переходят между средами. Эта короткая репетиция часто ловит одну проблему, которая могла бы испортить весь день.
Следующие шаги для lean-гибридной схемы
Большинству команд стоит начинать меньше, чем им кажется. Выберите один сервис со стабильным трафиком и понятными пиками, например web-tier, background worker или signup API. Базу данных и всё остальное не трогайте, пока первый burst не заработает чисто.
Lean-план выигрывает тогда, когда его несложно обслуживать. Если команда не может объяснить шаги failover за одну минуту, схема слишком сложная. Особенно это важно в 2 часа ночи, когда кому-то нужно быстро действовать.
Начните с того, что запишите пять решений: какой сервис первым переезжает на cloud-узлы, какое число запускает burst, какое число его завершает, как трафик возвращается после пика и какой дневной или недельный лимит расходов вы не готовы превышать.
Потом дождитесь одного настоящего события. Запуск, кампания или релиз продукта покажут вам больше, чем недели догадок. Замерьте, когда burst начался, как долго cloud-узлы оставались включёнными, видели ли пользователи медленные страницы и сколько стоила дополнительная мощность. После события скорректируйте триггеры. Чаще всего команды ставят их слишком рано и платят за пустое облачное время, либо слишком поздно и пропускают первую волну трафика.
Сохраняйте operating model простым: одна панель, один путь оповещения, один человек на связи. Короткий runbook всегда лучше длинного design doc.
Если перед запуском вам нужен второй взгляд, Oleg Sotnikov на oleg.is помогает стартапам и небольшим компаниям с Fractional CTO работой, планированием инфраструктуры и практичным контролем расходов. Иногда короткого разбора достаточно, чтобы увидеть перерасход ещё до добавления новых серверов.
Следующий шаг обычно не в полном перестроении. Обычно это один контролируемый burst, хорошо измеренный, со схемой, которой команда всё ещё доверяет, когда все устали.
Часто задаваемые вопросы
Когда имеет смысл схема bare metal плюс cloud burst?
Используйте такую схему, если у продукта есть стабильная базовая нагрузка и короткие пики во время запусков, кампаний или упоминаний в прессе. Обычную нагрузку держите на bare metal, чтобы был ниже фиксированный расход, а облачную мощность арендуйте только на период высокой активности.
Что стоит оставить на bare metal?
На bare metal лучше оставить всё, что работает весь день и меняется медленно. Обычно это обычные app-серверы, основная база данных и фоновые задачи с предсказуемой нагрузкой.
Что первым переводить в облако во время пика?
Сначала переносите stateless web-серверы, API-реплики и workers для очередей. Они быстро поднимаются, принимают дополнительный трафик и спокойно выключаются после окончания пика.
Нужно ли переносить базу данных в облако к дню запуска?
Обычно нет. Лучше оставить один путь записи и один источник истины, если только вы уже не тестировали репликацию, допустимую задержку и восстановление под нагрузкой. У большинства команд безопаснее оставить базу данных на bare metal и сначала масштабировать слой приложения.
Как работать с сессиями и файлами в обеих средах?
Храните сессии в общем Redis или другом центральном хранилище, а загрузки — в object storage, к которому могут обратиться все узлы. Если у каждого сервера свои сессии или свои файлы, пользователи будут сталкиваться со случайными выходами из аккаунта и пропавшими загрузками при смене трафика.
Какие метрики должны включать burst capacity?
Смотрите прежде всего на то, что чувствует пользователь. Время ответа, возраст очереди, уровень ошибок и сбойные health checks обычно говорят больше, чем один только CPU. До запуска задайте простые пределы и используйте одни и те же правила каждый раз.
Как рано запускать облачные инстансы перед запуском?
Поднимайте cloud-узлы до окна публичного запуска, а не после начала пика. Дайте им время пройти health checks, прогреть кэши и убедиться, что есть доступ к базе данных, Redis и хранилищу.
Как вернуть трафик обратно на bare metal после пика?
Снижайте нагрузку небольшими шагами. Постепенно переводите трафик обратно, следите за временем ответа и возрастом очереди и выключайте узлы только после того, как нагрузка снова станет нормальной. Слишком резкий возврат может создать второй пик уже на bare metal.
Какие ошибки чаще всего ломают failover или раздувают счёт?
Команды часто слишком поздно начинают масштабирование, хранят сессии в локальной памяти или игнорируют задержку базы данных через сеть. Счёт в облаке также растёт, когда забывают про трафик на выход, логи, снимки и оставшиеся включёнными после события инстансы.
Может ли небольшая команда управлять этим без лишней сложности?
Да, если держать схему простой. Используйте один вход, один короткий runbook, одну небольшую панель и одного ответственного за решения в день запуска. Начните с одного сервиса, протестируйте его и не трогайте остальное, пока первый burst не заработает чисто.


