Воспроизведение трафика перед переносом инфраструктуры: что тестировать
Воспроизведение трафика позволяет прогнать реальный паттерн запросов в новом окружении перед переносом, чтобы заранее заметить проблемы с кешем, аутентификацией и лимитами.
Содержание
Почему переносы ломаются по мелочам
Большинство переносов инфраструктуры дают сбои на краях, а не в очевидных местах. Приложение всё ещё стартует, база данных отвечает, health check остаются зелёными. Пользователи замечают что-то меньшее: страница загружается медленнее, вход отправляет их обратно на форму авторизации, или API-вызов отклоняется без понятной причины.
Кеши создают много таких проблем. При смене хоста, прокси, CDN или DNS часто меняется то, как группируются запросы и как хранится ответ. Кеш, который работал в старой настройке, может начать слишком часто промахиваться, хранить неправильную версию или перестать кешировать из‑за изменения одного заголовка. Добавьте пару сотен миллисекунд к каждому запросу — и пользователи это почувствуют быстро.
Проблемы с аутентификацией часто начинаются так же. Cookie зависят от точных правил домена, пути, флагов безопасности и поведения между сайтами. Перенос может случайно изменить любой из этих параметров. Заголовки тоже могут исчезнуть или переписаться, когда новый прокси вставляется перед приложением. В результате пользователи входят, но на следующей странице оказываются разлогиненными, или внутренний API начинает возвращать 401, хотя код приложения не менялся.
Лимиты запросов создают другой тип сюрпризов. В старой настройке трафик мог приходить с множества IP клиентов. В новой — прокси или шлюз могут делать так, что запросы выглядят пришедшими от меньшего числа источников. Это меняет способ подсчёта трафика. Лимиты, которые раньше казались безопасными, срабатывают намного быстрее, особенно на эндпоинтах входа, поиска или публичных API.
Эти проблемы обычно проявляются в циклах входа, медленных страницах после промахов кеша, блокируемых API‑запросах или случайных всплесках 429 и 403.
Небольшое несовпадение в заголовках, области cookie или маршрутизации запросов может запустить всё это. Именно поэтому до переноса важен traffic replay. Он проверяет те шаблоны, которые ваши пользователи создают каждый день, вместо надежды на аккуратные тест-кейсы, пропускающие «грязные» детали.
Что делает traffic replay
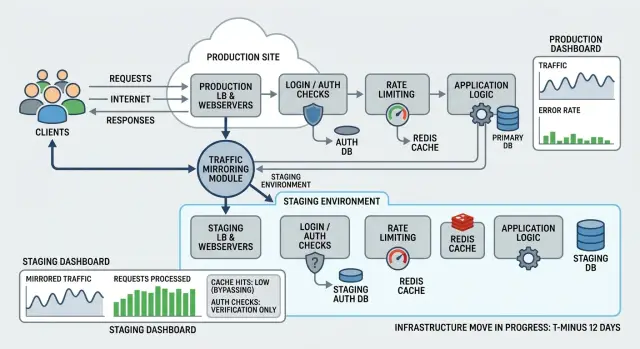
Traffic replay копирует реальные production‑запросы и отправляет их в отдельное окружение, пока production продолжает обслуживать пользователей. Живая система остаётся источником правды для ответов. Копия для реплея существует только для тестирования.
Это звучит просто, но меняет качество проверки. Синтетические проверки обычно покрывают счастливые сценарии. Реальный трафик несёт с собой странности: старые cookie, повторы мобильного приложения, отсутствующие заголовки, необычные query‑строки и запросы, приходящие всплесками в неудачное время.
Когда вы зеркалируете эти запросы в новую инфраструктуру, вы видите, как она ведёт себя под шаблонами, которые уже создают ваши пользователи. Вы можете сравнивать коды состояния, тайминги, поведение кеша, логи и уровень ошибок без риска для реальных пользователей.
Здесь traffic replay окупает себя. Часто он находит проблемы, которые пропускают базовые проверки на staging:
- правила кеша, которые кажутся правильными, пока редкий URL их не обходят
- проверки аутентификации, которые падают для старых токенов или непривычных потоков сессий
- настройки лимитов, которые блокируют нормальное поведение повторных попыток
- маршруты, заголовки или фоновые вызовы, которые никто не включил в план переноса
Он также показывает, справляется ли новое окружение с обычными и странными путями одинаково последовательно. Сервис может пройти десять чистых запросов в тесте и провалиться, когда реальный клиент пошлёт дубликаты запросов, устаревшие сессии или полезную нагрузку от старой версии приложения.
Replay не доказывает, что новое окружение идеально. Он помогает найти пробелы до того, как до них доберутся реальные пользователи. Это лучшая цель. Если зеркалирование выявит 2% отказов на запросах с истёкшими кеш‑записями, вы исправите это сейчас, а не узнаете о проблеме в ночь переноса.
При разумном использовании зеркалирование производственных запросов превращает живой трафик в генеральную репетицию. Production остаётся в безопасности, но тест становится гораздо честнее.
Настройте цель так, чтобы она не навредила пользователям
Цель реплея должна вести себя как production в тех областях, которые вы хотите проверить, но никогда не должна затрагивать реальных пользователей, реальные деньги или реальных участников-сторонних сервисов. Если реплеированный запрос пытается снять деньги, отправить письмо или пуш — цель должна это всегда блокировать.
Начните с жёстких блокировок всего, что вызывает побочные эффекты. Простое правило: чтение обычно безопасно, запись требует осторожности.
Отключите платежи, email, SMS, чаты и доставку вебхуков. Направляйте внешние API‑вызовы на тестовые аккаунты, sandbox‑эндпоинты или локальные заглушки. По возможности маскируйте персональные данные — особенно email, телефоны и токены. Держите логи реплея отдельно, чтобы production‑логи оставались чистыми.
Вызовы третьих сторон создают много проблем при реплее. Staging‑приложение может хранить живой API‑ключ, или фоновый воркер может отправлять события после завершения основного запроса. Проверьте и путь запроса, и асинхронные задачи за ним. Если приложение общается со Stripe, Twilio, Slack или провайдером email, убедитесь, что все эти пути указывают только на тестовые системы.
Маскируйте данные аккуратно. Вам всё ещё нужны реалистичные формы запросов, поэтому по возможности сохраняйте форматы полей. Поддельный email вроде [email protected] лучше, чем полное удаление поля. Так проверки аутентификации, поведение кеша и правила валидации остаются реалистичными.
Держите логи реплея отдельно от production‑метрик. Если смешать их, дашборды станут шумными, правила оповещений сработают по ложным поводам, и отладка быстро превратится в хаос. Дайте трафику реплея отдельный поток логов, собственные теги и, по возможности, отдельный проект для трекинга ошибок.
Реплей checkout показывает риск особенно наглядно. Если в цели остались живые платёжные настройки, один зеркалированный запрос может инициировать реальную попытку списания. Если остались живые настройки почты — тот же запрос может отправить дубликат квитанции. Хорошая изоляция предотвратит оба этих случая, прежде чем тест переноса превратится в инцидент.
Выберите запросы, которые стоит воспроизводить
Не начинайте с зеркалирования всего подряд. Начните с запросов, которые смешивают состояние пользователя, права доступа, кеширование и тайминг. Обычно именно они ломаются первыми при переносе инфраструктуры.
Потоки входа в систему должны быть в верхней части списка. Воспроизведённый вход может обнаружить проблемы с областями cookie, отсутствующие заголовки, баги обновления токенов и рассинхронизацию времени между сервисами. Поиск — ещё один сильный кандидат, потому что он затрагивает индексы, фильтры, кеши и лимиты запросов одновременно.
Пути оформления заказа требуют особого внимания, даже если вы реплеите их в безопасном режиме. Они собирают вместе цены, остатки, налоговые правила, сессии пользователей и внешние вызовы. Запросы записи через API тоже важны — особенно те, которые сохраняют профили, корзины, настройки или черновики. Такие запросы в логах выглядят нормально, но могут тихо падать на валидации, правах или таймаутах базы.
Страницы, сильно зависящие от кеша, стоит воспроизводить, даже если они кажутся простыми. Главная страница, страница товара, дашборд или результаты поиска могут вести себя очень по‑разному при изменении заголовков кеша, правил CDN или общей сессионной информации. Важны и фоновые коллбэки: потребители очередей, вебхуки и внутренняя логика часто зависят от заголовков, повторных попыток или IP‑правил, которые staging может не воспроизводить.
Хорошая выборка включает и обычный путь, и «неприятный» путь. Воспроизведите обычный вход, но также и вход с истёкшей сессией. Обычный поиск — и поиск с фильтрами, странными символами и без результатов. Оформление заказа для стандартного заказа, затем купон, большая корзина и пользователь, вернувшийся после таймаута.
Пропускайте эндпоинты, которые могут создать реальные побочные эффекты. Не реплейте живые захваты платежей, создание отправлений, отправку писем, SMS, обновление инвентаря или коллбэки партнёров против реальных систем. Маршрутизируйте такие запросы в моки, убирайте опасные части или заменяйте безопасными двойниками.
Если у вас мало времени, выберите потоки, которые приносят деньги, контролируют доступ или изменяют данные. Небольшой набор таких потоков обычно находит больше реальных проблем, чем огромный дамп низко‑рисковых запросов.
Как запускать — пошагово
Начните с малого. Маленькая выборка живых запросов говорит больше, чем полный синтетический тест, и её гораздо проще анализировать при ошибке.
Выберите узкую группу сначала, например анонимные GET‑запросы для пары загруженных эндпоинтов. Избегайте входа, checkout, записей и всего, что может создать или изменить пользовательские данные, пока цель не докажет, что с простым трафиком справляется чисто.
Практический первый запуск выглядит так:
- Захватите небольшой процент реальных запросов, часто 1% или меньше.
- Отправьте зеркальную копию в новую среду с жёсткими лимитами скорости.
- Сохраните оба ответа, чтобы сравнить их напрямую.
- Сгруппируйте рассогласования по типам до того, как начнёте исправлять что‑то.
- Увеличивайте объём только после стабилизации показателей.
Держите реплей намеренно медленным. Traffic replay в первый день — это не стресс‑тест. Вам нужны чёткие сигналы, а не шумная лавина ошибок, скрывающая первую реальную проблему.
Сравнивайте не только коды состояния. Две системы могут обе вернуть 200, но всё ещё вести себя по‑разному. Проверьте задержку, заголовки кеша, заголовки аутентификации, размер ответа, поведение редиректов и уровень ошибок. Если на одной стороне 80 мс, а на другой 900 мс, этот разрыв важен ещё до жалоб пользователей.
Когда вы находите проблемы, исправляйте по классам. Если падает аутентификация, приостановите работу с кеш‑ошибками и шумом лимитов, пока аутентификация не станет стабильной. Смешанные ошибки тратят время, потому что каждый новый прогон теста даёт новую кашу результатов.
Простой ритм работает хорошо. Запустите маленький реплей на 15–30 минут, просмотрите расхождения, разложите их по кешу, аутентификации, маршрутизации и лимитам, исправьте одну группу и запустите тот же срез ещё раз. Увеличивайте трафик только если результаты остаются чистыми.
Будьте строги при увеличении. Если 1% выглядит хорошо в полном тестовом окне, переходите к 5%, затем к 10%. Если после увеличения ошибки прыгают — откатывайтесь до последнего чистого уровня и исследуйте изменение. Это обычно показывает реальный предел быстрее, чем догадки.
Следите особенно за кешем, аутентификацией и лимитами
Большинство плохих переносов начинаются с мелких ошибок, а не с полного краха. Пользователи видят медленные страницы, случайные разлогины или короткие всплески 429 задолго до объявления инцидента.
С помощью replay следите сначала за самыми загруженными эндпоинтами. Сравните паттерны попаданий и промахов кеша между текущей и новой стеком. Страница может по‑прежнему возвращать 200, но при этом выполнять гораздо больше работы, если изменилось поведение кеша. Это обычно проявляется как более высокая нагрузка на базу, длинные «хвостовые» задержки и ухудшение нескольких маршрутов под давлением.
Загруженные эндпоинты чтения требуют дополнительного внимания. Поиск, каталог, дашборды и публичные чтения API часто выглядят здоровыми в лёгких тестах, а затем разваливаются, когда промахи кеша накапливаются. Если в новом окружении другие ключи кеша, TTL или прокси‑заголовки, вы можете промахиваться намного чаще, чем раньше.
Аутентификация требует полноценной трассировки запроса за запросом. Начните с первой анонимной загрузки страницы, затем запрос входа, создание сессии или токена, первый аутентифицированный вызов и последующее обновление сессии. Не останавливайтесь на «вход сработал». Многие проблемы с аутентификацией проявляются через 10–20 минут, когда попытка обновления сессии падает.
Небольшие различия в запросах создают много боли:
- прокси удаляет или переписывает пересылаемые заголовки
- secure cookie получает неправильный домен или путь
- приложение видит http вместо https
- лимитер группирует много пользователей под одним IP
- бэкенд отвергает заголовок, который старый стек пропускал
Считайте коды состояния по маршрутам и состоянию пользователя. Следите за 401 и 403 до входа и после входа. Если их число растёт в новом окружении, приложение, возможно, больше не доверяет тем же cookie, токенам или заголовкам.
Следите также за 429 и 5xx. Всплеск 429 часто означает, что лимитер теперь по‑другому определяет клиента. Всплеск 5xx после промахов кеша обычно указывает на нагрузку на бэкенд, а не на случайный баг.
Один простой пример объясняет полезность replay. Если старый прокси отправлял X-Forwarded-Proto: https, а новый — нет, приложение может неправильно выставлять cookie. Вход сработает один раз, но следующий аутентифицированный запрос упадёт. Реплей поймает это до появления проблем у пользователей.
Простой пример
Небольшая SaaS‑команда планирует поставить API за новый прокси. На бумаге приложение выглядит просто: пользователи входят, загружают дашборд и фоновые API‑вызовы идут ровным потоком. Команда поднимает отдельную целевую среду и прогоняет по ней реплей, пока реальные пользователи работают со старым стеком.
Сначала реплей выглядит нормально. Публичные страницы быстро грузятся, данные о продуктах возвращаются, кешированные ответы совпадают с ожиданиями. Если бы они остановились на этом, могли бы подумать, что перенос безопасен.
Потом они проверяют вход. Первый запрос после входа работает, но через несколько минут падает вызов обновления токена. Пользователи этого не заметили бы сразу: они вошли, покликали немного, а затем их выкидывает, когда сессия пытается обновиться.
Реплей делает баг видимым, потому что паттерн повторяется. Новый прокси пересылает запрос, но по‑иному обрабатывает область cookie. Одна cookie остаётся привязанной к правилам старого домена, и endpoint обновления никогда не получает необходимых данных. Команда исправляет настройки cookie до переключения и снова прогоняет тот же трафик, пока обновление не заработает постоянно.
Второй вопрос всплывает с лимитами. Старая настройка считала запросы по идентичности клиента так, как это соответствовало реальным пользователям. Новый прокси группирует слишком много запросов под одним общим IP. В тесте с несколькими вызовами это выглядит безобидно, но реплей реального трафика показывает иную картину. Загруженные офисные сети и мобильные операторы внезапно выглядят как один шумный клиент, и прокси начинает возвращать 429.
Команда меняет правила лимитов, чтобы использовать более подходящий идентификатор, и добавляет исключение для доверенных внутренних путей. После этого кешированные страницы снова работают, обновление входа стабильно, и обычные всплески перестают триггерить лимитер.
Именно поэтому зеркалирование production‑запросов так хорошо работает: оно ловит проблемы, которые проявляются только при реальном тайминге запросов, cookie и форме трафика.
Ошибки, скрывающие реальные проблемы
Реплей может выглядеть чистым и при этом мало о чём говорить. Команды часто запускают реплей, видят много 200 и предполагают, что перенос безопасен. Потом происходит cutover, сессии слишком часто истекают, коэффициенты попаданий в кеш падают, или лимитер начинает блокировать нормальных пользователей.
Одна распространённая ошибка — реплей только GET‑запросов. Это кажется безопаснее, но исключает запросы, которые обычно показывают худшие проблемы. Записи задействуют очереди, блокировки, лимиты базы, фоновые задачи и проверки прав. Пропуская их все, вы теряете те места, где новое окружение ведёт себя иначе. Не нужно реплейить опасные действия против живых систем, но нужны безопасные подстановки, которые проходят по тем же путям кода.
Время суток важнее, чем многие предполагают. Ночной трафик часто спокойнее, предсказуемее и менее смешан. Тест в 2:00 ночи может никогда не вызвать всплески, которые заполняют кеши, запускают потоки обновления сессий или триггерят лимиты. Если у вашего продукта есть дневной пик, синхронизации в конце дня или пиковые входы по понедельникам — тестируйте в эти окна.
Ещё одна ловушка — смотреть только на процент успешных ответов. Даже если 99.9% запросов идут успешно, самые медленные 5% могут стать гораздо медленнее, и пользователи это ощутят сразу. Сравнивайте времена ответа, промахи кеша, ошибки аутентификации и объём повторов. Перенос может сохранить ту же ошибочную статистику, но при этом сделать приложение неудобным.
Самая опасная ошибка — позволить реплей‑трафику вызывать реальные побочные эффекты. Тест никогда не должен отправлять письма клиентам, снимать деньги с карт, создавать дубликаты заказов или шлёпать вебхуки партнёрам. Поставьте жёсткие блоки перед стартом: маршрутизируйте исходящие вызовы в фейки, отключите платёжные действия и помечайте реплей‑запросы, чтобы downstream‑сервисы могли их игнорировать.
Если хотите честных результатов, делайте тест реалистичным там, где это важно, и фейковым там, где он может навредить людям. Такой баланс обнаружит проблемы рано и не создаст новых.
Быстрые проверки перед переносом
Перенос обычно ломается в обычных местах первым. Токены входа истекают слишком скоро, кешированные страницы остаются устаревшими, повторы триггерят лимиты, или наблюдаемость смешивает реплей‑трафик с реальным.
Пройдите короткий прогон перед переключением. Traffic replay полезен, но только если вы проверяете части, которые пользователи заметят в первые минуты.
- Начните с чистой сессии в браузере: полный вход, несколько обычных действий, обновление страницы, пауза и выход. Сессии, обновления токенов и выход часто ломаются после изменений прокси или домена.
- Измените данные, которые должны появиться на кешированной странице, затем перезагрузите эту страницу в другом окне или под другим аккаунтом. Если старое значение остаётся видно слишком долго — правила инвалидирования кеша не совпадают с новым стеком.
- Форсируйте повтор для одного‑двух медленных запросов. Смотрите на
429, повторные фоновые задания или дублированные записи. Повтор не должен создавать второй счёт, отправлять двойное письмо или ставить ту же задачу в очередь дважды. - Помечайте реплеированные запросы, чтобы логи, трейсинг и оповещения ясно их показывали. Если команда не может отличить зеркалированный трафик от реального за пару секунд, отладка станет хаотичной во время переноса.
- Держите новый стек на ожидаемой нагрузке не один всплеск, а дольше. CPU, память, подключения к базе, глубина очередей и уровень ошибок должны выравниваться, а не постоянно расти.
Небольшой пример упрощает оценку. Пользователь входит, открывает страницу аккаунта, меняет поле профиля, обновляет страницу и видит старое значение, потому что кеш не очистился. Затем браузер повторяет медленный запрос сохранения, а API отвечает 429, хотя нормальный трафик был бы в пределах лимита. Обе эти проблемы по‑отдельности выглядят мелкими; при реальном cutover они быстро превратятся в тикеты поддержки.
Если команда маленькая, держите прогон коротким и строгим. Один чистый поток аутентификации, один тест изменения кеша, один тест повтора, одна проверка наблюдаемости и краткий устойчивый прогон нагрузки поймают многое. Если что‑то не проходит — исправляйте до переноса.
Что делать дальше
Оформите результаты реплея в короткий письменный отчёт, пока детали ещё свежи. Зафиксируйте каждый разрыв, что его вызвало, как часто он возникал и что вы изменили для исправления. Делайте записи практичными. Если проблема влияет на вход, кеш, квоты API или биллинг — относите её к blocker'ам переноса, пока команда не подтвердит исправление.
Затем запускайте replay снова после каждого изменения конфигурации. Маленькие правки часто вызывают следующую проблему. Правило кеша может скрыть заголовок, изменение аутентификации — задействовать лимит, новая IP‑правила — ломать внутренние вызовы. Команды попадают в беду, когда тестируют один раз, продолжают менять настройки и предполагают, что прежний результат всё ещё в силе.
Перед cutover зафиксируйте несколько решений и запишите их:
- точное окно переключения
- правила отката и триггеры для их применения
- ответственный на связи, который может быстро принимать решения
- какие логи и дашборды команда будет смотреть в первый час
Держите план настолько коротким, чтобы любой участник мог прочитать его за минуту. Во время переноса скорость важнее отшлифованного документа.
Отсортируйте оставшиеся проблемы по влиянию на пользователя. Неправильный заголовок кеша может замедлять страницы или увеличивать расходы. Сломанное обновление токена может блокировать людей. Исправляйте в первую очередь то, что ломает доступ, портит состояние или вызывает шумную троттлинговую активность. Косметические несоответствия можно отложить.
Если хотите второй взгляд перед переносом, Oleg Sotnikov на oleg.is предлагает услуги Fractional CTO и консультирование стартапов по планированию миграций, проверке инфраструктуры и подготовке к cutover. Короткий внешний аудит дизайна реплея, безопасных целей тестирования, потоков аутентификации, поведения кеша и лимитов может обойтись дешевле одной плохой ночи переноса.
Часто задаваемые вопросы
Что такое traffic replay?
Traffic replay копирует реальные запросы из production и отправляет их в отдельную тестовую среду, пока живая система продолжает обслуживать пользователей. Это позволяет заранее заметить проблемы с кешем, аутентификацией, маршрутизацией и лимитами запросов до переключения.
Почему traffic replay лучше простых тестов на staging?
Тесты на staging обычно проверяют аккуратные, ожидаемые сценарии. Реальный трафик приносит старые cookie, странные заголовки, повторы и резкие всплески, которые простые тесты часто пропускают.
Может ли traffic replay навредить реальным пользователям?
Да, если цель не изолирована должным образом. Блокируйте платежи, email, SMS, вебхуки и другие операции записи, чтобы реплеи никогда не затрагивали реальных пользователей или внешних провайдеров.
Какие запросы стоит воспроизводить в первую очередь?
Начните с нагрузочных путей чтения: публичные страницы, дашборды, поиск и чтения API. Затем проверьте вход, обновление токена и безопасные варианты операций записи, важных для дохода или доступа к аккаунту.
Стоит ли воспроизводить запросы на оплату, email или платежи?
Нет — не против живых систем. Направляйте такие вызовы в песочницы, моки или заглушки, чтобы пройти по тому же коду, но не снимать деньги и не отправлять письма.
Сколько трафика следует зеркалировать вначале?
Начните с очень маленькой доли, часто 1% или меньше, и примените строгие лимиты скорости. Увеличивайте долю только после того, как выбранное окно теста остаётся чистым на текущем уровне.
Что сравнивать кроме кодов состояния?
Смотрите на задержки, редиректы, размер ответа, заголовки кеша, заголовки аутентификации и показатели ошибок по маршруту. Два ответа могут оба возвращать 200, но вести себя по-разному для пользователей.
Как поймать проблемы с входом и сессиями до переноса?
Проследите полный поток: от первой анонимной загрузки страницы до входа, первого аутентифицированного вызова, периода бездействия и обновления токена. Многие ошибки аутентификации проявляются позже, при попытке обновить сессию.
Почему кеши и лимиты часто ломаются после переноса инфраструктуры?
Изменение прокси или CDN может поменять ключи кеша, заголовки пересылки, обработку IP клиентов или область видимости cookie. Это приводит к пропускам кеша, неожиданным 401 и всплескам 429.
Что нужно проверить прямо перед cutover?
Запустите короткий, строгий прогон перед переключением. Проверьте вход, обновление закэшированных данных, путь повтора запросов, корректную маркировку реплеев в логах и устойчивость под ожидаемой нагрузкой; если что-то падает — фиксируйте до cutover.


