Контроль качества кода с ИИ, который ловит риски до релиза
Ворота качества кода с ИИ сокращают плохие релизы — добавьте тесты, линтинг, проверки зависимостей и явное ручное подтверждение перед релизом.
Содержание
Почему неконтролируемый код от ИИ опасен
Инструменты ИИ могут сгенерировать код, который выглядит завершённым, но ещё не безопасен. Имена аккуратные, структура — чистая, а комментарии звучат уверенно. Эта внешняя полировка может ввести в заблуждение плотный по времени состав команды.
Проблема проста: код может читаться хорошо и при этом ломать продукт. Функция проходит обычные сценарии и падает на крайних случаях. Запрос быстро возвращает данные и при этом раскрывает записи, которые пользователь не должен видеть. Платёжный поток может выглядеть нормально на демо, а затем списать неправильную сумму при использовании купона, повторе попытки или падении webhook'а.
Малые команды чувствуют это первыми. Когда два‑три человека одновременно занимаются продуктом, поддержкой и релизами, быстрый результат кажется спасением. Если ИИ пишет фичу за минуты, возникает искушение вмержить и двигаться дальше. Часто именно там и начинаются проблемы.
ИИ делает слабый код правдоподобным. Люди доверяют тому, что кажется знакомым. Они пролистывают pull request, видят, что всё компилируется, и предполагают, что все сложные решения уже приняты. Это не так.
Ущерб обычно попадает в части продукта, которые пользователи сразу замечают: биллинг, доступ к аккаунту, флоу регистрации, права админа и фоновые задания, работающие с данными клиентов. Это не редкие крайние случаи — это нормальные части реального продукта. Одна неверная проверка, одно упущенное условие или рискованный пакет могут превратить маленький merge в проблему для поддержки.
Именно поэтому нужны ворота качества. Они не созданы, чтобы тормозить каждый релиз. Это контрольные точки, где команда оценивает риск до того, как продакшн получит удар. Хорошие команды не доверяют коду просто потому, что он звучит правильно. Они доверяют ему после нескольких явных проверок и человеческого решения, что достаточно безопасно для релиза.
Если ваш стартап использует ИИ, чтобы двигаться быстрее, это нормально. Скорость помогает. Слепая скорость дорого обходится. Десятиминутный ревью перед релизом дешевле, чем выходные, потраченные на исправление сломанных регистраций, возврат денег и объяснения утечки данных клиентам.
Как выглядит ворота качества
Ворота качества — это правило, которое код должен пройти перед тем, как двигаться дальше. Результат должен быть однозначным: прошло или не прошло. Если люди спорят каждый раз, значит правило слишком расплывчатое.
Лучшие ворота преднамеренно просты. Они убирают домыслы, ловят распространённые ошибки рано и не дают рискованным изменениям проникнуть в продакшн только потому, что их сгенерировал инструмент.
Стандарт должен быть одинаков для всех. Код, написанный разработчиком, и код, сгенерированный ИИ, должны проходить одни и те же тесты, линты и путь ревью. Если AI‑код получает более лёгкий путь, команда начнёт доверять скорости вместо доказательств.
Большинство проверок должно выполняться автоматически. Компьютеры хорошо проверяют, прошли ли тесты, есть ли ошибки стиля или известные уязвимости в зависимостях. Люди лучше оценивают, соответствует ли изменение продуктовой логике, имеет ли смысл логика и приемлем ли риск.
Практичная настройка обычно небольшая и строгая. Набор тестов проходит в CI. Линтер не показывает блокирующих проблем. Новые зависимости соответствуют политике безопасности команды. Ревьюер одобряет изменения, затрагивающие чувствительные области: аутентификацию, биллинг или удаление данных.
Каждое правило должно оставаться бинарным. «В целом нормально» — это не ворота. «Выглядит ок для меня» — тоже нет.
Короткие наборы правил работают лучше, чем длинные политики. Команда может следовать четырём‑пяти правилам каждый день. 30‑пунктовый чеклист быстро становится фоном, особенно когда давит необходимость выпустить релиз.
Это особенно важно, когда команды часто полагаются на ИИ. Сгенерированный код может выглядеть чистым и при этом пропускать крайний случай, подтянуть неправильный пакет или незаметно сломать старый путь. Чёткие ворота ограничивают этот риск, не замедляя каждый релиз.
Если правило вызывает постоянные споры, перепишите его. Если правило никогда ничего не ловит — уберите его или снизьте его стоимость. Лучшие ворота легко запомнить, просто автоматизировать и трудно обойти случайно.
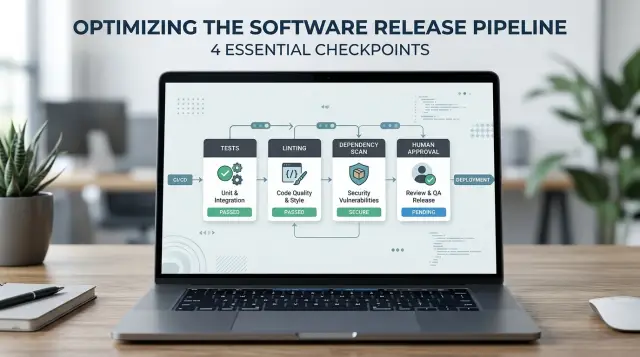
Первые четыре ворота
Начните с четырёх проверок, а не с десяти. Небольшая команда может держать процесс простым и при этом значительно снизить риск.
- Запускайте тесты по изменённому пути. Если ИИ правит логику биллинга — тестируйте биллинг. Если меняется логин — тестируйте аутентификацию и сессии. Не нужен огромный набор тестов в первый день, но нужна реальная проверка вокруг изменённого потока.
- Запускайте линтинг и форматирование на каждом изменении. Это ловит неаккуратности: неиспользуемые переменные, сломанные импорты, странный синтаксис и несогласованный стиль. Это также ускоряет ревью, потому что diff становится читаемее.
- Сканируйте новые или обновлённые пакеты. Проверяйте известные уязвимости и лицензионные проблемы до того, как пакет попадёт в продакшн. Одна небрежная зависимость может создать больше риска, чем сам сгенерированный код.
- Требуйте именованного ревьюера для рискованных изменений. Всё, что касается платежей, аутентификации, удаления данных, публичных API или инфраструктуры, должно ждать ручного согласования. Назначьте конкретного человека, а не общую фразу «команда одобрила».
Эти четыре ворота работают лучше при простом правиле: если хотя бы одно не проходит, деплой останавливается. Не пропускайте предупреждение, потому что релиз кажется маленьким. Маленькие изменения ломают реальные системы каждую неделю.
Команды, которые работают с Oleg Sotnikov, часто сначала нуждаются в таком простом контроле, особенно когда ИИ ускоряет выпуск быстрее, чем навыки ревью успевают адаптироваться. Стартап может сгенерировать пять pull request'ов за одно послеобеденное время. Без ворот эта скорость превращается в работу по очистке.
Сделайте первую версию быстрой. Прогон тестов за несколько минут будет использоваться. Чеклист ревью с трёх‑четырёх вопросов будет прочитан. Не нужна идеальная безопасность — нужен процесс, который ловит распространённые ошибки до пользователей.
Как настроить поток
Начните с закрытия самых простых путей к ошибкам. Защитите основную ветку, чтобы никто не мог запушить туда напрямую. Каждое изменение должно проходить через pull request, даже если команда маленькая и движется быстро.
Это правило решает две задачи одновременно. Оно даёт одно место для запуска проверок и делает ревью частью нормальной работы, а не последней минутой.
Установите фиксированный порядок, чтобы люди не угадывали, что будет дальше. Разработчик открывает pull request вместо пуша в main. CI запускает тесты и линт на каждом PR. Если изменение обновляет пакет или lock‑файл, CI также запускает скан зависимостей. Сливаете только после того, как все проверки пройдены и ревьюер одобрил изменение.
Это работает, потому что большинство низкорискованных изменений проходит без драмы, а рискованные останавливаются рано. Падающий тест блокирует сломанную логику. Ошибка линтера ловит неаккуратный код до того, как он распространится. Скан зависимостей показывает известные проблемы в момент добавления пакета, а не через недели.
Не обязательно сканировать каждый файл при каждом прогоне, если это замедлит команду. Начните с манифестов пакетов и lock‑файлов. Это даёт большую часть выгоды при гораздо меньшем шуме.
Добавьте ручное утверждение там, где риск высок
Некоторые изменения нужно читать человеку, как бы хороша ни была автоматизация. Требуйте ручного одобрения, когда PR затрагивает логин, биллинг, данные клиентов, права доступа или настройки деплоя. ИИ часто пишет правдоподобный код в этих областях, а правдоподобный не значит безопасный.
Короткое правило поможет: если изменение может заблокировать пользователей, списать деньги, раскрыть данные или сломать релиз — человек должен его одобрить.
Для маленькой команды одного ревьюера часто достаточно. Ревьюер смотрит diff, подтверждает, что автоматические проверки прошли, и задаёт один простой вопрос: «Я бы спокойно выпустил это сегодня?» Если ответ «нет», PR ждёт. Эта пауза экономит гораздо больше времени, чем поспешный фикс в продакшне.
Простой пример из маленькой команды
Представьте себе пятиместный стартап, который хочет сделать загрузку файлов в портале клиента. Фича кажется небольшой, поэтому команда просит инструмент ИИ собрать первый вариант.
Инструмент создаёт рабочую форму загрузки, бекенд‑хэндлер и новый пакет для обработки файлов. На демо всё выглядит нормально: пользователь выбирает файл, нажимает загрузить и видит его в аккаунте. Часто в этот момент команды доверяют коду слишком рано.
Первый ворота — тесты. Один тест отправляет файл гораздо больше допустимого размера. Загрузка проходит. Без этой проверки один клиент мог бы быстро заполнить хранилище, замедлить приложение или создать большой счёт в облаке. Команда добавляет ограничение размера и возвращает понятную ошибку.
Линт ловит более мелкие проблемы вокруг той же функции. ИИ оставил мёртвый код в обработчике и пропустил базовую проверку ввода. Эти ошибки не кажутся драматичными, но они усложняют поиск будущих багов.
Затем скан зависимостей флажит библиотеку, выбранную ИИ. У неё есть открытая проблема безопасности в одном из пакетов. На демо это никто не заметил, потому что фича работала. Скан заставляет остановиться, и команда меняет библиотеку на более безопасную.
Наконец ревьюер открывает портал в гостевой сессии и попадает на страницу загрузки без входа. Это хуже, чем сломанная кнопка: значит, любой человек может исследовать фичу и тестировать endpoint. Ревьюер находит пропущенную проверку аутентификации, которая предполагалась, но отсутствовала в сгенерированном коде.
К дню релиза команда исправила три реальные проблемы до того, как пользователи их увидели: отсутствие лимита размера файла, рискованный пакет и доступ гостя к защищённой странице. Релиз задержался на день. Это дешёвая плата.
Где команды совершают предотвратимые ошибки
Команды часто слишком доверяют зелёным галочкам. Набор тестов может быть зелёным и при этом почти ничего не говорить, если покрыты только счастливые сценарии. AI‑код усиливает эту проблему, потому что он часто выглядит полным, даже если пропускает крайние случаи, слабую обработку ошибок или необычные вводы, которые реальные пользователи вызовут сразу.
Поэтому одних тестов недостаточно. Небольшой набор вдумчивых тестов обычно лучше горы поверхностных. Если изменение касается платежей, аутентификации или удаления данных — кто‑то должен задать жёсткий вопрос: что тут может реально пойти не так, и доказывают ли наши тесты, что мы это поймаем?
Ещё одна частая ошибка — сделать одного человека постоянным утверждающим для всех рискованных изменений. Это кажется безопасным, но обычно создаёт узкое место и ухудшает качество ревью. Один ревьюер редко обладает полным контекстом по продукту, безопасности, инфраструктуре и бизнес‑риску одновременно. Одобрение работает лучше, когда ревьюер подходит под конкретное изменение, а не по должности.
Команды вредят себе, применяя одинаковые правила ко всем правкам. Исправление опечатки не должно стоять за теми же воротами, что и изменение биллинга. Когда процесс одинаков для мелких и рискованных правок, люди раздражаются, кликают в обход и перестают воспринимать процесс всерьёз.
Временные исключения наносят медленный урон. Команда пропускает предупреждение по зависимости, чтобы быстрее выпустить, отключает нестабильный тест на один релиз или откладывает ручное утверждение в пятницу вечером. Никто потом не возвращается, чтобы убрать этот обход. Если вы даёте исключение — назначьте владельца и срок истечения. Иначе оно перестанет быть временным.
Читаемый код вводит в заблуждение чаще, чем неаккуратный. ИИ умеет делать аккуратную структуру, понятные имена и уверенные комментарии. Ревьюеры расслабляются, когда вывод выглядит отполированным. Это ловушка. Чистый код может скрывать плохие предположения, небезопасные обновления пакетов или логику, которая проходит тесты только потому, что тесты слишком узкие.
Исправление не в большем количестве формальностей, а в лучшем суждении. Делайте более строгие проверки там, где последствия велики, более лёгкие правила там, где риск мал, и ясную ответственность при выдаче исключений.
Как сохранить полезность ручного утверждения
Ручное одобрение работает, только если команда оставляет его для изменений, которые реально могут навредить. Если каждый PR требует того же подтверждения, люди начинают одобрять просто чтобы расчистить очередь. Через пару недель ворота превращаются в рутину, а не в реальную проверку.
Выберите короткий набор изменений, которые всегда требуют второго взгляда. Большинству команд стоит включить всё, что затрагивает данные клиентов, логику платежей, флоу входа, права доступа, удаление аккаунта и доступ по публичным API. AI‑код может выглядеть аккуратно и при этом менять правила, которые никогда не должны сдвигаться.
Ревьюер не должен читать код в вакууме. Дайте ему небольшой чеклист и попросите проверить самое важное:
- Изменение раскрывает, копирует или удаляет пользовательские данные?
- Может ли оно списать деньги, изменить цены или пропустить правило биллинга?
- Меняет ли оно роли, права, токены или админ‑доступ?
- Открывал ли кто‑то приложение и тестировал изменённый путь вручную?
- Если команда пропустила ворота, записали ли они почему?
Последний пункт важнее, чем кажется. Исключения случаются. Хотфикс может нуждаться в скорости. Даже тогда команда должна зафиксировать, кто одобрил исключение, что было пропущено и что проверят сразу после релиза. Одной строчки в тикете достаточно. Память быстро подводит под давлением.
Ревьюеры также должны открывать приложение и пробовать изменённый путь: нажать кнопку, отправить форму, зайти под обычным пользователем и при необходимости под админом. Пять минут прямого использования часто ловят проблемы, которые тесты пропускают, например — неправильное меню для другой учётной записи или экран биллинга, разрешающий неверный план.
Права на обход держите узкими. Небольшая группа должна иметь разрешение форсить релиз, желательно люди, которые понимают продуктовые правила так же хорошо, как и код. Если любой может пропустить проверку — ворота потеряют смысл.
Быстрые проверки перед каждым релизом
Релиз должен проходить одни и те же проверки в одном и том же порядке. Если сборка работает только на ноутбуке одного разработчика, это почти ничего не говорит о том, что будет в продакшне.
Запускайте полный набор тестов на чистой ветке в общем пайплайне. Это значит свежие зависимости, чистая настройка окружения и никакой локальной магии. Команды пропускают это, когда торопятся, и обычно именно тогда мелкие ошибки превращаются в ночные откаты.
Короткий чеклист релиза достаточен:
- Подтвердить, что тесты проходят в CI, а не только локально.
- Проверить результаты линтинга по файлам, затронутым релизом, и исправить новые предупреждения.
- Просмотреть результаты скана зависимостей и закрыть нерешённые высокорисковые проблемы.
- Подтвердить шаги отката для базы данных, схемы или конфигурации.
- Назвать человека, который может остановить релиз, если что‑то пойдёт не так.
Линт часто считают косметикой. Это не так. Новые предупреждения в изменённых файлах могут указывать на слабую обработку ошибок, мёртвый код, небезопасные типы или поспешные правки, которые стоит посмотреть ещё раз.
Проверки зависимостей требуют такой же дисциплины. AI‑код может подтянуть пакеты, которые быстро решают задачу, но добавляют риск безопасности или поддержки. Если скан отмечает серьёзную проблему — не пропускайте её и не обещайте исправить позже. «Позже» редко наступает.
Проверки отката важны, когда релиз меняет схему или конфигурацию. Код‑деплой легко откатить. Битая миграция — нет. Запишите точные шаги отката до релиза и убедитесь, что команда может их выполнить без догадок.
Ещё одно правило спасает много проблем: все должны знать, кто имеет право запускать релиз и кто может его остановить. Это могут быть одни и те же люди, но решение должно быть ясным. Если тестер, инженер или менеджер замечает реальный риск, ему нужен прямой путь приостановить релиз, а не спор в чате.
Что делать дальше
Выберите один репозиторий и сделайте процесс реальным там сначала. Добавьте одно правило ветки для кода, который идёт к релизу, и используйте один короткий чеклист одобрения для всех рискованных изменений. Маленькое правило, которого люди придерживаются, лучше идеальной политики, которую никто не помнит.
Держите первую версию простой. Запускайте тесты, применяйте линт, сканируйте зависимости и требуйте ручного одобрения перед релизом, когда изменение затрагивает чувствительные области. Этого достаточно, чтобы поймать много плохого AI‑кода, не замедлив команду до остановки.
Не распределяйте усилия равномерно по всему продукту. Укрепляйте тестовое покрытие сначала вокруг биллинга, входа и экспорта данных. Эти области могут навредить пользователям, создать работу для поддержки и превратить маленькую ошибку в реальную бизнес‑проблему. Баг в чек‑ауте хуже, чем баг в верстке — относитесь к этому соответственно.
Если одно и то же правило постоянно падает — обычно проблема не в воротах. Возможно, промпт слабый, тестовые данные плохие или кодовая база нуждается в понятных паттернах, чтобы ИИ следовал им. Исправляйте корень, а не спорьте с процессом.
Для маленькой команды ворота качества AI‑кода должны казаться скучными и предсказуемыми. Открывается pull request, проверки запускаются, один человек ревьюит рискованные части, и изменение либо идёт дальше, либо возвращается на доработку. Если этот поток кажется тяжёлым — сократите чеклист, прежде чем убирать ворота.
Если вашей команде нужна помощь в решении, где поставить ворота, Oleg Sotnikov на oleg.is работает со стартапами и малыми бизнесами над AI‑ориентированными рабочими процессами разработки, инфраструктурой и поддержкой в формате Fractional CTO. Иногда короткий внешний обзор достаточно, чтобы задать разумные правила и избежать дорогих ошибок.
Начните с малого, следите, где процесс ломается, и сначала улучшайте эту часть. Так ворота станут привычкой команды, а не ещё одной забытой политикой.
Часто задаваемые вопросы
What is a quality gate?
Простое правило: код должен пройти проверку, прежде чем команда сльёт его в продакшн. Хорошие ворота дают чётный ответ «да» или «нет»: тесты в CI прошли, линтер чист, зависимостей с известными уязвимостями нет или есть именованный ревьюер для рискованных изменений.
Do small teams really need AI code quality gates?
Да. Особенно если два‑три человека одновременно занимаются продуктом, поддержкой и релизами. Малые команды очень быстро ощущают последствия плохих релизов, поэтому несколько строгих проверок экономят время и уменьшают количество возвратов и возмещений позже.
Which gates should I add first?
Начните с тестов для изменённого пути, линтинга и форматирования в каждом pull request, проверки зависимостей для новых или обновлённых пакетов и ручного подтверждения для изменений, затрагивающих аутентификацию, биллинг, удаление данных, API или настройки деплоя. Это закрывает много реального риска без сильного замедления.
Should AI-generated code follow different rules than human code?
Нет. Применяйте одинаковые базовые правила и к коду человека, и к коду, сгенерированному ИИ. AI‑код не должен получать более лёгкий путь, как и человек не должен получать свободный проход. Важно уровень риска: чувствительные изменения требуют больше проверки, независимо от автора.
What changes always need manual approval?
Попросите человека подтверждать изменения, которые могут заблокировать пользователей, списать деньги, раскрыть данные, изменить права или сломать релиз. Сюда входят логин‑флоу, биллинг, обработка данных клиентов, админ‑доступ, публичные API и изменения инфраструктуры.
How much testing is enough for AI-written code?
Тестируйте именно тот поток, который изменился, а не только «радостный путь». Если ИИ трогал загрузку файлов — попробуйте слишком большие файлы и неподдерживаемые типы. Если это билинг — проверьте повторы, купоны и ошибки. Несколько продуманных тестов лучше горы поверхностных.
Do I need to scan every dependency on every pull request?
Нет. Начните со скана файлов манифестов пакетов и lock‑файлов на pull request'ах, которые добавляют или обновляют зависимости. Это даёт большую часть пользы при меньшем шуме и задержках.
What should we do when a hotfix needs to ship fast?
Относитесь к хотфиксам как к исключениям, а не к обходам. Пусть один назначенный человек одобрит релиз, запишите, какие ворота вы пропустили и почему, и выполните пропущенные проверки сразу после деплоя. Если у исключения нет владельца — оно останется навсегда.
How do we stop manual review from turning into rubber-stamping?
Держите пул ревьюеров небольшим, но не назначайте одного человека на все проверки. Подбирайте ревьюера по изменению, просите его открыть приложение и прогнать изменённый путь вручную, и давайте короткий чеклист, чтобы он оценивал риск, а не просто очищал очередь.
Where should I start if our release process is messy?
Защитите ветку main, требуйте pull request'ы и запускайте CI с тестами и линтером на каждое изменение. Затем добавьте скан зависимостей и короткое правило согласования для рискованных областей. Начните с одного репозитория и сделайте процесс нормой там, прежде чем распространять дальше.


