Владение namespace в Kubernetes: что настроить в первую очередь
Владение namespace в Kubernetes начинается с алертов, бюджетов и прав на деплой. Узнайте, что нужно определить до разделения работы между командами.
Содержание
В чем проблема владения по namespace
Namespace — это ярлык, а не владение. Команды часто создают payments-prod или mobile-staging и думают, что название само объясняет, кто за что отвечает. Это не так. Владение namespace в Kubernetes становится реальным только тогда, когда вокруг него еще настраивают алерты, бюджеты и права на деплой.
Проблема быстро проявляется в повседневной работе. Команда считает, что владеет сервисом, потому что создала namespace, но продовые алерты все равно приходят в общий канал ops. Люди, которым приходит page, могут не знать ни приложение, ни код, ни недавние изменения. Команда, которая может исправить проблему, вообще может не увидеть алерт, пока кто-нибудь не тегнет ее вручную.
С затратами та же история. Расходы на облако, логирование и дополнительные сервисы часто остаются общими на уровне кластера или аккаунта. В итоге одна команда может увеличивать нагрузку, а виноватой в большем счете окажется другая. Когда финансы спрашивают, что изменилось, у никого нет внятного ответа по продукту, окружению или команде.
Права на деплой — еще одно слабое место. Многие компании поначалу дают широкие разрешения, потому что так быстрее. Потом почти любой, кто имеет доступ к кластеру, может выкатывать изменения почти в любой namespace. Команда может думать, что владеет checkout-prod, но если туда по-прежнему могут деплоить еще пять человек, это владение скорее наугад.
Представьте растущую софтверную компанию с тремя продуктовыми командами. У каждой свой namespace. На бумаге это выглядит аккуратно. На практике алерты все равно падают в один канал Slack, в ежемесячном счете видна одна общая сумма, а старшие инженеры по-прежнему имеют доступ ко всему кластеру, потому что никто не ограничил его точнее. Когда что-то ломается в пятницу вечером, название namespace не отвечает на единственный важный вопрос: кто сейчас обязан это чинить?
Вот почему один лишь namespace создает ложное ощущение порядка. Снаружи все выглядит организованно, но сложные части владения по-прежнему находятся где-то в другом месте.
Что должна владеть команда
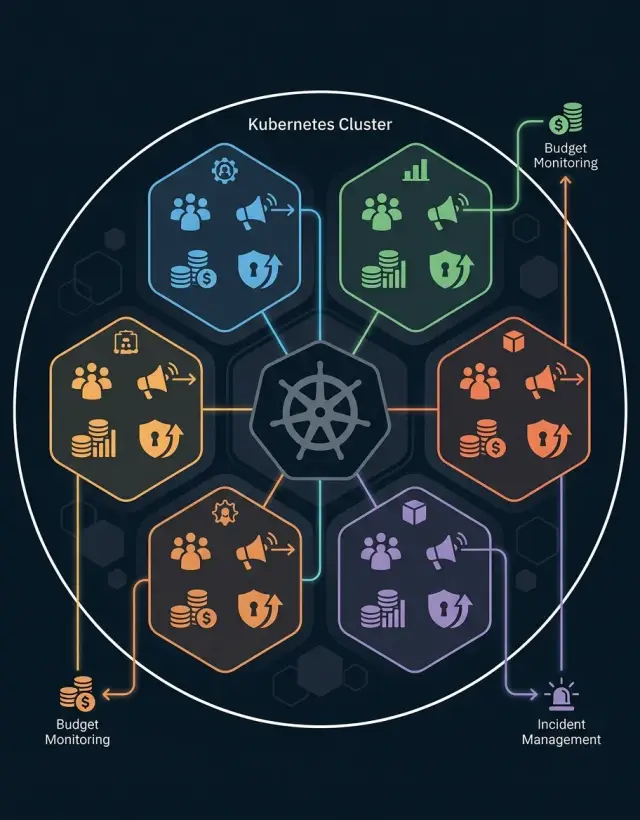
У namespace должен быть один владелец. Если две команды думают, что владеют им обе, никто не чинит мелкие проблемы заранее, и большие только накапливаются. Хорошее владение namespace в Kubernetes начинается с одного понятного названия команды в документах.
Запись о команде должна быть короткой, но она обязана отвечать на базовые вопросы, которые возникают и в обычную неделю, и во время инцидента. Когда pod постоянно перезапускается, кого page'ят? Когда появляется новый cron job, кто дает добро? Когда расходы на облако вырастают на 30 процентов, кто это объясняет?
Полезная запись о владельце обычно включает пять вещей:
- одна команда, которая владеет namespace
- один менеджер, который отвечает за решения
- один контакт on-call для инцидентов и алертов
- сервисы, воркеры и расписания, которые относятся к этому namespace
- человек или роль, которая одобряет продовые деплои и следит за бюджетом
Делайте название команды максимально конкретным.
Определите команду до создания чего-либо
Namespace создать легко. Разобраться с неясным владением — нет. Прежде чем кто-то выполнит kubectl create namespace, запишите один командный профиль, который отвечает на вопросы: кто владеет работой, кого page'ят, кто может деплоить и на кого ложатся расходы. Для владения namespace в Kubernetes этот документ важнее самого названия namespace.
Используйте названия команд, которые совпадают с реальной структурой компании. Если в компании группа называется «Payments», так и пишите «Payments» везде. Не придумывайте одну метку для Kubernetes, другую для биллинга и третью для контроля доступа. На первый взгляд это кажется безобидным, а во время инцидента превращается в путаницу.
Хорошая карточка команды короткая, но в ней должны быть базовые вещи:
- название команды и человек, который одобряет доступ
- сервисы, которые она поддерживает, и нужные ей окружения
- общие зависимости, такие как базы данных, очереди или ingress-правила
- контакты для алертов в рабочее и нерабочее время
- бюджетный тег и группы доступа, привязанные к этой же команде
Названия должны совпадать в облачных тегах, группах RBAC, маршрутизации алертов и внутреннем списке команд. Если в биллинге написано «commerce», в алертах — «platform», а права на деплой выданы группе «backend-admins», никто не поймет, кто владеет проблемой, когда ночью в 2:00 всех разбудит падение pod.
Небольшая софтверная компания часто учится этому на собственных ошибках. Команда приложения просит новый staging namespace, и кто-то создает его за пять минут. Через несколько недель staging начинает жечь деньги, алерты приходят не в тот канал Slack, а доступ на деплой есть у трех инженеров, хотя сервис использует только одна команда. Решение — не еще одно правило для namespace. Решение — тот самый профиль, который пропустили.
Создавайте namespace только после того, как этот документ готов и утвержден. Эта короткая пауза экономит часы последующей уборки и с самого начала связывает team based deploy rights, Kubernetes alert routing и Kubernetes cost allocation с одним владельцем.
Привяжите алерты к нужной команде
Владение namespace в Kubernetes быстро рушится, если все алерты идут в один общий канал. Namespace группирует ресурсы, но не подсказывает людям, кто должен проснуться, разобраться и исправить проблему. Если checkout-сервис начал падать, page должна прийти команде checkout. Если на узлах заканчивается диск или API server работает нестабильно, алерт должна получить platform-команда.
Такой раздел делает работу понятной. Продуктовые команды разбирают ошибки приложения, задержки и неудачные job'ы. Platform-инженеры отвечают за здоровье кластера, ingress, хранилище, давление на node и поломки в цепочке деплоя. Когда эти сигналы смешиваются, люди перестают доверять алертам и начинают их приглушать.
Хорошее правило простое: page'ьте ту команду, которая может действовать в течение нескольких минут. Все остальное можно отправлять в менее шумный канал для рабочего времени. Обычно это два класса алертов:
- pages — для отказов, заметных пользователю, бесконечных циклов перезапуска на живом сервисе, устойчивого всплеска ошибок или продовой job, которая упала и блокирует бизнес
- warnings — для коротких скачков CPU, единичного перезапуска pod, тенденций по quota или уведомлений, где еще есть время среагировать
Маршрут лучше хранить в записи о сервисе, а не прятать в одной конфигурации алерта. Каждый продовый сервис должен указывать команду-владельца, on-call цель и один резервный контакт. Кластерные алерты должны идти в ротацию platform-команды, даже если сегодня в ней всего один человек.
Небольшой пример делает это понятнее. Если payments pod начинает возвращать ошибки 500, алерт должна получить команда payments, потому что она знает код, релиз и недавние изменения. Если несколько nodes показывают memory pressure, алерт должна получить platform-команда, потому что исправление может потребовать правил планирования, autoscaling или исправления емкости кластера.
Перед запуском проверьте один реальный путь алерта. Сгенерируйте безвредный алерт в staging или проведите запланированную проверку в production в четко ограниченное время. Посмотрите, кто получил page, сколько времени ушло на реакцию и хватало ли контекста в сообщении. Если в тесте пинг пришел не той команде, ночью в 2:00 произойдет то же самое.
Сделайте затраты видимыми до того, как они станут сюрпризом
Namespace может группировать workload'ы, но он не скажет, кто должен за них платить. Расходы остаются расплывчатыми, если каждый workload не получает один и тот же небольшой набор меток. Начните с team, service, environment и cost_center. Когда кто-то смотрит счет, он должен за несколько минут понять, на какую команду приходится расход, а не разбирать длинную переписку в Slack.
Хорошее владение namespace в Kubernetes включает и правила учета затрат, а не только названия и quota. Если две команды запускают приложения в одном кластере, обеим нужны понятные labels на pod'ах, job'ах и связанных managed services.
Простой набор меток часто лучше сложной модели:
- team
- service
- environment
- cost_center
- owner
Больше всего споров вызывают общие расходы. Ingress, логирование, мониторинг и базовые node'ы кластера редко принадлежат одной команде. Выберите правило заранее и запишите его. Можно делить ingress по трафику, логирование — по объему, а накладные расходы платформы — по фиксированному проценту или по численности команды. Идеальная математика менее полезна, чем правило, которое всем понятно и которое можно объяснить.
Неиспользуемые окружения тихо сжигают деньги. Staging-приложение с node'ами размера production может простаивать всю ночь и без причины тратить бюджет. Проверяйте окружения, которые живут после рабочего времени, preview-приложения, которые никто не открывал несколько дней, и batch job'ы, которые по-прежнему запускаются по выходным. Один короткий еженедельный просмотр часто находит достаточно лишнего расхода, чтобы отложить более крупные изменения в инфраструктуре.
Сравните расходы команд, прежде чем одобрять еще один кластер. Если одна команда дает основную часть роста, ей могут понадобиться более жесткие лимиты, меньшие node'ы или меньше сервисов, которые работают постоянно. Если расходы стабильны и разделены аккуратно, позже может быть уместен новый кластер. Многие запросы на дополнительные кластеры появляются из-за плохой видимости, а не из-за реальной необходимости изоляции.
Компактные команды делают это хорошо. Они сохраняют один кластер понятным, делают расходы видимыми по командам и сокращают пустые траты до того, как они превращаются в бюджетный сюрприз.
Настройте права на деплой с понятными границами
Namespace мало что защищает, если деплоить могут все и везде. На практике владение namespace в Kubernetes работает только тогда, когда доступ совпадает с границами команды.
Каждая команда должна деплоить только в свой namespace и только в свои сервисы. Если одна команда может выкатывать изменения в зону другой команды, люди перестают доверять этой границе. Ошибки сложнее отследить, а владение превращается в догадки.
В production нужен более жесткий контроль. Окончательное одобрение продового деплоя должно быть у маленькой определенной группы, а не у широкой инженерной роли. В эту группу могут входить тимлид и один владелец platform. Это добавляет короткую паузу перед релизом, но она обычно дешевле, чем инцидент.
Полезно также разделять доступ по риску. Выкатить новую версию приложения — не то же самое, что менять secrets или редактировать кластерные настройки. Для этого должны быть отдельные разрешения, даже у старших инженеров.
Простая схема обычно работает хорошо:
- Команды могут деплоить и откатывать только в своем namespace.
- Команды могут читать логи, события и метрики только своих сервисов.
- Небольшая утвержденная группа может менять secrets и кластерные настройки.
Так ежедневная работа движется вперед, но admin-права не раздаются всем подряд. Это также снижает риск случайного вреда. Разработчик, который выкатил плохой образ, сможет сломать один сервис. Но этот же разработчик не должен по ошибке менять ingress-правила или трогать secrets другой команды.
Старые доступы тоже нужно чистить. Эту часть часто игнорируют, и она создает тихий риск. Когда люди переходят в другие команды, забирайте ненужные права в тот же день. Когда человек уходит из компании, удаляйте доступ из кластера, системы CI и хранилища secrets одновременно.
Одна растущая софтверная компания часто учится этому на собственных ошибках. В начале пять инженеров делят широкий доступ, потому что так быстрее. Через шесть месяцев появляется три команды, загруженный production-кластер, и никто уже не знает, кто еще что может редактировать. Решение редко бывает сложным. Запишите, кто владеет каждым namespace, кто может в него деплоить и кто утверждает production. Потом закрепите это не в памяти, а в ролях.
Понятные границы не тормозят команду надолго. Они делают владение реальным, уменьшают масштаб инцидентов и не дают временному доступу стать постоянным.
Простой пример из растущей софтверной компании
У растущей софтверной компании было четыре продуктовые команды, которые делили один Kubernetes-кластер. Billing, customer accounts, internal tools и public API — у каждого был свой namespace, и каждая команда выкатывала изменения по своему графику. На бумаге это выглядело аккуратно. На деле никто не настроил настоящее владение namespace в Kubernetes.
Команда billing выкатывала изменения дважды в неделю. Команда API деплоила почти каждый день. Internal tools менялись всего несколько раз в месяц. Platform-команда поддерживала кластер в рабочем состоянии, но она не должна была владеть каждым приложением внутри него.
Потом один billing job начал создавать гораздо более высокую нагрузку, чем обычно. Расходы выросли в течение месяца, а алерт сработал, когда spend превысил бюджетный порог. Этот алерт пришел platform-команде, а не billing-команде, потому что в компании алерты были настроены на cluster admins, а не на команду, которая владела сервисом.
Теперь у platform-инженеров было две проблемы. Во-первых, нужно было разбудить billing-команду и объяснить проблему, которую они не создавали. Во-вторых, финансы задали простой вопрос: какая команда стала причиной роста? Уверенного ответа не было ни у кого. У workload'ов были слабые labels, общие runners и не было понятной картины расходов по командам. Названия namespace выглядели аккуратно, но они не доказывали, кто владеет расходами, алертами или правом на деплой.
Компания отложила планы на второй кластер и сначала починила базу. Они оставили один кластер, но добавили к нему более понятную структуру команд:
- у каждого сервиса появились team labels, совпадающие с правилами учета затрат и алертов
- billing-алерты сначала шли в billing-команду, а platform была резервом
- группы деплоя совпадали с границами команд, а не с широким общим доступом
- ежемесячные отчеты по затратам показывали использование по командам, а не только по кластеру
Через месяц у той же компании по-прежнему был один кластер, но стало гораздо меньше путаницы. Когда менялись расходы, было видно, откуда пришло изменение. Когда срабатывали алерты, они попадали к нужным людям. Когда команда деплоила, ее права совпадали с ее же сервисами.
Обычно именно в этот момент и стоит спрашивать, нужен ли еще один кластер. Если в одном кластере уже есть понятное владение, следующий шаг сделать гораздо проще. Если его нет, второй кластер обычно просто переносит тот же хаос еще в одно место.
Ошибки, которые делают владение запутанным
Владение обычно ломается маленькими, обычными ошибками. Никто не планирует беспорядок. Он начинается тогда, когда namespace выглядит аккуратно на схеме, а работа внутри него принадлежит разным командам.
Один частый пример — namespace, где живут сервисы двух команд. API-команда выкатывает один сервис, data-команда — другой, и оба оказываются в одном месте просто потому, что так удобнее. Потом в 2:00 срабатывает алерт. Никто не знает, кто должен реагировать первым. Одна команда говорит: «мы меняли только наш worker», а другая — «мы не управляем тем sidecar базы данных». Название namespace этот спор не решает.
Алертинг быстро становится запутанным, если dev, staging и prod используют один и тот же маршрут. Люди начинают игнорировать шум, потому что большинство page'ей — это безвредные ошибки в тестах. Потом реальная production-проблема приходит в тот же канал и слишком долго там лежит. Хорошая маршрутизация алертов в Kubernetes специально скучная. Prod должен попадать к людям, которые дежурят по prod. Тестовые окружения не должны конкурировать за то же внимание.
Labels — еще одна тихая точка отказа. Команды добавляют owner, cost center, environment и service в первый день, а потом никто больше их не проверяет. Через несколько месяцев у половины workload'ов старые значения, пустые значения или ошибки в написании. Это ломает распределение затрат в Kubernetes и делает отчеты точнее, чем они есть на самом деле. Плохие labels хуже отсутствия labels, потому что создают ложную уверенность.
С доступом часто все идет не так по простой причине: cluster-admin кажется быстрее. Инженеру нужно починить один деплой, он получает широкие права и оставляет их навсегда. В итоге пять человек могут редактировать что угодно в любом namespace. Сегодня это экономит десять минут, а потом создает недели уборки, особенно когда команда меняется или подрядчик уходит.
Последняя ошибка — добавлять кластеры до того, как исправлены базовые вещи. Новый кластер может выглядеть как прогресс, но чаще он просто переносит ту же путаницу еще в одно место. Если в одном кластере права расплывчаты, а учет затрат неполный, два кластера не помогут.
Запутанное владение namespace в Kubernetes можно заметить заранее, если:
- две команды отвечают на один и тот же алерт, и ни одна не чувствует себя ответственной
- staging page'ит тех же людей и почти так же, как prod
- отчеты по затратам каждый месяц нужно вручную чистить
- инженеры просят широкие права, потому что обычный путь неясен
Если что-то из этого знакомо, не стоит наращивать структуру поверх хаоса. Сначала приведите в порядок границы команд, а уже потом пусть namespaces отражают их.
Короткая проверка перед добавлением кластера
Новый кластер часто кажется аккуратным решением. Обычно это не так. Команды добавляют его, потому что алерты слишком шумные, права слишком широкие или счет трудно объяснить. Второй или третий кластер может сделать эти проблемы менее заметными и более дорогими.
Хорошее владение namespace в Kubernetes начинается с короткого аудита. Если вы не можете ответить на эти пункты за несколько минут, добавление еще одного кластера, скорее всего, просто перенесет ту же путаницу в новое место.
- Поставьте рядом с каждым namespace одно название команды. Если у namespace нет понятного владельца или на него претендуют две команды, сначала остановитесь на этом.
- Проверьте все пути production-алертов. Каждый алерт должен попадать одному понятному человеку или одной on-call-команде, а не в общий inbox, который все игнорируют.
- Возьмите расходы за последний месяц и сгруппируйте их по командам. Если вы не можете показать, кто сколько использовал, новый кластер только сильнее размоет картину.
- Сравните права на деплой с реальными границами команд. Команда должна деплоить свои сервисы, а не половину кластера.
- Спросите, зачем вам еще один кластер. Если ответ — «нужна изоляция» или «все кажется запутанным», проблема может быть в процессе, а не в масштабе.
Маленькие пробелы быстро накапливаются. Один namespace без владельца превращается в сервис, который никто не патчит. Один алерт без контакта — в ночную беготню. Одна общая роль на деплой — в долгий спор после неудачного релиза.
Когда ответ — «пока нет»
Это обычно нормально. Многим растущим командам не нужен еще один кластер. Им нужны более чистые team based deploy rights, лучшая маршрутизация алертов в Kubernetes и простое распределение затрат в Kubernetes, которое читают и финансы, и инженеры.
Реальное ограничение выглядит конкретно. Вы уперлись в правило комплаенса, жесткую сетевую границу, требование по региону или в характер workload'а, который не должен жить рядом с остальными. Неясный процесс выглядит мягче: слишком много людей могут деплоить, никто не владеет алертами, и никто не доверяет счету. Сначала исправьте мягкие проблемы. Количество кластеров подождет.
Что делать дальше
Не начинайте с добавления еще одного кластера. Начните с одного настоящего аудита в одном существующем кластере, даже если он кажется маленьким или неаккуратным. Такой аудит покажет, есть ли у вас реальное владение или только ярлыки, которые красиво выглядят на бумаге.
Возьмите каждый namespace и запишите три простых факта: кто им владеет, как связаться с этой командой и какой бюджет или cost center за него платит. Если вы не можете заполнить все три пункта за несколько минут, у namespace пока нет понятного владения. Этот пробел важнее, чем следующая часть платформенной работы.
Простой проход выглядит так:
- перечислите все namespace и укажите по одной команде, а не список возможных владельцев
- добавьте реальный путь связи для алертов, например on-call канал или человека
- привяжите бюджет, cost center или месячный лимит расходов
- отметьте, какие общие сервисы использует namespace
- выделите все, где нет владельца или неясны права на деплой
После этого исправьте маршрутизацию алертов и права на деплой, прежде чем делить кластеры. Если алерты по-прежнему приходят platform-команде по приложениям, которые она не обслуживает, структура неправильная. Если любой разработчик может деплоить куда угодно просто потому, что так удобнее, структура тоже неправильная. Разделение на кластеры только на время скроет эти проблемы.
Общие сервисы тоже требуют короткого письменного правила. Логирование, ingress, CI runners, базы данных и observability часто находятся вне одного namespace, но они все равно стоят денег. Запишите, как команды делят эти расходы. Для начала подойдет и грубый метод. Смысл в том, чтобы убрать неожиданные счета и тихие споры.
Это еще и момент, когда нужно решить порядок внедрения. Сначала исправьте самую загруженную команду или ту, у которой самые шумные алерты. Обычно так быстрее всего видно, что лучшее владение namespace в Kubernetes реально уменьшает путаницу.
Если хотите свежий взгляд со стороны, запишитесь на консультацию к Oleg Sotnikov. Он помогает командам навести порядок во владении, выборе инфраструктуры и очередности изменений, не превращая простую уборку в большой миграционный проект.


