Ускорьте CI‑сборки хорошими привычками в репозитории, а не более мощными раннерами
Хотите ускорить CI‑сборки? Начните с привычек в репозитории: понятные имена, умная структура тестов и очистка зависимостей — прежде чем платить за более мощные раннеры.

Содержание
Почему более мощные раннеры часто разочаровывают
Команды часто тянутся за более мощными раннерами, как только сборки начинают казаться медленными. Это может срезать несколько секунд, но редко решает ту часть, которая действительно мешает.
Больше CPU ускоряет только ту работу, которая уже выполняется. Оно не убирает лишнюю работу. Если каждый pull request устанавливает устаревшие пакеты, сканирует половину репозитория и запускает тесты, не связанные с изменением, более мощная машина просто выполняет тот же лишний объём чуть быстрее.
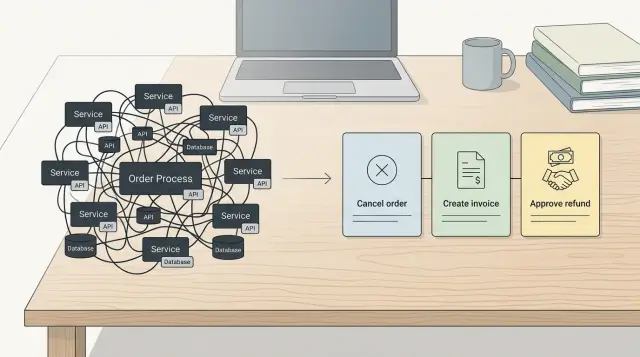
Вы часто видите это с одной широкой задачей, которая запускается практически на каждый коммит. Кто‑то правит небольшой файл с текстом UI, но CI всё равно запускает полную линтовку, бэкенд‑тесты и долгую сборку. Эта единая задача блокирует очередь мерджей, и все ждут работу, которая вовсе не должна была выполняться.
Беспорядок в папках ухудшает ситуацию. Когда команды смешивают несвязанный код в одних и тех же путях или используют имена, которые ничего не говорят CI о том, что изменилось, они получают широкие правила триггеров. CI играет осторожно и запускает слишком много. Здесь проблема не в машине — а в репозитории.
Старые зависимости добавляют ещё одно торможение. Более мощный раннер может распаковать и скомпилировать их быстрее, но всё равно нужно скачивать, проверять и устанавливать пакеты. Если проект содержит пакеты, которыми никого уже не пользуются, вы платите эту цену на каждой ветке и каждом PR. Эти минуты быстро складываются.
Большинству команд выгоднее сначала исправить репозиторий. Разбейте широкие задачи на более мелкие. Держите тесты рядом с кодом, который они покрывают. Обрежьте пакеты, которые замедляют каждую установку. Используйте имена папок, которые явно показывают, что изменилось.
Более мощные раннеры всё ещё имеют смысл для тяжёлых релизных сборок или очень больших наборов тестов. Но для повседневных pull request‑ов медленный CI обычно указывает сначала на грязные привычки в репозитории. Исправьте их, и следующая апгрейд раннера может оказаться не нужен.
Сначала найдите медленные места
Перед покупкой дополнительного CPU измерьте каждый шаг. Команды часто обвиняют медленные тесты, но самые большие задержки обычно сидят в настройке.
Засеките полный CI‑прогон от начала до конца. Отслеживайте checkout, установку зависимостей, сборку, тесты и загрузку артефактов. Набор тестов на семь минут ощущается плохо, но четырёхминутный шаг установки на каждом пуше часто легче исправить.
Затем выполните те же команды на одной машине разработчика и сравните цифры. Если приложение собирается локально за 90 секунд, а в CI занимает 6 минут, возможно, дело не в коде. Холодные кэши, медленные загрузки пакетов, запуск контейнеров и дополнительные шаги только в CI могут добавлять больше задержки, чем ожидают.
Посмотрите внимательно, какие задания запускаются при каждом маленьком изменении. Там прячется лишняя работа. Правка документации не должна запускать тот же путь, что миграция базы данных, но многие пайплайны всё ещё выполняют полные сборки, длинные интеграционные тесты и загрузки образов для обоих.
Полезно также записать, какие папки чаще всего менялись за последние недели. Держите список простым: app, tests, docs, infra, scripts — или что подходит для вашего репо. Шаблоны появляются быстро. Если половина коммитов трогает frontend, а лишь немногие — backend‑сервисы, CI должен обрабатывать эти пути по‑разному.
Малые команды обычно замечают это сразу, как только начнут смотреть. Они меняют UI‑файлы весь день, но каждый коммит всё равно запускает бэкенд‑интеграционные тесты и публикует артефакты, которые никому не нужны. Это достаточно, чтобы терять часы каждую неделю.
Начните с фактов, а не с догадок. Как только медленные шаги, всегда‑запускаемые задания и самые загруженные папки задокументированы, следующие изменения обычно очевидны.
Установите простые правила для имён и путей
Запутанные имена сначала замедляют людей. Потом они замедляют CI.
Когда папки, пакеты и скрипты растут без правил, команды возвращаются к широким маскам файлов, размытым фильтрам по путям и дополнительным защитным шагам. CI сканирует больше файлов, чем нужно, и маленькие изменения запускают большие прогоны.
Держите имена короткими, простыми и стабильными. Пакет billing лучше, чем billing‑v2‑final. Скрипт test:web проще маршрутизировать, чем run‑frontend‑full‑check. Короткие имена легче читать и они упрощают правила путей, кэшей и селективных запусков тестов.
Пара скучных правил решает большинство проблем. Соответствуйте именам папок реальным областям продукта, например auth, billing, admin или mobile. Держите общие скрипты в одном понятном месте, например scripts/. Переименуйте расплывчатые папки misc, temp, stuff или old, как только в них начнёт появляться реальный код. Если два вспомогательных файла делают почти одно и то же — оставьте один и удалите другой.
Это важнее, чем многие думают. CI часто решает, что запускать, по изменённым путям. Если код checkout лежит в payments/, shared‑temp/ и utils‑new/, пайплайн не может принять чистое решение. Обычно он запустит больше тестов, пересоберёт больше пакетов и упустит шансы на кэш.
Одна рабочая схема: согласовать имена пакетов, папок и скриптов. Если папка admin/, пакет — admin, а скрипты — test:admin и build:admin. Выглядит почти скучно — и в этом смысл. Скучные репозитории легче автоматизировать.
Вечер, потраченный на очистку путей, может сэкономить минуты при каждом прогоне. Это также избавит людей от угадываний, куда положить файлы.
Расположите тесты так, чтобы CI мог их разделять
Многие медленные пайплайны возникают из одной команды тестов, которая обходит весь репозиторий. Если каждое задание выполняет одно и то же обнаружение тестов, вы теряете время ещё до первого утверждения.
CI работает лучше, когда каждое задание точно знает, за какие файлы оно отвечает. Держите unit‑тесты рядом с кодом, который они проверяют. Если user_service.ts находится рядом с user_service.test.ts, небольшие изменения легко сопоставлять, и CI может запускать только юнит‑тесты этой области, вместо того чтобы обходить весь проект.
Поместите интеграционные тесты в отдельные папки. Не смешивайте их с шаблонами unit‑тестов. Раздел вроде src/.../*.test.ts для unit и tests/integration/... для интеграционных тестов обычно достаточно. Чёткие папки упрощают конфигурацию CI.
Медленным тестам нужен видимый ярлык. Используйте один тег и применяйте его последовательно. slow, db или network лучше, чем расплывчатые комментарии, которые никто не читает. Если тест запускает контейнеры, ждёт внешних сервисов или грузит большие фикстуры — пометьте его, чтобы CI мог отправить его в отдельное задание.
Одна команда не должна по‑умолчанию собирать все тесты. npm test или эквивалент со временем превращается в кладовку. Держите быстрый вариант по‑умолчанию для локальной работы, добавьте отдельные команды для unit, integration, browser или smoke тестов.
Каждое CI‑задание должно запускать одну группу, а не смешивать их. Если unit‑задача занимает две минуты, а integration — девять, разработчики получают раннюю обратную связь, вместо того чтобы ждать самого долгого пути.
Небольшая продуктовая команда часто начинает с одной команды тестов, потому что это кажется аккуратно. Месяц спустя эта команда запускает и базу данных, и browser‑проверки, и мелкие чистые функции в одной пачке. Разделение — не пустая трата времени. Это часто сокращает лишнюю работу ещё до того, как вы будете менять размер раннера, настройки кэша или параллельный хардвер.
Обрежьте зависимости до того, как они попадут в каждый прогон
Много лишней работы в CI начинается ещё до первого теста. Каждый пакет в репозитории добавляет время: установка, изменение lockfile, проверки безопасности или дополнительные шаги настройки. Полезный вопрос: действительно ли вы ещё используете этот пакет?
Команды хранят старые библиотеки, потому что их удаление кажется рискованным. На практике многие пакеты остаются нетронутыми после рефакторинга, смены инструмента или эксперимента. Быстрый поиск по импорту обычно находит несколько лёгких сокращений.
Проход по очистке должен искать четыре вещи: пакеты, которые никто больше не импортирует; тяжёлые инструменты, которые уже покрыты языком или фреймворком; dev‑инструменты, случайно попавшие в runtime‑зависимости; и postinstall‑скрипты, тянущие большие бинарники при каждой чистой установке.
Последний пункт быстро дорог. Инструменты для браузерного тестирования, библиотеки работы с изображениями и нативные модули могут загрузить сотни мегабайт в CI, даже когда большинство задач их почти не использует. Если нужен лишь один рабочий поток, держите такие зависимости вне стандартного пути.
Чёткое разделение runtime и dev‑зависимостей тоже помогает. Продакшн‑сборки должны устанавливать то, что нужно приложению для запуска, а не каждый линтер, форматтер, генератор кода и локальный скрипт. В монорепозиториях это ещё важнее: один раздутый пакет может замедлить все задания.
Встроенных опций часто достаточно. Если ваш тест‑раннер уже считает покрытие, возможно, вам не нужен второй инструмент покрытия. Если фреймворк уже компилирует TypeScript, не всегда нужен отдельный шаг компиляции ради CI. Небольшие замены экономят минуты на десятках прогонов ежедневно.
После каждого прохода очистки обновляйте lockfile и прогоняйте полный пайплайн раз. Так изменения остаются небольшими и легко рецензируются. Даже скромное веб‑приложение часто сокращает время установки на 20–40% только путём удаления неиспользуемых пакетов, убирания одной тяжёлой зависимости и исправления грязного разделения зависимостей.
Очистка зависимостей не красива, но это один из самых дешёвых способов ускорить CI.
План очистки на неделю
Медленный пайплайн обычно растёт из мелких привычек репозитория, набравшихся со временем. Прежде чем платить за более мощные раннеры, потратьте неделю на очистку репо.
Начните с базовой линии. Вытащите последние 10–20 прогонов и запишите, сколько реально занимает установка, сборка, unit‑тесты, integration и browser‑тесты. Используйте медиану, а не самый быстрый прогон, и отметьте задания с периодическими ошибками.
Дальше идите по фиксированному порядку:
- День 1: перечислите все задания, что запускаются на каждом pull request, и отметьте, какие из них действительно должны блокировать мердж.
- День 2: переименуйте скрипты и папки, которые постоянно вводят людей в заблуждение, особенно смешанные имена тестов или расплывчатые команды вроде
test:all. - День 3: разделите unit, integration и browser‑тесты на чёткие пути и команды, чтобы CI мог запускать их в нужных местах.
- День 4: удалите неиспользуемые пакеты, старые SDK, дублирующие хелперы и шаги установки, которые существуют только потому, что никто их не проверял.
- День 5: обновите кеши зависимостей, прогоните пайплайн несколько раз и сравните новые тайминги с базой.
Имена важнее, чем многие признают. Если одна папка tests содержит быстрые unit‑проверки, database‑тесты и browser‑флоу, люди пропускают всё через одну задачу. Чёткие пути tests/unit, tests/integration и tests/browser значительно упрощают разделение работы и пропуск тяжёлых проверок, когда это не требуется.
Очистка зависимостей менее захватывающая, но даёт быстрый результат. Несколько неиспользуемых пакетов добавляют время установки, увеличивают lockfile и приводят к пропускам кэша. Одна маленькая команда легко экономит минуту‑две просто, удалив старые инструменты тестирования и перейдя к одному менеджеру пакетов вместо двух.
Сохраняйте только те изменения, которые сокращают время, не скрывая при этом ошибки. Если сборка стала быстрее, но люди перестали доверять тестам, очистка провалилась.
Простой пример из маленькой продуктовой команды
Пятерка инженеров держала в одном репозитории веб‑приложение, API и фонового воркера. Сначала это было нормально, но PR превратились в мучение. Каждый PR запускал полную установку зависимостей и весь набор тестов, даже когда кто‑то менял один обработчик API или текст кнопки.
Результат был предсказуем. Ревью простаивали, пока CI прогонял browser‑тесты, unit‑тесты, API‑проверки и проверки воркера одним большим циклом. Люди начали группировать изменения, чтобы не ждать дважды, и это замедляло ревью и увеличивало риск.
Они не покупали большие раннеры в первую очередь. Они почистили репо.
Сначала выделили browser‑тесты в отдельную задачу, которая запускалась только при изменениях UI или при мердже в main. Этот шаг убрал много лишней работы, потому что эти тесты были самой медленной частью.
Дальше пересмотрели зависимости. В репо всё ещё лежали два старых SDK после миграции и дублирующие хелперы, которые копировались из разных частей кода. Каждая установка тянула пакеты, которыми уже не пользовались, а тестовые задания загружали похожие хелперы несколько раз.
Они убрали старые SDK, объединили дублирующие хелперы и почистили пути импортов так, чтобы каждая область репо имела ясное место. Код стал легче читать, но главный выигрыш — в CI: меньше пакетов означало быстрее установки, меньшие кэши и меньше случайных сбоев.
Через неделю мелких изменений большинство PR перестали запускать browser‑тесты, время установки упало, меньше стало таймаутов, и ревьюеры получали результаты, пока работа ещё была свежа в голове. Среднее время CI снизилось примерно с 22 до 10 минут.
Это тот тип улучшений, который помогает каждый день. В подобных случаях скучные привычки репозитория побеждают более мощные раннеры.
Ошибки, которые держат сборки медленными
Медленный CI обычно рождается из мелких решений в репозитории, которые никто не пересматривает. Команды добавляют ещё одно задание, ещё один пакет, ещё одну попытку — и ожидание растёт, пока люди не решают, что им нужны более мощные раннеры.
Это часто самая дорогая ошибка. Если один шаг тратит шесть минут на скачивание пакетов, генерацию файлов или повторные нестабильные тесты, более мощная машина просто сжигает больше денег, пока те же плохие практики остаются.
Общий кэш между несвязанными заданиями — тихая проблема. Звучит аккуратно, но часто приводит к промахам кэша, устаревшим файлам и случайным пересборкам. Фронтенд‑установка, бэкенд‑сборка и browser‑тесты редко нуждаются в одинаковом кэше. Когда они борются за один бакет, CI тратит время на распаковку не тех вещей или пересборку после порчи кэша.
Сгенерированные файлы в репозитории тоже замедляют прогоны. Они делают клоны тяжелее, создают шумные диффы и меняются чаще, чем ожидают. Это означает больше инвалидирования кэша и лишнюю работу для заданий, которым эти файлы не нужны. Если CI может генерировать их по запросу, лучше держать их вне репо.
Флейки‑тесты тратят больше времени, чем команды признают. Худший вариант — когда один нестабильный тест заставляет весь рабочий процесс перезапускаться. Десятиминутный пайплайн становится двадцатиминутным, потом тридцатиминутным, и никто не верит зелёному чек‑марку. Изолируйте флейки, карантинируйте при необходимости и перезапускайте только упавшую область.
Ещё одна распространённая трата — запускать весь пайплайн на каждой ветке. Опечатка в документации не должна триггерить тот же путь, что релизный кандидат. Многие команды говорят, что хотят более быстрый CI, но продолжают запускать сканы безопасности, полные browser‑наборы и упаковку на каждый пуш. Это вопрос политики, а не оборудования.
Лучший дефолт прост: измерьте самые медленные задания перед изменением размера раннера, разделяйте кэши по типам заданий и lockfile, держите сгенерированные артефакты вне репо, перезапускайте упавшие тесты вместо целых воркфлоу и оставляйте полный пайплайн для main, релизов или ночных прогонов.
Эта очистка не эффектна, но она меняет ежедневную работу. Команды получают фидбек раньше, тратят меньше на CI и перестают рассматривать каждую сборку как налог на доставку кода.
Быстрые проверки перед покупкой мощнее
Больше CPU может временно скрыть лишнюю работу. Оно не исправит репозиторий, который заставляет CI делать тяжёлую работу при каждом маленьком изменении. Прежде чем платить за более мощные раннеры, проверьте правила, которые решают, что запускать.
Пара быстрых проверок обнаружит большую часть беспорядка:
- Измените один файл документации и посмотрите, что запускается. Если CI всё ещё собирает приложение, запускает полные тесты и готовит артефакты релиза — ваши триггеры слишком широки.
- Откройте дерево тестов и сравните его с заданиями. Unit, integration и browser‑тесты должны находиться в местах, наглядно позволяющих разделять их.
- Прочитайте шаг установки построчно. Уберите инструменты, SDK, браузеры и пакеты, которые не нужны нескольким заданиям.
- Просканируйте имена скриптов в package‑файле, Makefile или конфиге CI. Чёткие имена уменьшают ошибки и делают настройку заданий понятнее.
- Попробуйте ветку с изменениями только в документации. Тяжёлые задания должны её пропускать, если только сборка документации не требует специальных проверок.
Малые команды обычно находят один и тот же паттерн: одна общая установка тянет всё, одна гигантская команда тестов запускает все наборы, и одно широкое правило пути будит весь пайплайн. Одна строка в /docs тогда стоит так же, как реальное изменение кода.
Фикс обычно скучный — и в этом его преимущество. Переименуйте скрипты, чтобы люди понимали их назначение с первого взгляда. Разместите тесты в папках, соответствующих заданиям, разделите установки, чтобы браузерные инструменты не попадали в простые unit‑задачи. Добавьте правила для изменений только в документации, чтобы CI делал лёгкие проверки и пропускал дорогие.
Такая очистка часто экономит больше времени, чем апгрейд раннера, потому что сокращает работу, а не только ожидание. Если хотя бы две из этих проверок провалены — исправляйте их в первую очередь.
Часто задаваемые вопросы
Действительно ли более мощные раннеры решают проблему медленных сборок?
Обычно — лишь немного. Больше CPU заставляет уже выполняемую работу закончиться быстрее, но не устраняет лишнюю работу.
Если каждый пулл‑реквест по‑прежнему устанавливает старые пакеты, запускает несвязанные тесты и собирает то, что не менялось, более мощный раннер просто дороже выполняет те же плохие практики.
Как понять, замедляют ли CI привычки моего репозитория?
Измерьте полный прогон от checkout до выгрузки артефактов и сравните каждый шаг с прогоном на локальной машине. Медленная настройка, холодные кэши, широкие триггеры и дополнительные шаги только в CI часто объясняют разницу.
Также посмотрите, что запускается после маленького изменения — например, правки в документации или текста UI. Если просыпается весь пайплайн, правила репозитория требуют правки.
Что сначала измерять в медленном пайплайне?
Начните с таймингов для checkout, установки зависимостей, сборки, тестов и загрузки артефактов. Это покажет, куда уходит время.
Многие сначала винят тесты, но установка и настройка часто съедают больше минут, чем ожидают.
Как называть папки и скрипты, чтобы CI работал лучше?
Используйте короткие, понятные и стабильные имена, которые соответствуют реальным областям продукта. Если папка называется admin, держите пакет и скрипты с похожими именами.
Чёткие имена упрощают правила по путям, кэшаванию и селективным запускам тестов. Расплывчатые папки вроде misc, temp или old обычно подталкивают CI к широким правилам.
Как лучше раскладывать тесты для более быстрого CI?
Держите unit‑тесты рядом с кодом, который они проверяют, а медленные тесты — в отдельных папках. Чистое деление позволяет CI запускать только ту группу, что соответствует изменению.
Не позволяйте одной команде по‑умолчанию захватывать всё. Разделите unit, integration, browser и smoke проверки, чтобы разработчики получали быстрый фидбек в первую очередь.
Должны ли изменения в документации запускать полный пайплайн?
Нет. Документо‑только изменения обычно должны запускать лёгкие проверки, а не полные сборки, browser‑тесты или шаги релиза.
Если маленькие правки пробуждают тот же путь, что и реальные изменения в коде, правила триггеров слишком широки и все платят за это.
Какие зависимости стоит чистить в первую очередь?
Начните с пакетов, которые никто больше не импортирует, старых SDK после миграций, дублирующих хелперов и тяжёлых инструментов, которые нужны только одной рабочей ветке. Это обычно безопасные и быстрые выигрыши.
Особое внимание уделите postinstall‑скриптам: браузерные инструменты, нативные модули и крупные бинарники быстро тянут сотни мегабайт при каждой чистой установке, даже если большинство задач их не использует.
Хорошая ли идея использовать общий кэш для всех заданий?
Обычно — нет. Фронтенд‑установки, бэкенд‑сборки и browser‑тесты часто требуют разного содержимого кэша.
Когда несвязанные задания делят один кэш, это приводит к пропускам, устаревшим файлам и случайным пересборкам. Лучше разделять кэши по типу задания и lockfile.
Что маленькая команда может сделать за неделю, чтобы ускорить CI?
Выделите неделю и держите объём работы малым. Сначала измерьте недавние прогоны и зафиксируйте медленные шаги. Затем исправьте широкие задания, переименуйте запутанные пути, разделите тесты, удалите неиспользуемые пакеты и перезапустите пайплайн несколько раз.
Оставляйте только те изменения, которые экономят время, не скрывая при этом ошибки. Если люди перестали доверять результатам, очистка провалилась.
Когда имеет смысл приглашать внешнего эксперта для ревью CI?
Привлекать внешних экспертов имеет смысл, когда команда продолжает гадать, одни и те же нестабильные задания возвращаются или нет времени распутать репозиторий и правила пайплайна.
Свежий взгляд часто быстро замечает ошибки с путями, неверные разделения кэша и старые зависимости. Если нужен такой обзор, Oleg Sotnikov на oleg.is работает в роли Fractional CTO и консультирует стартапы и SMB: он помогает с ревью инженерных процессов, инфраструктуры и переходом к AI‑ориентированной разработке до того, как увеличивать расходы на облако или инструменты.