Turborepo, Nx или обычные workspaces для растущих команд
Turborepo против Nx и обычных workspaces: сравните кэширование, граф задач, сложность настройки и размер команды, чтобы выбрать самый простой вариант для репозитория.
Содержание
Почему этот выбор быстро становится запутанным
Монорепозиторий часто начинается с малого. Одно приложение, один общий пакет, несколько npm-скриптов — и всё кажется простым.
Через полгода у каждого пакета уже есть свои команды для сборки, тестов, lint и запуска в разработке. Какие-то скрипты дублируют друг друга. Какие-то устарели. Никто уже не уверен, какие из них действительно нужны.
Проблема обычно сначала проявляется в CI. Один разработчик может спокойно пережить лишние 20 секунд на ноутбуке и пойти дальше. А команда быстро замечает, когда каждый pull request пересобирает всё, дважды запускает одни и те же тесты и каждый день тратит минуты CI впустую.
Именно здесь выбор между обычными workspaces, Turborepo и Nx становится размытым. Команды редко останавливаются и спрашивают: «Что на самом деле тормозит?» Они реагируют на боль, которую видят. Если CI медленный, добавляют кэш. Если скрипты беспорядочные, добавляют task runner. Если границы пакетов слишком расплывчатые, вводят правила. Иногда это помогает. Иногда просто добавляет ещё один слой поверх настройки, которую никто так и не навёл в порядок.
Небольшой пример показывает проблему очень ясно. Допустим, у вас есть web-приложение, admin-приложение и общий пакет с UI. Один человек добавляет собственные shell-скрипты в корне. Другой пишет скрипты на уровне пакетов, которые делают почти то же самое. CI связывает всё это своими командами. И вот у вас уже три места, где нужно искать одну проблему со сборкой.
Обычные workspaces уже решают часть этой задачи. Они держат пакеты в одном репозитории и в одном графе зависимостей. Для некоторых команд этого хватает очень надолго. Другим нужен кэш-aware подход к сборкам или инструмент, который понимает порядок задач между пакетами. Ошибка — выбирать более крупный инструмент раньше, чем вы доказали, что он действительно нужен.
Такой выбор остаётся с командой на годы. Инструмент влияет не только на скорость сборок. Он формирует правила папок, названия скриптов, настройку CI и то, как новички осваивают репозиторий. Если выбрать лишнюю сложность, команда будет нести этот груз очень долго.
Что уже решают обычные workspaces
Обычные workspaces решают больше, чем многие команды ожидают. Они позволяют приложениям и общим пакетам жить в одном репозитории и связываться друг с другом без ручного подключения, неудобной локальной публикации и копипаста.
Это снимает много ежедневного раздражения. Новый разработчик может клонировать репозиторий, выполнить одну установку в корне и сразу получить приложения и общие пакеты. Не нужно запускать отдельную установку для каждой папки и гадать, какую локальную версию пакета кто-то забыл обновить.
Обычные скрипты тоже отлично работают, если у репозитория хорошие границы. Если каждое приложение само отвечает за сборку, тесты и запуск, скрипты workspaces остаются понятными. Общий UI-пакет, API-клиент и два приложения вполне могут жить на простых командах уровня пакета вроде build, test и lint.
Для многих команд workspaces достаточно, если общие пакеты меняются реже, чем приложения, сборки завершаются быстро, одно изменение не запускает работу по всему репозиторию, и людям понятно, какой пакет за что отвечает.
В такой настройке дополнительный инструмент может казаться тяжелее самой проблемы. Вы добавляете конфигурацию, специальные команды и больше правил, а повседневная работа почти не меняется. Простота часто лучше, особенно для маленькой команды, которой нужно меньше движущихся частей.
Типичный пример — стартап с одним web-приложением, одним admin-приложением и общим пакетом типов. Одна установка в корне работает. Локальные пакеты резолвятся правильно. Скрипты остаются читаемыми. Если каждая сборка занимает минуту или две и пакеты не переплетены сложными зависимостями, обычные workspaces уже справляются.
Это не значит, что репозиторий навсегда останется простым. Это значит, что дополнительная сложность должна заслужить своё место. Если сборки всё ещё короткие и в основном независимые, workspaces уже снимают первую боль, которую чувствует большинство команд.
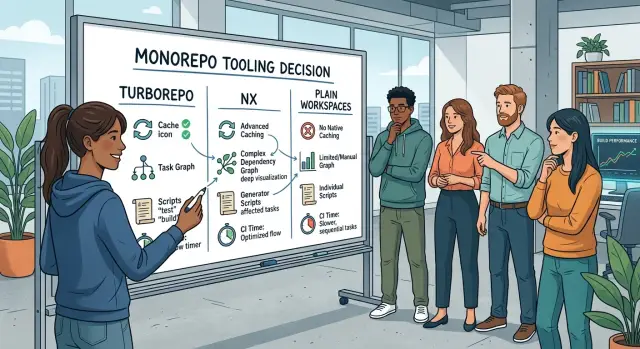
Что меняет Turborepo
Turborepo обычно не меняет форму репозитория. Большинство команд оставляют те же package scripts, которые уже используют: build, test, lint и typecheck. Turborepo работает поверх этих скриптов, запускает их между пакетами в правильном порядке и по возможности распараллеливает работу.
Главное изменение — кэширование. Если входные данные задачи не изменились, Turborepo может взять старый результат вместо повторного запуска. Вы перестаёте снова и снова платить за одну и ту же сборку, если код не менялся.
На бумаге это звучит скромно, но в повседневной работе ощущается очень сильно. Сборка, которая в первый раз занимает 4 минуты, может занять всего несколько секунд при следующем запуске, если вы изменили один маленький файл. Это даёт реальную экономию времени, особенно когда разработчики много раз повторяют одни и те же проверки перед merge.
Попадание в кэш обычно зависит от простых вещей: файлов в пакете, файлов в зависимых пакетах, самой команды и любых переменных окружения, которые объявлены для задачи. Если эти входные данные не меняются, можно переиспользовать старый результат.
Remote cache делает это ещё полезнее для команды. Если CI уже собрал и протестировал пакет, другой разработчик может использовать этот результат локально вместо того, чтобы делать ту же работу заново. И наоборот: разработчик может отправить коммит, а CI сможет переиспользовать работу, которая уже выполнилась на этой машине. Меньше повторов — быстрее обратная связь.
Turborepo часто хорошо подходит командам, у которых репозиторий в целом уже работает, но кажется медленным и немного неаккуратным. Возможно, у каждого пакета свои скрипты, люди запускают чуть разные команды, а CI повторяет слишком много работы на каждом pull request. В таком случае Turborepo часто даёт прирост скорости без необходимости переосмысливать весь репозиторий.
Представьте репозиторий с web-приложением, общим UI-пакетом и API-клиентом. Вы меняете текстовый файл в приложении. С обычными скриптами репозиторий всё равно может пересобрать больше, чем нужно, потому что старые команды никто не приводил в порядок. Turborepo может пропустить большую часть этого и запустить только то, что реально затронуло изменение.
Что меняет Nx
Nx даёт репозиторию более чёткую карту. Он строит project graph, то есть отслеживает, какое приложение, пакет или библиотека зависит от каких других частей. Звучит абстрактно, но результат очень простой: инструмент может понять, что именно затронет изменение, ещё до того, как вы запустите целую пачку скриптов.
Это становится важно, когда репозиторий перестаёт быть маленьким. Если кто-то меняет общий UI-пакет, Nx видит, что от него зависит web-приложение, а внутренний worker service — нет. Больше не нужно гадать, какие сборки и тесты запускать.
Команды affected — это то, что делает Nx особенно полезным в повседневной работе. Вместо того чтобы пересобирать всё после каждого коммита, Nx сужает работу до проектов, связанных с изменением. Небольшое правка в одной библиотеке может запустить тесты для двух приложений и пропустить остальные двенадцать. За неделю это экономит много ожидания.
Где проявляется дополнительная структура
Nx обычно требует, чтобы команда описывала репозиторий более явно. У проектов должны быть понятные имена, чёткие targets и объявленные зависимости. Скрытые связи, разовые скрипты и привычка «у меня на машине работает» обычно ломают эту модель.
Эта дополнительная структура помогает большим репозиториям оставаться аккуратными. Новые пакеты следуют тем же шаблонам. CI становится проще понимать. Люди могут посмотреть на graph и понять, как устроен репозиторий, не читая каждый пакет вручную.
Но за это приходится платить. Настройка требует больше усилий, чем обычные workspaces, и команда должна поддерживать репозиторий в честном состоянии. Если разработчики обходят Nx, подключают скрипты случайным образом или оставляют зависимости неясными, graph становится менее полезным.
Небольшой команде с тремя пакетами такой overhead может казаться лишним. Растущей команде с множеством приложений, общими библиотеками и разными владельцами часто, наоборот, становится легче. В таком случае Nx может навести порядок в репозитории, который иначе расползался бы в хаотичный набор скриптов.
Как кэш и task graph влияют на повседневную работу
Кэширование очень приятно, когда оно действительно работает. Вы меняете один файл, снова запускаете команду, и репозиторий пропускает то, что уже знает как неизменившееся. Это может сэкономить несколько секунд в маленьком репозитории или несколько минут в загруженном.
Но есть важная оговорка: кэш помогает только тогда, когда задачи каждый раз ведут себя одинаково. Если build-скрипт записывает текущую временную метку в выходной файл, подтягивает меняющуюся переменную окружения или зависит от файлов, которые никогда не объявлял, кэш будет промахиваться. Тогда люди перестают доверять инструменту, потому что одна и та же команда в понедельник работает быстро, а во вторник — медленно.
Task graph важен, когда один пакет влияет на многие другие. Допустим, команда обновляет общий UI-пакет. Если репозиторий знает, что от него зависят два приложения, один набор тестов и docs-пакет, он может запустить только задачи, затронутые этим изменением. Без такого graph команды часто возвращаются к грубым командам вроде «собрать всё» или «протестировать всё». Это быстро надоедает.
У стабильных задач обычно есть несколько общих признаков. Они читают понятные входные данные, пишут понятные выходные данные, не зависят от случайностей и времени, и используют одну и ту же команду локально и в CI.
Плохие скрипты вызывают два вида боли. Во-первых, они убивают попадания в кэш, поэтому локальные запуски замедляются, а счета за CI растут. Во-вторых, они создают странные ошибки. Скрипт может пройти, если запускать его отдельно, а потом сломаться в полном pipeline, потому что тайно зависел от того, что другая задача уже выполнилась. Это тратит больше времени, чем просто медленная сборка.
Эти проблемы обычно идут вместе. Когда разработчики дольше ждут на своих ноутбуках, CI обычно тоже работает дольше. Когда CI тянется, команды читают больше логов и повторяют больше jobs. Когда попыток становится слишком много, отладка усложняется, потому что никто не понимает, это реальная ошибка или просто хрупкий скрипт.
Именно поэтому команды с дисциплинированными скриптами часто получают от кэша больше пользы, чем команды с более крупными репозиториями. Инструмент важен. Но ещё важнее чистые входные данные задач.
Как выбирать шаг за шагом
Большинству команд стоит начинать с наблюдения, а не с нового инструмента. Если вы не знаете, что запускается каждую неделю, что занимает слишком много времени и что ломается чаще всего, выбор превращается в угадайку.
Запишите задачи, которые команда действительно выполняет. Будьте конкретны: установка зависимостей, lint, type check, unit tests, сборка приложений, сборка пакетов, preview builds, release-шаги и CI jobs. Репозиторий с двумя приложениями и общим UI-пакетом имеет совсем другие потребности, чем репозиторий с десятью пакетами, несколькими целями сборки и тяжёлым CI.
Затем засеките время этих задач, не меняя ничего. Измеряйте локальные запуски на обычной машине разработчика, а не на самом быстром ноутбуке в компании. Измерьте и CI. Если чистая установка, тесты и production build уже завершаются достаточно быстро, новый инструмент может добавить больше конфигурации, чем сэкономит времени.
После этого разберите реальные зависимости между пакетами. Команды часто думают, что всё зависит от всего остального. Обычно это не так. Нарисуйте простую схему или таблицу. Если изменение в одном пакете не должно пересобирать четыре не связанные между собой приложения, значит, у вас уже есть реальная причина подумать о кэшировании или task-graph инструменте.
Практичный путь выглядит так:
- Оставайтесь на обычных workspaces, если скрипты всё ещё читаемые и большинство людей понимают, как работает репозиторий.
- Выбирайте Turborepo, если повторные сборки и CI отнимают время, но границы пакетов уже выглядят разумно.
- Выбирайте Nx, если вам нужны кэширование, более строгие границы проектов, генераторы и более жёсткий контроль над тем, как связаны задачи.
- Остановитесь, если никто не может назвать точную боль. «Репозиторий выглядит грязно» — слишком расплывчато.
Небольшой пример помогает понять это лучше. Если у вас одно web-приложение, один worker и два общих пакета, обычных workspaces может хватить на месяцы. Если CI снова и снова пересобирает одни и те же пакеты, Turborepo начинает приносить пользу. Если команда постоянно нарушает границы пакетов, создаёт странные импорты и спорит о правилах сборки, Nx может сэкономить больше времени.
Выбирайте самый маленький инструмент, который решает сегодняшнюю проблему. Добавляйте больше только тогда, когда можете указать на конкретные потерянные минуты.
Простой пример команды
Представьте команду из шести человек. У них одно приложение на Next.js для клиентов, один API для внутренних и публичных данных и два общих пакета: UI-библиотека и небольшой пакет с типами и хелперами. В большинстве случаев разработчик меняет приложение и один общий пакет, затем отправляет ветку и ждёт CI.
Сначала обычные workspaces кажутся вполне нормальными. Установка проще, локальные импорты чище, а общие пакеты перестают превращаться в копипасту. Если приложение собирается за 20–40 секунд, а тесты заканчиваются быстро, добавление ещё одного инструмента может ощущаться как плата за аренду дома, которым вы почти не пользуетесь.
Это как раз тот момент, который многие упускают. Если сборки всё ещё занимают секунды, workspaces уже решают самую неприятную часть: один репозиторий, общий код и меньше скриптов, за которыми нужно присматривать.
Теперь команда растёт. Небольшое изменение в shared types package запускает сборки для приложения, API и пары тестовых jobs. CI увеличивается с менее чем 2 минут до 8–10. Разработчики открывают pull request и потом ждут так долго, что теряют фокус.
Вот здесь Turborepo часто становится первым разумным шагом. Команда сохраняет ту же структуру репозитория, добавляет определения задач и получает кэширование сборок без большой переписки проекта. Если изменились только одно приложение и один общий пакет, CI может пропустить работу, которая уже не нужна. Это способно сократить несколько минут у каждого pull request.
Nx начинает лучше подходить в немного другой версии той же истории. Представьте, что репозиторий вырос до трёх приложений, двух API, общих design rules, общих lint rules и более строгого процесса релиза. Тогда проблема уже не только в скорости. Команде нужны ещё и более чёткие границы, правила зависимостей и лучший контроль над тем, что может от чего зависеть.
Простое правило хорошо работает:
- Используйте обычные workspaces, когда репозиторий маленький, а сборки остаются быстрыми.
- Попробуйте Turborepo, когда CI замедляется, но структура всё ещё выглядит управляемой.
- Выбирайте Nx, когда многие приложения разделяют правила, зависимости и общие для команды соглашения.
Большинству команд не нужна самая большая настройка в первый день. Им нужен самый маленький инструмент, который убирает сегодняшнюю задержку и не создаёт завтрашнюю работу по поддержке.
Ошибки, которые крадут время
Больше всего времени команды теряют, когда сначала решают не ту проблему. Репозиторию с несколькими пакетами и несколькими надоедливыми скриптами обычно не нужен самый сложный инструмент прямо сейчас. Прежде чем становиться на чью-то сторону, измерьте уже существующую боль: медленный CI, повторные сборки, сложные релизы или слишком много сломанных package scripts.
Кэшу часто придают слишком большое значение, когда настоящая проблема — это беспорядочные скрипты. Кэширование хорошо работает только тогда, когда задачи делают одну и ту же работу из одинаковых входных данных. Если скрипт читает текущее время, пишет файлы в случайные папки, зависит от необъявленных env vars или вызывает живой API во время сборки, попадания в кэш будут редкими или небезопасными.
Быстрая проверка помогает:
- Выход сборки меняется, хотя код не менялся.
- Тесты зависят от состояния локальной машины.
- Скрипты подтягивают данные во время сборки.
- Пакеты читают файлы вне своей папки.
Слабые границы пакетов тоже медленно съедают время. Команды говорят, что у них отдельные пакеты, но приложения импортируют внутренние файлы друг друга, общий код превращается в один огромный utils-каталог, и каждое маленькое изменение трогает половину репозитория. В такой ситуации task-graph-инструменты мало чем помогут, потому что сама форма зависимостей уже неряшливая.
Ещё одна ловушка — копировать большой пример конфигурации. Настройка может выглядеть аккуратно, но если никто в команде не может объяснить, почему одна задача зависит от другой, маленькие изменения превращаются в долгую отладку. Простая конфигурация, которую все понимают, лучше, чем умная конфигурация, которую может исправить только один человек.
Remote cache в CI звучит дешево, пока вы не начинаете считать хранилище, правила доступа и cache misses между ветками. Нужно заранее решить, кто может читать сохранённые артефакты, должны ли ими делиться pull request'ы и что происходит, если на выход сборки влияют секреты. Если это не продумать, remote cache добавит и расходы, и путаницу.
Часто побеждает самый скучный выбор: чистые скрипты, понятные границы пакетов и ровно столько инструментов, сколько нужно, чтобы убрать реальное узкое место.
Быстрые проверки перед тем, как решиться
Большинству команд не нужен ещё один слой инструментов. Им нужно доказательство, что репозиторий теряет время в одних и тех же местах каждую неделю.
Если вы застряли между этими вариантами, просто понаблюдайте за тем, что люди делают два-три дня. Источник раздражения обычно проявляется быстро.
- CI снова и снова пересобирает и перетестирует пакеты, которые не менялись, поэтому pull request'ы стоят в очереди ради одной и той же работы.
- Разработчики прыгают между пакетами и запускают одни и те же скрипты вручную, потому что у репозитория нет одной команды, которой они доверяют.
- Попросите одного коллегу за две минуты объяснить границы пакетов. Если он не может сделать это без длинных отступлений, структура репозитория всё ещё размыта.
- Когда сборка падает, сообщение об ошибке указывает на весь репозиторий, а не на один пакет или одну задачу, поэтому люди начинают гадать.
- После настройки никто не хочет трогать конфиг, потому что он уже кажется хрупким или сложнее самого кода, которым управляет.
Эти сигналы важнее, чем списки возможностей. Команда может довольно долго жить с базовой настройкой монорепозитория, если скрипты последовательны, владение пакетами понятно, а CI остаётся достаточно быстрым.
Простое правило помогает. Если на один или два вопроса вы отвечаете «да», обычных workspaces с более чистыми скриптами может хватить. Если «да» уже на три и больше, вам, скорее всего, нужно кэширование или task-graph-инструмент. Вот тогда Turborepo или Nx начинают действительно приносить пользу.
Будьте честны и насчёт поддержки. Дополнительный инструмент экономит время только если в команде есть человек, который будет поддерживать конфигурацию в порядке по мере роста репозитория. Если такого человека нет, выберите более простую настройку и вернитесь к вопросу через месяц или два.
Лучший выбор — это обычно тот, который ваша команда всё ещё поймёт уставшим четвергом во второй половине дня.
Следующие шаги для вашего репозитория
Выберите самое маленькое изменение, которое решит проблему, которую команда ощущает на этой неделе. Если люди в основном теряют время на повторяющиеся скрипты и запутанные связи между пакетами, обычных workspaces может хватить. Если CI всё время пересобирает один и тот же код, кэширование, вероятно, стоит проверить.
Не меняйте весь репозиторий сразу. Создайте одну ветку, перенесите одно приложение и один общий пакет и поработайте так несколько дней в обычном режиме. Это скажет вам больше, чем долгий спор, особенно когда выбор всё ещё кажется абстрактным.
До начала теста запишите простую scorecard:
- минуты CI для обычного pull request
- время локальной установки и сборки
- усилия, чтобы объяснить инструмент новому коллеге
- число пользовательских скриптов, которые всё ещё нужны
- время, которое потребуется, чтобы откатить эксперимент, если он пойдёт плохо
Эти цифры делают разговор честным. Инструмент, который экономит 4 минуты в CI, но добавляет ежедневную путаницу, может не быть победой для маленькой команды. Монорепозиторий должен окупать сам себя.
Специально держите тест коротким и скучным. Одна ветка, одна неделя, несколько обычных задач. Если разработчики чувствуют пользу без длинной инструкции, это хороший знак. Если инструмент постоянно требует исправлений, репозиторию он, возможно, пока не нужен.
Если после этого выбор всё ещё неясен, поможет внешняя оценка. Другой инженер часто замечает то, к чему команда уже привыкла: например, границы пакетов, которые не совпадают с продуктом, или правила кэширования, которые добавляют сложность без заметной скорости.
Oleg Sotnikov в oleg.is работает Fractional CTO и startup advisor, и именно такие задачи он помогает командам разбирать. Если вам нужен второй взгляд на структуру репозитория, инфраструктуру или практичный шаг в сторону AI-first development, короткое ревью может сэкономить вам долгую миграцию, которая вам и не была нужна.
Часто задаваемые вопросы
Нужны ли мне инструменты сложнее, чем обычные workspaces?
Начните с plain workspaces, если репозиторий легко объяснить, сборки завершаются достаточно быстро, а люди понимают, какой пакет за что отвечает. Добавляйте более сложный инструмент только тогда, когда можете точно показать, где уходит время, обычно в CI или при сборке между пакетами.
Когда стоит выбрать Turborepo?
Выбирайте Turborepo, когда структура репозитория уже нормальная, но сборки и CI снова и снова делают одну и ту же работу. Обычно он помогает командам, которым нужен кэш и более умный порядок запуска задач, без перестройки всего репо.
Когда Nx подходит лучше, чем Turborepo?
Nx лучше подходит, когда скорость — не единственная проблема. Если вам ещё нужны более строгие границы пакетов, project graph и более жёсткий контроль над тем, какие изменения на что влияют, Nx обычно даёт больше пользы, чем более лёгкий инструмент.
Исправит ли кэш медленный CI сам по себе?
Кэш помогает не всегда сам по себе. Он работает только тогда, когда задачи используют стабильные входные данные и дают одинаковый результат для одного и того же кода. Если скрипты тянут живые данные, зависят от скрытых env vars или пишут случайные файлы, промахи кэша будут появляться снова и снова.
Почему мои cache hits постоянно не срабатывают?
Чаще всего промахи возникают из-за грязных скриптов, а не из-за инструмента кэша. Проверьте, не читает ли сборка неописанные файлы, не использует ли timestamps, не зависит ли от состояния локальной машины и не меняет ли вывод, хотя код остался тем же.
Может ли маленькая команда остаться на обычных workspaces?
Да. Небольшая команда может долго жить на обычных workspaces, если установка проста, скрипты пакетов остаются понятными, а сборки заканчиваются за секунды или пару минут. Более сложная настройка не нужна только потому, что в репозитории больше одного приложения.
Переход с workspaces на другой инструмент — это большая миграция?
Обычно нет. Многие команды могут добавить Turborepo поверх существующих package scripts и проверить его на одной ветке. Nx часто требует больше наведения порядка, потому что он лучше работает, когда проекты названы одинаково и зависимости описаны честно.
Как понять, что границы моих пакетов слабые?
Смотрите на импорты, которые лезут во внутренние файлы другого пакета, на общие папки, превращающиеся в свалку, и на мелкие изменения, после которых пересобирается половина репозитория. Обычно это значит, что разделение на пакеты выглядит аккуратно только на бумаге, но не в реальной работе.
Что стоит измерить перед сменой инструментов для монорепозитория?
Измерьте время обычного pull request, время локальной установки, локальной сборки и количество скриптов, которые люди запускают вручную, потому что не доверяют одной команде. Ещё посмотрите, сколько времени нужно коллеге, чтобы объяснить репозиторий без догадок.
Когда стоит попросить внешнее ревью?
Приглашайте другого инженера, когда команда не может назвать реальное узкое место, конфиг уже кажется хрупким, или все варианты начинают выглядеть одинаково плохо. Короткое ревью часто стоит меньше, чем долгая миграция, которая решает не ту проблему.


