Единый trace ID в разных системах для быстрого решения инцидентов
Единый trace ID между системами помогает проследить один запрос через приложения, очереди, инструменты ИИ и записи поддержки, чтобы находить ошибки быстрее.
Содержание
Почему одна ошибка превращается в долгое расследование
Тикет в поддержку часто начинается с расплывчатого сообщения: "Это не сработало" или "Я не получил результат." У поддержки есть клиент, время и, возможно, скриншот. Инженеры видят логи, задачи в очередях, API‑вызовы и ответы моделей. Каждое средство показывает свой фрагмент одного события, и по отдельности эти фрагменты не складываются.
Эта пробелы отнимают время быстро. У поддержки может быть номер тикета и ID пользователя. Бэкенд — request ID. Воркeр очереди создаёт свой job ID через несколько секунд. Если подключается модель ИИ, провайдер добавляет ещё один идентификатор. Одно действие клиента превращается в четыре‑пять записей, которые по‑разному описывают одну и ту же ошибку.
Команды начинают догадываться. Они ищут по времени, просматривают логи за минуту и пытаются сопоставить записи по форме полезной нагрузки или аккаунту. Это работает при низкой нагрузке и явной ошибке. Разваливается, когда одновременно проходит много похожих запросов.
Сценарий знаком: поддержка находит тикет и аккаунт. Один инженер смотрит логи приложения за нужный промежуток. Другой открывает панель очереди и ищет похожую задачу. Ещё кто‑то проверяет логи вызовов модели или консоль вендора. Команда спорит, какая запись относится к настоящей ошибке.
Очереди усугубляют ситуацию: они скрывают, где началась проблема. Оригинальный веб‑запрос может успешно завершиться, а воркер упадёт позже на другой машине. К этому моменту чистой истории уже нет: видна только неуспешная задача с локальным ID, но не предыстория.
Вызовы моделей добавляют слой путаницы. Подсказка (prompt) может переписываться, повторяться или делиться между инструментами до получения результата. Если команда использует несколько моделей или направляет запросы через внутренний сервис, след быстро становится грязным.
Именно поэтому важны trace ID по всем системам. Без одного общего идентификатора поддержка и инженеры не расследуют один инцидент — они сортируют горая фрагментов и надеются, что выбрали правильную стопку.
Что даёт trace ID
Trace ID — это одна ссылка на один запрос. Его создают при старте запроса и прикрепляют к каждому последующему шагу. Звучит мелко. Но меняет многое.
Без общей ссылки каждая команда ищет по времени, имени клиента, email, номеру заказа или интуиции. Эти подсказки помогают, но приносят шум. Один trace ID прорезает этот шум и указывает на один путь через систему.
При правильном использовании trace ID группируют логи, повторы и ошибки под одной ссылкой. Они показывают: началась ошибка в приложении, воркере, внешнем API или в вызове модели. Можно сравнить первую неудачу с последующими повторами, вместо того чтобы считать каждое событие отдельной проблемой. И поддержка, и инженерия получают одинаковую метку для поиска.
Это важнее, чем многие ожидают. Поддержке не нужно каждый раз переводить историю клиента в технический язык. Достаточно скопировать один ID в тикет, и инженеры найдут точно то же значение в логах, трассах, записях очереди и отчётах об ошибках. Никто не тратит 20 минут на споры, какой запрос соответствует действию пользователя.
Хороший trace ID показывает последовательность, а не только факт. Вы увидите не просто пять ошибок, а что приложение приняло запрос, воркер его подобрал, сработал один retry, вызов модели тайм‑аутился и финальный ответ потерпел неудачу. Эта последовательность обычно указывает, где исправлять.
Это особенно важно, когда система частично работает. Запрос может пройти в одном сервисе и упасть в другом. Если каждый retry и последующая задача несут тот же ID, след сохраняется. Полную историю можно восстановить за минуты, даже когда запрос трогали несколько инструментов и команд.
Для поддержки trace ID — это номер дела по конкретному инциденту. Для инженеров — самый короткий путь от симптома к причине.
Где должен «путешествовать» ID
ID помогает только если выживает при каждой передаче. Если он пропадает при переходе от приложения к очереди или от вызова модели к заметке поддержки, след рвётся.
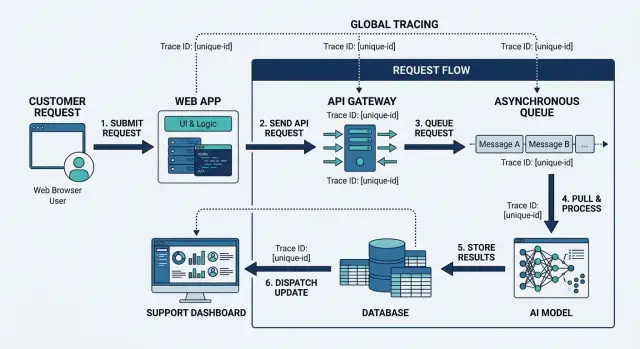
Начните на краю системы. Браузер, мобильное приложение или запрос партнёра должны отправлять trace ID в первом API‑вызове. Поместите его в заголовки запроса, контекст логов и в любые полезные поля ошибок, которые сохраняете для отладки. Если пользователь сообщает о проблеме, поддержка должна уметь запросить этот ID или извлечь его из сессии.
API должен не менять значение при вызове других сервисов. Не создавайте новый ID для каждого внутреннего хопа, если вы не храните явную связь parent‑child. Для повседневной отладки обычно достаточно одного общего идентификатора, чтобы проследить запрос через все системы.
Именно в очередях многие теряют след. Сообщения часто считают «новым стартом». Это не так. Когда API публикует задачу, сообщение должно нести trace ID в метаданных. Воркeр, взявший задачу, должен логировать тот же ID, передавать его сервисам и включать в записи о retry и dead‑letter.
AI‑флоу требует той же дисциплины. Если приложение вызывает модель, потом инструмент, потом другую модель, каждый шаг должен логировать тот же ID. То же относится к записям в базе: сохраняйте ID в audit‑строках, записях фоновых задач и событиях ошибок, чтобы инженер мог быстро ответить: какой запрос записал эту строку, какой ответ модели это вызвал и какой воркер обработал следующее действие.
Системы поддержки тоже важны. Если ID есть только в инженерных логах, поддержке всё ещё придётся просить помощи у техников. Помещайте trace ID в поля тикета, внутренние заметки, передачу в чат и записи инцидентов. Тогда поддержка сможет сказать: "Запрос 7f3a... упал после retry в очереди," вместо копирования скриншотов и догадок.
Один идентификатор должен появляться в пользовательском запросе, логах сервисов, метаданных очереди, вызовах моделей и инструментов, активности базы и записи поддержки, которая запускает расследование.
Создавайте ID при первом контакте
Создавайте trace ID до любых действий системы. Если ждать до вызова базы, задачи или шага с моделью — часть истории уже потеряна. Поддержке нужен один референс, который начинается с первого контакта и остаётся с запросом до конца.
Первый контакт зависит от продукта: это может быть HTTP‑запрос в приложение, API‑шлюз, webhook или форма, отправленная клиентом. Выберите этот край и каждый раз создавайте ID там.
Формат держите коротким и удобным для людей. Длинный UUID удобен для машин, но неудобен на звонке поддержки. Что‑то вроде RF7K-29QX или ORD-84M2P9 обычно проще, если только это достаточно уникально для вашей нагрузки.
Сразу сохраняйте его в контексте запроса. Не оставляйте ID в одном контроллере или одной строке лога. Ваше приложение должно относиться к нему как к базовым данным запроса, так же как к текущему пользователю, аккаунту или сессии. Тогда каждая строка лога, вызов модели, сообщение в очереди и заметка поддержки будет нести одно и то же значение без дополнительной работы.
Показывайте его клиенту, когда это полезно. Если платёж не прошёл — выведите короткий референс на экране ошибки. Если запрос прошёл, но может потребовать последующего действия, включите тот же ID в экран подтверждения или на чек. Это может сократить переписку с поддержкой с десяти сообщений до двух.
Именно здесь trace ID либо работают, либо рушатся. Если ID генерируется поздно, каждая команда строит собственную частичную историю. Если он стартует на краю, один поиск восстанавливает весь путь за минуты.
Простое правило: если человек может сообщить о проблеме, человек должен уметь прочитать ID.
Как его пронести от начала до конца
Trace помогает только если тот же ID переживает каждый хоп. Используйте один trace ID для одного действия клиента и копируйте его дальше без изменений. Если вы отчеканите новый ID в середине, след быстро теряет полезность.
Запишите ID в самой первой строке лога запроса. Делайте это, как только приложение, API или webhook принимает вызов, до взаимодействия с базой, очередью или моделью. Эта первая строка лога даст начало пути, даже если запрос умрёт сразу.
Далее копируйте поле в каждое сообщение очереди. Поместите его в payload или метаданные и относитесь как к обязательному полю, а не к приятному дополнению. Если воркер берёт сообщение, он должен сначала прочитать trace ID и загрузить его в собственный контекст логирования до ретраев, валидации или запуска следующих задач.
AI‑флоу требует той же дисциплины. Когда воркер вызывает модель, сохраняйте trace ID рядом с именем модели, версией подсказки, задержкой и текстом ошибки. Если модель вызывает инструмент, передавайте тот же ID, чтобы логи инструмента совпадали с исходным запросом. Это — разница между настоящей трассировкой и кучей разрозненных логов.
Записи поддержки тоже важны. При открытии кейса сохраняйте trace ID рядом с номером заказа, user ID или разговором. Поддержка сможет передать инженерам одну короткую строку вместо длинного рассказа о том, что видел клиент.
Одно правило упрощает: сохраняйте оригинальный trace ID на всём пути и добавляйте отдельные ID только для дочерней работы. Пакетная задача, попытка retry или шаг инструмента могут иметь свой job_id или step_id, но родительский trace ID должен оставаться тем же.
Команды часто пропускают это в корреляции сообщений очереди: логируют входящий запрос, а потом забывают ID при старте асинхронной работы. Простой чек помогает: откройте любой упавший инцидент и посмотрите, можно ли отследить один ID от первой строки лога запроса до логов воркера, вызовов модели, инструментов и тикета поддержки без догадок.
Простой пример с неудачным возвратом денег
Клиент открывает приложение после двойного списания и нажимает "Request refund." Приложение отправляет запрос на API. При первом контакте API создаёт trace ID, например trc_9a7f2c, и прикрепляет его к запросу, записи о возврате и строке лога этого вызова.
API принимает запрос и ставит задачу возврата в очередь. Тот же trace ID попадает в метаданные сообщения, чтобы воркер, который возьмёт задачу, не придумывал новую идентичность для того же случая. Это маленькое решение имеет значение дальше.
Через несколько секунд воркер читает сообщение и отправляет кейс модели. Возможно, модель проверяет, не дубликат ли это списания, ошибка биллинга или возможное злоупотребление. Воркeр передаёт тот же trace ID в вызов модели, логирует время старта и ждёт результат.
Потом шаг с моделью зависает. Провайдер не отвечает вовремя или ваш таймаут слишком мал для такого запроса. Через 30 секунд воркер сдается, помечает задачу как упавшую и записывает событие таймаута с тем же trace ID.
Теперь поддержка получает сообщение от клиента: "Мой возврат всё ещё в ожидании." Без общего ID поддержка начинает гадать: ищет по email в одном месте, по номеру заказа в другом и, может быть, по job ID очереди в третьем.
С trace ID по всем системам поддержка вводит одно значение и видит всю цепочку:
- API принял запрос на возврат в 10:14:03.
- Очередь сохранила задачу в 10:14:04.
- Воркeр начал вызов модели в 10:14:08.
- Вызов модели тайм‑аутнулся в 10:14:38.
- Возврат остался в статусе "pending review" вместо продвижения дальше.
Инженеры используют тот же ID, чтобы вытащить точные логи воркера, проверить таймаут и понять, сработали ли повторы или остановились слишком рано. Поддержка объясняет клиенту, что произошло простыми словами, а инженеры исправляют нужный шаг в первую очередь. Один поиск заменяет десять догадок.
Ошибки, которые рвут след
Большинство настроек трассировки ломаются по мелким, скучным причинам. Обычно проблема не в отсутствии логов, а в разорванной цепочке, где каждая система рассказывает свою часть истории, и никто не может быстро их соединить.
Обычная ошибка — создавать новый ID в каждом сервисе. Это кажется аккуратным, но убивает трассировку запросов. Если у API один ID, у воркера другой, а у модели третий, поддержка не поймёт путь. Держите один главный trace ID и используйте отдельные поля для локальных идентификаторов.
Повторы ещё порча. Задача очереди падает, спустя десять минут retry срабатывает, и код логирует попытку под новым ID. Тогда первая неудача и ретрай выглядят как разные события. Сохраняйте тот же trace ID, а номер попытки храните отдельно.
Команды также прячут ID в свободном тексте. Запись поддержки вроде "payment issue for trace abc123" лучше, чем ничего, но слаба: текст редактируют, копируют с ошибками или пропускают при поиске. Помещайте ID в структурированные поля логов, payload очередей, тикетов и админ‑экранов. Машины лучше ищут по полям, чем люди по предложениям.
Ещё легкий способ сломать след — показывать один ID поддержке, а инженеры логировать другой. Тогда поддержка спрашивает про дело 8F2K, а в логах есть только 19C7. Используйте одну видимую метку везде, где человек может коснуться проблемы: экран ошибки, тикет, внутренний дашборд и логи.
Запланированные задания и пакетные импорты часто игнорируют, потому что их никто не запустил кликом. Им тоже нужны ID. Ночной синк должен получать run ID, а каждая запись внутри — либо этот run ID, либо дочерний ID, который ссылается на него. Иначе упавшие записи выглядят случайными.
Короткий чек‑лист:
- Создавайте trace ID один раз на первом реальном входе.
- Передавайте его через каждый вызов, задачу, retry и инструмент.
- Храните в структурированных полях, а не только в свободном тексте.
- Показывайте одинаковый ID поддержке и инженерам.
- Давайте запланированной работе собственный трассировочный путь.
Команды, которые строят AI‑первые процессы с небольшой командой, особенно зависят от такой консистентности. Один пропущенный поле может превратить починку за 5 минут в полдня поиска.
Быстрые проверки перед запуском
Роллаут проваливается, когда ID есть в логах, но никто не может им воспользоваться. Перед публикацией тестируйте путь как реальный кейс поддержки, а не как разработчик, читающий по одному сервису.
Начните с клиентского экрана. Человек, который ведёт тикет, должен видеть один понятный идентификатор и копировать его в один клик. Если поддержке приходится открывать devtools, смотреть заголовки или просить инженера найти значение, система ещё не готова.
Потом проверьте поиск. Вставьте тот же ID в отображение логов приложения, просмотрщик очереди, логи фоновых задач, трекер ошибок и админ‑инструменты. Инженеры должны за несколько минут увидеть всю историю. В этом и смысл: один поисковый термин, одна временная шкала, меньше догадок.
Короткий пред‑запуск ловит большинство ошибок:
- Запустите один запрос в UI и подтвердите, что тот же ID появился в логе API, сообщении очереди и логе воркера.
- Форсируйте retry и убедитесь, что retry сохраняет оригинальный trace ID. Номер попытки храните отдельно.
- Сгенерируйте алерт и проверьте, что ID появляется в тексте алерта или в присоединённых данных события.
- Пропустите запрос через любой AI‑шаг и зафиксируйте ID в метаданных, логах или спанах, не записывая при этом приватные данные клиента рядом с ним.
- Передайте ID человеку вне инженерии и посмотрите, сможет ли он пройти по следу без помощи.
Повторы требуют особого внимания. Многие команды создают новый ID при повторном запуске задачи, и это ломает историю. Держите основной trace ID с первого действия пользователя до финального результата. Для детализации добавляйте номер попытки или дочерний job ID.
AI‑вызовы тоже нужно проверять: записывайте trace ID с именем модели, временем запроса, задержкой и статусом результата. Не прикладывайте сырые личные данные только потому, что вызов модели упал. Поддержке нужен контекст для расследования, а не копия приватного содержания.
Небольшая тренировка делает это реальным: попросите поддержку выбрать недавнее упавшее действие и пройти его через все инструменты. Если где‑то застревают — исправьте это до релиза.
Следующие шаги для вашей команды
Начните с простой карты полного пути запроса. Нарисуйте на одной странице путь одного действия клиента: браузер/приложение, API, фоновые задачи, очереди, вызовы AI, записи в базе, админ‑инструменты и экран поддержки, который используется, когда что‑то идёт не так.
Это упражнение обычно быстро показывает проблему. Большинству команд не хватает логов — им не хватает одной общей дорожки, которая показывает, где запрос переходил от руки к руке.
Выберите формат trace ID и назначьте ответственного за роллаут. Если каждая команда придумает собственную версию, след сломается рано и останется сломанным. Простой UUID подойдёт для большинства случаев, если все просто передают одно и то же значение дальше, а не создают новое по пути.
Держите внедрение небольшим. Выберите один реальный поток, например регистрацию, покупку или возвраты, и протестируйте его от конца до конца. Стартуйте действие с новым trace ID. Подтвердите, что тот же ID появляется в логах приложения, сообщениях очереди, логах воркеров, вызовах AI и заметках поддержки. Намеренно вызовите ошибку, чтобы команда могла отследить проблему без догадок. Запишите все места, где ID исчезает, меняется или зарыт.
Закройте эти пробелы до того, как строить дашборды или еженедельные отчёты. Красивая визуализация не поможет, если корреляция сообщений очереди ломается или поддержка не может найти тот же ID, что видит инженеры. Сначала чистая «труба», потом отчётность.
Когда путь работает, дайте поддержке простую процедуру поиска. Один ID должен позволять ответить на базовые вопросы за минуты: где начался запрос, кто к ним прикасался, где он упал и нужно ли перезапустить или делать ручную правку.
Если команда хочет внешнюю проверку, Oleg Sotnikov at oleg.is работает со стартапами и небольшими компаниями по вопросам AI‑первых разработок, инфраструктуры и процессов поддержки. Такие проблемы гораздо проще исправлять на раннем этапе, до тех пор, пока у каждой команды не появится собственная привычка трассировки.
Часто задаваемые вопросы
What is a trace ID?
Trace ID — это короткая ссылка на одно действие пользователя. Приложение создаёт его при первом запросе и передаёт через логи, задачи очереди, вызовы моделей, записи в БД и тикет поддержки.
Why not just search by time and user ID?
По времени и данным пользователя приходит много шума, когда одновременно проходит множество похожих запросов. Один trace ID указывает на единственный путь, так что поддержка и инженеры не догадываются, а сразу находят нужную запись.
Where should we create the trace ID?
Создавайте его при первом контакте — когда браузер, мобильное приложение или шлюз делает первый запрос. Если ждать до работы воркера или шага с моделью, начало истории теряется.
Should every service generate its own ID?
Нет. Сохраняйте один родительский trace ID для всего запроса и добавляйте локальные поля вроде job_id или step_id только для детализации. Если каждый шаг создаёт новый ID, след теряется.
How should queues handle the trace ID?
Поместите тот же trace ID в метаданные или тело сообщения очереди, а затем загрузите его в контекст логирования воркера до выполнения каких‑либо действий. Так вы свяжете API‑запрос, задачу в очереди, повторы и dead‑letter записи.
What should we do with retries?
Сохраняйте оригинальный trace ID во всех попытках (retry). Отдельно храните номер попытки, чтобы видеть оба факта: это тот же запрос и он выполнялся снова.
Do AI calls need the same trace ID?
Да. Передавайте trace ID в вызовы модели, вызовы инструментов и внутренние AI‑сервисы, логируйте его вместе с именем модели, задержкой и статусом результата. Тогда у вас будет единый след, даже если подсказки переписываются или разбиваются на шаги.
Should support see the trace ID?
Да. Показывайте короткий читаемый ID на экране ошибки или подтверждения и сохраняйте тот же идентификатор в тикете, чтобы поддержка могла передать инженерам точную ссылку на инцидент.
What data should we store with the trace ID?
Храните trace ID в структурированных полях рядом с нужными атрибутами: user ID, номер заказа, статус, задержка и текст ошибки. Не прикладывайте сырые приватные данные просто потому, что запрос упал.
How do we test the rollout?
Прогоните один реальный сценарий от начала до конца, намеренно вызовите ошибку и потом найдите тот же ID в логах, очередях, шагах AI и финальной ошибке. Если поддержка не может пройти путь сама — есть пробелы, которые нужно закрыть.


