Топологии OpenTelemetry Collector для продуктов в одном регионе
Топологии OpenTelemetry Collector для продуктов в одном регионе: узнайте, когда один gateway сохраняет простоту, а когда per-node agents помогают избежать потерь и шумных сбоев.
Содержание
Какую задачу вы решаете
Телеметрия помогает только тогда, когда она попадает в одно место по чистому и предсказуемому пути. Для продукта в одном регионе это обычно значит один понятный маршрут для logs, metrics и traces от приложения до хранилища и дашбордов, без лишних переходов.
Если не продумать схему, все быстро становится хаотичным. Один сервис отправляет данные напрямую в backend. Другой идет через коллектор. Третий так усердно повторяет отправку, что появляются дубликаты. Данные вроде бы есть, но они перестают рассказывать понятную историю.
Проблемы особенно заметны во время реальных инцидентов. Alerts приходят с опозданием, потому что очередь переполнилась. Traces рвутся, потому что один сервис сбрасывает spans под нагрузкой. Logs выглядят неполными, потому что один узел на пять минут потерял сеть. Когда вы разбираете сбой в оплате или медленный вызов API, такие пробелы стоят времени.
Для observability в одном регионе цель проста: сделать путь передачи коротким, оставить как можно меньше точек отказа и сохранить настройку достаточно легкой, чтобы с ней справилась небольшая команда. Вам не нужно проектировать глобальную маршрутизацию или отказоустойчивость между континентами. Вы выбираете самую простую топологию OpenTelemetry Collector, которая все еще дает полные, своевременные данные.
Три компромисса важнее всего: сложность настройки, риск отказа и ежедневное обслуживание. Один общий коллектор быстро запускается, но может стать узким местом. Agents на каждом узле требуют больше работы, но часто лучше справляются с всплесками и краткими сетевыми проблемами. Чем больше коллекторов, тем больше конфигурации, обновлений и мест, которые нужно проверять, когда данные пропадают.
Поэтому схема важна уже на раннем этапе. Слабая топология не просто ухудшает observability. Она еще и усложняет работу команды, потому что время уходит на починку пути телеметрии вместо улучшения продукта.
Если ваш продукт живет в одном регионе, обычно можно обойтись гораздо более простой схемой, чем у крупных распределенных компаний. Сложность здесь не в том, чтобы добавить больше компонентов. Сложность в том, чтобы выбрать минимальное их количество, которое все еще сохраняет данные полными, быстрыми и заслуживающими доверия.
Два варианта простыми словами
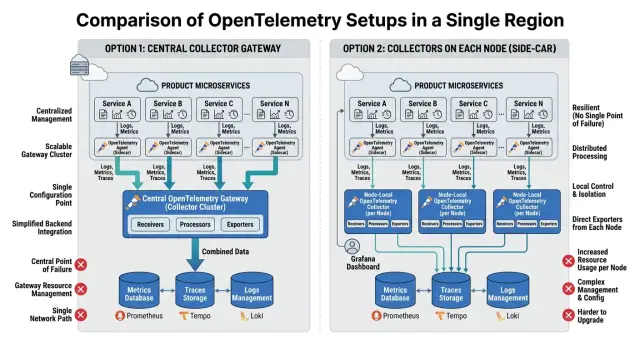
Большинство схем OpenTelemetry в одном регионе сводятся к одному выбору: отправлять все в центральный коллектор или поставить небольшой коллектор рядом с каждой рабочей нагрузкой.
Один gateway collector — более простой вариант. Приложения, контейнеры или сервисы отправляют traces, metrics и logs в один коллектор по центру. Этот коллектор приводит данные в порядок, batch'ит их и пересылает в backend.
Путь выглядит так: app -> gateway collector -> backend.
Эту схему легко обслуживать, потому что настройки меняются в одном месте. Кроме того, она компактна, что особенно удобно, когда команда только начинает.
Per-node agents работают иначе. Вместо одного центрального коллектора на каждом сервере, виртуальной машине или Kubernetes-узле запускается свой локальный коллектор. Приложение сначала общается с коллектором на той же машине, а не с чем-то через сеть.
Путь выглядит так: app -> local collector -> backend.
Поскольку первый шаг локальный, он обычно лучше переживает перезапуски, краткие всплески и небольшие сетевые сбои. Кроме того, он может добавить сведения о хосте перед отправкой данных дальше.
Смешанная схема
Многие команды в итоге останавливаются посередине. Они запускают local agents на каждом узле и передают данные в один gateway collector на финальном этапе. Локальные коллекторы находятся рядом с приложениями, а gateway отвечает за общие правила и export.
Теперь путь такой: app -> local collector -> gateway collector -> backend.
Да, это добавляет еще один hop. Но часто такая схема упрощает жизнь, потому что каждый узел может буферизовать или убирать шумные данные еще до того, как они попадут в центральную точку.
Компромисс здесь простой. Один gateway означает меньше компонентов и меньше конфигурации. Per-node agents означают больше софта, но часто уменьшают потери телеметрии и не дают локальным проблемам превращаться в шум на уровне всей системы.
Если у вас небольшой продукт с несколькими сервисами, один gateway обычно выглядит чище. Если узлов много или сервисы генерируют большой объем телеметрии, локальные agents часто быстро снимают головную боль.
Когда один gateway работает хорошо
Один gateway collector часто оказывается правильным первым выбором для небольшого продукта в одном регионе. Если у вас немного сервисов, небольшая команда и вы не ожидаете резких скачков трафика, один центральный коллектор делает схему понятной.
Этот вариант лучше всего работает, когда трафик в течение дня остается довольно ровным. Коллектор получает предсказуемый поток logs, traces и metrics, поэтому очереди остаются короткими, а настройка — простой. Вам не нужно много думать о rollout агентов, конфигурации на уровне хоста или разном поведении на разных машинах.
Он также полезен, когда вам нужен один config-файл и одно место для отладки. Если spans перестают приходить, вы проверяете один коллектор. Если sampling настроен неправильно, вы меняете одну конфигурацию. Это звучит просто, но это важно. Команда из двух-трех человек может потратить часы, гоняясь за проблемами телеметрии по множеству узлов, когда у самого продукта всего четыре сервиса.
Один gateway хорошо подходит, когда большинство из этого правда:
- У вас небольшое число приложений или контейнеров.
- Нагрузка скорее ровная, чем всплесковая.
- Вы развернуты на небольшом числе хостов или в одном кластере.
- Вам нужен самый быстрый путь к рабочей observability.
- Вы можете без особых трудностей наблюдать еще один центральный компонент.
Главный плюс — скорость. Вы можете включить tracing и metrics за день, а потом улучшать схему позже. Для раннего SaaS-продукта это обычно лучше, чем заранее проектировать более сложную топологию, пока вы еще не знаете, где на самом деле болит.
Простой пример: стартап запускает API, worker, веб-приложение и базу Postgres в одном регионе. Команде нужны базовый tracing, error logs и service metrics. Один gateway collector дает достаточно видимости, чтобы замечать медленные запросы к базе и retry storm без установки софта на каждый узел.
Но за емкостью все равно нужно следить. Если коллектор начинает терять данные, слишком много потребляет CPU или становится самой проблемной частью observability-стека, значит, у простого варианта уже закончился запас прочности.
Когда per-node agents действительно помогают
Per-node agents чаще имеют смысл, когда инфраструктура часто меняет форму. Если кластер добавляет и удаляет узлы в периоды нагрузки, локальный коллектор дает каждой новой рабочей нагрузке такой же близкий target. Приложения продолжают отправлять телеметрию на тот узел, где уже работают, даже когда кластер масштабируется.
Эта схема также полезна, когда сеть ведет себя шумно. Один удаленный gateway может хорошо работать на чистом канале, но краткая потеря пакетов или небольшая перегрузка сети быстро приводит к потерянным spans. Local agent может поставить данные в очередь, повторить попытку и batch'ить их до того, как они покинут машину. Такой небольшой буфер часто сохраняет детали, которые нужны именно в тот момент, когда что-то ломается.
Еще одна сильная причина использовать local agents — контекст хоста. Они могут добавлять labels узла, host metrics и системные сведения до export. Это важно, когда проблема возникает только на одном worker с плохим диском, одним шумным соседом или странной версией kernel. Без контекста на уровне узла traces покажут, что запросы замедлились, но не покажут, где началась проблема.
У центрального коллектора есть и другая особенность: он выглядит нормально, пока трафик не подскакивает. А потом одновременно прилетают deploys, autoscaling и error storm. Одна машина или небольшой пул коллекторов начинает терять данные именно тогда, когда видимость важнее всего. Per-node agents распределяют эту работу. Каждый узел локально batch'ит и сжимает данные, поэтому upstream-коллекторы получают более ровный поток вместо стены из всплесков.
Смешанные runtime-среды тоже подталкивают команды в ту же сторону. Один кластер может одновременно держать Java-сервисы, Node.js API, Python workers и несколько sidecar'ов от другой команды. Они не всегда одинаково отправляют телеметрию и почти никогда не выкатывают изменения одновременно. Local agent дает одно место, где можно нормализовать теги, отфильтровать мусор и не дать особенностям каждой команды превратиться в центральный хаос.
Один из типичных вариантов выглядит так: на каждом узле рядом с рабочими нагрузками запускается один agent, агент добавляет host и node metadata, агент буферизует короткие сетевые сбои, а upstream gateway занимается export и routing.
Представьте вечерний всплеск трафика в продукте в одном регионе. Кластер увеличивается с 20 узлов до 40, число checkout-запросов растет, и один сервис начинает уходить в timeout. Если у вас только один gateway, объем spans в тот же момент подскакивает вместе с error logs. Если у вас per-node agents, каждый узел сначала принимает свой всплеск сам. Вам по-прежнему нужен здоровый gateway-слой, но вы избегаете одного перегруженного узкого места и сохраняете host details, которые сильно ускоряют root cause analysis.
Как выбирать по шагам
Хороший выбор начинается с текущей системы, а не с диаграммы вендора. Для продукта в одном регионе схема коллектора должна соответствовать числу сервисов, числу узлов и объему телеметрии в обычные дни и в плохие дни.
Начните с простых фактов. Посчитайте приложения, фоновые задачи, базы данных и узлы или pods, на которых они работают. Затем прикиньте объем в простых категориях: ровный трафик, пиковый трафик и любые всплесковые задачи вроде импорта, повторной обработки очередей или ночной синхронизации. Если вы не можете назвать главные источники, вы все еще гадаете.
Потом посмотрите на уже существующие проблемы. Проверьте короткие пики трафика, шумные окна деплоя, нестабильную сеть на узлах и сервисы, которые слишком часто перезапускаются. Один gateway часто хорошо работает, когда сервисы общаются по стабильной сети, а объем телеметрии остается предсказуемым. Per-node agents полезнее, когда узлы теряют связь, резко всплескивают или нуждаются в локальной буферизации, чтобы избежать потерь.
Практичный набор правил помогает ориентироваться:
- Если большинство сервисов работает на небольшом числе стабильных узлов, сначала попробуйте один gateway.
- Если каждый узел способен перегрузить сеть во время всплесков, склоняйтесь к per-node agents.
- Если потеря нескольких секунд телеметрии скроет реальный инцидент, выбирайте локальную буферизацию.
- Если одной небольшой команде принадлежит вся инфраструктура, держите схему простой, если нет явной причины усложнять.
- Если разными хостами управляют разные команды, local agents часто упрощают rollout.
Ownership важнее, чем многие ожидают. Кому-то нужно поддерживать конфигурацию коллектора, выкатывать ее, разбирать ошибки в pipeline и следить за тем, чтобы processors оставались согласованными. Один gateway дает одно место для изменений. Per-node agents распределяют работу, если только у вас уже нет хорошей автоматизации для хостов или DaemonSet rollout'ов.
Начните с более простого варианта, если только текущие сбои явно не подсказывают обратное. Для многих продуктов в одном регионе это означает сначала один gateway. Поставьте дату проверки через две или три напряженные недели. Если вы видите потерянные batches, давление на очереди или слишком сильную зависимость от стабильности сети, переходите к per-node agents до следующего скачка роста.
Реалистичный пример
Представьте SaaS-приложение, работающее в одном регионе. В нем есть API-серверы, которые обрабатывают пользовательский трафик, worker-процессы, которые разгребают очереди задач, и одна база данных, где хранится обычный набор аккаунтов, заказов и событий.
Команда начинает с простой схемы. Каждый экземпляр приложения отправляет traces, metrics и logs в один OpenTelemetry Collector gateway за внутренним service. Этот gateway batch'ит данные, добавляет общие атрибуты вроде окружения и имени сервиса и экспортирует все в observability backend.
Сначала это работает. Трафик API ровный, пул workers небольшой, и один gateway легко понимать. Если кому-то нужно изменить правила export, sampling или redaction, это делается в одном месте.
Потом растет сторона worker'ов. Появляется ежедневная задача импорта, включается autoscaling, и число экземпляров workers быстро прыгает вверх. Каждый новый worker начинает отправлять телеметрию одновременно. Gateway получает всплеск spans и logs, глубина очереди растет, а часть данных приходит с опозданием или теряется, когда увеличивается pressure на память.
Признаки знакомы:
- Traces у workers выглядят неполными.
- Host details отсутствуют или отличаются друг от друга.
- Gateway требует гораздо больше CPU, чем когда-либо требовал путь API.
- Короткие всплески создают длинные задержки export.
Команде не нужно выбрасывать gateway. Они добавляют per-node agents. Теперь на каждом узле работает локальный коллектор, который принимает телеметрию от приложений на этой машине, буферизует короткие всплески и добавляет host-level tags вроде имени узла, зоны или типа инстанса.
Это снимает нагрузку с центрального gateway. Workers отправляют данные в локальный agent по короткому пути, поэтому burst traffic поглощается ближе к месту, где он возникает. У gateway по-прежнему важная роль: он применяет общие правила routing, хранит credentials для export в одном месте и отправляет данные в финальный backend.
В итоге получается смешанная схема, а не переход по принципу все или ничего. Per-node agents берут на себя сбор и буферизацию рядом с рабочей нагрузкой. Gateway остается посередине для политики и контроля export. Для продукта в одном регионе с рывками у workers такое разделение часто убирает худший сценарий отказа, не делая всю систему трудной в эксплуатации.
Частые ошибки, которые создают проблемы
Много проблем начинается с одного предположения: «одного коллектора хватит на все». Иногда это правда. Но если каждое приложение, задание и worker отправляет телеметрию в один маленький gateway, эта машина становится узким местом. Всплески traces задерживают logs, потерянные batches скрывают инциденты, а один перезапуск создает слепую зону по всему продукту.
Команды также создают проблемы, когда копируют per-node agents вручную. Десять узлов кажутся управляемыми. Тридцать — уже нет. У одного agent другой exporter, у другого старое значение processor, а третий все еще смотрит на тестовый backend. Вскоре вы отлаживаете config drift вместо того, чтобы наблюдать за системой.
Сам коллектор тоже нуждается в ограничителях. Retries, очереди, настройки batch и лимиты памяти — это не необязательная косметика. Они определяют, что произойдет, когда трафик подскочит в 9:00 утра или когда backend замедлится на пять минут. Если их пропустить, коллектор может съесть слишком много памяти, упасть или потерять те данные, которые были важнее всего.
Еще одна частая ошибка — ставить agents до того, как вы поняли, где именно находится узкое место. Команды иногда размещают agents на каждом узле просто потому, что traces приходили поздно, а потом выясняется, что реальная проблема была в слишком маленьком gateway с плохим batching и без очереди. Больше компонентов не исправили медленный участок. Они только усложнили понимание схемы.
Отделяйте настройки приложения от настроек pipeline коллектора. Приложение должно знать, что именно отправлять и куда отправлять. Коллектор должен решать, как batch'ить, обогащать, повторять отправку и экспортировать. Когда команды смешивают эти задачи, они меняют sampling в приложении, чтобы решить проблему с памятью коллектора, или жестко прописывают сведения о backend в конфигурации сервисов. Из-за этого обычные изменения превращаются в рискованные деплои.
Обычно рано появляются несколько предупреждающих признаков:
- CPU на узлах приложений остается низким, а один коллектор весь день работает на пределе.
- Разные узлы показывают разный объем телеметрии для одного и того же сервиса.
- Перезапуски на время устраняют потерю данных, а потом проблема возвращается.
- Для небольших изменений конфигурации нужно вручную трогать каждый сервер.
Схемы с одним gateway ломаются, когда команда относится к ним как к бесконечным по мощности. Per-node agents ломаются, когда та же неразбериха просто размазывается по большему числу машин. Самая чистая схема обычно та, которую можно оценить по размеру, обновлять и отлаживать без догадок.
Быстрые проверки перед тем, как принять решение
Большинство плохих схем коллектора не разваливаются в первый день. Они ломаются во время перезапуска, всплеска масштабирования или неаккуратного инцидента, когда никто не может понять, сломалось ли приложение или путь телеметрии.
Начните с перезапусков. Если один общий gateway падает на 30 секунд, подумайте, сколько данных вы можете потерять без вреда для отладки или alerts. Многие продукты в одном регионе могут пережить короткий пробел в traces, особенно если logs и metrics все еще доходят до хранилища. Если даже короткие провалы вам вредят, local agents дают каждому узлу небольшой буфер и не дают одному перезапуску затронуть все сервисы сразу.
Следующий фильтр — metadata. Некоторым командам нужно, чтобы перед выходом с машины к данным были добавлены имена узлов, labels контейнеров, теги зоны или сведения о процессах хоста. Центральный gateway может добавить часть resource attributes, но он не видит всего того, что видит узел. Если локальный контекст важен при разборе инцидентов, per-node agents обычно экономят время позже.
Шаблон трафика тоже имеет значение. Если ваш продукт может масштабироваться в 5 раз или больше во время запуска, batch-job или внезапного всплеска клиентов, проверьте, куда уходит эта телеметрия. Один gateway может работать, если вы действительно заложили запас и протестировали burst traffic. Если объем растет быстро и неравномерно, agents сглаживают всплеск, потому что каждый узел batch'ит локально, а не отправляет все в одну точку.
Привычки команды тоже часто решают все. Когда телеметрия пропадает, может ли ваша команда за несколько минут понять, что коллектор перегружен, застрял в перезапуске или блокируется на export? Один gateway проще наблюдать, потому что есть одно место для проверки. Agents добавляют больше частей, но делают отказы легче для изоляции, потому что проблема часто остается на одном узле.
Стиль конфигурации — последняя проверка. Если команде нужен один общий config и почти нет вариаций, схема с gateway-first проще. Если вам нужна общая база плюс небольшие изменения для отдельных узлов или сервисов ради metadata, фильтрации или routing, лучше подходят layered configs.
Простое правило работает хорошо. Выбирайте один gateway, если короткие потери допустимы, требования к metadata невелики, а трафик достаточно стабилен. Выбирайте per-node agents, если важен локальный контекст, масштабирование идет резкими скачками или один перезапуск коллектора слишком сильно ударит по системе.
Что делать дальше
Для большинства продуктов в одном регионе простой чертеж лучше, чем еще одна неделя споров. Возьмите один лист и нарисуйте текущий путь телеметрии: приложение, локальные буферы, если они есть, коллектор, backend и места, где данные могут копиться, ломаться или теряться.
Обычно такая картинка снимает половину спора. Сразу видно, достаточно ли трафик прост для одного gateway или какие-то узлы уже дают всплески, которым нужны local agents.
Начните с более компактной схемы и проверьте ее под нагрузкой. Если вам кажется, что один gateway выдержит ваш трафик, прогоните нагрузочное тестирование по тем всплескам, которые у вас реально бывают во время деплоев, batch-задач или error storm. Простую схему легче эксплуатировать, легче отлаживать и часто вполне достаточно.
Добавляйте per-node agents только там, где это подтверждают цифры. Если один сервис теряет spans во время коротких всплесков, если шумный узел перегружает gateway или если backpressure одновременно мешает logs и metrics, сначала поставьте agent именно там, а не меняйте весь парк.
Короткого рабочего плана уже достаточно:
- Нанесите на одну страницу текущий путь для traces, metrics и logs.
- Протестируйте схему с одним gateway на реалистичном пиковом трафике.
- Проверьте потерю данных, рост очередей, всплески retries и нагрузку на CPU или память.
- Добавляйте agents только на те узлы или workloads, где есть проблемы со всплесками или нестабильной доставкой.
- Запишите, кто отвечает за pipelines, sampling, rate limits, лимиты памяти и alerts.
Ownership имеет значение. Если за лимиты коллектора никто не отвечает, одна команда увеличивает batch size, другая меняет sampling, и проблема становится заметной только тогда, когда дашборды пустеют.
Первые alerts держите скучными и прямыми. Настройте оповещения на dropped telemetry, exporter failures, длину очереди, давление на память и перезапуски коллектора. Эти сигналы рано ловят большинство плохих rollout'ов.
Если выбор все еще кажется туманным, попросите внешнюю проверку до того, как вы распространите более сложную схему на production. Oleg Sotnikov at oleg.is работает со стартапами и небольшими командами над инфраструктурой и решениями Fractional CTO, включая практический дизайн observability, когда неочевидно, какая схема будет самой простой.
Часто задаваемые вопросы
Когда лучше начинать с одного gateway collector?
Начинайте с одного gateway, если у вас немного сервисов, стабильные хосты и трафик меняется не слишком резко. Так у вас будет одно место для изменения конфигурации, одно место для проверки, если данные пропали, и более быстрый путь к рабочим tracing, logs и metrics.
Этот вариант перестает быть удобным, когда коллектор работает на пределе, очереди растут во время всплесков или короткие сетевые сбои создают уже неприемлемые пробелы.
Когда per-node agents подходят лучше?
Используйте per-node agents, если узлы часто добавляются и удаляются, трафик приходит всплесками или локальные сетевые сбои приводят к потерям телеметрии. Коллектор на той же машине может буферизовать, batch'ить и повторять отправку, прежде чем данные покинут узел.
Они также помогают, когда рядом с рабочей нагрузкой нужно добавить сведения о хосте: имя узла, labels или системные метрики.
Не слишком ли много смешанная схема с agents и gateway для продукта в одном регионе?
Нет. Mixed setup хорошо подходит многим продуктам в одном регионе, когда объем телеметрии вырастает. Local agents обрабатывают буферизацию и контекст хоста рядом с приложением, а gateway оставляет у себя общие правила маршрутизации, redaction и учетные данные для backend.
Это добавляет еще один hop, так что делайте так только по причине. Если один gateway спокойно справляется с нагрузкой, оставляйте схему проще.
Что обычно ломается первым в схеме с одним gateway?
Обычно первым слабым местом становится сам gateway. Растет CPU, очереди забиваются, export задерживается, а traces и logs начинают приходить поздно именно тогда, когда происходит инцидент.
Следите за повторяющимися потерями, давлением на память и перезапусками, которые создают слепые зоны сразу для всех сервисов.
Действительно ли local agents помогают при autoscaling и bursty jobs?
Да, это один из лучших сценариев для них. Каждый узел сначала принимает собственный всплеск, поэтому upstream видит более ровный поток вместо одной резкой стены из spans и logs.
Это не отменяет необходимости хорошо настроить gateway и backend. Это просто переносит часть амортизации ближе к месту, где всплеск начинается.
Насколько host metadata должна влиять на это решение?
Это важно, если в ваших инцидентах всплывают проблемы на уровне узлов. Если вам нужно знать, на каком worker'е были плохие disk I/O, странное поведение kernel или шумные соседи, local agents экономят время, потому что добавляют этот контекст до отправки.
Если вам достаточно данных на уровне сервиса, central gateway часто закрывает базовые задачи без лишних движущихся частей.
Должно ли приложение само отвечать за retries, batching и правила export?
Оставьте приложению только emission телеметрии и передачу данных в коллектор. Пусть коллектор занимается batching, retries, enrichment, filtering и export.
Когда команды переносят логику коллектора в конфигурацию приложения, обычные изменения превращаются в деплои приложения, а отладка быстро становится запутанной.
Как перейти с одного gateway на per-node agents без большой переработки?
Переходите по шагам. Оставьте gateway, добавьте agents только на те узлы или рабочие нагрузки, где есть проблемы со всплесками, и направьте эти приложения к local collector вместо центрального.
Так вы сможете сравнить результат на реальном трафике и не менять весь парк сразу.
На что стоит поставить alert после внедрения коллектора?
Начните с dropped telemetry, exporter failures, длины очереди, давления на память и перезапусков collector'а. Эти сигналы рано показывают, что проблема в пути телеметрии, а не в самом продукте.
Потом следите за ingest delay и объемом по сервисам, чтобы заметить пропажу данных еще до того, как кто-то увидит пустой дашборд.
Какое самое простое правило выбора между gateway и per-node agents?
Выбирайте один gateway, если короткие потери телеметрии допустимы, требования к metadata невелики, а трафик остается предсказуемым. Выбирайте per-node agents, если важен локальный контекст, масштабирование идет резкими скачками или один перезапуск коллектора ударит слишком сильно.
Если сомневаетесь, начните с более простой схемы и нагрузите ее реальными пиковыми сценариями, а не средним трафиком.


