Типы ошибок Rust для команд: как ясно моделировать сбои
Типы ошибок Rust помогают командам разделять повторяемые, видимые пользователю и внутренние сбои, сохранять контекст и значительно упрощать отладку.
Содержание
Почему команды теряют настоящую ошибку
Команды обычно теряют настоящую причину, когда сводят все сбои в одну корзину вроде AppError::Internal или простого сообщения «что-то пошло не так». На неделю или две это кажется аккуратным. Потом ломается сброс пароля, поддержка не может подсказать пользователю, что делать дальше, а инженер, который разбирает проблему, уже не видит, истёк ли таймаут у почтового сервиса, истёк ли токен или база данных отклонила запись.
Это не только проблема кода. Разным людям нужны разные сигналы от одного и того же сбоя. Поддержке нужно сообщение, с которым можно работать. Продукту нужно видеть закономерности, например, сталкиваются ли пользователи с ошибками валидации или с отключениями внешних сервисов. Инженерам нужна исходная причина с достаточным контекстом, чтобы воспроизвести проблему. Если всё это заменяет одна универсальная ошибка, каждая команда работает медленнее.
Чаще всего вред наносят обёртки. Вспомогательная функция ловит ошибку и возвращает RequestFailed. Ещё один слой ловит её и возвращает Internal. На верхнем уровне теперь видно, что запрос не удался, но не видно, какой именно запрос, почему он провалился и помогла бы ли повторная попытка. Код выглядит чисто, но сам сбой оказался сглажен.
Типы ошибок в Rust помогают, когда они описывают форму проблемы, а не прячут её. Таймаут, неверный ввод пользователя и баг в вашем собственном коде не должны выглядеть одинаково. Они ведут к разным действиям:
- повторить операцию
- показать пользователю понятное сообщение
- поднять тревогу и записать полные детали в лог
Сложнее всего удержать оба взгляда одновременно. Нужен простой enum ошибок, который понимает вся команда, но при этом нужно сохранить и нижележащую причину. Значит, надо добавлять контекст, не теряя исходную ошибку.
Небольшой пример сразу показывает цену ошибки. Если почтовый провайдер возвращает «429 rate limit», а ваше приложение превращает это в «сброс не удался», вы теряете единственную подсказку, которая говорит сделать паузу и попробовать позже. Хорошие типы ошибок в Rust сохраняют эту подсказку видимой. Цель проста: одна ошибка должна объяснять каждому читателю, что произошло, что делать дальше и что именно сломалось под капотом.
Разделите аудитории ошибок
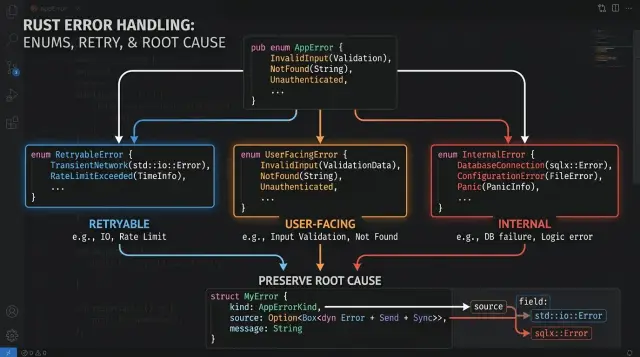
Команды часто застревают на проектировании ошибок, потому что слишком рано группируют сбои по источнику. База данных, HTTP, кэш, парсер — это показывает, где произошла проблема, но не кто должен на неё реагировать. Хорошие типы ошибок в Rust начинаются с аудитории.
Простое правило помогает: каждая ошибка должна подсказывать одному человеку, что делать дальше. Иногда системе нужно попробовать ещё раз. Иногда вызывающему коду нужно изменить ввод. Иногда вашей команде нужно исправить код, конфигурацию или неверное предположение.
Повторяемые ошибки описывают временную проблему. Это может быть таймаут при обращении к другому сервису, короткий обрыв сети или ограничение скорости со стороны внешнего API. Ваше приложение часто может повторить попытку с задержкой или отложить задачу на потом. Ответ должен говорить, что запрос не удался пока, а не навсегда. В логах нужно сохранить операцию, номер попытки и настоящую причину. Обычно за это отвечает команда, которая следит за состоянием сервиса, или инженер, владеющий этой интеграцией.
Ошибки для пользователя — это другое. На них можно отреагировать. Сюда относятся плохой ввод, истёкший токен или отсутствие прав. Для таких ошибок нужны простые сообщения вроде «код сброса истёк» или «неверный формат email». Они не должны раскрывать внутренности, например детали SQL или стек вызовов. В логах можно оставить чуть больше подробностей, но они всё равно должны быть чистыми и безопасными. Обычно за такие ошибки отвечает команда, которая определяет правила API или продукта.
Внутренние ошибки — это то, что пользователям не стоит показывать напрямую. Сюда относятся отсутствующая переменная окружения, нарушенный инвариант или код, который попал в невозможное состояние. Слепые повторные попытки тут редко помогают. Возвращайте общее сообщение о сбое, пишите в лог полный контекст и сохраняйте цепочку причин, чтобы кто-то мог быстро всё исправить. Обычно за это отвечает инженер или команда, которая владеет этим участком кода или настройкой деплоя.
Общий enum становится проще формировать, когда каждый вариант отвечает на четыре вопроса:
- Можно ли это повторить?
- Что должен увидеть вызывающий код?
- Что нужно включить в лог?
- Кто отвечает за исправление?
Если вариант не отвечает на эти четыре вопроса, он, скорее всего, слишком расплывчатый. OperationFailed объясняет меньше, чем кажется.
Сформируйте общий enum ошибок
Начинайте с границы сервиса, а не глубоко внутри каждого помощника. Именно на этой границе ваш хендлер, джоб или команда решает, что остальная система должна знать о сбое. Во многих командах поначалу хватает трёх или четырёх вариантов.
Смысл не в том, чтобы описать каждый низкоуровневый сбой. Смысл в том, чтобы сделать следующий шаг очевидным. Можно ли повторить попытку? Нужно ли пользователю исправить ввод? Или ваш код столкнулся с внутренней проблемой, которую надо залогировать и поднять тревогу?
Небольшой enum заставляет принять это решение заранее:
#[derive(Debug, thiserror::Error)]
pub enum ServiceError {
#[error("temporary failure")]
Retryable {
code: &'static str,
source: anyhow::Error,
},
#[error("invalid request")]
User {
code: &'static str,
details: Vec<FieldIssue>,
},
#[error("internal failure")]
Internal {
code: &'static str,
source: anyhow::Error,
},
}
Каждый вариант должен значить что-то одно. Команды начинают путаться, когда добавляют корзины вроде Other, External или RequestFailed. Названия выглядят гибко, но скрывают настоящее решение. Таймаут у другого сервиса, неверный email и баг в вашем собственном коде не должны попадать в одну и ту же корзину.
Хорошие варианты описывают поведение, а не источник. Retryable подсказывает вызывающему коду, что делать дальше. User показывает API-слою, что можно вернуть понятное сообщение. Internal говорит вашей команде, что нужно смотреть логи и исходную причину.
Сообщения для вызывающего кода держите короткими и стабильными. Если сегодня ваш API возвращает «Пожалуйста, попробуйте ещё раз позже», он не должен через месяц начать говорить «Обнаружен временный сбой зависимости». Стабильные формулировки помогают клиентским приложениям, поддержке и тестам. Подробное объяснение оставьте для логов, трассировок и отладочных представлений.
Именно поэтому коды и детали должны жить отдельно от текста для показа. Код вроде auth.reset_token_expired или billing.provider_timeout легко искать в дашбордах и логике клиента. Структурированные детали, например какое поле не прошло проверку, должны жить в отдельном payload. Текст Display у ошибки Rust может оставаться простым и даже немного скучным.
Скучное здесь — это хорошо. Когда коллега читает enum, он должен понимать значение каждого варианта, не открывая пять файлов. Если нельзя сразу сказать, надо ли повторить ошибку, показать её пользователю или поднять её для команды, значит enum всё ещё делает слишком много.
Сохраняйте причину и добавляйте контекст
Размытая ошибка тормозит всех. Если таймаут базы данных превращается в InternalError, команда теряет самое важное — что именно не сработало. Нужна чистая ошибка уровня приложения, но при этом нельзя выбрасывать нижележащую причину.
Оборачивайте исходную ошибку, а не заменяйте её. В типах ошибок Rust это обычно означает вариант enum, который хранит и ваш собственный контекст, и исходную ошибку. Тогда приложение может сказать пользователю «сброс пароля временно недоступен», а в логах при этом останется настоящая цепочка, например сетевой таймаут или неудачный SQL-запрос.
Небольшой шаблон
#[derive(Debug, thiserror::Error)]
pub enum ResetPasswordError {
#[error("password reset is temporarily unavailable")]
Retryable {
op: &'static str,
account_id: String,
timeout_ms: u64,
#[source]
source: reqwest::Error,
},
#[error("we could not reset that password")]
User {
op: &'static str,
account_id: String,
},
#[error("internal error during {op} for account {account_id}")]
Internal {
op: &'static str,
account_id: String,
#[source]
source: sqlx::Error,
},
}
Этот шаблон разделяет два уровня. Текст Display остаётся коротким и безопасным. Поле source сохраняет настоящую причину для логов, алертов и инструментов отладки. Когда кто-то разбирает инцидент, он видит и смысл для бизнеса, и исходный сбой без догадок.
Контекст важен не меньше, чем источник. Добавляйте поля вроде названия операции, ID входных данных, значения таймаута или request ID. Эти мелкие детали быстро отвечают на базовые вопросы: на каком шаге произошёл сбой, для какой записи и при каком ограничении. Хорошая ошибка часто экономит 20 минут поиска.
Будьте строги к секретам. Не копируйте в сообщения пользователю сырые токены, пароли, API-ключи, полные email-адреса или ответы провайдера. Не тащите их и в поля логов. Оставляйте текст для пользователя простым, а контекст для логов — скучным: название операции, account ID, request ID, таймаут и цепочка ошибок. Так команда получит достаточно данных, чтобы исправить проблему и не создать новую.
Постройте один поток запроса шаг за шагом
Возьмите один реальный запрос и нарисуйте карту его сбоев по порядку. Хорошие типы ошибок в Rust обычно рождаются из того пути, который уже проходит запрос, а не из большого enum, который вы придумываете заранее.
У простого потока обычно есть четыре точки отказа:
- разбор или проверка ввода
- сетевой вызов к другому сервису
- правило предметной области внутри приложения
- чтение или запись в хранилище
Этот порядок полезен, потому что каждый шаг отвечает на свой вопрос. Пользователь отправил плохие данные? Другой сервис временно сбойнул? Бизнес-правило запретило действие? База данных сломалась?
Когда карта есть, преобразуйте ошибки на границе. Оставляйте reqwest::Error внутри HTTP-клиента. Оставляйте sqlx::Error внутри слоя хранилища. А обработчик запроса должен видеть смысл на уровне приложения вместе с исходной причиной.
#[derive(Debug, thiserror::Error)]
pub enum RequestError {
#[error("invalid input: {0}")]
InvalidInput(String),
#[error("temporary upstream failure")]
RetryableUpstream(#[source] reqwest::Error),
#[error("email already exists")]
EmailTaken,
#[error("storage failure")]
Storage(#[source] sqlx::Error),
}
В потоке запроса сначала вызывайте validate и сразу падайте на плохом вводе. Потом делайте сетевой запрос. Если он превышает таймаут или возвращает временный сбой, сопоставьте его с RetryableUpstream. Если приложение упирается в правило вроде EmailTaken, остановитесь и верните понятное сообщение пользователю. Если запись в базу не удалась, сохраните sqlx::Error как источник, чтобы в логах всё ещё была видна настоящая проблема.
Правила повторных попыток должны быть скучными и жёсткими. Таймауты, сбросы соединения и временные отказы внешнего сервиса часто заслуживают повторной попытки. Плохой ввод, отсутствие прав и сломанные бизнес-правила — нет. Команда теряет время, когда каждая ошибка выглядит повторяемой только потому, что она пришла из библиотеки.
Прежде чем добавлять ещё варианты, протестируйте по одному падающему пути для каждого из них. Достаточно короткого набора:
- неверный email возвращает
InvalidInput - таймаут внешнего сервиса становится
RetryableUpstream - дубликат email становится
EmailTaken - сбой базы данных становится
Storage
Если один тест не может подсказать, нужно ли повторять запрос, сначала поправьте enum, а уже потом расширяйте код.
Пример с восстановлением пароля
Сброс пароля — хороший тест для типов ошибок в Rust, потому что одно простое действие может провалиться по очень разным причинам. Пользователь может ввести неправильный email. Почтовый провайдер может зависнуть по таймауту. Ваше приложение может не найти шаблон письма на диске.
Эти сбои не должны выглядеть одинаково.
#[derive(Debug, thiserror::Error)]
pub enum ResetPasswordError {
#[error("Enter a valid email address")]
InvalidEmail,
#[error("Email service timed out")]
MailTimeout {
#[source]
source: reqwest::Error,
},
#[error("Password reset is unavailable right now")]
MissingTemplate {
#[source]
source: std::io::Error,
},
}
InvalidEmail — это ошибка для пользователя. Она даёт понятный способ исправить проблему: человек может исправить адрес и попробовать ещё раз. Не нужен расплывчатый текст вроде «Что-то пошло не так». Он только добавляет работы поддержке.
MailTimeout — другое дело. Пользователь, возможно, вообще ничего не сделал неправильно. Приложение должно считать это временным сбоем, вернуть временную ошибку и сохранить таймаут от почтового клиента как источник. Когда коллега откроет логи, он должен увидеть настоящую ошибку провайдера, а не просто плоское сообщение «send failed».
MissingTemplate — это внутренняя ошибка. Пользователь её не исправит, поэтому публичное сообщение должно оставаться простым и спокойным. В логах всё равно нужен файловый сбой как источник, потому что «шаблон отсутствует» подсказывает команде, где искать, а std::io::Error — что именно сломалось.
Поток запроса может сопоставить их так:
InvalidEmail-> показать ошибку в форме и попросить ввести правильный адресMailTimeout-> вернуть временную ошибку и разрешить повторить попыткуMissingTemplate-> вернуть общую ошибку сервера и поднять тревогу для команды
Такое разделение помогает всем. Поддержка понимает, нужно ли пользователю менять ввод. Продукт видит, важны ли повторные попытки. Инженеры могут проследить исходный таймаут или сбой файла без догадок.
Вот почему типы ошибок в Rust хорошо подходят для команд. Один endpoint может говорить ясно сразу трём аудиториям: пользователю, приложению и людям, которые читают логи в два часа ночи.
Ошибки, которые размывают сбой
Команды попадают в неприятности, когда все сбои начинают выглядеть одинаково. Код по-прежнему собирается, логи по-прежнему наполняются, и пользователи по-прежнему видят ошибку. Но никто уже не понимает, что можно повторить, что показать пользователю и где нужен инженер немедленно.
Одна из частых ошибок — вариант на все случаи жизни. Названия вроде Other, Unknown или Failed кажутся безопасными в момент написания, а через месяц становятся бесполезными. Если таймаут базы данных, неверный email и отсутствие записи попадают в одну корзину, вашей команде остаётся только читать логи и гадать.
Некоторые названия сами по себе уже сигнал тревоги:
OtherUnknownFailedMessage(String)
Обычно такие варианты означают, что тип перестал нести смысл.
Другая ошибка — отправлять пользователю сырой текст библиотеки. Сообщение от SQL-драйвера или HTTP-клиента может содержать названия таблиц, внутренние хосты или детали низкоуровневого парсинга. Это полезно при локальной разработке. В продакшене это плохое сообщение для пользователя. Людям нужен простой язык вроде «Срок действия этой ссылки сброса истёк» или «Пожалуйста, введите корректный email». Инженерам по-прежнему нужна исходная причина, но в логах и цепочке ошибок, а не в интерфейсе.
Повторные попытки причиняют вред, когда тип ошибки не разделяет временный сбой и плохой ввод. Если пользователь ввёл неверный промокод, три повторные попытки это не исправят. Вы только добавите задержку, лишнюю нагрузку и шумные алерты. Оставляйте повторные попытки для случаев, где следующий шанс может сработать, например при таймаутах, лимитах или кратковременном обрыве сети.
Последняя ошибка обычно всплывает на границах. Один слой получает настоящую ошибку, потом превращает её в строку или без сохранения источника сводит всё к InternalError. Одна такая строка может стереть след, который нужен вам во время инцидента. Когда добавляете контекст, сохраняйте и причину. «Не удалось отправить письмо для сброса пароля» — это полезно. «Не удалось отправить письмо для сброса пароля» плюс таймаут почтового провайдера — это уже то, что помогает быстро всё исправить.
Хорошие типы ошибок в Rust делают одну простую вещь: они держат смысл рядом со сбоем, а не превращают всё в шум.
Быстрая проверка перед мерджем
Хорошие типы ошибок в Rust экономят время только тогда, когда люди могут быстро на них реагировать. Читайте diff так, как будто вы дежурите в два часа ночи, а не как автор изменений.
Перед одобрением pull request используйте четыре проверки:
- Для каждого варианта, видимого пользователю, может ли поддержка подсказать человеку, что делать дальше? «Попробуйте позже» — слабый вариант. «Запросите новую ссылку для сброса» или «Проверьте, не истёк ли срок действия ссылки» дают понятный следующий шаг.
- Может ли сервис решить, нужно ли повторять попытку, без догадок? Таймаут, ограничение по скорости и неправильный email не должны выглядеть одинаково в коде. Если вызывающему коду приходится смотреть на строку сообщения, тип делает слишком мало.
- Может ли инженер проследить один логовый путь от верхнеуровневой ошибки до исходной причины? Дополнительный контекст должен говорить, где случился сбой, но обёрнутая исходная ошибка всё равно должна сохранять детали базы данных, сети или парсинга.
- Протестировали ли вы хотя бы один реальный случай для каждого варианта? Команды часто определяют шесть вариантов и в обычной работе видят только два. Неиспользуемые варианты ломаются первыми, потому что их никто не проверяет.
Во время ревью помогает простое правило: каждый вариант должен отвечать на один понятный вопрос. Что пользователь должен сделать сейчас? Нужно ли коду повторить попытку? На что инженеру смотреть первым делом? Если вариант не отвечает ни на один из них, возможно, он не заслуживает отдельной ветки в enum.
Названия важнее, чем многие команды думают. InvalidToken, EmailProviderTimeout и AuditWriteFailed рассказывают три разные истории. OperationFailed почти ничего не говорит. Размытые названия заставляют людей читать логи, искать вызовы и гадать о смысле под давлением.
Тест может быть маленьким. Прогоните один реальный поток запроса и вызовите одну ошибку пользователя, один временный сбой и один внутренний отказ. Потом проверьте ветку match, сообщение пользователю и сохранённый источник. Если настоящая причина где-то по пути исчезает, исправьте это до релиза.
Что делать команде дальше
Для большинства команд спор о типах ошибок в Rust заканчивается, когда начинается боль on-call. Исправление редко требует большой переделки. Короткое командное правило и одна точечная чистка обычно дают больше эффекта, чем ещё одна долгая дискуссия о дизайне.
Запишите правила, которых вы ожидаете от всех. Сделайте их достаточно короткими, чтобы они помещались в шаблон pull request или в командный документ.
- Называйте варианты по тому, что произошло, а не по тому, откуда это пришло.
EmailInvalidпонятнее, чемValidationFailed. - Пишите текст для вызывающего кода простым языком. Пользователю нужен следующий шаг, а не сырые внутренности.
- Держите поля логов одинаковыми во всех сервисах. Несколько стабильных полей лучше, чем свой формат в каждом crate.
- Каждый раз сохраняйте исходную ошибку, когда добавляете контекст. Если корневая причина исчезает, отладка быстро замедляется.
Затем выберите один участок кода, где сбои происходят часто, и приведите в порядок его в первую очередь. Хорошие кандидаты — сброс пароля, логин, обработка вебхуков и повторные попытки платежей, потому что именно там обычно накапливаются размытые корзины ошибок. Замените catch-all названия вроде Internal, Unknown или RequestFailed на варианты, которые показывают, может ли вызывающий код повторить попытку, исправить ввод или остановиться и сообщить об ошибке.
Добавьте простой привычный этап ревью для pull request. Он не обязан быть сложным, но его должно быть трудно пропустить.
- Может ли другой инженер понять, повторяемая ли эта ошибка, не читая всю функцию?
- Остаётся ли сообщение для пользователя безопасным и понятным?
- Показывают ли логи исходную ошибку?
- Значат ли названия вариантов одно и то же во всех сервисах?
Такое ревью ловит мелкие ошибки до того, как они расползутся по кодовой базе. Одна потерянная исходная ошибка в общем клиенте может скрыть настоящую проблему на недели.
Если вашей команде нужен внешний взгляд, Oleg Sotnikov может посмотреть на границы Rust-сервисов и помочь выстроить устойчивую модель ошибок в роли fractional CTO. Особенно это полезно, когда сервисов уже несколько, люди используют разные enum ошибок, а никто больше не доверяет тому, что означает Internal.
Хорошая цель проста: когда запрос падает, поддержка может это объяснить, инженеры могут проследить причину, а код делает выбор о повторной попытке очевидным.


