Типизированные SDK для партнерских API со стабильным внутренним контрактом
Типизированные SDK для партнерских API помогают скрыть причуды вендоров внутри продукта. Узнайте, как задать тонкий внутренний контракт и безопасно менять провайдеров.
Содержание
Почему данные в формате вендора создают проблемы
Типизированные SDK помогают, но не решают всю проблему. Большинство из них дают типы, которые почти поле в поле совпадают с ответом партнёра. Ваш код становится безопаснее во время компиляции, но всё равно начинает думать терминами вендора, а не терминами вашего продукта.
Первая проблема проста. Разные партнёры часто присылают один и тот же факт в разных формах. Один возвращает status: "paid". Другой — payment_state: "complete". Третий прячет ответ внутри вложенного объекта. Вашему продукту нужен только один ответ: оплатил ли клиент? Без чёткой границы каждый экран, каждая задача и каждый обработчик вебхуков начинают переводить этот ответ по-своему.
Дальше всё быстро запутывается. Небольшое изменение в API одного партнёра может разойтись по всему приложению. Переименованное поле, пустая строка вместо null или значение, перенесённое в новый массив, могут сломать поиск, отчёты или фоновую синхронизацию. В документации это выглядит как мелочь, но в коде исправление редко бывает мелким.
Глубже проблема в связности. Продуктовый код начинает зависеть от названий полей вендора, значений enum и странных пограничных случаев. Разработчики перестают спрашивать: «Что нужно нашему продукту?» и начинают спрашивать: «Как partner X назвал это поле?» Когда такая привычка выходит за пределы слоя интеграции, ядро приложения становится труднее менять.
Потом замена провайдера становится дорогой. Вы меняете не одну интеграцию на другую. Вы выискиваете допущения о вендоре в checkout, админке, тестах, аналитике и support-скриптах. То, что должно было занять несколько дней, легко растягивается на недели.
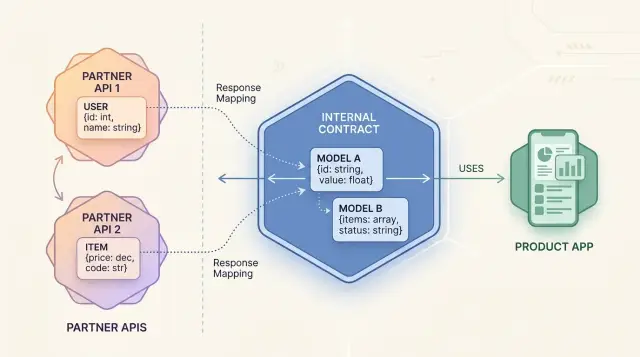
Тонкий внутренний контракт предотвращает большую часть этих проблем. Он даёт остальному продукту одну стабильную форму, на которую можно опираться. Без него каждое решение вендора просачивается внутрь, и каждая новая интеграция делает кодовую базу чуть более хрупкой.
Что делает тонкий внутренний контракт
Тонкий внутренний контракт даёт вашему продукту более маленькую и чистую форму, чем API партнёра. Вы определяете только те поля, которые приложение реально использует, и игнорируете всё остальное. Звучит просто, но это сильно экономит время на доработках.
Большинство API партнёров возвращают намного больше данных, чем нужно вашему продукту. Там есть vendor ID, вложенные метаданные, старые поля, странные коды статусов и названия, понятные только внутри команды этого вендора. Если весь этот сырой payload начнёт гулять по приложению, код функций начнёт зависеть от решений, которые ваша команда никогда не принимала.
Контракт останавливает это расползание. Checkout, billing и отчётность читают ваши собственные типы, а не ответ партнёра. Обёртка один раз преобразует payload на границе и даёт остальной части продукта что-то стабильное.
Здесь команды часто обманывают сами себя. Они генерируют полный клиент, выставляют наружу все поля и называют это «typed». Да, это типизировано, но форма всё равно остаётся вендорской. Одно переименование или одна смена вложенности всё ещё могут отозваться по всему приложению.
Называйте контракт по терминам вашей предметной области, а не по терминам вендора. Если продукту нужна стоимость доставки, назовите это ShippingQuote, а не CarrierRateReply. Если вам нужен статус счёта, используйте InvoiceStatus, а не внутренний enum партнёра. Понятные названия делают код легче для чтения, а изменения провайдера — менее болезненными.
Держите границу тонкой
Обёртка — это граница, а не зеркало. Она должна отвечать на вопросы продукта, а не сохранять каждую деталь из документации партнёра.
Провайдер доставки может возвращать 70 полей, но вашему UI могут быть важны только название услуги, срок доставки, финальная цена и наличие трекинга. Такой более маленький контракт даёт вам свободу сменить провайдера, объединить несколько провайдеров или исправить плохой ответ без затрагивания бизнес-логики.
Если вам нужен сырой payload для логов или отладки, держите его на границе. Не передавайте его в правила ценообразования, сценарии оформления заказа или код, который видит клиент.
Именно так небольшие команды сохраняют скорость. Та же идея есть в работе Oleg Sotnikov на oleg.is: защищать центр продукта, держать границы понятными и вносить изменения в одном месте, а не в десяти.
Начинайте с потребностей продукта, а не с документации API
Документация API легко затягивает в копирование мира партнёра в свой код. На первый взгляд это кажется быстрым решением. Позже это превращается в тормоз, когда вендор добавляет поля, переименовывает enum или возвращает пять статусов, которые вашему продукту никогда не были нужны.
Начните с простой истории продукта. Для shipping-потока это обычно небольшой набор действий: получить тариф, купить этикетку, отменить этикетку, отслеживать доставку и показать понятное сообщение об ошибке. Этот список гораздо короче полной поверхности API партнёра — и именно так и должно быть.
Ваш контракт должен соответствовать тому, что делает продукт, а не всему, что вообще способен вернуть вендор.
Потом разделите поля на две группы: нужны сейчас и, возможно, потом. Если checkout нужны адрес получателя, размер посылки, цена и номер для отслеживания, оставьте их. Если провайдер ещё возвращает коды депо, налоговые зоны, подсказки маршрутизации и десять временных меток, которые ни один экран не использует, не тащите их внутрь. Лишние поля не остаются безвредными. Они расползаются в тесты, столбцы базы данных и свойства UI.
То же самое делайте с ошибками. UI не нужен дамп сырых ошибок партнёра. Ему нужны состояния, с которыми можно что-то сделать. Обычно хорошо работает короткий набор: неверные данные, нет доступного варианта, временная проблема у провайдера и операция не удалась после повторной попытки. Полный ответ вендора всё равно можно логировать для поддержки и отладки, но приложение должно говорить на языке продукта.
Вот где типизированные SDK действительно помогают. Их задача — не только обернуть HTTP-вызовы типами. Они должны помогать провести линию между нестабильными внешними данными и стабильными доменными моделями внутри приложения.
Небольшой пример хорошо показывает разницу. Если один провайдер возвращает rate_id, а другой — service_code, вашему checkout, скорее всего, не нужен ни один из них. Ему нужно что-то вроде optionId, плюс цена, валюта и срок доставки. Такой более маленький формат проще тестировать, проще менять и сложнее сломать из-за изменения у вендора.
Если поле сегодня не поддерживает реальную функцию, не добавляйте его. Вернётесь к нему позже, когда продукту действительно понадобится это значение.
Постройте обёртку шаг за шагом
Спрячьте каждый запрос к партнёру за одним адаптером. Этот адаптер должен быть единственным местом, которое знает endpoint вендора, правила авторизации, странные названия полей и поведение повторных попыток. Остальная часть приложения должна работать с вашим внутренним контрактом, а не с сырым ответом.
Хорошая обёртка идёт по простому сценарию. Отправьте запрос через один адаптер для этой операции. Сразу же распарсьте сырой ответ. Проверьте только те поля, которые вам действительно нужны. Сопоставьте payload вендора со стабильными доменными моделями. Верните один формат результата остальной части приложения и залогируйте всё неожиданное.
Такой ранний парсинг важнее, чем кажется. Сырой JSON выглядит безобидно, но он быстро расползается. Как только несколько частей кодовой базы начинают читать поля вендора напрямую, ваш слой абстракции уже сломан.
Держите внутренний результат маленьким. Если продукту нужны только status, price, currency и estimatedDelivery, возвращайте только эти поля. Не пропускайте через себя ещё двадцать свойств просто потому, что они существуют. Лишние данные создают скрытые зависимости.
Shipping-пример хорошо это показывает. Provider A возвращает eta_days, а Provider B — delivery_window с началом и концом даты. Ваша обёртка может привести оба варианта к одному внутреннему полю, например estimatedDelivery. Странице checkout всё равно, как именно каждый партнёр это описывает. Ей нужен только один стабильный ответ.
Логируйте неожиданности, но делайте это осознанно. Если партнёр вдруг начинает присылать новый статус, пропущенное поле или другое значение enum, сохраните это событие вместе с raw payload и названием партнёра. Так вы сможете позже увидеть реальные изменения, не ломая живые сценарии.
Подход простой, и именно поэтому он работает. Один адаптер владеет всей грязной частью. Остальная часть приложения получает чистый результат и остаётся проще для изменений.
Приводите хаотичные ответы к стабильным типам
Стабильный тип не копирует ответ партнёра. Он хранит только те поля, которые использует ваш продукт, и хранит их в одном формате. Если один вендор присылает вес в фунтах, а другой — в килограммах, преобразуйте оба значения на границе, до того как данные попадут в остальную часть приложения.
Та же логика работает с деньгами, датами и идентификаторами. Выберите один формат денег, один формат времени и один стиль именования для внутренних моделей. Потом заставьте каждый адаптер преобразовывать данные именно в эту форму. Тогда ваш продуктовый код остаётся скучным — а это и есть цель.
Состояния требуют такого же подхода. API партнёров часто приходят с длинными списками статусов, разным регистром и неочевидными пограничными состояниями. Вашему приложению обычно нужно намного меньше. В потоке доставки может хватить pending, in_transit, delivered, failed и unknown.
Это значит, что значения вроде IN_PROGRESS, moving, out_for_delivery и carrier_scan_12 можно все свести к in_transit. Вы теряете шум, а не смысл. Если завтра партнёр добавит новый статус, вы обновите один маппер вместо того, чтобы гоняться за условиями по всей кодовой базе.
Отсутствующим данным тоже нужны правила, а не догадки. Решите, какие поля продукт обязан получить, и отклоняйте ответ, если их нет. Решите, какие поля могут быть необязательными, и как UI должен вести себя, когда они пустые. Ещё решите, когда «отсутствует» означает «неизвестно», а когда — «не применимо». Это разные состояния.
Ошибки тоже заслуживают собственной границы. Уберите коды ошибок партнёра, сырые сообщения и странные фрагменты payload из общих моделей. Ваша общая модель ошибки может оставаться маленькой: код, который понимает приложение, безопасное для пользователя сообщение и, возможно, флаг повторной попытки. Сырые детали вендора храните в логах или debug-метаданных, где команда сможет их посмотреть, не протаскивая эту форму в продукт.
Именно здесь обёртка окупается. Она принимает на себя изменения у вендора, а ваши стабильные модели меняются только тогда, когда меняется сам продукт. Если провайдер переименует поле на следующей неделе, это должно быть обновление адаптера, а не рефакторинг по всему приложению.
Пример: один checkout, два shipping-провайдера
Страница checkout редко нуждается во всех полях, которые возвращает shipping-партнёр. Обычно ей хватает нескольких деталей, влияющих на выбор покупателя: цена, ETA и уровень сервиса. Всё остальное может оставаться внутри слоя интеграции.
Представьте, что provider A возвращает цену в центах, дату доставки вроде 2026-05-12 и код сервиса, например EXPRESS. Provider B присылает строку с десятичным числом вроде 12.99, не точную дату, а окно времени вроде 2-4 business days и метку вроде priority.
Если сырые ответы просочатся в код checkout, хаос быстро распространится. Один экран делит центы на 100, другой парсит десятичные строки, а третий пытается сравнить дату с временным окном. Маленькие различия превращаются в баги и неловкие пограничные случаи.
Тонкий внутренний контракт не даёт этому случиться:
type ShippingQuote = {
amount: number
currency: string
etaText: string
serviceLevel: "standard" | "express"
}
Теперь у каждого провайдера есть свой маппер. Provider A превращает 1299 в 12.99, переводит дату доставки в понятную строку ETA и сопоставляет EXPRESS с express. Provider B парсит "12.99" в число, оставляет "2-4 business days" как текст ETA и сопоставляет priority с express, если именно так ваш продукт показывает этот вариант.
Checkout-поток никогда не видит форму партнёра. Он каждый раз читает один тип ShippingQuote, независимо от того, какой перевозчик стоит за ним. Это сильно упрощает логику цен, подписи в интерфейсе, сортировку и тесты.
В этом и есть практическая ценность внутреннего контракта. Он не делает вид, что оба провайдера одинаковы. Он определяет маленькую общую форму, которую ваш продукт реально использует.
Позже, если вы замените provider B на нового перевозчика, большая часть приложения останется нетронутой. Вы обновите один адаптер, прогоните интеграционные тесты и сохраните те же стабильные модели в checkout. Вот как выглядит настоящий vendor abstraction layer: тонко, честно и только в пределах того, что нужно продукту.
Ошибки, которые создают иллюзию абстракции
Ложная абстракция выглядит аккуратно на схеме, но детали вендора всё равно просачиваются в продукт. Если ваше приложение по-прежнему знает названия полей партнёра, коды ошибок и странные формы ответа, обёртка — это просто декорация.
Самая частая ошибка — копировать полную схему вендора в кодовую базу и называть это внутренней моделью. Сначала это кажется быстрым решением. Через месяц один партнёр добавляет три необязательных поля, переименовывает одно значение enum, и ваше приложение меняется, хотя сам продукт не менялся.
Настоящий внутренний контракт оставляет только то, что нужно продукту. Если checkout нужны дата доставки, стоимость доставки и tracking ID, оставьте только их. Не тащите с собой ещё сорок полей только потому, что партнёр их прислал.
Команды ещё и ломают границу, когда в спешке обходят обёртку. Один инженер вызывает SDK партнёра напрямую «только для этого случая», потом кто-то копирует этот путь, и вот у вас уже два источника правды. Следующее изменение у вендора превращается в поиск по следам.
Сигналы беды появляются рано. Компоненты интерфейса ветвятся по кодам ошибок вендора. Сервисы читают сырые payload вне обёртки. Внутренние типы обрастают nullable-полями, которыми никто не пользуется. Логика повторных попыток оказывается рядом с продуктовыми правилами.
Последнее наносит тихий вред. Повторы, таймауты, rate limits и идемпотентность должны быть ближе к слою интеграции. Правила вроде «показывать экспресс-доставку только для оплаченных заказов» должны жить в продуктовом коде. Смешайте их, и каждое изменение станет труднее тестировать.
Передавать коды ошибок вендора в UI — ещё одна утечка. Экран не должен заботиться о том, сказал ли партнёр ERR_1047 или ADDRESS_FAIL. Обёртка должна свести оба варианта к небольшому набору ошибок приложения, например invalid_address или service_unavailable. Так интерфейс остаётся стабильным, а сообщения — понятнее для пользователя.
Добавлять поля «на всякий случай» звучит безобидно, но это делает контракт мягким. Каждое поле, которое вы открываете наружу, становится обещанием, которым кто-то может начать пользоваться. Позже, когда вы захотите навести порядок, команды уже будут зависеть от данных, которые вы вообще не собирались поддерживать.
Хорошая абстракция немного строже, и в этом весь смысл. Она защищает стабильные модели, удерживает изменения интеграции в рамках и намного упрощает добавление второго провайдера.
Проверки перед релизом
Обёртка готова к продакшену, когда команда может описать её, не открывая документацию партнёра. Если на это уходит больше одной страницы, контракт, скорее всего, всё ещё слишком близок к сырому ответу.
Большая часть поломок начинается вне вашего продукта. Партнёр переименовывает одно поле, меняет enum или начинает присылать null там, где раньше приходила строка. Остальная часть приложения не должна ощущать ничего этого за пределами слоя маппинга.
Оставьте проверки короткими и строгими:
- Попросите одного инженера объяснить внутренний контракт на одной странице простым языком.
- Подменяйте фикстуры партнёра в тестах, не трогая продуктовый код.
- Сводите ошибки партнёра к небольшому набору состояний приложения, а не к сырому тексту вендора.
- Намеренно удалите или переименуйте поле в фикстуре и убедитесь, что тесты маппинга падают сразу.
- Логируйте сырой ответ и преобразованный результат с одним и тем же request ID, скрывая секреты.
Небольшой пример хорошо показывает суть. Допустим, ваше приложение ожидает deliveryEtaDays, но один провайдер присылает eta_days, а другой — estimated_delivery. Продуктовый код никогда не должен заботиться о том, какое имя выбрал партнёр. Тесты должны ловить несовпадение там, где ответ преобразуется, а не позже в checkout.
Ещё до релиза прогоните не только happy path, но и неприятные случаи. Имитируйте таймаут. Отправьте неполный payload. Верните неизвестный статус. Если приложение каждый раз всё равно попадает в понятное состояние, значит контракт работает как надо.
Когда эти проверки проходят, обёртка, скорее всего, достаточно маленькая, достаточно строгая и достаточно скучная, чтобы доверять ей в продакшене.
Что делать дальше
Начните с одного потока партнёра, который и так меняется слишком часто. Shipping quotes, проверки налогов, проверки личности и выплаты — частые проблемные места, потому что поля там дрейфуют, а пограничных случаев становится всё больше. Сначала оберните один поток, выкатите его и поучитесь на реальном использовании, прежде чем трогать все интеграции.
Сделайте первый контракт тонким. Если продукту нужны только статус, сумма, валюта, reference ID и причина ошибки, остановитесь на этом. Небольшой контракт легче ревьюить, тестировать и держать стабильным, когда вендор добавит ещё десять ненужных полей.
Привлеките к ревью и продукт, и инженерию. Продукт подскажет, какие состояния важны для пользователей и поддержки. Инженерия покажет, какие поля безопасны, какие шумные и где начнут просачиваться причуды провайдера, если вы не будете строгими.
Помогает простой чек-лист. Пишите названия внутренних типов на языке продукта, а не на языке вендора. Держите vendor ID и raw payload на границе. Убирайте названия провайдеров из общих моделей, событий и подписей в UI. Добавляйте тесты на сопоставление, отсутствующие поля и смену статусов. Логируйте сырые ответы, чтобы команда могла отлаживать без изменения контракта.
Здесь команды часто оступаются. Поле с названием вроде carrier_code или partner_status выглядит безобидно, но как только оно попадает в общий код, форма вендора начинает управлять продуктом. UI подхватывает термины провайдера, а замена этого провайдера позже становится дорогой.
Если вы строите типизированные SDK для API партнёров, относитесь к обёртке как к продуктовому коду, а не как к glue code. Назначьте ей владельца, версионируйте аккуратно и меняйте её, когда меняется потребность продукта.
Один небольшой шаг уже достаточен, чтобы доказать подход. Проведите одного провайдера через новую обёртку, заставьте один экран продукта читать только внутренние модели и обновите один сценарий поддержки, чтобы он использовал новые названия статусов.
Если вашей команде нужен ещё один взгляд на этот контракт или план внедрения, Oleg Sotnikov на oleg.is занимается таким видом консультаций в формате Fractional CTO для стартапов и небольших компаний. Это практичный вариант, когда нужны более ясные архитектурные решения без превращения процесса в тяжёлый проект.
Часто задаваемые вопросы
Что такое тонкий внутренний контракт?
Тонкий внутренний контракт — это небольшой набор полей и состояний, которые реально использует ваш продукт. Ваш адаптер один раз преобразует ответ каждого вендора в этот формат, чтобы остальная часть приложения работала с вашими моделями, а не с payload партнёра.
Почему типизированных SDK недостаточно сами по себе?
Типизированные SDK только упрощают вызов и проверку типа ответа вендора. Они не мешают продуктову коду зависеть от названий полей, значений enum и странных форм ответа у партнёра.
Какие поля стоит оставить во внутренней модели?
Начинайте не с документации API, а с действия продукта. Оставляйте только те поля, которые сегодня поддерживают реальный экран, правило, отчёт или задачу поддержки, а всё остальное держите на границе.
Стоит ли хранить сырой ответ в коде продукта?
Храните сырые payload'ы в слое адаптера — для логов и отладки. Не передавайте их в checkout, правила ценообразования, отчётность или UI, иначе граница быстро начнёт протекать.
Как обрабатывать разные значения статусов у разных провайдеров?
Выберите один внутренний набор статусов и заставьте каждого провайдера сопоставляться с ним. Так ваше приложение будет получать один понятный ответ, например pending, in_transit или failed, даже если у вендоров совсем разные названия.
Должен ли интерфейс когда-нибудь видеть коды ошибок вендора?
Нет. UI должен видеть небольшой набор прикладных ошибок, например invalid_address или service_unavailable, а в логах пусть остаются код партнёра и сырое сообщение для работы поддержки.
За что должен отвечать один адаптер?
Один адаптер должен отвечать за детали endpoint'а, авторизацию, повторы, парсинг, валидацию и сопоставление для конкретной операции партнёра. Продуктовый код должен вызывать адаптер и получать обратно один стабильный формат результата.
Как понять, что моя абстракция ненастоящая?
Ложная абстракция всё равно пропускает названия полей и детали ответа в общий код. Если компоненты ветвятся по кодам партнёра или сервисы читают сырые поля вне обёртки, значит контракт не выполняет свою работу.
Как протестировать это до релиза?
Используйте тесты сопоставления, которые падают сразу, как только вендор меняет поле, enum или поведение null. Ещё прогоняйте плохие сценарии специально: таймауты, неполные payload'ы и неизвестные статусы — и проверяйте, что приложение всё равно приходит в понятное состояние.
С чего начать, если в приложении уже везде используются данные в формате вендора?
Начните с одного потока, который уже создаёт много изменений, например с shipping quotes или payouts. Сначала оберните именно его, оставьте контракт маленьким и докажите, что одна страница может работать только на внутренних моделях, прежде чем расширять подход.


