Тестирование шлюза федеративных моделей перед всплесками трафика
Тестирование шлюза федеративных моделей помогает обнаружить медленные ответы, простои и некорректные вызовы инструментов с помощью фейковых вендоров до того, как реальные пользователи начнут нагружать систему.
Содержание
Почему первые всплески трафика ломают шлюзы
Первый всплеск трафика редко ломает шлюз из-за объёма сам по себе. Он ломается потому, что реальные пользователи создают проблемы с таймингом, которые чистые тесты никогда не показывают.
Десять спокойных запросов в стейджинге могут выглядеть нормально. Двести перекрывающихся запросов обнаружат накопление очередей, штормы повторов и таймауты за пару минут. Один медленный вендор может держать открытым весь путь запроса, пока шлюз ждёт ответа, пытается выполнить фоллбек или повторяет тот же вызов. Как только достаточно запросов накапливается, задержка распространяется. Потребление памяти растёт, воркеры загружены, и даже здоровые вендоры начинают казаться медленными.
Вызовы инструментов усугубляют ситуацию. Некорректный вызов инструмента — это не просто один плохой ответ от одной модели. Он может вызвать ошибки схемы, сбои парсера, неправильные повторы и запутанные правила отката по всему потоку. Если шлюз пропускает один сломанный полезный груз дальше, следующая служба часто расплачивается за это.
Простой пример показывает, как быстро это происходит. Допустим, ваше приложение отправляет каждый пользовательский запрос трем вендорам для маршрутизации, ранжирования или фоллбека. Вендор A отвечает за 800 мс. Вендор B зависает на 12 секунд. Вендор C возвращает вызов инструмента с неправильной формой аргумента. При лёгком тестировании это может выглядеть как одна строка лога о задержке. При реальном трафике шлюз начинает ждать, повторять и держать соединения открытыми. Вскоре одна слабая точка превращается в очередь.
Маленькие тестовые кейсы это пропускают, потому что они слишком «чистые». Они используют короткие промпты, один инструмент, тёплые кэши и по одному запросу за раз. Пиковые часы выглядят совсем иначе. Пользователи шлют грязный ввод. Вызовы приходят вспышками. Некоторые клиенты повторяют запрос, прежде чем первый запрос завершится.
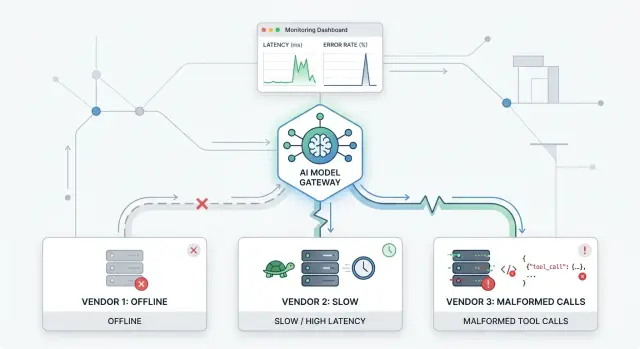
Команды, которые эксплуатируют компактные AI-системы, учатся этому рано: шлюзы сдают на краях. Они ломаются там, где происходят провалы по таймингу, где вендоры расходятся во мнениях, и где вывод инструментов становится грязным. Поэтому фейковые вендоры важны до первого реального всплеска, а не после него.
Что должны имитировать ваши фейковые вендоры
Хорошее тестирование шлюза федеративных моделей начинается с фейковых вендоров, которые ведут себя как настоящие провайдеры, включая раздражающие моменты. Если ваш тестовый вендор всегда отвечает быстро, чисто и бесконечно, вы узнаете почти ничего.
Начните с нормального поведения. Большинство вызовов должно проходить успешно, возвращать разумный вывод и занимать правдоподобное время. Вендор, который отвечает за 40 мс каждый раз, не кажется реальным. Дайте распределение времени. Один ответ приходит за 800 мс, другой за 2.1 с, а ещё один за 5 с при большем промпте.
Затем заставьте того же вендора проваливаться способами, которые нагружают логику маршрутизации. Реальный провайдер может принять запрос, часть ответа стримить, а потом обрезать соединение. Этот случай важен, потому что шлюз должен решить, ретрайить ли, переключаться на фоллбек или остановиться, прежде чем выполнять дублирующую работу инструмента.
Лимиты скорости тоже должны проявляться не сразу, а после некоторого роста трафика. Лучший фейковый вендор позволяет пройти несколько успешных запросов, а затем начинает возвращать 429 при повышении нагрузки. Такой паттерн ловит шлюзы, которые выглядят здоровыми в маленьких тестах, но качаются при росте конкуренции.
Полезный фейковый вендор обычно имеет несколько привычек:
- правдоподобные задержки, а не фиксированное время
- частичные стримы, которые иногда обрываются на полпути
- лимиты скорости, которые появляются после некоторого числа успешных запросов
- сломанный JSON, отсутствующие поля или неправильное имя инструмента
- поведение, которое меняется со временем, а не один фиксированный сбой
Плохие вызовы инструментов заслуживают особого внимания. Один вендор может прислать JSON со завершающей запятой. Другой может вызвать web_serch вместо web_search. Третий может вернуть правильное имя инструмента, но с неправильной формой аргумента. Это выглядят как мелкие ошибки, но они создают большие проблемы по каскаду, если ваш парсер, логика повторов или раннер инструментов ожидают идеального вывода.
Поведение, основанное на времени, делает тесты гораздо честнее. Вендор может вести себя нормально первые 20 запросов, замедлиться следующие 10, а затем начать смешивать медленные ответы с искаженными вызовами инструментов. Многие шлюзы проходят изолированные проверки и падают только после накопления состояния.
Простое правило: фейковые вендоры должны ощущаться слегка непоследовательными, а не случайными. У реальных провайдеров есть паттерны. Они замедляются под нагрузкой, строже себя ведут при лимитах и становятся грязнее при стриминге или сложном использовании инструментов. Если ваши тестовые дублеры копируют это поведение, ваш первый всплеск трафика гораздо с меньшей вероятностью преподаст неприятный сюрприз в проде.
Задайте правила отказов до запуска теста
Случайный хаос — это не план тестирования. Перед началом тестирования шлюза федеративных моделей решите, какие отказы для вас важнее всего с точки зрения пользователей и бюджета. Начните с случаев, которые реальнее всего повредят трафику: вендор, который таймаутится, вендор, который отвечает слишком медленно, и вендор, который возвращает сломанный вывод инструмента.
Простая ранжировка работает хорошо. Если задержка в 20 секунд блокирует оформление заказа, поддержку или внутренний рабочий процесс, протестируйте это раньше редких крайних случаев. Если одна модель часто уходит в плохие вызовы инструментов, поставьте её вверху списка. На первом дне вам не нужна гигантская матрица. Нужен короткий список, соответствующий реальному риску.
Установите бюджет таймаута для каждого вендора вместо одного глобального числа. Вендоры ведут себя по-разному, и ваш шлюз должен относиться к ним по-разному. Быстрая модель классификации может получить 2 секунды. Большая модель рассуждения — 8. Если вы шлёте работу в Claude, GPT и open source модель через один шлюз, дайте каждому маршруту лимит, подходящий для задачи.
Правила ретраев тоже нужны. Слепые повторы часто усугубляют проблему. Делайте ретрай, когда ошибка выглядит временной, например сетевой таймаут или 5xx. Не ретрайте, когда вендор вернул некорректный вывод инструмента или плохой JSON — следующая попытка скорее всего повторит ту же ошибку.
Отказывайтесь быстро, когда ожидание не приносит пользы. Если запрос уже пропустил пользовательский дедлайн, прекратите и верните понятный фоллбек. Это может означать использование меньшей модели, пропуск шага с инструментом или возвращение простого текста с сообщением, что действие не удалось выполнить.
Запишите заранее, что значит успех. Держите критерии конкретными:
- шлюз переключается на другой вендор в течение 3 секунд после таймаута
- количество повторов не превышает бюджет запроса
- сломанные вызовы инструментов не крашат воркер
- логи показывают, какое правило сработало и почему
Если вы не можете сформулировать успех в одном предложении на правило, тест всё ещё слишком расплывчат.
Стройте тестовый цикл шаг за шагом
Начните с минимальной конфигурации, которой вы доверяете: один фейковый вендор, который отвечает корректно, использует нормальные задержки и возвращает форму, которую ожидает ваш шлюз. Если этот путь ненадёжен, все последующие результаты будут вводить в заблуждение.
Сначала держите трафик скучным. Отправляйте небольшой стабильный поток запросов в течение нескольких минут, чтобы увидеть базовую линию. Вам нужно знать нормальную латентность, частоту повторов и завершаются ли ответы корректно.
В тестировании шлюза федеративных моделей чистые сравнения важнее больших чисел. Измените одну вещь, проведите тот же тест снова и сравните результаты. Если вы добавите таймауты, повторы и плохие полезные данные одновременно, вы не поймёте, что именно вызвало сбой.
Простой цикл работает хорошо:
- Запустите одного фейкового вендора с нормальным поведением и зафиксируйте базу.
- Добавьте один режим сбоя, например таймаут или ошибку 500.
- Держите объём запросов постоянным и следите за задержкой, числом повторов и итоговым статусом.
- Повышайте конкуренцию фиксированными шагами: 5, 20, 50, затем 100.
- Повторяйте тот же прогон после каждого изменения в шлюзе.
Эти фиксированные скачки важны. Прыжок с 10 до 1000 запросов выглядит драматично, но скрывает точку, где шлюз начинает шататься. Меньшие шаги показывают, когда формируются очереди, когда накапливаются повторы и когда путь фоллбека начинает делать слишком много работы.
Записывайте каждый прогон в одном и том же формате. Короткая таблица или сводка лога достаточна: число запросов, конкуренция, средняя латентность, p95, общее число повторов, упавшие вызовы и какое поведение вендора вы включили. Такая привычка экономит часы, когда два теста похожи, но падают по разным причинам.
Если вы меняете правила маршрутизации, лимиты повторов или таймауты, снова прогоните исходную базу перед дальнейшими изменениями. Небольшие правки могут сдвинуть поведение так, что это легко пропустить. Лучший тестовый цикл не сложный. Он воспроизводим, немного скучен и легко сравним между прогонками.
Симулируйте медленные ответы, не скрывая причину
Медленный вызов модели может выглядеть как пять разных багов, если смешать все задержки в кучу. Разделите замедление на этапы. Отложьте заголовки ответа, подавайте тело по частям, затем снова приостановитесь перед возвратом результата инструмента.
Такая настройка показывает, где именно шлюз застревает. Некоторые системы падают при установлении соединения. Другие держат стрим открытым, но захлёбываются, когда результат инструмента приходит поздно.
Начните с одного медленного вендора
Замедляйте сначала только одного вендора. Держите остальных быстрыми и чистыми. Если каждый фейковый вендор тянет одновременно, вы доказываете, что система может стать медленной, но не узнаёте, какой таймаут сработал, какая очередь выросла или какое правило фоллбека ухудшило ситуацию.
Используйте два типа задержек. Короткие паузы 1–3 секунды выявляют нервную логику повторов и плохие пользовательские таймауты. Длинные подвисания 20–60 секунд показывают, держатся ли воркеры вечно, накапливаются ли запросы за ними и выполняется ли код очистки.
Наблюдайте систему вокруг медленного вызова, а не только итоговую ошибку:
- длина очереди запросов
- число открытых соединений на вендор
- время ожидания до первого байта
- время ожидания результатов инструмента
- число повторов на запрос
Если очередь растёт, а CPU спокойный, скорее всего шлюз ждёт I/O и держит работу слишком долго. Если повторы растут сразу после таймаута, у вас может быть шторм повторов. Один таймаут в шлюзе может вызвать ретрай в SDK, затем ещё в job-воркере. Трафик быстро умножается.
Небольшой тест делает это легко заметным. Вендор A отвечает за 300 мс. Вендор B ждёт 2 секунды перед заголовками, медленно стримит, затем делает паузу 15 секунд перед результатом инструмента. Вендор C остаётся здоровым. Если запросы всё равно накапливаются по всем трём вендорам, скорее всего бутылочное горлышко в планировщике или общем пуле воркеров, а не в самом вендоре.
Цель проста. Вы не пытаетесь доказать, что медленные ответы существуют. Вы пытаетесь назвать конкретную стадию, которая вредит системе, а затем исправить именно её без догадок.
Форсируйте плохие вызовы инструментов и грязный вывод
Шлюзы обычно ломаются на уродливых ответах, а не на чистых простоях. Один вендор может вызвать инструмент, который ваш роутер не знает. Другой может прислать JSON, который парсится, но всё равно ломает логику. Тестирование федеративного шлюза становится гораздо полезнее, когда фейковый вендор специально ведёт себя «мусорно».
Начните с отсутствующих полей в аргументах инструмента. Удаляйте по одному обязательному полю, затем пробуйте null, пустые строки и неправильные типы. Если инструмент ждёт query, account_id и limit, протестируйте все способы, как эти значения могут пойти не так. Парсер, который просто говорит "bad request", недостаточен. В логе должно быть указано, какой вендор это прислал, какое поле провалилось и что шлюз сделал дальше.
Затем возвращайте JSON, который валиден, но имеет неправильную форму. Эта ошибка легко проходит мимо, потому что парсер удачно её принимает, и плохие данные утекают дальше в систему. Допустим, ожидаемый инструмент — get_weather с аргументами { city: "Berlin", units: "c" }, а вендор возвращает weather.lookup с { location: "Berlin", unit: "celsius" }. Парсер может принять структуру, но бизнес-логика ломается.
Это небольшое несоответствие портит маршрутизацию, повторы и аудиторские следы. Может появиться ещё худшая ошибка: шлюз думает, что вызов удался, и отправляет уверенный ответ, построенный на пустоте.
Грязный вывод так же важен. Некоторые модели смешивают плейн-текст с некорректным полезным грузом в одном ответе. Вы можете получить "Я нашёл счёт" и затем половину JSON-объекта, лишнюю запятую или усечённый блок аргументов. Ваш шлюз не должен пропускать такой текст как будто инструмент сработал. Он должен отделять текст для пользователя от провалившегося вызова инструмента и пометить ответ явно.
Используйте одного фейкового вендора, который ведёт себя так в каждом пятом запросе. Другой может менять имена инструментов без предупреждения. Небольшие паттерны быстро выявляют баги парсера.
Когда парсер фиксирует ошибку, делайте её точной. Включите имя вендора, request ID, сырое имя инструмента, ошибку схемы и указание, ретрайил ли шлюз или остановился. Если вашей команде нужно десять минут, чтобы понять, что произошло, сообщение всё ещё слишком расплывчато.
Хороший тест заканчивается скучным результатом: шлюз отклоняет плохой вызов, сохраняет сессию стабильной и оставляет чистую запись для следующего, кто будет это дебажить.
Простой пример с тремя вендорами
Прогоните 120 запросов через ваш шлюз с тремя фейковыми вендорами и одним простым правилом: каждый запрос просит один и тот же инструмент и ожидает одну и ту же форму ответа. Это делает тест легче для чтения, потому что вы можете свалить изменения на поведение вендора, а не на меняющиеся промпты.
Вендор A — спокойный. Отвечает примерно за 400 мс и остаётся здоровым на протяжении всего прогона. Вендор B стартует нормально, затем после 50-го запроса замедляется и начинает брать 8–12 секунд. Вендор C держит нормальную скорость, но каждый десятый запрос возвращает сломанный вызов инструмента, например отсутствие полей или неправильно сформированный JSON.
Ваш шлюз должен продолжать обслуживать трафик, не застревая, когда B и C идут плохо. После того как B переступит ваш лимит таймаута или латентности, роутер должен посылать туда меньше запросов и смещать нагрузку на A. Когда C присылает сломанный вызов, шлюз должен отклонить этот ответ, зафиксировать ошибку парсинга и при правилах ретрая попробовать другой вендор.
Чистый прогон обычно выглядит так:
- запросы 1–50 распределены по A, B и C
- запросы 51–120 уходят от B по мере роста его латентности
- каждый десятый ответ от C помечается как ошибка вызова инструмента
- общая доля успехов остаётся стабильной, потому что A поглощает дополнительную нагрузку
Логи важны так же, как и процент прохождения. Ваша команда должна уметь прочитать несколько минут логов и объяснить, почему запрос 67 пошёл к A вместо B, почему запрос 80 сделал ретрай после ошибки от C и почему ни один воркер не застрял в ожидании мёртвого апстрима.
Если команда не может объяснить эти исходы, тест не справился со своей задачей. Oleg Sotnikov часто подталкивает команды к тому, чтобы поведение при отказах было читаемым, прежде чем они гонятся за сырой скоростью, и это хороший пример почему. Шлюз, который аккуратно перераспределяет трафик — полезен. Шлюз, который делает это и оставляет ясный след в логах — тот, которому можно доверять во время реального всплеска трафика.
Ошибки, которые тратят время на тесты
Самая большая трата времени — тестирование карикатурных отказов. Вендор, который полностью уходит, легко анализируется. Реальная проблема обычно начинается в грязной середине: ответы по 8 секунд вместо 800 мс, короткие всплески ошибок 502 или инструменты, которые работали один раз и ломаются в следующий раз.
Если вы тестируете только полные простои, вы пропускаете поведение, которое чаще всего вредит пользователям сначала. Шлюз может не сработать быстро: он может продолжать принимать трафик, складывать запросы и выглядеть почти нормально до того момента, когда латентность прыгнет для всех.
Ретраи создают следующую ловушку. Команды часто добавляют их на ранних этапах, а затем забывают поставить жёсткий предел. Один медленный вендор может вызвать шторм повторов, и этот шторм хуже исходной неисправности. Вместо одного отставшего запроса у вас теперь три-четыре копии, гоняющиеся по тому же плохому пути.
Вот почему рост очереди так важен. Шлюз переживёт несколько медленных ответов. Он страдает, когда эти ответы блокируют воркеры, держат соединения открытыми и старят каждый ожидающий запрос позади них. Если вы не следите за очередью, вы можете уйти с мыслью, что тест прошёл, потому что доля ошибок осталась низкой.
Набор простых счётчиков обычно говорит правду быстрее, чем гигантский дашборд:
- глубина очереди
- возраст старейшего запроса
- повторы на запрос
- доля таймаутов
- отдельно посчитанные ошибки парсера
Последний пункт часто упускают. Ошибки парсера — это не обычные модельные сбои. Если вендор вернул искажённый JSON или сломанный вызов инструмента, фикса может быть в ваших проверках схемы, санитайзере или правилах отката. Если вы смешиваете эти случаи с таймаутами и 5xx, вы теряете сигнал, который вам действительно нужен.
Ещё одна пустая трата — менять две переменные в одном прогоне. Если вы одновременно повышаете конкуренцию и сокращаете таймауты, вы не поймёте, что вызвало результат. То же самое при тестировании медленного вендора и нового парсера одновременно. Меняйте одну вещь, фиксируйте результат, затем переходите к следующей.
Звучит строго, но экономит часы. Чистые прогоны делают отказы скучными, а скучные отказы — те, которые вы можете быстро исправить.
Быстрая проверка перед открытием трафика
Последний проход должен быть скучным. Если что-то всё ещё неясно, трафик найдёт это быстро.
Начните с таймаутов. Каждый вендор нуждается в своём лимите, основанном на реальном поведении вендора, а не на одном общем числе для всех. Быстрый вендор может получить 8 секунд, медленнее — 20. Если вы оставите это расплывчатым, один плохой апстрим может держать весь запрос открытым дольше, чем пользователь готов ждать.
Затем жёстко ограничьте повторы. Один ретрай часто достаточно. Два могут быть приемлемы. Больше обычно превращает кратковременный сбой в медленную лавину, особенно когда несколько вендоров одновременно шатаются.
Короткий чеклист перед запуском помогает:
- поставьте ясный таймаут для каждого вендора и каждого пути инструмента
- держите повторы в небольшом фиксированном количестве и логируйте каждый ретрай
- проверьте, что правила фоллбека соответствуют реальной стоимости отказа
- убедитесь, что логи называют вендора, тип ошибки и request ID
- разделите дашборды так, чтобы медленные ответы и плохие полезные данные отображались как разные проблемы
Правила фоллбека требуют особой осторожности. Они должны соответствовать задаче, а не просто держать шлюз в живых. Для общего чат-ответа фоллбек на вторую модель может быть приемлем. Для вызова инструмента, затрагивающего биллинг, заказы или данные аккаунта, часто безопаснее закрыть канал.
Ваши логи должны отвечать на один вопрос за секунды: что сломалось, где и почему? "Request failed" ничего не говорит. "Vendor B timeout after 12s" или "Vendor C returned malformed tool arguments" — достаточно, чтобы коллега мог действовать.
Дашборды должны разделять латентность и качество полезных данных. Если оба попадают в одну корзину ошибок, вы теряете причину и гонитесь за неправильным фиксом. Медленные ответы указывают на таймауты и правила ёмкости. Плохие полезные данные указывают на парсинг, проверки схемы или защиту вывода.
Один финальный тест важнее, чем многие признаются: передайте настройку коллеге. Если он не сможет быстро её запустить по докам и скриптам, ваш тестовый риг ещё слишком хрупок для реального трафика.
Что делать дальше
Оставьте фейковых вендоров в регулярных релизных проверках. Если они запускаются только один раз, прямо перед релизом, ценность теста сильно падает. Маленькие изменения в маршрутизации, повторах, таймаутах, схемах инструментов или логах могут тихо сломать поведение, которое еще неделю назад выглядело нормально.
Хорошая практика — запускать один и тот же набор отказов для каждого релиз-кандидата. Один вендор должен таймаутиться. Один должен отвечать медленно. Один должен возвращать сломанные аргументы инструмента или грязный текст вокруг структурированного вывода. Это даёт вашей команде устойчивый сигнал, а не однократную снимок.
Перед большим запуском репетируйте один всплеск трафика целенаправленно. Делайте это близко к релизу, чтобы код, настройки и дашборды соответствовали реальности. Смотрите, кого зовут на пейдж, как быстро люди замечают проблему и ведёт ли шлюз себя спокойно при отказе. Короткая тренировка экономит часы догадок позже.
Держите плейбук команды коротким, чтобы люди действительно его читали. Он должен ответить на четыре простых вопроса: какие отказы вы симулируете каждую неделю, какие метрики и логи команда проверяет в первую очередь, когда переключаться, ретраить или останавливать выполнение инструмента и кто принимает решение, если пользователи начинают видеть ошибки. Пропишите имена ответственных. Расплывчатая ответственность всё замедляет.
Если вы хотите внешнего обзора, Oleg Sotnikov at oleg.is помогает стартапам и небольшим командам подтянуть правила отказов шлюза, инфраструктуру и практическое принятие AI. Такой обзор полезен, когда вы уже деплоите модели в продакшн, но хотите более чистые правила фейловера, более бережные системы и меньше сюрпризов в неделю запуска.
Цель проста: когда вендор ведёт себя плохо, ваш шлюз должен вести себя предсказуемо. Если команда может доказать это на каждом релизе, всплески трафика перестают быть загадкой.
Часто задаваемые вопросы
Почему всплески трафика так быстро ломают шлюз модели?
Трафиковые всплески обычно выявляют проблемы с таймингом, а не просто большой объём. Медленные вендоры, зависающие запросы, повторы и открытые соединения быстро накапливаются, и одна слабая точка может замедлить весь шлюз.
Что должны копировать фейковые вендоры в реалистичном тесте?
Заставьте их вести себя как настоящие провайдеры. Пусть большинство запросов проходят успешно, а затем добавьте неравномерную задержку, частичные стримы, поздние лимиты скорости, некорректный JSON, неправильные имена инструментов и поведение, которое меняется после накопления нагрузки.
Какой первый тест лучше всего запустить?
Начните с одного фейкового вендора, который отвечает корректно и использует нормальные задержки. Сначала прогоните небольшую устойчивую нагрузку, чтобы получить базовую линию, прежде чем добавлять таймауты, ошибки или некорректные ответы инструментов.
Должен ли у каждого вендора быть один и тот же таймаут?
Используйте бюджет таймаута для каждого вендора, исходя из задачи. Быстрая модель может получить пару секунд, более тяжёлая — больше, но для каждого маршрута предел должен соответствовать пользовательскому дедлайну.
Когда следует повторять неудачный вызов вендора?
Повторяйте вызов только когда ошибка выглядит временной, например сетевой таймаут или 5xx. Не делайте повторы при некорректном JSON или неправильных аргументах инструмента — следующий запрос скорее всего повторит ту же ошибку и только увеличит нагрузку.
Как симулировать медленные ответы, не делая тест размытым?
Замедляйте только одного вендора за раз и разделяйте задержку на этапы: задержка заголовков, медленная подача тела, пауза перед результатом инструмента. Это покажет точное место, где шлюз начинает ждать слишком долго.
Как шлюз должен обрабатывать некорректные вызовы инструментов?
Форсируйте отсутствующие поля, неправильные типы, неверные имена инструментов и корректный JSON с неправильной формой. Шлюз должен отклонять плохой вызов, сохранять устойчивость сессии и логировать, что именно сломалось, понятным языком.
Какие метрики показывают, что шлюз начинает шататься?
Следите за глубиной очереди, возрастом старейшего запроса, количеством повторов на запрос, долей таймаутов и количеством ошибок парсера. Эти метрики покажут, борется ли шлюз с медленным I/O, плохими полезными данными или штормом повторов.
Какие ошибки больше всего тратят время на тестирование?
Трата времени идёт на тесты «в стиле мультфильма», где вендор полностью уходит в офлайн. Реальные проблемы начинаются в «грязной середине»: ответы по 8 секунд вместо 800 мс, короткие всплески 502, или инструменты, которые работают один раз и ломаются на следующем запросе.
Что стоит проверить прямо перед запуском трафика?
Проверьте таймауты для каждого вендора, жёсткие лимиты повторов, правила отката и логи перед включением трафика. Потом попросите коллегу быстро переиграть настройку по документации и скриптам; если у него не получается, риг всё ещё хрупок.


