Terraform workspaces против отдельных state files для изоляции
Terraform workspaces и отдельные state files по-разному влияют на изоляцию клиентов, права доступа, drift и восстановление. Разберитесь, какой вариант безопаснее.
Содержание
Что именно вы хотите изолировать?
Прежде чем выбирать между workspaces и отдельными state files, определите, что именно должно оставаться раздельным. Команды часто говорят «клиенты», но за этим могут стоять очень разные вещи. Иногда людям нужно просто более аккуратное именование. Иногда нужна жёсткая граница, чтобы один инженер, один секрет или одна ошибка при apply не затронули среду другого клиента.
Это не одна и та же задача.
Workspaces проще в эксплуатации, потому что они оставляют один код и один шаблон backend. Это экономит время. Но это не отвечает на более сложный вопрос: если кто-то запустит apply не там, куда нужно, до чего Terraform всё ещё сможет дотянуться?
Запишите границы, которые важнее всего:
- данные state
- secrets и переменные
- права в облаке
- процесс согласования изменений
- audit и записи о drift
Если у двух клиентов общий код, но они не должны делить ни один из этих уровней, вы выбираете не метод именования. Вы выбираете границу безопасности.
Радиус ущерба важнее аккуратности папок. Задайте прямой вопрос: если у provider credential ошибка, модуль изменился или кто-то выбрал не тот workspace, сможет ли Terraform затронуть ресурсы другого клиента? Если ответ должен быть «нет», воспринимайте это как жёсткое правило.
В это решение нужно включить и drift. Если предупреждения по одному клиенту смешиваются с общим процессом проверки, люди пропускают важные вещи. Обычно так происходит, когда разделение есть в названиях, но нет в доступе, согласованиях или хранилище state.
Правила аудита часто быстро снимают спор. Некоторым клиентам нужны отдельные логи доступа, отдельная история согласований и отдельные хранилища secrets из-за контрактов или проверок на соответствие требованиям. Более мягкая изоляция обычно потом создаёт больше работы. Приходится доказывать разделение вручную, потому что сама настройка его не обеспечила.
Небольшое агентство может позволить себе более мягкие границы для внутренних тестовых стендов. Но клиентские среды — это другое. Если вы ведёте пять платящих клиентов, каждый из них ожидает, что credentials, инфраструктура и история изменений останутся в своей зоне.
Как Terraform workspaces обеспечивают изоляцию
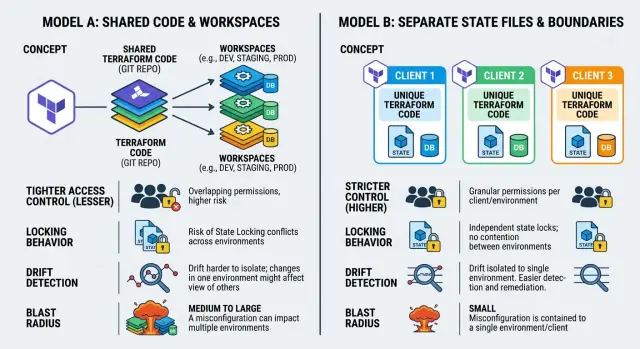
Terraform workspaces создают отдельные снимки state внутри одного backend. У клиента A может быть один state, а у клиента B — другой, даже если они используют один и тот же Terraform-код. Это даёт изоляцию на уровне state. Но не даёт полной изоляции всей системы.
Код при этом остаётся общим. Backend тоже остаётся общим. Если команда использует один remote backend, все работают с одной и той же системой хранения и обычно с одной и той же моделью доступа. Workspace лишь говорит Terraform, какой снимок state читать и обновлять.
В этом и заключается реальный масштаб workspace. Он разделяет записи о том, что существует. Но не разделяет владение кодом, backend и привычки людей, которые запускают команды.
На практике это означает несколько вещей:
- у каждого workspace свой снимок state
- одна и та же конфигурация может применяться ко всем workspace
- доступ к backend часто охватывает все workspaces, а не только один
- выбор не того workspace может направить plan на не того клиента
Именно с правами доступа команды часто удивляются. Если человек может читать и писать в backend, у него нередко больше доступа, чем ожидалось. Во многих схемах доступ не выдаётся с высокой точностью отдельно по каждому клиентскому workspace. Обычно доступ дают к bucket, аккаунту или проекту backend, и это может открыть все клиентские state внутри него.
Повседневный риск очень прост. Кто-то по ошибке выполняет terraform workspace select client-b или забывает переключиться обратно после предыдущей задачи. Plan при этом выглядит знакомо, потому что код тот же. Теперь изменения нацелены не на того клиента.
Небольшое агентство может жить с таким подходом, если у него строгие правила именования, внимательные проверки и очень мало операторов. Даже тогда workspaces зависят от того, что люди каждый раз правильно держат контекст. Если вам нужны жёсткие границы для доступа, аудита или просто спокойствия, одних workspaces обычно недостаточно.
Что меняют отдельные state files
Отдельные state files переносят изоляцию из метки внутри одной системы в настоящую границу в хранилище и доступе. У каждого клиента появляется своё место для state — обычно отдельный backend path, object prefix или даже отдельный bucket.
На первый взгляд это небольшая настройка хранения, но она влияет на то, кто может читать state, кто может применять изменения и какой ущерб может нанести одна ошибка.
В такой модели state каждого клиента становится отдельной единицей. Можно дать одной команде доступ к Client A, не открывая ресурсы Client B, outputs или secrets, которые лежат в state. Можно также настроить locking, retention и правила аудита отдельно для каждого клиента, а не делить одну политику на все workspaces.
Главное преимущество — меньший blast radius. Если кто-то запустит плохой plan для одного клиента, ошибка останется внутри его state. Она не затронет другого клиента, потому что у Terraform нет общего снимка state, на который можно случайно указать. Drift тоже проще удерживать в пределах. Когда у одного клиента что-то расходится с конфигурацией, вы проверяете и исправляете только этот state, а не разбираете смешанную схему.
Такой подход меняет ежедневную работу в нескольких местах. Вам нужен backend path или bucket для каждого клиента. IAM-правила должны быть привязаны к state каждого клиента, а не только к репозиторию целиком. Locks должны работать отдельно, чтобы команды не мешали друг другу. Ещё нужен понятный шаблон именования, чтобы цель была очевидна.
Последний пункт важнее, чем кажется. Отдельные state files дают более чистую изоляцию, но требуют больше структуры. Кто-то должен определить имена папок, названия backend, метки сред и шаги проверки. Если этого не сделать, команды начинают копировать конфигурации backend вручную, и мелкие ошибки накапливаются.
Моё мнение простое: если у клиентов должны быть разные права, отдельные линии оплаты или границы соответствия требованиям, отдельные state files обычно стоят дополнительной настройки. За это вы платите более сложной конфигурацией и более строгим процессом. Взамен получаете более крепкую стену между клиентами.
Сравните важные компромиссы
Обычно выбор сводится к одному вопросу: вам нужна мягкая граница или жёсткая?
Workspaces легче сопровождать. Отдельные state files сложнее настроить, но они ставят более надёжный барьер, когда кто-то ошибается.
Сначала идут права доступа. Если один и тот же backend, репозиторий и pipeline могут затрагивать все workspaces, изоляция настолько сильна, насколько силён ваш процесс. Разработчик, который может запускать apply в одном месте, часто может дотянуться и до другого workspace. Отдельные state files намного проще позволяют дать Client A доступ только к Client A. Это важно, когда клиенты, подрядчики или сотрудники поддержки не должны даже читать чужой state.
Следующая точка давления — drift. В workspaces проверки drift часто живут в одном общем pipeline, и это удобно поддерживать. Минус — размытая ответственность. Все думают, что кто-то другой займётся предупреждением. Отдельные state files делают ответственность понятнее, потому что у каждого клиента может быть свой job, своё расписание и свой путь уведомлений. Компромисс — дублирование. Если вы копируете одни и те же проверки пять раз и забываете обновить одну из них, drift может жить там неделями.
Неудачные apply многое говорят о blast radius. В схеме с workspaces плохой apply всё ещё может задеть не того клиента, если кто-то выбрал не тот workspace, использовал не те переменные или запустил общий pipeline со слабыми ограничениями. Восстановление тоже проходит напряжённее, потому что один и тот же путь изменений часто управляет многими средами. Отдельные state files ограничивают ущерб. Если ломается один клиент, вы чините один state, один lock и один путь восстановления.
Ручная работа накапливается быстрее, чем ожидают команды. Workspaces сначала уменьшают объём настройки. У вас один шаблон backend, один код и меньше движущихся частей. В первую неделю это кажется очень эффективным. Через несколько месяцев начинают мешать повторяющиеся действия людей: выбрать правильный workspace, проверить правильные переменные, подтвердить правильный account и ещё раз перепроверить цель plan.
Отдельные state files требуют больше работы в начале, но при хороших шаблонах могут убрать еженедельную суету. У каждого клиента есть своё имя backend, понятные credentials и отдельный pipeline. Команда меньше времени тратит на вопрос: «Я точно в нужном месте?»
Хорошее простое правило здесь такое. Если разным людям нужны разные права, отдельные state files безопаснее. Если одна доверенная команда управляет всеми клиентами и работает быстро, workspaces могут подойти. Если неудачные apply должны оставаться в пределах одного клиента, выигрывают отдельные state files. А если команда постоянно путается с контекстом, не полагайтесь на выбор workspace.
Используйте этот путь принятия решения
Начните с границы, которую нельзя нарушить. Если один клиент ни при каких условиях не должен видеть ресурсы, outputs или данные state другого клиента, воспринимайте это как жёсткое правило, а не как предпочтение. В таком случае обычно разумнее использовать отдельные state files. Отдельные cloud accounts или projects часто следуют за этим же решением.
Простой путь выбора помогает:
- Спросите, кому нужна изоляция. Если ответ связан с законом, контрактом или безопасностью клиентов, выбирайте отдельный state. Workspaces разделяют снимки state, но сами по себе не создают жёсткий человеческий барьер безопасности.
- Проверьте границу облака. Если у каждого клиента уже есть свой AWS account, GCP project или Azure subscription, держите границу Terraform такой же ясной. Один state на клиента лучше совпадает с реальной средой и упрощает правила доступа.
- Решите, кто запускает
planиapply. Если всем управляет маленькая внутренняя команда через контролируемый CI pipeline, workspaces могут быть удобны. Если изменения вносят разные инженеры, подрядчики или сами клиенты, отдельный state снижает риск пересечений. - Честно оцените дисциплину именования. Workspaces требуют, чтобы команда каждый раз аккуратно держала в порядке файлы переменных, настройки backend, именование и параметры provider. Некоторые команды так и делают. Многие — нет, особенно когда всё делается в спешке.
- Выберите вариант с наименьшим числом простых ошибок. Если одно неверное workspace, одна неправильная переменная или одна скопированная команда могут задеть не того клиента, схема слишком хрупкая.
Обычно это приводит к практичному разделению. Используйте workspaces, когда одной и той же доверенной командой управляются очень похожие стеки и команда готова к дополнительной аккуратности, которую требует контекст команд. Используйте отдельные state files, когда важнее клиентский доступ, границы оплаты, правила соответствия требованиям или обычный человеческий фактор.
Если сомневаетесь, выбирайте более сильную изоляцию. Дополнительные файлы раздражают. Ошибки между клиентами — хуже.
Пример: агентство с пятью клиентами
Небольшое агентство использует один Terraform module, чтобы разворачивать одинаковый стек для пяти клиентов. Инфраструктура у всех похожая: сеть, серверы приложения, база данных, мониторинг и несколько настроек, зависящих от клиента. Повторно использовать код логично. Проблемы начинаются, когда агентство пытается изолировать каждого клиента тем же самым шаблоном state.
Три клиента спокойно относятся к общей операционной модели. Та же небольшая команда применяет изменения, просматривает plans и решает обычные проблемы. Для этих клиентов workspaces могут быть нормальным вариантом, если команда дисциплинирована. Module остаётся тем же, backend остаётся тем же, а у каждого клиента свой workspace.
Остальным двум клиентам нужен более жёсткий контроль. Они просят отдельные согласования, отдельные credentials и более чистую историю аудита. Это меняет ответ. Как только разным людям нужны разные права, отдельные state files значительно упрощают жизнь. Агентство может жёстко ограничить каждый state file, разделить права на backend и снизить шанс того, что спешная правка затронет не того клиента.
Это важно, потому что команда уже однажды так ошиблась. Один инженер запустил plan в неверном workspace и заметил это только тогда, когда имена ресурсов выглядели странно. Ничего серьёзно не сломалось, но сигнал был понятен. После одной путаницы с workspace риск уже не теоретический.
Смешанная модель хорошо подходит для такого агентства. Для двух более строгих клиентов держите отдельные state files с раздельными правами на backend. Для трёх клиентов, которым подходят общие операции, используйте workspaces, и оставьте workspaces для внутренних sandboxes и краткоживущих тестовых сред.
Именно так этот выбор обычно выглядит в реальной жизни. Он меньше про красоту и больше про контроль ущерба. Workspaces быстры, когда всем управляют одни и те же люди. Отдельные state files требуют больше настройки, но создают более чёткие границы.
Типичные ошибки, которые создают проблемы
Команды попадают в неприятности, когда воспринимают Terraform workspaces как запертые комнаты. Это не так. Workspace помогает разделить state внутри одного backend, но не создаёт жёсткую границу безопасности для каждого клиента. Если одни и те же люди, репозиторий и credentials backend могут затрагивать все workspaces, одна ошибка при apply всё равно может попасть не к тому клиенту.
Именование создаёт больше хаоса, чем ожидают многие команды. Строка вроде client-a-prod выглядит нормально, пока кто-то не добавит prod-client-a-eu, а другой человек не прочитает её по-своему. Когда имя клиента и имя среды живут внутри одной расплывчатой схемы, люди выбирают не тот workspace, пишут хрупкую автоматизацию или строят исключения, о которых через полгода уже никто не помнит.
Простое и скучное правило именования экономит время. Держите идентификатор клиента и идентификатор среды отдельными полями в коде, переменных или путях backend. Если человеку нужно прочитать имя workspace, каждая часть должна быть очевидной.
Локальные credentials — ещё одно слабое место. Многие команды строят аккуратные CI-правила, проверяют plans в pull requests и требуют согласования перед apply. А потом один инженер запускает terraform apply с ноутбука с широким доступом и обходит весь процесс.
Обычно это происходит в самый неподходящий момент, часто когда клиенту нужен срочный фикс. Если вы хотите чистую изоляцию между клиентами, ограничьте права на запись только CI и используйте short-lived roles. Локальный доступ лучше оставить только для чтения, ограничить или вообще закрыть.
Политики backend тоже часто скатываются в copy-paste. Команда настраивает одну широкую политику для первого клиента, а потом использует её ещё для четырёх, потому что так быстрее. В итоге каждый state file находится за одними и теми же размытыми правами, и никто не может объяснить, кто что может читать, блокировать или изменять.
Обычно предупреждающие признаки такие:
- один инженер может unlock или изменять state всех клиентов
- одно правило backup покрывает всех клиентов, даже когда риск разный
- один шаблон пути state повторно используется в проектах, где нужна более жёсткая изоляция
Последняя ошибка легко игнорируется до дня релиза: никто не проверяет восстановление. Backups state есть, но никто не пробовал restore. Locks накапливаются, state file зависает, и команда начинает гадать под давлением.
Проведите тренировку восстановления до того, как она вам понадобится. Проверьте, как команда восстановит предыдущую версию state, снимет stale lock и убедится, что к работе допущены нужные люди. Для агентств, консультантов или схемы Fractional CTO, где несколько клиентов обслуживаются одновременно, это важнее идеальной структуры папок. Обычно работает та модель, в которой ошибки труднее сделать и легче ограничить.
Короткий чек-лист
Правильный выбор обычно проявляется в ежедневной работе, а не в архитектурных заметках. Если схема выглядит чистой на бумаге, но становится проблемной, когда кто-то восстанавливает state, меняет доступ или запускает plan не на того клиента, это принесёт неприятности.
Проверьте пять вещей, прежде чем принять решение:
- Уберите доступ одного клиента на бумаге и пройдите все шаги. Если для этого приходится трогать общие роли, общие настройки backend или общие CI job, изоляция слабая.
- Спросите, как инженер выбирает правильного клиента перед
planилиapply. Если ответ звучит как «сначала не забудь переключить workspace», ждите хотя бы один плохой день. - Проведите упражнение на восстановление. Если state одного клиента повреждён, сможет ли команда быстро восстановить только его, с понятным путём backup и без догадок?
- Проверьте схему на новом сотруднике. Если ему нужен длинный звонок, чтобы понять правила именования, скрытые исключения или структуру state, дизайн слишком хитрый.
- Проверьте audit trail. Вы должны иметь возможность показать, кто менял state, когда он это сделал и какого клиента затронул.
Хорошая модель изоляции проходит все пять пунктов без оправданий. Если два или три ответа звучат как «обычно» или «зависит», воспринимайте это как предупреждение.
Что делать дальше
Начните с простого инвентаря. Запишите каждого клиента, каждую среду, у кого должен быть доступ и что сломается, если кто-то применит не те изменения. Одна такая страница обычно проясняет ответ лучше, чем ещё один раунд споров.
Потом мысленно проведите маленький тест на сбой. Выберите одну модель и спросите: если разработчик нацелится не на того клиента, что он сможет читать, что он сможет изменить и насколько сложно будет восстановление? Для этого не нужна лаборатория. Пятнадцатиминутное упражнение уже покажет слабые места в правах доступа, именовании и границах state.
Простой план на одной странице должен охватывать четыре вещи:
- клиентов и среды, которыми вы управляете сегодня
- кто может выполнять plan, apply и читать state для каждого из них
- что произойдёт, если будет изменён не тот state
- как вы восстановите сервис после неудачного apply
Если ответы кажутся расплывчатыми, схема ещё не готова к росту. Упростите её сейчас, а не после появления шестого клиента.
Правила именования заслуживают больше внимания, чем обычно им уделяют команды. Рано решите, как будете называть backend, state files, workspaces, папки и переменные. Сделайте схему скучной и строгой. Если смешать prod, production и прозвища клиентов, кто-то в конце концов выберет не ту цель.
Также полезно выбрать один путь по умолчанию для новых работ. Если большинству клиентов нужна строгая изоляция, сделайте отдельные state files вариантом по умолчанию. Если одной командой управляются многие почти одинаковые среды с одними и теми же правилами доступа, workspaces могут быть достаточны. Смешанные модели тоже работают, но только если вы продумываете их специально.
Перед окончательным решением запишите точные шаги восстановления после неудачного apply. Укажите, кого уведомлять, как подтверждать drift, как восстанавливать state и кто одобряет повторную попытку. Если этот процесс выглядит медленным или запутанным, модель изоляции слишком мягкая или операционные правила слишком размыты.
Если текущая схема уже кажется запутанной, попросите второй взгляд, прежде чем добавлять новых клиентов. Oleg на oleg.is работает со стартапами и небольшими командами как Fractional CTO, помогая с инфраструктурой и архитектурными решениями, когда системы должны оставаться лёгкими и надёжными.
Примите решение, зафиксируйте его и используйте тот же подход для следующего клиента. Последовательность помогает держать ошибки маленькими.
Часто задаваемые вопросы
Что именно изолируют Terraform workspaces?
Workspaces разделяют снимок state для каждой цели, но не разделяют репозиторий, backend или доступ оператора. Если одни и те же учётные данные backend'а могут дотянуться до любого workspace, человек всё равно может направить Terraform не на того клиента.
Когда отдельные state files подходят лучше, чем workspaces?
Выбирайте отдельные state files, когда клиентам нужны разные права доступа, отдельные согласования, более понятная история аудита или более жёсткая защита от ошибок. Настройка сложнее, но одной ошибке намного труднее перейти к другому клиенту.
Достаточно ли Terraform workspaces для клиентских сред?
Они могут подойти для клиентских сред, если небольшая доверенная команда управляет всем через строгие CI-правила, а клиенты принимают общий операционный процесс. Если клиенты ждут жёсткой изоляции, workspaces обычно кажутся слишком мягким вариантом.
Нужны ли отдельные cloud accounts или projects вместе с отдельными state files?
Не всегда, но это часто помогает. Если у каждого клиента уже есть свой AWS account, GCP project или Azure subscription, то отдельный state в Terraform обычно лучше совпадает с реальной средой и упрощает доступ и восстановление.
Какой вариант лучше справляется с drift?
Обычно отдельные state files помогают лучше. Для каждого клиента можно настроить свой check, своё расписание и свой путь уведомлений. В workspaces drift часто живёт в одном общем pipeline, и из-за размытой ответственности предупреждения легче пропустить.
Как снизить риск применить изменения не к тому клиенту?
Перенесите apply в CI, используйте short-lived roles и сделайте цель максимально заметной в pipeline. Если люди запускают Terraform с ноутбуков с широким доступом, вы почти наверняка получите путаницу с workspace и ошибки между клиентами.
Может ли работать смешанная модель для агентства с несколькими клиентами?
Да, и для агентства это часто хороший вариант. Можно оставить workspaces для внутренних тестовых стендов или клиентов с низким риском, а для клиентов с более строгими правами, отдельным учётом и жёстким аудитом использовать отдельные state files.
Какой подход к именованию помогает избежать ошибок?
Держите схему простой и строгой. Отделяйте имя клиента и имя среды, а один и тот же формат используйте для папок, путей backend, переменных и названий pipeline, чтобы никому не приходилось гадать, что именно выбрано.
Кому разрешать запускать plan и apply?
Максимально ограничьте права на запись. Небольшая группа должна выполнять apply, а всем остальным лучше оставить только чтение, если им не нужно больше. Так согласования остаются понятными, а риск поспешной ошибки снижается.
Как проверить восстановление, прежде чем выбрать модель?
Проведите простой drill по восстановлению до того, как начнёте доверять настройке. Выберите одного клиента, восстановите предыдущую версию state, снимите stale lock и убедитесь, что нужные люди могут сделать это, не затрагивая state другого клиента.


