Тёплая реплика против восстановления из бэкапа
Тёплая реплика против восстановления из бэкапа: сравните скорость восстановления, риск потери данных и ежемесячные расходы, чтобы команда могла выбрать практический дефолт.
Содержание
Почему этот выбор важен в плохой день
В планах восстановление звучит просто. Вернуть приложение, восстановить базу данных, сказать пользователям, что всё в порядке. Когда что-то реально ломается, восстановление становится гораздо более приземлённым: как быстро команда сможет вернуть сервис, сколько данных потеряно и сколько денег пришлось потратить, чтобы это сделать.
Именно поэтому выбор между тёплой репликой и восстановлением из бэкапа имеет значение. Оба варианта относятся к disaster recovery. Оба могут выглядеть хорошо в таблице. Но в 2:13 ночи, когда срабатывают оповещения, заказы останавливаются, и кто-то спрашивает, сколько продлится простой, ощущения совсем другие.
Большинство команд не сталкиваются с этой проблемой в архитектурных обсуждениях — они сталкиваются с ней, когда начинается давление и каждая минута имеет цену. Восстановление из бэкапа кажется дешёвым, пока нужно найти правильный снимок, проверить его, поднять окружение и надеяться, что ничего не пропущено. Тёплая реплика кажется дорогой, пока она не сокращает восстановление с часов до минут.
Большинство людей заботятся в первую очередь о трёх вещах: как долго сервис будет недоступен, сколько недавних данных может исчезнуть и сколько стоит держать план восстановления готовым. Всё остальное идёт потом. Как только клиенты не могут войти, сделать заказ или доверять данным, внутренние процессы и техническая аккуратность начинают иметь гораздо меньшее значение.
Нет универсального идеального решения для всех компаний. Небольшой внутренний инструмент может спокойно обходиться бэкапами и спокойным процессом восстановления. Продукт с платящими пользователями в нескольких часовых поясах часто нуждается в чем-то быстрее, даже если это дороже. Цель — не идеал, а выбор дефолта, который соответствует ущербу, который бизнес реально может вынести.
Команды часто переплачивают за защиту, которой не пользуются, или недоподготавливаются и учатся на ошибках. Разумный дефолт — это компромисс: достаточно защиты для реального риска, без превращения восстановления во вторую штатную систему.
Что даёт тёплая реплика
Тёплая реплика — это вторая копия production-системы, которая поддерживается близко к боевой. Обычно у неё те же приложение, база данных и конфигурация, но она не обрабатывает весь трафик постоянно. Данные реплицируются с небольшим отставанием, поэтому при падении production команда не начинает с нуля.
Это меняет восстановление в практическом ключе. Серверы уже существуют. В базе данных уже есть большинство последних записей. Приложение уже умеет работать в этом окружении. Вместо того чтобы восстанавливать машины, откатывать большие бэкапы и надеяться, что всё сработает под давлением, команда в основном переключает трафик и проверяет, что вторая система здорова.
Тёплая реплика не отменяет всю работу. Всё ещё нужно переключить трафик, поднять standby-базу как writable (если требуется), проверить очереди, планировщики задач, логи, оповещения и интеграции с внешними сервисами. Даже так, переключение обычно значительно быстрее полного восстановления, потому что большая часть ожидания исчезает.
Компромисс — это постоянные издержки. Вы платите за дополнительный compute, хранение, трафик репликации и расширенный мониторинг. Вы также платите вниманием команды: кто-то должен тестировать failover, патчить оба окружения, следить за lag репликации и следить, чтобы реплика не ушла в дрейф относительно production.
Для многих команд эти расходы легче пережить, чем медленное восстановление. Если у продукта стабильная пользовательская активность, тёплая реплика часто даёт более спокойный дефолт. Вы тратите больше каждый месяц, но получаете более короткие простои и меньший риск потери недавних данных.
Проще говоря: восстановление из бэкапа — это план перестройки, а тёплая реплика — почти готовая запасная копия. Когда что-то ломается в 2 часа ночи, запас обычно выигрывает.
Что подразумевает восстановление из бэкапа
Восстановление из бэкапа означает, что вы восстанавливаетесь после сбоя, а не в процессе его. Команда хранит снимки, бэкапы баз данных и файлов в безопасном месте и восстанавливает сервис, когда боевой стенд не может продолжать работу.
На бумаге путь простой: развернуть новые серверы и хранилище, откатить последний пригодный бэкап, проверить, что приложение и данные согласованы, затем переключить на восстановленную систему. В реальности каждый шаг занимает время. Кому‑то нужно выбрать правильный снимок, проверить версии, подтвердить миграции, восстановить секреты и сертификаты, протестировать входы и платежи — и только после этого переводить пользователей.
Вот почему бэкап‑восстановление выглядит дешёвым в обычные недели. Вы не платите за второе тёплое окружение. Вы храните бэкапы, периодически тестируете их и избегаете постоянной платы за дублирующие compute, реплики баз данных и расширенный мониторинг. Для небольших команд с ограниченным бюджетом это реальное преимущество.
Компромисс — время ожидания. Если production‑база упала в 14:15, а последний чистый бэкап от 14:00, эти 15 минут записей могут быть безвозвратно потеряны. Заказы, сообщения, правки профилей и административные изменения могут исчезнуть, если только другая система их не зафиксировала. Вот где реальный риск потери данных.
Время восстановления тоже быстро растёт. Даже подготовленной команде может потребоваться от получаса до нескольких часов, чтобы вернуть всё, при условии, что бэкапы целы и скрипт восстановления работает. Если приходится импровизировать — простой увеличивается.
Восстановление из бэкапа часто разумно, когда простой менее болезнен, чем постоянная инфраструктурная стоимость. Это подходит для внутренних инструментов, ранних продуктов и систем, где пользователи могут повторить операцию. Это плохой выбор для приложений с постоянными платежами, реалтайм‑синхронизацией или записями, которые нельзя легко восстановить вручную.
Вы экономите деньги в краткосрочной перспективе, но соглашаетесь на медленное восстановление и реальный шанс, что самые свежие данные не вернутся.
Как сопоставить компромиссы
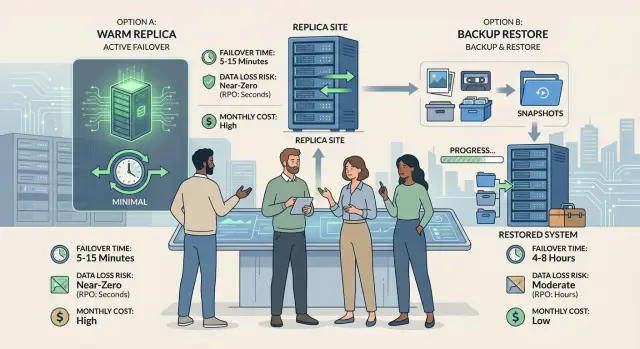
Когда production падает, разница проявляется быстро. Тёплая реплика обычно возвращает сервис за минуты. Восстановление из бэкапа часто занимает часы, потому что команде нужно поднять системы, восстановить данные и убедиться, что приложение действительно работает.
| Trade-off | Warm replica | Backup restore |
|---|---|---|
| Failover time | Обычно минуты. Вторая копия уже работает, команда переключает трафик и проверяет приложение. | Часто часы. Команда откатывает бэкапы, запускает базы и сервисы, затем тестирует вход, записи и фоновые задания. |
| Data loss risk | Ниже. Можно потерять только самые последние записи, которые не дошли до реплики. | Выше. Можно потерять всё, что было после последнего пригодного бэкапа, включая изменения, которые пользователи считали сохранёнными. |
| Monthly cost | Выше. Вы платите за дополнительный compute, репликацию, хранение и рутинные проверки. | Ниже на бумаге. Хранение дешёвое, а compute в основном выключен до аварии. |
| Cost during an outage | Ниже, если простой вредит выручке или доверию. Короткие простои означают меньше возвратов, меньше тикетов и меньше ручной работы. | Часто выше, чем команды ожидают. Дешёвая месячная схема может превратиться в длительный и дорогой простой. |
Потеря данных — то, где команды часто недооценивают риск. При тёплой реплике обычно теряются последние секунды или минуты транзакций и правок. При восстановлении из бэкапа разрыв может быть гораздо больше. Если последний чистый снимок был в 2:00 ночи, а сбой начался в полдень, всё, что было записано после 2:00, возможно, придётся восстанавливать вручную или оно будет утеряно навсегда.
Это не абстрактные записи. Клиент мог обновить платёжные данные. Менеджер по продажам мог добавить заметки к сделке. Саппорт‑агент мог закрыть десять тикетов. Пользователи чувствуют, что их работа сохранена, даже если система не сможет её вернуть.
Требуется также честный взгляд на стоимость. Один вариант смещает расходы в ежемесячные операции. Другой — в боль простоя. Тёплые реплики дороже каждый месяц, потому что вы держите резервную мощность готовой. Восстановление из бэкапа дешевле в обслуживании, но команда платит позже часами работы, поддержкой, потерянными продажами и восстановлением данных.
Для многих небольших команд правило простое: если час простоя дорого обходится, данные сложно восстановить, и восстановление зависит от уставшего человека, выбирайте тёплую реплику. Если сервис внутренний, нагрузка не критична и недавние изменения можно потерять, восстановление из бэкапа обычно хватает.
Как выбрать дефолт за пять шагов
Большинство команд застревают, потому что начинают с технологий. Начните с ущерба. Восстановление — это сначала бизнес‑решение, потом техническое.
-
Назначьте цену одного часа простоя. Посчитайте потерянные продажи, нагрузку поддержки, отложенную работу и время команды на уборку после восстановления. Если один плохой час стоит больше месяца дополнительной инфраструктуры — тёплая реплика часто оправдана.
-
Решите, сколько недавних данных вы готовы потерять. Будьте конкретны. Пять минут? Час? Целый день? Если потеря последних заказов, тикетов или обновлений клиентов нанесёт реальный вред — восстановление из бэкапа рискованный дефолт.
-
Посмотрите, кто будет выполнять восстановление, когда люди уставшие. План, который зависит от лучшего инженера, проснувшегося в 2 утра и сделавшего всё без ошибок — слабее, чем кажется. Команды с ограниченным покрытием должны предпочитать вариант с меньшим количеством ручных шагов.
-
Выберите самое простое решение, которое укладывается в ваши лимиты. Если бизнес выдержит несколько часов простоя и некоторую потерю данных — бэкапы подойдут. Если нужно быстрое переключение и плотная защита данных — платите за реплику.
-
Запишите один дефолтный путь. В инциденте споры отнимают минуты. Укажите, кто решает, что срабатывает первым, и когда команда переключается на резервный план. Короткий runbook лучше красивой диаграммы, которую никто не читает.
Одно грубое правило работает для маленьких и средних команд: если простой дорого стоит, данные трудно восстановить, и восстановление зависит от сонного человека — выбирайте тёплую реплику. Если сервис внутренний, нагрузка нерегулярна, и недавние изменения можно легко воспроизвести, хватит восстановления из бэкапа.
Простой пример из работы растущей продуктовой команды
Представьте небольшую SaaS‑команду из 12 человек, несколько тысяч платящих пользователей и клиентов в США, Европе и Азии. Их приложение поддерживает ежедневную работу, поэтому кто‑то всегда онлайн. Если база упадёт в 2 ночи для основателей, для части клиентской базы это всё ещё рабочий день.
Для этой команды выбор перестаёт быть теорией. Он меняет время ожидания клиентов, объём потерянных данных и ежемесячные расходы компании.
Если команда выпускает обновления ежедневно и активность никогда не останавливается, даже 15–20 минут простоя могут вызвать цепную реакцию. Саппорт завален. Клиенты пытаются повторять операции. Команда в панике объясняет, что случилось. В таком случае тёплая реплика — более безопасный дефолт. Ежемесячный счёт выше, но короткое восстановление защищает выручку и снижает последующую уборку.
Теперь представьте другую команду. Они поддерживают нишевый внутренний инструмент для небольшой группы клиентов. Трафик слабый. Большинство записей меняются в рабочие часы, а в некоторые дни база почти не двигается. Если сбой случится ночью, никто не заметит до утра.
Та команда может жить с восстановлением из бэкапа. Восстановление занимает дольше, потому что кому‑то нужно выбрать правильный снимок, откатить его, проверить приложение и снова открыть доступ. Они могут потерять самые свежие изменения, но это приемлемо, потому что обновления редки и их можно восстановить по почте или таблицам.
Первая команда выбирает тёплую реплику, потому что даже короткий простой вредит выручке и доверию. Вторая команда выбирает восстановление из бэкапа, потому что более низкая операционная стоимость важнее быстрого восстановления, и бизнес может выдержать задержку.
Ошибки, которые превращают восстановление в хаос
Команды часто тратят деньги на восстановление и всё равно застывают, когда что‑то ломается. Проблема обычно не в плане на бумаге, а в разрыве между тем, что купили, и тем, что действительно отработано.
Тёплая реплика выглядит безопасной, пока кто‑то не попробует реально переключить трафик. Многие платят за резервные системы, но никогда не тестируют изменение DNS, connection strings, режимы чтения/записи или порядок старта сервисов. При инциденте эти мелочи превращаются в длительные задержки.
Бэкапы ломаются иначе. Говорят: «Мы всегда можем восстановиться», но никто не запускал полноценный откат в чистом окружении. Восстановление базы — это только часть задачи. Приложению всё ещё нужны compute, конфигурация, сетевой доступ и способ проверить пригодность данных.
Отсутствующие элементы часто находятся вне основной базы: фоновые очереди, файловое хранилище, секреты, переменные окружения, внешние вебхуки, API‑ключи, планировщики и внутренние воркеры. Если хотя бы один из них не синхронизирован, приложение может вернуться в сломанном виде. Пользователи войдут, но загрузки не пройдут. Заказы появятся, но письма не уйдут. Такое «полувосстановление» тратит время, потому что команда думает, что система вернулась, когда это не так.
Ещё слабое место — принятие решений. Когда production упал, кто решает переключаться? Если ответ «мы разберёмся», люди ждут, спорят или спрашивают разрешения у того, кто спит или в полёте. Хороший runbook назначает одного владельца и запасного владельца.
И, наконец, стоимость вводит в заблуждение. Дешёвая схема кажется дешёвой до первой серьёзной аварии. Один длинный откат может съесть часы инженерного времени, поддержку, потерянные продажи и доверие клиентов. С другой стороны, нетестированная тёплая реплика — это просто ежемесячный счёт с ложным чувством безопасности.
Поэтому практические тренировки важнее красивых диаграмм. Oleg Sotnikov часто это подчёркивает в своей работе как Fractional CTO — и он прав. Вариант восстановления работает только после того, как команда отпробовала его по времени, задокументировала и повторила под давлением.
Быстрая проверка перед тем, как принять решение
Многие команды недели спорят о инструментах, а потом пропускают простые вопросы, которые реально решают, сработает ли восстановление. Прежде чем выбирать между тёплой репликой и восстановлением из бэкапа, запишите, как выглядит успех, когда production недоступен и клиенты ждут.
Начните с трёх простых утверждений. Первое — определите время восстановления простым языком: «нам нужно вернуть приложение в течение 30 минут». Второе — определите приемлемую потерю данных также ясно: «мы можем потерять до 5 минут заказов» или «мы не можем потерять платёжные транзакции». Третье — перечислите системы, которые должны подняться в первую очередь. Большинству команд не нужны все сервисы одновременно. Сначала обычно нужны база данных, аутентификация, платежи и клиентская часть, затем аналитика, внутренние дашборды и низкоприоритетные воркеры.
Потом проведите одну тренировку с теми, кто будет реально работать в аварии, и засеките время каждого шага. Измерьте время обнаружения проблемы, утверждения плана, переключения трафика, восстановления данных, проверки логина и выполнения одного реального пользовательского сценария.
Здесь бумажные планы часто проваливаются. Откат, который выглядит как 45‑минутная задача, может превратиться в два часа, если кому‑то придётся искать последний чистый снапшот, восстанавливать креды или вручную править DNS и конфиг.
После этого сравните месячный счёт с ценой одного простоя. Тёплая реплика дороже каждый месяц, но некоторые команды окупают эти расходы уже при первом избежанном длительном простоe. Восстановление из бэкапа дешевле в обслуживании, но его стоимость проявляется позже, если простой блокирует продажи, поддержку или операции.
Если хотите ясный дефолт, выберите вариант, который соответствует вашим целям по времени восстановления и потере данных в реальной тренировке, а не в таблице.
Что делать дальше
Если команда всё ещё не может решиться, не спасайте ситуацию толстым политическим документом. Выберите один письменный дефолт, который соответствует бюджету и реальному риску. Многие команды лучше начинают с протестированного восстановления из бэкапа, а затем добавляют тёплую реплику только для тех систем, отказ которых реально вредит выручке или нагрузке поддержки.
Опишите дефолт простым языком. Назовите сервис, цель восстановления, человека, который решает переключаться, и человека, который выполняет шаги. Если никто не владеет этими решениями, восстановление быстро замедляется.
Короткий чек‑лист достаточно:
- Установите один дефолтный подход для каждой системы.
- Запланируйте тренировку восстановления на этот месяц.
- Измерьте самый медленный шаг и исправьте его первым.
- Добавляйте тёплую реплику только там, где простой стоит дороже ежемесячного счёта.
Тренировка важнее диаграммы. Одна реальная проверка быстро показывает слабое место. Может оказаться, что откат занимает слишком много времени из‑за отсутствующих креденциалов. Может DNS‑изменения зависят от одного инженера. Может снапшот нормальный, но конфигурация приложения — нет. Исправьте первую узкую горлышко и повторите тренировку.
Держите тёплую реплику небольшой сначала. Не нужно сразу дублировать всё. Защитите базу данных, очередь или сервис, который создаёт наибольшие убытки при простое. Оставьте менее критичные внутренние инструменты на восстановлении из бэкапа, если задержка допустима.
Если хотите внешнюю проверку, oleg.is может быть полезной отправной точкой. Oleg Sotnikov консультирует стартапы и небольшие компании как Fractional CTO по дизайну восстановления, контролю расходов, инфраструктуре и практической AI‑ориентированной эксплуатации. Такой обзор особенно полезен, когда у вас уже есть черновой план и нужен конкретный совет, куда вложиться дальше.
Назначьте владельца, забронируйте тренировку и протестируйте план прежде, чем он пригодится.


