Теневые развертывания: как безопасно тестировать рискованные изменения бэкенда
Теневые развертывания позволяют отправлять реальный трафик в тихую копию сервиса, сравнивать результаты и обнаруживать несоответствия бэкенда до того, как пользователи почувствуют проблемы.
Содержание
Почему рискованные изменения бэкенда ломаются в продакшене
Рискованные изменения бэкенда обычно терпят неудачу по скучным причинам. Код работает на чистых тестовых данных, а в продакшене приходят странные форматы дат, частично заполненные поля, дубли записей, устаревшие кэши и запросы в неожиданном порядке.
Эта разница становится опасной, когда изменение касается логики, которой люди привыкли доверять без раздумий. Новая версия может по‑другому округлять цены, сортировать результаты или отфильтровывать записи, которые старый код оставлял. Каждое отличие само по себе выглядит мелким. В продакшене мелочи быстро накапливаются.
Реальный трафик «грязнее», чем тестовые наборы. У одного клиента старый аккаунт десятилетней давности. У другого мобильный запрос с пропущенной метаинформацией. Фоновая задача повторно обрабатывает одно и то же событие. Если новый код по‑другому обрабатывает хоть один из этих случаев, вы получите несоответствие, которое на стейджинге не видно.
Урон редко остаётся в одном месте. Неправильный результат бэкенда может отобразиться на экране клиента, попасть в счёт, запустить неправильное письмо, прокормить синхронизационную задачу и в итоге оказаться в финансовом отчёте.
Вот почему рискованные изменения кажутся безопасными вплоть до релиза. Проблема не всегда в падении. Тихие ошибки хуже. Страницы всё ещё загружаются, но итоги, статусы, права или рекомендации слегка неверны.
Команды также недооценивают, сколько скрытого поведения накопилось вокруг старого кода. Другая служба может ожидать поля в определённом порядке. Клиентское приложение может полагаться на запасной вариант, который никто не документировал. Пакетная задача может продолжать работать только потому, что старый эндпоинт возвращает пустой массив вместо ошибки.
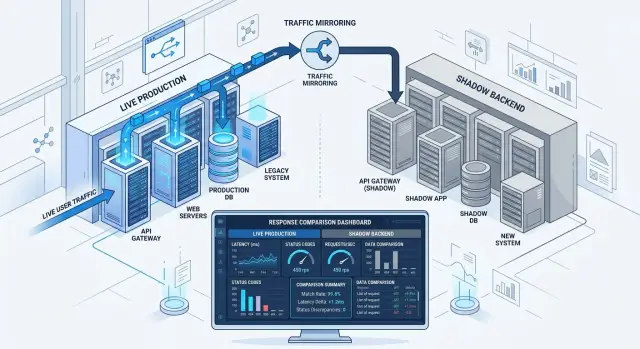
Теневые развертывания помогают, потому что выявляют эти пробелы до того, как пользователи их заметят. Вы отправляете реальный продакшен‑трафик в тихую копию новой версии, сравниваете выводы и ловите странные случаи, которые не попали в тесты. Так рискованный релиз превращается из догадки в измеряемое событие.
Что делает теневое развертывание
Теневое развертывание даёт новой версии возможность обработать реальные продакшен‑запросы, не подвергая пользователей риску. Живая система по‑прежнему отвечает на каждый запрос, а тихая копия получает дубликат запроса.
Пользователи продолжают видеть старый сервис. Если новая версия падает, тормозит или возвращает странные данные, никто вне команды этого не увидит.
Это и отличает теневые развертывания от staged rollout. Вы пока не отправляете часть пользователей на новый код. Вы зеркалируете продакшен‑трафик, чтобы новый путь увидел те же входные данные, что и текущий.
Идея простая. Запрос приходит, слой маршрутизации дублирует его, и обе службы обрабатывают копию. Назад клиенту возвращается только один ответ — от текущего стабильного сервиса.
Теневая копия нужна для измерений. Команды обычно сравнивают коды статуса, время ответа, различия в полезной нагрузке, сообщения об ошибках и частоту таймаутов. Если старый сервис вернул 200, а тень — 500, несоответствие очевидно. Если оба вернули 200, но один отвечает за 80 мс, а другой — за 2 секунды, это тоже важно.
Риск — в побочных эффектах. Теневая служба не должна отправлять письма, списывать карты, создавать дубли записей или запускать downstream‑джобы. Если она может писать в базу или вызывать сторонние системы, тест перестаёт быть безопасным.
Большинство команд блокируют такие действия через доступ только для чтения, фиктивные провайдеры, отключённые воркеры или строгие проверки в коде. Теневая служба может читать, посчитать ответ и залогировать результат. Она не должна менять мир.
При корректной настройке вы получаете обнаружение несоответствий в продакшене до реального релиза. У вас есть живые данные, и пользователи не платят за ваш тест.
Когда это имеет смысл
Используйте теневые развертывания, когда код может вернуть неверный ответ, даже если не падает. Это лучший кейс: изменения, проходящие тесты, но ведущее себя иначе на реальном трафике, с реальными данными или при неудобном тайминге.
Типичный пример — полный перепис. Новая служба может соблюдать тот же контракт, но мелкие различия в парсинге, округлении, кэшировании или значениях по умолчанию меняют результат. Аналогично — изменения в запросах к базе: то, что в стейджинге кажется быстрее, в продакшене может не покрыть краевые случаи из‑за более грязных данных.
Новая логика маршрутизации — ещё одна хорошая причина. Если запросы теперь идут в другую службу, регион или набор правил, хочется проверить, принимает ли новый путь те же решения, прежде чем пользователи начнут на него полагаться.
Это лучше всего работает на путях, которые в основном читают данные и возвращают ответ. Проверки цен, результаты поиска, рекомендательные ленты, правила допуска и сводки по аккаунту — хорошие кандидаты, потому что их выходы легко сравнить.
Будьте осторожнее, когда новый путь меняет данные. Если теневая копия может списать с карты, отправить письмо, зарезервировать инвентарь или записать дубли, вы можете нанести реальный ущерб во время «теста». Иногда можно заглушить побочные эффекты или отправить их в «сток». Если блокировать чисто нельзя — откажитесь от подхода.
Сравнение также требует чётких правил. Если вы не можете определить, что считается совпадением, теневая прогонка превратится в шум. Рекомендательная система подойдёт, если вы сравниваете диапазоны баллов, категории или последующие клики; хуже — если каждое отличие станет поводом для спора.
Начинайте там, где запросов много, ответы легко сравнивать, а ошибки дешевы. Так вы получите полезные несоответствия без превращения продакшена в эксперимент.
Как настроить — пошагово
Начните с одного эндпоинта, не со всего сервиса. Выберите запрос, у которого вход и выход легко захватить и сравнить. Цены на заказ, налоги, ранжирование поиска или скоринг мошенничества обычно лучше старта, чем рабочий процесс, затрагивающий пять систем одновременно.
Самое безопасное первое действие — маленькая выборка реального трафика. Отправьте 1–5% живых запросов в обе версии, но возвращайте пользователю только ответ текущего продакшена. Новая версия тихо работает в фоне, вы смотрите на её поведение, не меняя UX.
Простая настройка обычно выглядит так:
- Выберите эндпоинт с понятным запросом и ответом.
- Зеркальте небольшой срез продакшен‑трафика в новую службу.
- Добавьте один и тот же request ID обеим копиям и те флаги, что влияют на бизнес‑логику.
- Сохраните оба вывода в одинаковом формате и сравните поле в поле.
- Логируйте точные несоответствия, а не расплывчатые "response differs."
Последний пункт важнее, чем кажется. «total=49.90 vs 51.40, tax_rate=8% vs 11%» даёт команде конкретику для исправления. «Responses differ» просто тратит время.
Просматривайте логи несоответствий и ошибки каждый день. Ищите паттерны, а не просто счётчики. Десять несоответствий из‑за одного неверного кода страны могут быть менее критичными, чем одно несоответствие, которое изменяет сумму платежа.
Повышайте долю трафика только после того, как поймёте, что увидели. Идите от 1% к 5%, затем 10% и дальше. Если новая версия молчит, кроме понятных мелких отличий, доверие растёт. Если логи всё ещё шумят — держите развёртывание маленьким и исправьте причину.
Команды с хорошими логами и метриками делают это гораздо проще. Вот почему опытные CTO часто настаивают на наблюдаемости перед рискованными изменениями бэкенда.
Что сравнить, прежде чем довериться новой версии
Начните с кода статуса. Если старый сервис возвращает 200, а тень — 500, проблема уже есть. 404 вместо 200 важнее мелких различий в полезной нагрузке, так что сортируйте несоответствия по кодам статуса в первую очередь.
Далее сравнивайте те части ответа, что влияют на решения. Сырой размер JSON почти ничего не говорит. Два ответа одинаковой длины могут списать разные суммы, пропустить флаг доступа или выбрать другой склад.
Сосредоточьтесь на полях, от которых зависят люди и системы: итоги, идентификаторы, валюта, скидки, состояние запасов, роль пользователя, результат проверки на мошенничество или пометка товара как доступного. Если старый сервис говорит "approved": true, а новый — false, это логическая ошибка, даже если всё остальное совпадает.
Некоторые отличия — просто шум. Порядок полей в JSON, лишний пробел, новый trace ID или округлённая до секунд метка обычно не меняют поведения. Кластеризуйте их в безвредную корзину. Серьёзную корзину держите строгой: неверный статус, неверное значение, отсутствующее поле, изменённый побочный эффект или другой downstream‑вызов.
Скорость тоже важна. Новая служба может возвращать тот же ответ, но быть небезопасной из‑за задержек. Отслеживайте латентность, повторные попытки и таймауты. Если тень даёт тот же результат, но за 1.8 секунды вместо 200 мс, пользователи это почувствуют при реальном релизе.
Повторы заслуживают отдельного внимания. Они часто выявляют нестабильные запросы к БД или сетевые вызовы, которые проявляются только под нагрузкой. Таймауты ещё более критичны: таймаут в теневом пути легко игнорировать до тех пор, пока он не станет таймаутом, который видят пользователи.
Короткая шкала для проверки держит обзор честным:
- процент совпадений по коду статуса
- процент совпадений по бизнес‑полям
- процент таймаутов и повторов
- разрыв по латентности между старой и новой
- повторяющиеся причины несоответствий
Не судите релиз по одному странному запросу. Считайте, как часто происходят несоответствия, а затем группируйте их по эндпоинту, сегменту клиентов или типу запроса. Повторяющиеся паттерны важнее изолированных примеров.
Простой пример с итогами заказа
Магазин решает переписать сервис подсчёта итогов заказа за две недели до праздничной распродажи. Старый сервис отработан годами, но код грязный и трудно поддерживаемый. Новая версия чище, быстрее и легче тестируется. Звучит хорошо, пока реальные корзины не начнут попадать в неё.
Команда оставляет старый сервис живым. Клиенты по‑прежнему видят итоги от текущей системы на чекауте, в чекe и в платёжных запросах. Параллельно команда отправляет те же данные корзины в новую службу в фоне. Второй результат скрыт.
Обе версии получают те же товары, скидки, адрес доставки и купоны. Один результат идёт клиенту, другой — в лог для сравнения.
Через день зеркалирования появляется паттерн. Большинство корзин совпадает, но небольшая группа — нет. Плохие случаи сконцентрированы в регионах с локальными налоговыми правилами. Корзина с тремя дешевыми товарами отличается на один цент. Корзина с освобождёнными от налога товарами и скидкой на доставку отличается гораздо сильнее.
Проблема не случайна. Старый сервис округлял налог после группировки товаров по налоговому классу. Новая версия округляла каждую строку, а затем суммировала корзину. В некоторых регионах оба метода проходят базовые тесты, но только один совпадает с правилами, которые бизнес уже использует в продакшене.
Команда находит вторую проблему: новая служба применяет купон до налогообложения в одном регионе, где текущие правила требуют сначала посчитать налог. Никто не замечает, потому что живой путь всё ещё использует старую логику.
Команда исправляет правила, воспроизводит несоответствующие корзины и сравнивает снова. Количество несоответствий в выбранной выборке падает до нуля. Только тогда они рассматривают отправку небольшой доли реального чекаута на новую версию.
Это практическая ценность зеркалирования трафика. Вы ловите досадные, дорогие краевые случаи до того, как праздничный пик превратит тихую математическую ошибку в тысячи неверных итогов.
Ошибки, которые скрывают реальные проблемы
Теневой тест может выглядеть чисто и при этом вводить в заблуждение. Обычно новый путь не работает в тех же условиях, что и живой, поэтому сравнение с самого начала может быть неверным.
Самая частая ошибка — позволять тени трогать внешние системы. Если она может списать с карты, отправить письмо, записать в вебхук или вызвать API партнёра, тест перестаёт быть тихим. Команды стараются использовать тестовые аккаунты, но это всё равно меняет поведение. Тень должна обработать запрос и остановиться перед любым побочным эффектом.
Конфигурационный дрейф даёт ещё одно ложное прохождение. Если живой сервис использует один набор feature‑флагов, налоговые правила, настройки кэша или таймауты, а тень — другой, несоответствия теряют смысл. Вы сравниваете не старый и новый код, а два разных продукта.
Многие команды смотрят только на тело ответа и пропускают медленные отказы. Запрос, который возвращает правильный JSON за 4 секунды, всё ещё проблема, если в продакшене обычно 200 мс. Следите за таймингами, повторными попытками, ростом очередей, нагрузкой на БД и всплесками ошибок, которые появляются минутой позже. Некоторые баги прячутся в хвосте распределения, а не в проценте успешных ответов.
Аппаратное окружение тоже может ввести в заблуждение. Если теневая копия работает на меньших машинах, с холодными кэшами или с более шумной репликой БД, люди обвинят код, хотя проблема в ёмкости. И наоборот: если тень получает больше CPU и памяти, ей может «везти» до дня развёртывания.
Время запуска важно. Тихий час почти ничего не доказывает. Низкий трафик пропускает уродливые входные данные, резкие всплески, отток кэшей и запланированные задания. Если система нагружена в обед, при ночных импортерах или после платёжных ведомостей, тень должна покрыть эти периоды.
Теневые развертывания работают лучше всего, когда настройка одинаковая с обеих сторон: те же входы, та же конфигурация, та же нагрузка, никаких внешних побочных эффектов и достаточно времени для охвата реальных паттернов трафика. Если результаты выглядят слишком идеальными, перепроверьте тест, прежде чем доверять коду.
Быстрая проверка перед полномасштабным rollout
Чистая теневая прогонка всё ещё может ввести в заблуждение, если сравниваемые запросы не одинаковы. Перед отправкой реального трафика на новую версию держите проверки простыми, видимыми и строгими.
Начните с входных данных. Зеркалируемый и живой запросы должны иметь одинаковое тело, заголовки, параметры, контекст авторизации и предположения о времени. Если один путь получает кэшированное значение, а другой вычисляет из свежих данных, процент совпадений теряет смысл.
Короткий чек‑лист перед релизом:
- Подтвердите, что оба пути получают одни и те же входные данные, включая значения по умолчанию, добавляемые шлюзами или middleware.
- Держите тень только для чтения: она не должна списывать с карт, отправлять письма, записывать строки или вызывать внешние сервисы с реальными эффектами.
- Группируйте частые несоответствия в понятные корзины, которые команда может объяснить простым языком.
- Разместите процент несоответствий, латентность и число ошибок на одном дашборде.
- Заранее пропишите триггер отката с точным порогом и ответственным лицом.
Корзины несоответствий важнее, чем многие думают. Малый процент допустим, если вы можете объяснить его причину: например, форматирование временной метки или известное правило округления. Даже меньший процент — плох, если никто не понимает, почему итоги заказа отличаются, почему одна версия теряет необязательные поля или почему большие полезные нагрузки падают.
Дашборд должен давать одну картину: если растёт латентность, но несоответствия остаются плоскими, новая логика всё равно может навредить пользователям. Если ошибки низкие, но на одном эндпоинте растут несоответствия, возможно логическая ошибка, которую логи не ловят.
Правила отката должны быть скучными и конкретными. Например, откатывать, если несоответствия держатся выше 0.5% в течение 10 минут, если p95 латентности поднимается выше 20%, или если любой побочный эффект проскальзывает через теневой путь. Команды спорят меньше, когда правило уже прописано.
Что делать после чистой тенью
Чистая теневая прогонка — хороший знак, но это не финал. Зеркалирование показывает, что новая версия ведёт себя как старая под реальной нагрузкой. Оно не снимает весь риск, когда реальные пользователи начнут получать новые ответы.
Начните с небольшой доли живого трафика. Для большинства команд 1–5% достаточно, чтобы поймать сюрпризы без большого числа затронутых пользователей. Держите старую версию по‑умолчанию, пока новая не станет скучной под живым трафиком.
Не отключайте сравнения. Оставьте те же проверки для этой первой живой доли и наблюдайте несколько часов или полный рабочий цикл, если трафик меняется в течение дня. Версия может выглядеть хорошо в теневой режиме и провалиться, когда кэши прогреются иначе, накопятся повторы или появятся отличия в write‑пути.
На этой стадии следите за четырьмя вещами:
- коды статусов и различия в ответах
- латентность, таймауты и повторы
- записи в базу и downstream‑вызовы
- логи краевых случаев, которые триггерят только живые пользователи
Запишите, что произошло, пока воспоминания свежи: что совпало, что упало, что вы поменяли и почему решили расширять развёртывание. Эта запись сэкономит время позже, особенно если похожая ошибка появится через полгода.
Со временем запись станет плейбуком. Следующий рискованный бэкенд‑чейндж сможет переиспользовать те же правила зеркалирования, точки сравнения и условия остановки, если система существенно не изменилась.
Если план развёртывания всё ещё кажется шатким — полезно мнение со стороны. Oleg Sotnikov at oleg.is консультирует стартапы и небольшие команды по архитектуре, инфраструктуре и работе в роли Fractional CTO, и такой обзор релиза — именно то место, где опытный взгляд может заметить слабые места заранее.
Если маленькая доля живого трафика остаётся чистой — увеличивайте трафик по этапам. Медленно — значит быстрее, чем один большой откат.
Часто задаваемые вопросы
What is a shadow deployment?
Теневое развертывание отправляет реальные запросы из продакшена в копию нового бэкенда, но пользователи по-прежнему получают ответ от текущего стабильного сервиса. Это позволяет команде сравнивать результаты, скорость и ошибки, не подвергая клиентов риску плохого релиза.
When does a shadow deployment make sense?
Используйте его, когда ошибка в логике опаснее, чем явный краш. Подходит для переписок, логики подсчёта цен, поиска, изменений маршрутизации и другой серверной работы, где мелкие различия в поведении могут навредить пользователям, даже если интерфейс продолжает загружаться.
How is this different from a canary release?
Канарея направляет часть реальных пользователей на новую версию и даёт им почувствовать проблемы. Теневой режим этого не делает: новая служба видит тот же трафик, но ответы по-прежнему отдаёт старый сервис.
What should I compare between the old and new service?
Начните со статусов ответа, затем бизнес-поля, задержек, ре-траев и таймаутов. Сравнивайте значения, которые влияют на решения: итоги, скидки, состояние запасов, флаги прав доступа или результаты утверждений, а не только размер JSON.
How much traffic should I mirror first?
Большинство команд начинают с малого — обычно 1–5% трафика. Это даёт реальные примеры без перегрузки логов и без излишней нагрузки на новую службу, пока вы исправляете очевидные расхождения.
Can I use shadow deployments on endpoints that write data?
Да, но только если вы заблокируете все побочные эффекты. Теневой путь не должен снимать деньги с карт, отправлять письма, записывать строки или вызывать внешние системы. Если это невозможно сделать надёжно, выберите другой метод тестирования.
How do I keep the shadow copy from causing real damage?
Держите теневую службу только для чтения, отключите воркеры и замените реальные провайдеры фиктивными или «синковыми». Также защитите рискованные участки кода, чтобы сервис мог посчитать ответ и залогировать его, не изменяя ничего вне себя.
What counts as a real mismatch versus harmless noise?
Шумом можно считать порядок полей в JSON, trace ID, пробелы или мелкие отличия формата времени, если они не влияют на поведение. Настоящие ошибки — неверные итоги, отсутствующие поля, изменения статусов, медленные ответы или другие изменённые вызовы вниз по цепочке.
How long should I run a shadow deployment?
Запускайте достаточно долго, чтобы покрыть нормальные паттерны трафика, а не только тихий час. Включите периоды пиковой нагрузки, смену кэшей, периодические задания и неудобные входные данные — именно там обычно всплывают скрытые баги.
What should I do after a clean shadow run?
Не переходите сразу на 100%. Отправьте небольшой процент реального трафика на новую версию, продолжайте те же сравнения и внимательно следите за задержкой, ошибками и записями в базе. Если версия остаётся «скучной» при живых пользователях, постепенно увеличивайте трафик.


