Temporal, Inngest и обычные очереди для продуктовых workflow
Temporal, Inngest и обычные очереди решают разные задачи workflow. Сравните повторы, прозрачность и ответственность команды, прежде чем принимать решение.
Содержание
Почему этот выбор быстро превращается в хаос
Большинство команд не начинают с оркестрации рабочих процессов как с чистой задачи проектирования. Сначала у них есть несколько background jobs, отложенное письмо, обработчик webhook и одно действие в продукте, которое срабатывает после клика пользователя. Через месяц эти части начинают зависеть друг от друга, и никто уже не может объяснить весь путь, не открыв несколько панелей и не перечитав старый код.
Именно поэтому выбор между Temporal, Inngest и обычными очередями так быстро запутывается. На бумаге все три инструмента уводят работу из request path. На практике они решают, кто видит сбои, кто запускает повторы и кого винят, когда клиент получает два письма, пропускает шаг онбординга или списание происходит дважды.
Повторы звучат как техническая деталь, но сначала их чувствуют клиенты. Если задача отправляет приветственное письмо дважды, с опозданием обновляет доставку или запускает шаг биллинга уже после отмены подписки, проблема перестаёт быть абстрактной. Политика повторов — это продуктовое решение, спрятанное внутри технической настройки.
Ответственность только усложняет ситуацию. Когда работа падает, кому-то всё равно нужно ответить на четыре простых вопроса: кто замечает проблему первым, кто безопасно перезапускает процесс, кто решает, повторять шаг или остановиться, и кто объясняет ситуацию support или клиенту.
Названия инструментов могут скрывать эту операционную работу. Очередь выглядит простой, пока команде не понадобятся задержки, защита от дублей, история аудита и ручной повторный запуск. Инструмент для событий кажется дружелюбным, пока люди не начинают думать, что он бесплатно закрывает все крайние случаи. Workflow engine выглядит безопасным, пока команда не понимает, что теперь она владеет более глубокой системой со строже заданными правилами.
Именно здесь застревают маленькие продуктовые команды. Они выбирают не библиотеку. Они решают, насколько заметными будут сбои, сколько логики останется в коде, а сколько уйдёт в инструмент, и сколько ежедневного ухода потребует система. Такое решение становится дорогим задолго до того, как трафик становится большим.
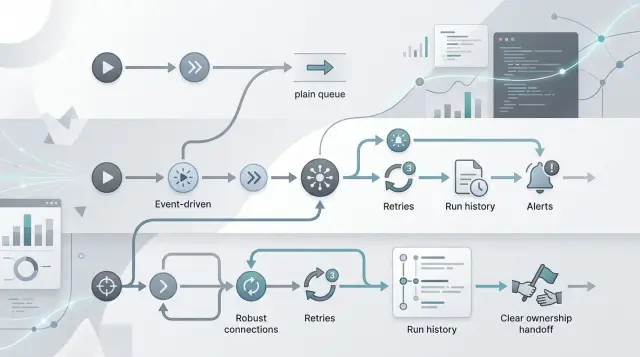
Что хорошо умеют обычные очереди
Обычные очереди лучше всего работают тогда, когда каждая задача небольшая, понятная и независимая. Worker берёт одну задачу, делает работу, помечает её как выполненную и идёт дальше. Такой подход сложно превзойти, когда задача занимает секунды, а не часы, и когда один сбой не ставит под угрозу весь продуктовый поток.
Именно поэтому очереди до сих пор подходят для многих повседневных продуктовых задач. Они делают workers небольшими, дешёвыми в запуске и понятными. Если команда уже понимает, как ведёт себя приложение, она часто может добавить очередь почти ничего больше не меняя.
Они хорошо подходят для задач вроде отправки приветственного письма, изменения размера загруженного изображения, повторной попытки webhook или генерации PDF после оплаты. Обычно у таких задач есть один понятный вход и один ожидаемый результат. Для этого не нужен большой orchestration layer. Нужен worker, который может подхватить задачу, записать, что произошло, и попробовать ещё раз, если возникла временная ошибка.
С обычными очередями сложные части остаются на стороне приложения. Это включает правила повторов, защиту от дублей и решение о том, когда задачу безопасно запускать снова. Если email-провайдер не отвечает вовремя, ваш код решает, сколько раз повторять попытку и как долго ждать. Если одна и та же задача по картинке попала в очередь дважды, приложению нужна проверка idempotency, чтобы не обработать её повторно и не сохранить лишние файлы.
Часто это вполне нормально. Многие команды предпочитают такой подход, потому что правила остаются рядом с product code, а не живут в отдельном инструменте. Для стартапа такая скука обычно полезна.
Слабое место — прозрачность. Одна очередь может казаться аккуратной. Пять очередей, кастомные правила повторов и передача задач между сервисами очень быстро превращаются в догадки. Обычные очереди хорошо работают тогда, когда задачи короткие, путь прямой, а команда готова владеть логикой внутри приложения.
Где уместен Inngest
Inngest хорошо подходит тогда, когда workflow начинается с product events и одной команде нужно быстро выпускать изменения. Подумайте об онбординге после регистрации, напоминаниях о пробном периоде, follow-up после неудачной оплаты или email-цепочке после покупки. Вы пишете шаги в коде, добавляете задержки и настраиваете повторы без недель, потраченных на построение всей инфраструктуры вокруг этого.
Для маленьких команд это важный компромисс. Если инженерам приятнее улучшать онбординг, чем дежурить за workers, таймерами и таблицами очередей, Inngest — разумный середняк. Для команд, которые только начинают работать с оркестрацией, именно более лёгкая настройка часто и нужна.
Прозрачность — одна из главных причин, почему его выбирают. Запуски, ошибки на шагах и попытки повторов видны в одном месте, поэтому команда может ответить на вопрос «что случилось с этим пользователем?» без прыжков между логами, cron-задачами и панелями очередей. Для product-людей это не менее важно, чем для инженеров: они могут проследить сломанный поток до того, как он превратится в обращение в support.
Логика повторов тоже остаётся рядом с работой. Команда может сказать: «повтори этот API-запрос три раза», подождать десять минут и перейти к следующему шагу. Если нужен reminder через два дня, это тоже можно смоделировать напрямую. Обычные очереди умеют делать то же самое, но команды часто вынуждены собирать дополнительные workers, таймеры и таблицы статусов, чтобы добраться до такого результата.
Inngest лучше всего подходит, когда одним product team принадлежит весь workflow от начала до конца. Одна и та же группа определяет событие, пишет шаги, следит за сбоями и исправляет странные случаи. Небольшая SaaS-команда — хороший пример. Регистрация запускает письма онбординга, оценку аккаунта и сигнал в sales, если пользователь достигает порога активности. Одна команда может это построить, наблюдать за этим и менять уже на следующей неделе без помощи инфраструктурной команды.
Он подходит хуже, когда одним длинным процессом пользуются многие команды или когда правила исполнения требуют строгого контроля между сервисами. В таких случаях более тяжёлый инструмент может оправдать свою цену. Но для event-driven продуктовых потоков с понятной ответственностью Inngest часто даёт команде достаточно логики повторов и достаточно прозрачности без лишней операционной нагрузки.
Где уместен Temporal
Temporal имеет смысл тогда, когда workflow живёт долго, а сбои — это норма, а не редкость. Если процесс длится часы, дни или недели, простая очередь быстро начинает казаться хрупкой. Temporal хранит состояние workflow, знает, какой шаг уже завершён, и понимает, с какого места продолжить после перезапуска.
Это меняет способ построения продуктовых потоков. Можно моделировать реальный бизнес-процесс, а не склеивать таймеры, статусные флаги и скрипты очистки. Worker может остановиться посреди flow, вернуться позже и продолжить без потери прогресса.
Польза становится особенно заметной, когда в потоке много шагов в строгом порядке, когда он ждёт людей или внешние системы, когда для разных действий нужны разные правила повторов и когда команда готова владеть ещё одной частью инфраструктуры. Эти условия важнее любой страницы со сравнением функций.
Temporal особенно полезен для согласований, долгих ожиданий и дедлайнов. Представьте, что клиент подаёт заявку на финансирование. Приложение проверяет документы, ждёт ручную проверку, отправляет дело партнёру-банку, ждёт ответа до 72 часов и поднимает тревогу, если ответа нет. С обычными очередями это неудобно. Temporal справляется с этим чисто, потому что ожидание — часть workflow, а не заплатка поверх него.
У него сильная модель восстановления. Если worker падает после четвёртого шага, не нужно гадать, что произошло, или пересматривать логи, чтобы восстановить состояние. Temporal проигрывает историю workflow и продолжает с безопасной точки. Это может уберечь команду от двойных списаний, повторных писем и незавершённых изменений аккаунта.
Компромисс — ответственность. Temporal — не маленькая вспомогательная библиотека. Кому-то нужно понимать дизайн workflow, версии workers и повседневную эксплуатацию. Команды, которые уже воспринимают workflows как продуктовую логику, обычно принимают эту цену. Команды, которым нужны только несколько background jobs, обычно — нет.
Если сам workflow — часть продукта, Temporal часто оправдывает себя. Если это просто клей между несколькими задачами, он быстро начинает казаться тяжёлым.
Сопоставьте инструмент с повторами, прозрачностью и ответственностью
Большинство команд выбирают workflow tool по функциям. Но лучший фильтр — это ответственность. Если никто не отвечает за лимиты повторов, разбор сбоев и ночные исправления, даже самая удобная orchestration setup создаст путаницу.
С обычными очередями команда задаёт правила в коде. Сюда входит количество попыток, пауза между ними, момент, когда задача попадает в dead letter queue, и способы защитить себя от дублирования работы. Обычно это нормально, если те же инженеры, которые написали workers, смотрят логи и могут быстро исправить проблему.
Inngest хорошо работает, когда вам нужна более понятная история запусков и более простая прозрачность сбоев без полноценного workflow engine. Product manager или руководитель support часто могут увидеть, что именно сломалось, когда это произошло и повторялось ли это — всё в одном месте. Это логично для продуктовых потоков, где задержки раздражают, но редко бывают опасны.
Temporal требует более сильного владельца процесса, и это не минус. Он подходит для случаев, когда работа длится долго, зависит от нескольких шагов или должна каждый раз восстанавливаться в правильном порядке. Но кому-то всё равно нужно владеть версиями workflow, здоровьем workers и зависшими выполнениями. Если этим никто не хочет заниматься, Temporal покажется тяжелее, чем сама проблема.
Перед выбором задайте несколько прямых вопросов. Кто настраивает лимиты повторов и правила backoff? Где люди смотрят на упавшие runs? Кто чинит зависшую работу после окончания рабочего дня? Можно ли понять сбой без пяти разных инструментов?
На signup flow это особенно легко проверить. Если одно неудачное приветственное письмо — это небольшая проблема, хватит очереди или Inngest. Если signup ещё и создаёт billing records, поднимает аккаунты и синхронизирует данные с другими системами, Temporal может оказаться безопаснее.
Обычно выигрывает самый лёгкий инструмент, который соответствует реальной ответственности. Выбирайте тот, с которым команда сможет работать в 11 вечера, а не только тот, который красиво выглядит на схеме.
Реалистичный пример
Refund flow выглядит простым, пока одна заказанная операция не затрагивает три команды. Клиент просит вернуть деньги после двойного списания. Продукту нужно вернуть платёж, отправить подтверждение по email и оставить заметку для support, чтобы следующий оператор видел, что произошло.
Обычной очереди часто достаточно, когда каждый шаг завершается быстро и каждая задача может существовать сама по себе. Один worker обращается к payment provider. Другой отправляет письмо. Третий пишет заметку для support. Если письмо не отправилось, вы несколько раз повторяете именно эту задачу и двигаетесь дальше. Один инженер может владеть таким процессом без большого количества дополнительной логики.
Это меняется, когда команде нужна лучшая прозрачность. Support может спросить: «Возврат начался, сломался или завершился?» Product может захотеть follow-up через два дня, если payment provider всё ещё показывает статус pending. Inngest подходит для такого потока очень хорошо. У вас есть понятная история запусков, паузы по времени и более простой способ увидеть, что произошло по одному заказу, не копаясь в логах очереди.
Temporal становится более уместным, когда возврат должен ждать чего-то вне вашего приложения. Возможно, возвраты выше $500 требуют одобрения финансового отдела. Возможно, payment provider присылает webhook через несколько часов. Возможно, support может отменить возврат, пока он ещё ждёт. Тогда workflow нуждается в надёжном состоянии и в чистом способе ставить его на паузу, возобновлять, повторять и реагировать на события во времени.
Именно поэтому один и тот же refund flow может пройти через три стадии по мере роста продукта. Он может начаться с обычных очередей, когда работа короткая и всё в духе «отправил и забыл». Потом перейти на Inngest, когда команде понадобится история запусков и отложенные follow-up. А потом оказаться в Temporal, когда согласования, webhook и решения людей становятся нормой.
Ответ часто меняется, когда support нужен статус в реальном времени. Как только агентам приходится открывать заказ и видеть «refund pending approval» или «email failed, retrying», прозрачность перестаёт быть приятным дополнением. Она становится частью продукта.
Ошибки, которые команды совершают в самом начале
Команды, спорящие о workflow tools, часто сначала пропускают скучную часть: определите сбой до покупки orchestration. Если шаг однажды тайм-аутится, вы повторяете его через 30 секунд, просите человека вмешаться или останавливаете и помечаете как failed? Без таких правил более продвинутый инструмент просто даст вам красивую панель для путаницы.
Команды также прячут состояние workflow в случайных местах. Один флаг лежит в jobs table, другой — в логах приложения, третий — у payment provider, а остальное хранится в голове у кого-то из сотрудников. Потом никто не может ответить на простой вопрос вроде «Заказ уже отправлен или письмо просто не прошло?»
Повторы наносят самый дорогой ущерб. Команды часто повторяют каждую ошибку одинаково, даже если шаг уже изменил деньги или данные. Так происходит двойное списание, дублирование счетов и повторная отправка одного и того же обновления аккаунта.
Платёжные шаги, возвраты, запись в склад и письма клиентам требуют дополнительной осторожности. Такие действия нуждаются в idempotency, защите от дублей или точке ручной проверки до того, как система попробует снова. Пропустите эту работу — и логика повторов превратит небольшой сбой в проблему для клиента.
Многие команды не подключают support до первого разгневанного клиента. Когда пользователь спрашивает, что произошло, support должен видеть, когда задача началась, на каком шаге она сломалась, что попыталась сделать система и вмешивался ли человек. Если каждый зависший случай всё ещё требует инженера, читающего логи, процесс сломан.
С ответственностью тоже всё быстро усложняется. Product определяет поток, engineering владеет очередью, operations разбирает инциденты, а правила на случай ошибки никому не принадлежат. Один человек должен иметь последнее слово по тайм-аутам, логике повторов, ручному восстановлению и тому, когда workflow можно безопасно возобновить.
Этому владельцу не нужно строить всю систему. Ему нужно только принимать решения там, где сбой становится дорогим, видимым для клиента или и тем и другим.
Как выбрать без лишних размышлений
Выбор становится гораздо проще, когда вы перестаёте сравнивать продукты и рисуете на бумаге один реальный workflow. Возьмите один поток, например: «пользователь платит, аккаунт создаётся, человек проверяет настройку, и уходит приветственное сообщение». Запишите каждый шаг от триггера до финального результата.
Потом отметьте, как ведёт себя каждый шаг. Одни шаги должны завершаться за секунды. Другие ждут таймер, webhook или batch job. Третьи останавливаются, пока человек не одобрит следующий ход. Это разделение важнее списка функций.
После этого опишите историю сбоя простыми словами. Что происходит после одной ошибки? После трёх? После десяти? Если ответ остаётся простым, например «несколько раз повторить и потом предупредить человека», очереди может хватить. Если для разных шагов нужны разные правила повторов, и вы хотите более понятную историю, начинает подходить Inngest. Если workflow должен переживать долгие ожидания, изменения кода и строгие правила восстановления, Temporal обычно подходит лучше.
Ещё одна проверка быстро меняет решение: кому нужен статус кроме инженеров? Если только разработчикам, логов и панели очереди может быть достаточно. Если support, operations или founder должны уметь отвечать на вопрос «где это зависло?», прозрачность становится частью продукта, а не только частью backend.
Проверьте workflow под давлением, прежде чем выбрать инструмент. Запишите весь поток на одной странице. Попросите человека вне engineering прочитать статус запуска и объяснить, ожидает ли он, повторяется или уже упал. Возьмите один реальный сбой и проиграйте его от начала до конца. Поставьте жёсткий предел на стоимость повторов, чтобы баг не долбил внешний сервис всю ночь. Потом спросите, кто будет сопровождать это через год.
Если вы не можете сделать это за десять минут для простого потока, не добавляйте ещё больше orchestration. Сам процесс всё ещё слишком расплывчатый, и более крупная система только спрячет эту проблему.
Начните с одного пилота
Не переносите десять workflows сразу. Выберите один, который уже достаточно болит, чтобы его стоило чинить, но всё ещё достаточно мал, чтобы за ним можно было внимательно наблюдать. Refund flow, follow-up после регистрации или восстановление неудачной оплаты обычно лучше подходят для пилота, чем весь order pipeline.
Погоняйте этот пилот несколько недель и смотрите не только на сам workflow, но и на всё, что вокруг него. Полезные сигналы скучны, но честны: как часто поток останавливается или дублирует работу, сколько минут кто-то тратит на исправление упавшего run, как часто support нужен, чтобы объяснить статус, и кто на самом деле замечает проблему первым.
Если обычные очереди справляются с пилотом с понятной логикой повторов и достаточной прозрачностью, оставьте их. Если Inngest даёт лучшую историю запусков и более лёгкий повторный запуск без лишней нагрузки, возможно, это правильный следующий шаг. Если Temporal исправляет долго живущее состояние, передачу задач и восстановление, в которых команда постоянно ошибается, дополнительная настройка может быть оправданной.
Оставьте себе пространство для изменений позже. Держите бизнес-правила отдельно от orchestration layer и не разбрасывайте код, завязанный на конкретный инструмент, по всему продукту. Одно это решение заметно удешевляет будущие изменения.
Небольшой пилот расскажет больше, чем месяц архитектурных встреч. Вы увидите, кто владеет сбоями, насколько тяжело делать повторные запуски под давлением и помогает ли инструмент или просто добавляет ещё одну систему для присмотра.
Если перед выбором вам нужен второй взгляд, Oleg Sotnikov на oleg.is предлагает Fractional CTO advisory для стартапов и небольших команд, которым нужна помощь с product architecture, infrastructure или AI-first development. Разбор одного workflow часто уже показывает, в чём настоящая проблема: в инструменте, в модели повторов или в неясной ответственности.
Часто задаваемые вопросы
Как выбрать между обычными очередями, Inngest и Temporal?
Начните с одного реального процесса, а не с таблицы возможностей. Если в потоке короткие, независимые задачи, используйте обычные очереди. Если процесс запускается от product events и вам нужна история запусков с задержками и повторами в одном месте, выбирайте Inngest. Если процесс ждёт людей или внешние системы часами или днями и должен возобновляться точно с нужного места, выбирайте Temporal.
Когда обычной очереди достаточно?
Используйте обычную очередь, когда каждая задача делает одну понятную вещь и быстро завершается. Хорошие примеры — отправить одно письмо, уменьшить размер изображения, повторить webhook или создать PDF после оплаты.
Это хорошо работает, если ваша команда готова сама отвечать за повторы, защиту от дублей и логи в коде приложения.
Когда стоит использовать Inngest?
Выбирайте Inngest, когда процесс запускается от product events и одна команда хочет быстро выпускать изменения. Он хорошо подходит для онбординга, напоминаний, follow-up после неудачной оплаты и других последовательностей с задержками и повторами.
Он также помогает, когда support или product-людям нужно видеть, что произошло, без поиска по нескольким системам.
Когда имеет смысл Temporal?
Обращайтесь к Temporal, когда процесс работает долго и сбои происходят не как исключение, а как обычная часть жизни. Он подходит для согласований, долгих ожиданий, шагов, зависящих от webhook, и потоков, которые должны ставиться на паузу, возобновляться и восстанавливаться по порядку.
Он требует больше от команды, поэтому окупается только тогда, когда сам workflow действительно важен для продукта.
Какая самая большая ошибка с повторами?
Не повторяйте все ошибки одинаково. Если шаг уже затронул деньги, склад или данные клиента, слепой повтор может создать двойное списание, дублированный счёт или повторное письмо.
Для рискованных шагов добавьте idempotency или ручную проверку, прежде чем увеличивать число повторов.
Почему прозрачность workflow так важна?
Прозрачность становится не просто приятным бонусом, когда ответ нужен не только инженерам. Support должен понимать, ждёт ли run, повторяется ли он или уже упал, чтобы объяснить ситуацию без просьбы к инженеру читать логи.
Если людям приходится открывать пять инструментов, чтобы понять одну проблему клиента, система уже слишком сложна для эксплуатации.
Кто должен отвечать за сбои workflow?
Один человек или небольшая группа должны отвечать за лимиты повторов, разбор ошибок, ручные перезапуски и ночные исправления. Если product описывает поток, engineering владеет workers, а финальное решение по правилам сбоев никто не принимает, путаница появится очень быстро.
Чёткая ответственность важнее длинного списка функций.
Можно ли начать с очередей и потом перейти дальше?
Да, многим командам именно так и стоит делать. Начните просто, посмотрите, где повторы ломаются, и переходите дальше только тогда, когда потоку нужно больше состояния, тайминга или восстановления, чем могут дать очереди.
Держите бизнес-правила отдельно от orchestration layer, чтобы не привязывать весь продукт к одной системе.
Какой workflow выбрать для пилотного проекта?
Выбирайте один поток, который уже болит, но остаётся достаточно маленьким, чтобы за ним можно было наблюдать. Возвраты, follow-up после регистрации или восстановление неудачной оплаты обычно подходят хорошо, потому что они затрагивают реальных клиентов, но не тянут за собой весь продукт.
Запустите пилот на несколько недель и смотрите на stalls, дублирование работы, время на исправление неудачного run и на то, как часто support просит помощи.
Как понять, что текущего решения уже недостаточно?
Следите за несколькими типичными признаками. Люди не могут объяснить неудачный run без просмотра старого кода, повторы создают ошибки, которые видны клиенту, support просит engineering показать статус, или процесс зависит от таймеров, согласований и внешних событий.
Когда это начинается, вашей команде уже нужно больше, чем простая настройка background jobs.


