Tailscale SSH против bastion-хостов для доступа небольшой команды
Сравните Tailscale SSH и bastion-хосты: аудит, доступ подрядчиков, аварийный доступ и ежедневные решения для небольших команд.
Содержание
Проблема доступа простыми словами
Небольшие команды обычно начинают с запутанного набора привычек. Один основатель входит каждый день. Сотрудник трогает продакшен раз в неделю. Подрядчику нужны два часа в пятницу, а потом он пропадает на месяц. Если не разобраться с этим заранее, доступ превращается в груду исключений, в которой никто толком не ориентируется.
Начинайте с людей, а не с инструментов. Запишите каждого человека, которому может понадобиться доступ к серверу, даже если ответ — «редко». Включите основателей, технических лидов, штатных сотрудников, part-time-операторов, специалистов поддержки, подрядчиков и того, кто занимается аварийными ситуациями.
Частота важнее, чем многие команды ожидают. Для ежедневного доступа нужен удобный путь с меньшим числом ручных шагов. Для доступа раз в месяц можно сделать правила строже, потому что небольшая задержка никому не навредит. Временный доступ подрядчика должен быстро истекать, иначе он часто остаётся открытым задолго после окончания работ.
Обычная работа и аварийная работа не должны подчиняться одним и тем же правилам. Если человек выкатывает код, смотрит логи или перезапускает сервис в рамках обычной работы, дайте ему обычный путь. Если кому-то может понадобиться чинить сбой в 2 часа ночи, относитесь к этому как к аварийному доступу с более жёсткими контролями и понятной причиной использования. Смешивание этих случаев потом только путает.
Затем решите, что именно нужно фиксировать. Для большинства небольших команд достаточно базы: кто вошёл, когда вошёл, к какому серверу подключился и почему доступ был вообще нужен. Некоторым командам ещё нужен номер тикета, заметка о согласовании или история команд для чувствительных систем.
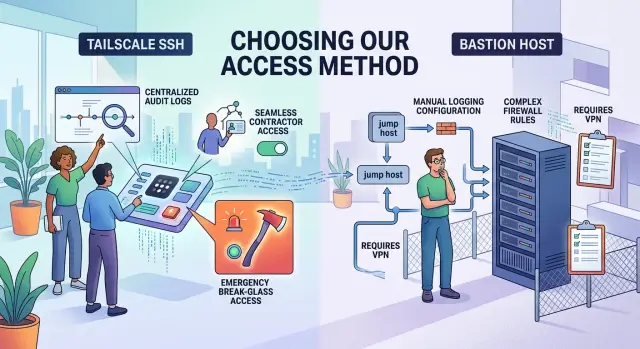
В этом и есть реальный выбор между Tailscale SSH и bastion-хостами. Дело не в том, какой инструмент кажется современнее. Важно то, как на самом деле работает ваша команда. У стартапа из трёх человек с одним доверенным инженером совершенно другая задача по доступу, чем у небольшой компании с подрядчиками, клиентскими данными и дежурствами по выходным.
Если вы можете назвать людей, частоту, аварийные случаи и записи, которые вам нужны, выбор инструмента становится намного проще.
Как работают два варианта
Tailscale SSH даёт людям прямой SSH-доступ к машине, но связывает этот доступ с реальной учётной записью пользователя, а не с общим сетевым путём. Разработчик входит через корпоративную систему идентификации, его устройство подключается к приватной сети, и целевой сервер решает, может ли именно этот человек подключиться. Главное отличие в том, что соединение может идти прямо на сервер без отдельного прыжкового узла посередине.
Bastion-хост работает как охраняемый вход. Ваши приватные машины не торчат в публичном интернете, и сначала люди подключаются к одному защищённому серверу. Уже оттуда они переходят на нужную внутреннюю машину. Это даёт команде одну точку, которую можно жёстко контролировать, мониторить и ограничивать, поэтому во многих старых схемах его всё ещё используют.
Логи тоже живут в разных местах. В Tailscale SSH данные об идентификации и доступе обычно лежат в админ-слое Tailscale и часто ещё в системе идентификации. Серверные SSH-логи по-прежнему важны, но логика допуска обычно начинается с учётных записей, статуса устройства и правил доступа. В bastion-хосте сам bastion часто становится основным контрольным пунктом для логов, истории сессий и записи команд, если команда это включает. Согласование может жить в IAM, в правилах VPN, в самом bastion-хосте или в тикет-процессе.
Это меняет ежедневную работу команды. Tailscale SSH переносит усилия в сторону правил идентификации, доверия к устройствам, увольнения пользователей и политик доступа на уровне машин. Bastion-хост переносит усилия в сторону поддержки прыжкового сервера, обновлений, укрепления SSH, ротации правил доступа и контроля пути от bastion к приватным машинам. В обеих схемах кто-то всё равно должен регулярно проверять, у кого есть доступ, и быстро удалять устаревшие учётки.
Небольшим командам часто нравится Tailscale SSH, потому что он убирает один сервер и сокращает время настройки. Bastion требует больше ухода каждую неделю, но он может быть уместен, когда вам нужен один узкий вход, одно место для дополнительных контролей или знакомая модель для аудита.
Простой способ думать об этом: Tailscale SSH приближает доверие к пользователю и его устройству. Bastion-хост приближает доверие к одной контролируемой машине. Ни один из вариантов не убирает админскую работу. Он лишь меняет, где именно эта работа живёт.
Что обычно спрашивают аудиторы
Аудиторы обычно начинают с простого вопроса: кто вошёл на какой хост и когда? Им нужна запись, которая связывает реального человека с реальной машиной в конкретное время. Общие админские учётки сильно усложняют это, даже если команда совсем маленькая.
Проверки редко зависят от названия инструмента. Аудиторам нужны доказательства. Если ваша схема показывает личность пользователя, время входа, целевой хост и то, прошёл доступ или нет, вы уже закрываете большую часть запроса.
Следующий вопрос — офбординг. Если подрядчик уходит в пятницу, как вы убираете его доступ в тот же день? Аудиторы часто хотят не обещания, а подтверждения. Они могут попросить показать изменение доступа в админ-системе, дату изменения и того, кто его утвердил.
С этим помогает несколько базовых правил. Дайте каждому человеку именной доступ. Не используйте общие SSH-ключи. Удаляйте доступ в одном месте, когда работа заканчивается. Храните датированную запись о том, кто одобрил изменение.
Одних логов не всегда достаточно. Некоторым командам хватает только логов входа, потому что они работают с низкорисковыми внутренними серверами и контролируют команды другими способами. Другим нужны записи сессий, особенно если люди работают с производственными данными, платёжными системами или инфраструктурой клиентов. Если вы не можете объяснить, что происходило после входа, ждите больше вопросов.
Ещё нужно понимать, где живут согласования. Если одно согласование в чате, другое в почте, а третье существует только в чьей-то памяти, аудит быстро превращается в хаос. Выберите одно место для запросов на доступ и для его удаления, а потом используйте его каждый раз.
Небольшой стартап с одним основателем, двумя инженерами и краткосрочным DevOps-подрядчиком может оставить всё довольно простым. Дайте каждому именной доступ, храните согласования в одной ticket-системе и уберите подрядчика в дату окончания договора. Это намного легче отстаивать, чем потом пытаться восстановить картину из разрозненных логов через несколько месяцев.
Как работать с подрядчиками
Подрядчики обычно лучше всего показывают разницу между этими схемами. Штатный сотрудник со временем подстроится под ваши правила. Краткосрочному подрядчику нужны жёсткие ограничения с первого дня.
Самое безопасное правило простое: давайте доступ только к тем хостам и сервисам, которые подрядчику действительно нужны. Если человек чинит CI-раннер, ему не нужен доступ к production-базе. Если он обновляет один app server, ему не нужен путь во всю приватную сеть.
Tailscale SSH в таком случае часто ощущается аккуратнее, потому что можно привязать доступ к одному человеку и одному устройству, а потом быстро всё убрать. Bastion-хост тоже может хорошо работать, особенно если вам нужен один контролируемый вход и подробные логи команд. Но bastion помогает только если права после входа остаются узкими. Один широкий прыжковый сервер всё равно остаётся широким доступом.
Короткие окна доступа важнее, чем команды часто думают. Открытые аккаунты для подрядчиков обычно висят месяцами просто потому, что никому не хочется что-то сломать. Давайте доступ на неделю, на спринт или на тикет. Продлевайте его осознанно, если работа продолжается.
До того как кто-то получит доступ, определите четыре вещи: к каким хостам он может обращаться, какие порты или сервисы нужны, когда доступ заканчивается и кто проверяет эти аккаунты каждую неделю. Сделайте владельца процесса явным. Обычно это тимлид или ops-специалист.
Не используйте общих пользователей. Не передавайте приватные ключи в чате. Если три человека входят как «admin», вы теряете чистую историю доступа и создаёте проблемы, которых можно было избежать, во время проверок.
Планирование аварийного доступа
Аварийный доступ помогает только тогда, когда он скучный, ограниченный и описан заранее. Именно здесь команды чаще всего находят реальный пробел. Они доверяют обычному пути входа, но никогда не решают, что делать, если он сломается.
Начинайте с конкретных людей, а не с ролей. Выберите двух или трёх человек, которые смогут использовать аварийный доступ, и держите эту группу маленькой. Если шесть человек могут открыть доступ к продакшену, у вас нет запасного пути. У вас есть дополнительный админ-путь, который никто по-настоящему не контролирует.
Подрядчики не должны хранить аварийные учётные данные. Они могут помогать во время инцидента, но открывать аварийный путь должен сотрудник или владелец, и именно он остаётся ответственным за то, что будет дальше.
Короткое правило лучше длинной политики. Используйте аварийный доступ только когда обычный путь входа недоступен, сбой у провайдера идентификации блокирует админов или активный инцидент угрожает данным клиентов или доступности сервиса. Добавьте ещё одно правило: тот, кто воспользовался этим доступом, должен сразу записать причину в тикет инцидента или в командный лог.
Храните аварийные учётные данные в vault с понятным процессом выдачи. Если позволяет время, требуйте согласование от одного названного запасного владельца. Если проблема серьёзная и согласовать некому, один человек может открыть доступ, но после инцидента обязательно должен быть ревью. Vault должен фиксировать, кто открыл секрет, когда это сделал и когда команда потом ротировала его.
Проверьте запасной путь до того, как это сделает реальный сбой. Раз в несколько месяцев проводите короткое учение. Заблокируйте обычный админский путь, используйте аварийный и засеките время. Если команде нужно 40 минут, чтобы найти секрет, или хост не принимает вход, план у вас пока только на бумаге.
Как выбрать шаг за шагом
Начинайте с масштаба, а не с инструментов. У команды из четырёх человек и восьми серверов совсем другая задача по доступу, чем у команды из 15 человек с десятками хостов, внешними подрядчиками и проверками соответствия. Посчитайте людей, посчитайте машины и запишите, кому вообще нужен shell-доступ.
Затем посмотрите на требования к учёту. Если вам нужно только показать, кто подключался, когда подключался и к какому хосту обращался, более лёгкий вариант часто выигрывает. Для многих небольших команд вопрос не философский. Это вопрос о том, достаточно ли базовых записей доступа.
Практичный подход работает хорошо:
- Запишите размер команды, число хостов и любые известные вам требования аудита.
- Перечислите особые случаи, особенно подрядчиков, краткосрочных админов и аварийный доступ.
- Выберите самую лёгкую схему, которая всё ещё даёт понятные логи и простой офбординг.
- Добавьте bastion-хост, если вам нужна одна точка для контроля доступа, согласования сессий или записи активности.
- Пересмотрите схему после первого контракта с подрядчиком или первого серьёзного запроса на аудит.
Tailscale SSH имеет смысл, когда важнее всего скорость и низкая нагрузка. С его помощью маленькая команда быстро начинает работать, а ежедневная админская рутина остаётся простой. Это важно. Если у команды нет времени нянчиться с системой доступа, более простая схема часто и безопаснее, потому что люди действительно будут её поддерживать.
Bastion заслуживает места, когда контроль нужно централизовать. Обычно это происходит, когда нескольким людям нужны админские обязанности, подрядчики приходят и уходят или аудитор хочет видеть один чёткий контрольный пункт для доступа. Если вам нужна запись сессий, более строгие согласования или одна дверь в продакшен, дополнительная настройка оправдана.
Не считайте первый выбор окончательным. Команды меняются быстро. Один подрядчик, один security review или один неприятный инцидент в 2 часа ночи может показать, что текущая схема слишком свободная или, наоборот, слишком тяжёлая.
Простой пример для команды
В стартапе из пяти человек два app server и одна база данных. Основатель всё ещё участвует в исправлениях продакшена, и никто не хочет тратить неделю на построение правил доступа до начала настоящей работы.
Они начинают с Tailscale SSH, потому что его быстро настроить и легко понять. Каждый сотрудник входит под своей учётной записью, серверам не нужно открывать public SSH в интернет, а процесс входа остаётся простым.
На этом этапе выбор логичен. Троим людям нужен регулярный доступ к серверам, база остаётся приватной, а команде в первую очередь нужно избежать общих SSH-ключей и грязной ручной настройки пользователей.
Потом на две недели подключается freelance DevOps-инженер, чтобы привести в порядок деплой и проверить резервные копии. Команда даёт этому человеку доступ только к app server, но не к базе, и ставит чёткую дату окончания. Для небольшой быстрорастущей компании это разумная краткосрочная схема.
Позже клиент просит подтверждение для аудита. Ему нужны понятные ответы на базовые вопросы: кто заходил в продакшен, когда входил и остался ли у подрядчика доступ после завершения проекта.
Именно здесь компромисс становится по-настоящему заметным. Tailscale SSH часто выигрывает на старте, потому что убирает лишнее трение. Когда внешний доступ растёт, командам обычно нужны более строгие записи и одно место для проверки входа в продакшен.
Стартап не выбрасывает первую схему. Он оставляет Tailscale SSH для основной команды, потому что так повседневная работа по-прежнему проще. Позже они добавляют bastion-хост для подрядчиков и для доступа к продакшену, где нужен более формальный учёт.
Такое разделение хорошо подходит для команды этого размера. Сотрудники сохраняют быстрый доступ для обычной админской работы. Подрядчики идут через bastion. База данных остаётся за более жёсткими правилами, а у клиентских аудитов появляется одно понятное место для проверки.
Вывод простой: начинайте с той схемы, которая соответствует вашей текущей команде, а затем добавляйте структуру, когда к продакшену подключается больше внешних людей.
Ошибки, которые потом создают проблемы
Выборы по доступу редко ломаются в первый день. Они ломаются через месяцы, когда у подрядчика всё ещё есть вход, аудитор просит доказательства или единственный человек, который может зайти, спит с севшим ноутбуком.
Большая часть хаоса возникает из привычек, а не из инструментов. Небольшие команды начинают с одного обходного решения, а потом наращивают исключения, пока никто уже не понимает, какой путь ещё активен.
Одна частая ошибка — объединять сотрудников и подрядчиков в одну группу доступа. Сначала это кажется быстрее. Потом краткосрочный подрядчик получает слишком широкие права, потому что никому не хочется распутывать общие правила. Разделяйте их заранее, давайте подрядчикам более узкий доступ и задавайте даты окончания ещё до старта работ.
Старые SSH-ключи — ещё одна тихая проблема. Команда увольняет человека из Google Workspace, GitHub или Tailscale, а потом забывает, что ключи всё ещё лежат в authorized_keys на нескольких серверах. Это оставляет заднюю дверь. Если вы используете Tailscale SSH, уменьшайте риск, отключая прямой SSH там, где это возможно. Если у вас остаётся традиционный SSH, удаляйте ключи автоматически во время офбординга, а не полагайтесь на память.
Аварийный доступ ломается похожим образом. Некоторые команды зависят от одного ноутбука старшего администратора во время каждого кризиса. Это не план. Если ноутбук потерян, заблокирован или офлайн, ваш break-glass-процесс исчезает вместе с ним. Держите как минимум двух доверенных админов, которые умеют пользоваться аварийным путём, и проверяйте этот путь с другой машины.
Логи тоже потом создают боль, потому что команды считают их необязательными, пока не приходит аудит. А потом кто-то спрашивает, кто три месяца назад заходил на production box, под какой учёткой и совпадала ли сессия с согласованием. Если ваши логи хранились всего неделю, вы не сможете ответить уверенно. Храните auth-логи и записи сессий достаточно долго, чтобы закрывать ваши аудит- и клиентские требования.
Bastion-хосты создают ещё одну ловушку: команды строят умный шлюз, который никто не может починить в 2 часа ночи. Bastion должен быть скучным. Используйте простую схему, опишите шаги восстановления и убедитесь, что больше одного человека умеет его обновлять, перезапускать и ротировать доступ.
Несколько скучных правил предотвращают большую часть проблем. Держите доступ подрядчиков отдельно от доступа сотрудников. Удаляйте старые SSH-ключи при офбординге. Проверяйте аварийный доступ с двумя администраторами, а не с одним. Храните логи достаточно долго, чтобы отвечать на реальные вопросы аудита. Делайте bastion достаточно простым, чтобы дежурный мог починить его почти вслепую.
Небольшим командам не нужна идеальная система. Им нужна такая, которая остаётся понятной после текучки, ночных инцидентов и первого серьёзного аудита.
Быстрые проверки перед тем, как решиться
Небольшой команде не нужна идеальная схема доступа. Ей нужна такая, которую люди могут объяснить, проверить и которой можно доверять под давлением.
Начните с вопроса, который задают и основатели, и аудиторы, когда что-то кажется странным: кто трогал продакшен и когда? Выберите реальный день и попросите одного человека достать ответ. Если ему нужно полчаса искать его в чате, истории shell и облачных логах, схема слишком запутанная.
Потом проверьте удаление подрядчика. Дайте тестовому аккаунту подрядчика доступ, а затем удалите его, пока кто-то смотрит на часы. Хорошая схема позволяет закрыть доступ за несколько минут, а не после цепочки ручных действий в трёх разных системах. Если доступ может висеть из-за одного пропущенного SSH-ключа или одной записи в allowlist, потом это аукнется.
Аварийному доступу нужна отдельная проверка. Вам нужен путь, который работает даже тогда, когда обычная система идентификации ломается, но при этом контроль тоже нужен. На практике два доверенных человека должны уметь открыть этот путь вместе и сразу закрыть его после исправления. Если один человек может сделать это в одиночку и без следа, это скрытая задняя дверь.
Ясность важнее, чем признают многие команды. Попросите нового сотрудника пересказать схему простыми словами после короткой передачи дел. Если он не может сказать, кто входит, как работает согласование и куда попадают записи, значит, дизайн сложнее, чем должен быть.
Один последний тест ловит много проблем: пройдите полный процесс входа с чистого ноутбука. Если команде нужен длинный гайд по настройке, личные заметки или дежурство старшего инженера, ежедневный доступ всё равно будет ломаться по мелочам. Обычно лучший выбор — тот, который команда может спокойно отрепетировать без драмы.
Что делать дальше
Большинству команд нужно меньше инструментов и больше понятных правил. Если вы выбираете между Tailscale SSH и bastion-хостами, сначала опишите, как должен работать доступ, а уже потом что-то покупайте.
Уместите этот документ на одну страницу. Он должен отвечать на простые вопросы: кто может попасть в продакшен, кто утверждает доступ подрядчиков, как долго живёт временный доступ, что логируется и кто может использовать аварийный доступ, когда обычные механизмы не работают.
Потом проверьте план на реальных людях, а не на догадках. Попросите одного подрядчика пройти процесс от начала до конца и засеките каждый шаг. Если его блокирует какая-то глупость, чините сам процесс, а не только формулировки.
Проведите и учение по аварийному доступу. Выберите безопасный сценарий, например ночной сбой на одном сервере, и посмотрите, как кто-то попадает внутрь, когда обычный владелец недоступен. Вам нужно понять, насколько путь break-glass понятный, быстрый и при этом задокументированный.
Обращайте особое внимание на шаги, которые люди пропускают. Команды всегда что-то пропускают. Может быть, они забывают истечь временный доступ, или отправляют сообщение вместо того, чтобы идти по утверждённому пути. Обычно это значит, что в процессе есть один-два раздражающих места, которые нужно убрать.
Хорошие правила доступа в повседневной работе ощущаются скучными. Люди могут следовать им без помощи, а вы сможете объяснить их аудитору простыми словами.
Если хотите второе мнение, Олег Сотников на oleg.is помогает разбирать модели доступа для стартапов и небольших команд. Такая проверка особенно полезна, когда уже накапливаются аудит, доступ подрядчиков и правила аварийного доступа.
Часто задаваемые вопросы
Хватит ли Tailscale SSH для совсем маленькой команды?
Для команды из нескольких доверенных людей и простых требований к аудиту — да. Он хорошо работает, когда нужны персональный доступ, лёгкий офбординг и меньше еженедельной рутины.
Когда лучше выбрать bastion-хост?
Выбирайте bastion-хост, если вам нужен один контролируемый вход в продакшен. Он особенно полезен, когда подрядчики приходят и уходят, нескольким людям нужны админские права или вам нужны записи сессий в одном месте.
Можно ли использовать и Tailscale SSH, и bastion-хост?
Да, так делают многие небольшие команды. Оставьте ежедневный доступ простым для сотрудников, а доступ подрядчиков или к чувствительному продакшену направляйте через bastion-хост ради более строгого контроля.
Что обычно хотят видеть аудиторы?
Начните с базового: кто входил, когда входил, к какому хосту получил доступ и зачем. Если вы работаете с чувствительными системами, храните ещё и записи согласований и историю сессий.
Как лучше организовать доступ подрядчиков?
Дайте каждому подрядчику именной доступ только к тем хостам и сервисам, которые ему нужны, и сразу задайте дату окончания. Если работа продолжается, продлевайте доступ осознанно, а не оставляйте аккаунт открытым.
Почему стоит избегать общих админ-аккаунтов и SSH-ключей?
Общие учётки и общие ключи быстро ломают аудит-трек. Когда все входят под одной и той же учёткой, вы не можете доказать, кто что сделал, и проверки превращаются в догадки.
Что должно входить в офбординг?
Сначала удалите доступ в системе идентификации, а затем проверьте серверы на старые SSH-ключи или локальные учётки. Делайте это в тот же день и сохраняйте датированную запись о том, кто утвердил изменение.
Как безопасно настроить аварийный доступ?
Держите группу маленькой и указывайте конкретных людей, а не общие роли. Храните аварийную учётную запись в vault, фиксируйте каждое использование и сразу ротируйте её после инцидента.
Как долго хранить логи доступа?
Срок хранения должен соответствовать вашим требованиям клиентов и аудита, но не ограничивайтесь несколькими днями. Если через три месяца кто-то спросит о доступе в продакшен, у вас всё ещё должен быть понятный ответ.
Что стоит проверить перед тем, как выбрать одну схему?
Проведите реальный вход с чистого ноутбука, удалите тестовую учётку подрядчика и попробуйте аварийный путь во время учений. Если любой из этих шагов кажется медленным или запутанным, исправьте процесс до окончательного выбора.


