Сжатие Docker-образов для заметно более быстрых развертываний
Сжатие Docker-образов может сократить время загрузки и ускорить релизы, если упорядочить слои, убрать мусор от сборки и правильно выбрать базовый образ.
Содержание
Почему меньший размер образов не всегда ускоряет развертывания
200 МБ образ может всё ещё казаться медленным, если команда ждёт не ту часть релиза.
Релиз обычно проходит через четыре шага: собрать образ, запушить изменившиеся слои в регистри, скачать отсутствующие слои на сервер, затем запустить контейнер и дождаться успешных health check'ов. Размер образа влияет только на часть этого цикла. Если регистри, сервер или кластер уже имеют большинство слоёв в кеше, время pull может быть коротким. В таком случае сокращение на несколько сотен мегабайт выглядит хорошо на бумаге и почти не меняет время релиза.
Порядок слоёв часто важнее окончательного размера. Один плохо расположенный слой может нарушить повторное использование кеша. Распространённая ошибка — ставить установку зависимостей и исходники приложения в один шаг. Тогда даже небольшое изменение кода заставляет Docker пересобирать, заново пушить и скачивать весь этот слой. Образ может выглядеть компактным, но каждый релиз остаётся медленным.
Сжатие тоже может скрывать реальную стоимость. Образ может сжаться на диске и всё равно потребовать времени на распаковку, проверку и запуск. Некоторые команды гоняются за мегабайтами и игнорируют путь старта. Если приложению требуется 40 секунд на прогрев, один только меньший образ не спасёт релиз.
Простой пример иллюстрирует это. Допустим у вас небольшой API. Вы уменьшили образ с 450 МБ до 260 МБ, но при каждом деплое всё равно пересобирается слой зависимостей, и приложению всё равно нужно 30 секунд, чтобы отвечать на health check. Релиз ощущается почти так же.
Важно время ожидания, а не только размер образа. Измеряйте, сколько занимает сборка, сколько данных вы реально пушите и скачиваете, и как быстро контейнер становится готов. Если эти числа уменьшаются, команда заметит разницу.
Что действительно замедляет релиз
Большинство медленных релизов происходят по четырём причинам: сборка, push, pull и запуск. Команды часто винят размер образа во всём, но это слишком упрощённо. Размер в основном влияет на время push и pull. Время сборки и задержки при старте обычно вызваны другими факторами.
Если задача CI тратит 6 минут на сборку и только 40 секунд на push в регистри, уменьшение образа на 200 МБ мало что изменит. Если сборка заканчивается за 50 секунд, но каждый сервер тратит 2 минуты на скачивание слоёв по медленному каналу, тогда размер имеет большое значение. Засекайте время каждого шага, прежде чем начинать удалять пакеты.
Быстрая проверка обычно расскажет всё:
- сколько времени занимает сборка в CI
- сколько времени занимает push в регистри
- сколько времени каждый сервер тратит на pull слоёв
- сколько времени контейнер становится здоровым
Кеш меняет картину при повторных релизах. Docker не передаёт каждый байт при каждом релизе, если старые слои уже существуют в регистри или на сервере. 900 МБ образ может деплоиться удивительно быстро, если изменился только маленький слой приложения. Обратная ситуация тоже встречается. 250 МБ образ всё ещё может казаться медленным, если плохой порядок слоёв заставляет Docker пересобирать и заново пушить слои зависимостей при каждом коммите.
Время старта — отдельная проблема. Меньший образ не гарантирует более быстрый запуск. Контейнеры часто стартуют медленно, потому что приложение выполняет миграции, прогревает кэши, скачивает модели или ждёт базу данных. Статический сервис на Go в большем образе может подняться за секунду. Маленький Node или Python образ всё равно может запускаться дольше, если подготовительной работы много.
Ограничения сети важнее, чем многие ожидают. CI-раннеры, регистри и продакшн-серверы часто находятся в разных регионах или у разных провайдеров. Каждый релиз пересекает сеть дважды: при push и при pull. Если одно звено ограничено 20–50 Мбит/с, уменьшение образа заметно влияет на время. Во многих конфигурациях сближение раннеров, регистри и серверов экономит столько же времени, сколько и обрезка образа.
Выбирайте базовый образ, подходящий под приложение
Самый маленький базовый образ не всегда лучший. Если приложению нужны дополнительные библиотеки, сертификаты, shell-инструменты или помощники для сборки, крошечный базовый образ может быстро разрастись и всё равно привести к медленным и раздражающим деплоям.
Правило проще: выбирайте базовый образ, которому нужно наименьшее количество дополнительных частей для вашего реального приложения. Это обычно лучше, чем погоня за минимальным числом в панели.
Alpine крошечен и часто хорошо подходит для статических бинарников Go или Rust. Он отлично работает, когда вы копируете один скомпилированный бинарник и запускаете его.
Но Alpine использует musl вместо glibc. Это может вызывать проблемы с Python wheels, нативными модулями Node, некоторыми настройками Java и инструментами, которые ожидают более распространённой Linux-среды. Команды тогда добавляют лишние пакеты, чтобы всё заработало, и образ перестаёт быть маленьким в практическом смысле.
Debian slim больше, но для многих стэков это более безопасный дефолт. Если вы запускаете Node, Python, Java или что-то с нативными зависимостями, Debian slim часто экономит время, потому что пакеты ведут себя ожидаемо, и отладка проще.
Distroless-образы могут отлично подходить для runtime-контейнеров в продакшне. Они убирают shell, менеджер пакетов и много лишних файлов, что сокращает размер и убирает шум. Минус очевиден, когда что-то ломается: нельзя просто открыть shell и посмотреть внутри контейнера. Такой компромисс подходит зрелым сервисам с хорошими логами и мониторингом. Для небольшой команды, которая ещё часто проверяет контейнеры вручную, это может замедлить работу.
Полные образы всё ещё имеют место. Они удобны на стадиях сборки или для приложений со сложными цепочками зависимостей. Редко они лучший финальный runtime-образ, но часто упрощают и делают надёжнее сборку.
Короткое практическое правило:
- Используйте Alpine для простых статических бинарников и строго контролируемых окружений.
- Используйте Debian slim для большинства общих стэков приложений.
- Используйте distroless для стабильных runtime-образов, когда отладка выполняется вне контейнера.
- Используйте полные образы для стадий сборки или громоздких зависимостей.
На практике важнее меньше установленных пакетов, а не модный крошечный базовый образ. Node-приложение на Debian slim с только необходимыми пакетами часто деплоится лучше, чем Alpine-образ, наполненный фиксовыми пакетами, компиляторами и инструментами отладки.
Располагайте слои в правильном порядке
Порядок слоёв решает, будет ли Docker переиспользовать работу или выбросит её. Если вы копируете весь проект слишком рано, одно небольшое изменение кода может заставить Docker заново установить пакеты, пересобрать ассеты и снова запушить большие слои.
Начинайте с частей, которые редко меняются. Системные пакеты, runtime-инструменты и настройка пользователя должны быть в верхней части Dockerfile, потому что они остаются стабильными долгое время. Код приложения помещайте позже. Исходники меняются каждый день, иногда каждый час. Когда они находятся ближе к концу, Docker пересобирает только последние шаги, а не начинается сначала.
Для большинства приложений простой порядок работает хорошо: старт от базового образа, установка только нужных системных пакетов, копирование манифестов пакетов и lock-файлов, установка зависимостей приложения, затем копирование остального исходного кода.
Шаг с lock-файлом важнее, чем многие думают. Файлы вроде package.json, package-lock.json, poetry.lock, requirements.txt, go.mod или Cargo.lock сообщают Docker, когда изменились зависимости.
Если lock-файл остаётся тем же, Docker может переиспользовать слой зависимостей, даже если вы правите десять исходных файлов. Это экономит время при локальных сборках, CI и push'ах в регистри. Меньшие по объёму деплои ощущаются быстрее, потому что неизменные слои не передаются заново.
Node-приложение часто замедляет само себя такой схемой:
COPY . .
RUN npm install
Лучше такой порядок:
COPY package.json package-lock.json ./
RUN npm ci
COPY . .
Теперь правка CSS или небольшой API-фикс не триггерит полную установку зависимостей. Та же идея работает для проектов на Python, Go, Rust и Java.
Именно здесь сжатие образа начинает приносить ощутимый эффект. Меньшие слои зависимостей помогают, но более крупная выгода — в том, чтобы вообще не пересобирать и не перезаписывать их. Если маленькое изменение кода меняет только один верхний слой, время релиза часто падает сильнее, чем команды ожидают.
Очистка пакетов и артефактов сборки
Большинство выигрышей по размеру приходят от скучной работы по очистке. Пара забытых кэшей, временных папок и инструментов сборки могут добавить сотни мегабайт, и они останутся, если вы удаляете их неправильно.
Поведение слоёв важно здесь. Если один шаг ставит пакеты, а последующий шаг удаляет кэш, старый слой всё равно хранит лишние файлы. Чтобы уменьшить образ, устанавливайте и очищайте в одной команде RUN.
Частый пример — apt. Индекс пакетов нужен при установке, но вашему приложению он не нужен в runtime. Если оставить его, при каждом релизе перемещаются лишние данные без причины.
RUN apt-get update && apt-get install -y build-essential curl \\
&& rm -rf /var/lib/apt/lists/*
Инструменты сборки — другой тихий источник раздутия. Компиляторы, заголовки и менеджеры пакетов часто нужны только на стадии сборки. Ваш production-контейнер обычно нуждается только в финальном бинарнике, скомпилированных ассетах или установленных файлах приложения. Ему не нужен gcc, make или полный toolchain.
Временные файлы вызывают ту же проблему. Архивы, распакованные каталоги, тестовые артефакты и остатки установщиков часто остаются в образе, потому что никто их не удалил до завершения слоя. Оказавшись в слое, они продолжают занимать место, даже если вы удалили их позже.
Хорошая очистка обычно означает удаление кешей менеджеров пакетов в том же слое, где вы их установили, удаление скачанных архивов после распаковки, не включать инструменты сборки в финальный образ и копировать в продакшн только runtime-файлы.
Многое из этого решается мультистадийными сборками. Вы собираете приложение в одной стадии со всеми тяжёлыми инструментами, затем копируете только результат в меньшую runtime-стадию. Это оставляет финальный образ сфокусированным на том, что реально запускается.
Подумайте о Node-приложении, которое устанавливает Python, make и g++ для компиляции нативных модулей. Эти инструменты помогают при npm install, но в продакшне после запуска приложения они не нужны. Мультистадийная сборка позволяет сохранить скомпилированное приложение и выбросить всё остальное.
Это не гламурная работа, но она часто даёт более быстрые релизы, которые вы почувствуете сразу, особенно когда один и тот же образ проходит через CI, push в регистри, pull и развёртывание при каждом релизе.
Уменьшайте образ шаг за шагом
Начинайте с чисел, а не с правок. Проверьте текущий размер образа, затем замерьте, сколько времени занимает pull того же образа через ту же регистри, регион и сетевой путь, который использует ваш релиз. Догадки тратят время. Иногда большое сокращение размера почти ничего не меняет, потому что реальная задержка в другом месте.
Затем выпишите, что нужно приложению после старта. Большинство образов несут лишний багаж от процесса сборки. Runtime обычно нуждается в собранном приложении, бинарнике или статических файлах, библиотеках, сертификатах и конфиге, плюс пользователя, порты и рабочую директорию.
Обычно ему не нужны компиляторы, тестовые инструменты, кэши, индексы пакетов или исходники, которые никогда не выполняются в продакшне. Пропустите этот список runtime, и сжатие превратится в эксперимент вслепую.
Дальше перестройте Dockerfile с мультистадийными шагами. Используйте одну стадию для установки build-зависимостей и компиляции. В финальной стадии оставляйте только runtime-файлы. Копируйте минимальный набор артефактов, который позволяет приложению стартовать корректно. Node-приложение может копировать скомпилированный сервер и production-модули. Go-приложение — один бинарник и сертификаты.
Очищайте по ходу. Удаляйте кеши менеджеров пакетов в том же слое, где вы их установили, иначе байты останутся в истории слоя. То же правило относится к временным архивам, папкам сборки и скачанным установщикам.
После этого протестируйте новый образ по тому же пути деплоя, который используете в реальных релизах. Прогоните pull, запуск, health check и откат. Меньший образ, который ломает логи, shell-доступ или доверие к SSL, — не улучшение. Вам нужен более быстрый релиз, который ведёт себя так же под нагрузкой.
Оставьте версию, которая сокращает время pull без усложнения сопровождения. Если мелкий образ экономит две секунды, но делает отладку болезненной, не стоит его использовать. Если чистая мультистадийная сборка уменьшает сотни мегабайт и каждый раз ускоряет деплой, оставьте её и задокументируйте причины.
Простой пример «до и после»
Небольшое Node-приложение быстро показывает проблему. Само приложение не большое, но образ раздут, потому что сборка начинается с полного базового образа и копирует всё слишком рано.
В первой версии даже однострочное изменение в src/index.js ломает кеш для установки зависимостей. Docker вынужден выполнить npm install снова, заново собрать и запушить или скачать больше данных, чем нужно.
FROM node:20
WORKDIR /app
COPY . .
RUN npm install
RUN npm run build
CMD ["node", "dist/index.js"]
Этот порядок кажется безобидным, но он дорого обходится. COPY . . добавляет весь проект сразу. Когда меняется любой исходник, Docker считает следующие слои новыми, поэтому слой установки пакетов пересобирается тоже.
Лучше копировать сначала только файлы зависимостей, установить пакеты один раз, а потом копировать код приложения. Также стоит использовать отдельную runtime-стадию с более лёгким базовым образом.
FROM node:20 AS build
WORKDIR /app
COPY package.json package-lock.json ./
RUN npm ci
COPY src ./src
COPY tsconfig.json ./
RUN npm run build
FROM node:20-slim
WORKDIR /app
COPY --from=build /app/node_modules ./node_modules
COPY --from=build /app/dist ./dist
CMD ["node", "dist/index.js"]
Теперь кеш работает так, как вы хотите. Если вы меняете только код приложения, Docker сохраняет слой с npm ci. Пересборка короче, а финальный образ меньше, потому что runtime-стадия выбрасывает инструменты сборки и прочие остатки полного базового образа.
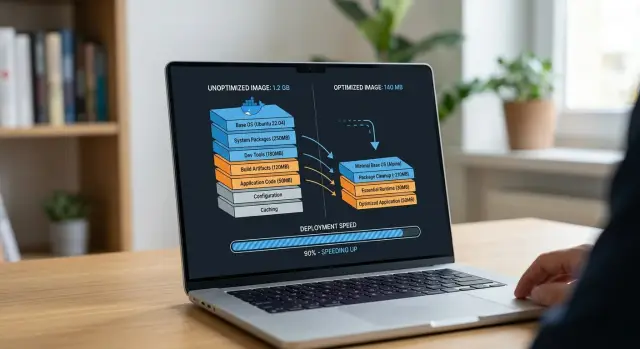
Цифры обычно легко прочувствовать. Частый «до» образ может быть около 1.1 ГБ и занимать 30–40 секунд на pull на чистом сервере. После переупорядочивания слоёв и переключения финальной стадии на node:20-slim тот же проект может упасть до 220 МБ и скачиваться за 6–9 секунд.
Поэтому сокращение размера важно, когда оно идёт в паре с хорошим кешированием. Меньший образ помогает. Но ещё важнее — чтобы при каждом изменении не переустанавливались зависимости.
Ошибки, которые сводят на нет выигрыши
Меньший образ всё ещё может деплоиться с той же скоростью, если вы обрезали не те части. Если кеш ломается часто, или финальный образ всё ещё содержит ненужные инструменты, сэкономленные мегабайты могут ни на что не повлиять.
Одна распространённая ошибка — оставлять инструменты отладки в финальном образе. Shell-утилиты, менеджеры пакетов, компиляторы и сетевые инструменты полезны при тестировании, но в продакшне редко нужны. Они добавляют размер, увеличивают зону атаки и превращают образ в универсальную коробку вместо специализированного runtime.
Очистка часто идёт не так по тонкой причине. Команды устанавливают пакеты в одном слое, затем удаляют кеши в следующем и думают, что образ чист. Docker хранит эти байты в истории слоёв. Если устанавливать и очищать в одной команде RUN или переместить шаги сборки в отдельную стадию, финальный образ действительно уменьшится.
Частые изменения базового образа — ещё одна проблема. При использовании latest или при частой смене базовых образов Docker вынужден чаще скачивать и пересобирать. Релизы становятся менее предсказуемыми. Фиксированная версия базового образа даёт более стабильное кеширование и меньше сюрпризов.
Некоторые команды гонятся за абсолютным минимумом и в итоге получают систему сложнее, чем нужно. Сохранение ещё 20 МБ не стоит того, если Dockerfile становится хрупким, непонятным и тяжело поддерживаемым. Простой образ, который ежедневно быстро деплоится, лучше крошечного образа, который ломается при рутинных обновлениях.
Худшие сокращения случаются, когда кто-то удаляет файлы, которые приложение всё ещё использует в runtime. Это могут быть сертификаты CA, общие библиотеки, данные по временной зоне или маленький бинарник, используемый entrypoint'ом. Образ выглядит стройным до тех пор, пока контейнер не начнёт падать в продакшне.
Короткая проверка на здравый смысл:
- оставляйте в финальном образе только runtime-инструменты
- устанавливайте и очищайте в одном слое
- фиксируйте версии базовых образов
- тестируйте контейнер после каждой обрезки
- прекращайте обрезки, когда время релиза перестаёт улучшаться
Если изменение экономит место, но добавляет риск — пропустите его. Быстрые релизы получаются из меньшего объёма данных и меньшего количества сюрпризов.
Быстрые проверки и дальнейшие шаги
Измеряйте три числа вместе: размер образа, время pull и время пересборки. Если следить только за размером, можно пропустить реальную проблему. Быстрые релизы обычно получаются за счёт меньших pull'ов, лучшего повторного использования кеша и меньшего объёма пересборок.
Простая таблица проверок:
- итоговый размер образа
- время pull на чистой машине
- время пересборки после небольшого правки кода
- время холодного старта контейнера
Запускайте контейнер так, как в продакшне. Убедитесь, что приложение стартует только с runtime-зависимостями. Если в финальном образе всё ещё есть компиляторы, менеджеры пакетов или инструменты сборки, которые приложение не использует в runtime, вы упустили простые выигрыши.
Сделайте ещё одну практическую проверку перед релизом. Прочитайте логи, протестируйте health check и подтвердите, что вы всё ещё можете отлаживать контейнер так, как это ожидает ваша команда. Некоторые команды убирают shell-доступ и экономят место, а затем застревают при инциденте, потому что никто не может посмотреть внутри рабочего контейнера. Это может быть правильным решением, но решение нужно принять сознательно.
Запишите порядок слоёв Docker в репозитории. Держите это просто и ясно: сначала копировать lock-файлы, затем устанавливать зависимости, потом копировать код приложения и очищать кеши в том же шаге, где вы их установили. Если никто этого не записывает, Dockerfile обычно загромождается снова после нескольких срочных правок.
Относитесь к этому как к регулярному обслуживанию, а не разовой очистке. Проверяйте образ каждые несколько релизов. Если время релиза снова начинает расти, ищите новую зависимость, COPY, ломающее кеш, или базовый образ, который больше не подходит приложению.
Если хотите практический разбор Dockerfile и всего процесса доставки, Oleg Sotnikov на oleg.is работает с командами в роли временного CTO и советника стартапов. Второй взгляд часто обнаруживает тот самый слой, сетевой хоп или привычку в сборке, которая делает релизы медленнее, чем нужно.


