Стратегия тестовых окружений для небольших команд: полная, облегчённая или превью?
Стратегия тестовых окружений для небольших команд зависит от риска релиза, потребностей тестирования и бюджета. Сравнение полной копии, облегчённого окружения и preview‑сборок.
Содержание
Почему это быстро становится беспорядком
Небольшие команды редко имеют отдельные ритмы для разработки, тестирования и релиза. Те же люди, кто пишет код в понедельник, часто исправляют баги, ревьюят пулл-реквесты и отправляют релиз в пятницу. Поэтому стейджинг ощущается и как страховка, и как налог.
Проблема начинается, когда ещё одно окружение создает работу каждую неделю. Кто‑то должен держать конфигурации в синхронизации, загружать полезные тестовые данные, чинить скрипты деплоя, вращать секреты и замечать, когда стейджинг отклоняется от production. В команде из четырёх‑пяти человек эта работа ложится на тех же людей, которые пытаются завершить продукт.
Слабый стейджинг создаёт другую проблему. Пока всё выглядит нормально до дня релиза, небольшие отличия превращаются в реальные баги. Фоновые задачи ведут себя иначе. Письма не уходят. Хранилище файлов указывает не туда. Права ломаются только на данных, похожих на продакшн. Команда думает, что тестировала релиз, но на деле проверила упрощённую версию приложения.
Команды часто переигрывают с другой стороны: делают полную копию production для каждого изменения, даже если это правка текста, небольшое изменение формы или одно поле в админке. Тогда релизы становятся тяжёлыми. Разработчики ждут деплоев, QA ждёт данных, а простые изменения застревают из‑за инфраструктурных задач.
Вот почему выбор быстро становится запутанным. Дело не только в качестве тестов. Речь о времени, облачных расходах и о том, сколько трения команда может выдержать, прежде чем скорость релизов упадёт.
Напряжение видно просто. Допустим, команда релизит раз в неделю и делает шесть‑десять изменений за релиз. Если стейджинг ловит один серьёзный баг, но добавляет по полдня обслуживания каждую неделю, команда сразу почувствует эти затраты. Если стейджинг слишком тонок и пропускает сломанный чек‑аут или вебхук, цена ошибки ещё выше.
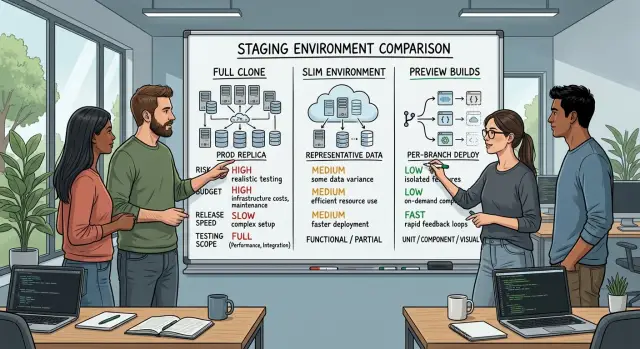
Что означают три варианта
Если команда выпускает часто, настройка стейджинга сразу меняет две вещи: сколько проблем релиза вы поймаете и сколько времени и денег потратите до запуска.
Эти три варианта лежат на одной шкале. Чем ближе к production — тем реалистичнее тестирование. Чем легче настройка — тем быстрее и дешевле она работает.
- Полная копия реплицирует большую часть production: основное приложение, структуру базы данных, фоновые задачи, очереди, права и ключевые интеграции.
- Облегчённое окружение включает только то, что нужно для обычных проверок: приложение, одну базу и несколько ключевых сервисов, без тяжёлых загрузок данных и редко используемых интеграций.
- Preview‑сборка создаёт краткоживущую версию для каждой ветки или пулл‑реквеста, чтобы можно было посмотреть изменения до слияния.
Терпеть компромисс просто. Полная копия даёт наилучшие шансы поймать баги, зависящие от окружения, но она дороже в эксплуатации и поддержке. Облегчённое окружение дешевле и проще поддерживать, но некоторые продакшн‑специфичные проблемы проскользнут. Preview‑сборки — самый быстрый вариант для фидбэка, но обычно они проверяют одно изменение за раз, а не всю систему в боевых условиях.
Небольшим командам не нужно делать из этого идеологию. Это просто инструменты для разных рисков. Если оплата, права или фоновые задачи могут упасть дорого, реализм важнее. Если же большинство изменений — правки интерфейса или небольшие обновления процессов, важнее скорость.
Когда полная копия оправдывает затраты
Полная копия имеет смысл, когда плохой релиз может нарушить оплату, раскрыть чужие данные или закрыть пользователей в сломанном потоке. Небольшие команды сильнее чувствуют такие ошибки: у них меньше пространства для откатов, всплесков поддержки и восстановления доверия.
Если ваше приложение обрабатывает оплату, подписки, возвраты, роли пользователей, процессы согласования или длинные рабочие процессы, перескакивающие между экранами, задачами и письмами, почти production‑подобный стейджинг часто окупается.
Главное преимущество — точность. Вы хотите, чтобы стейджинг вел себя как production, а не как упрощённая догадка. Это значит совпадение версий приложения, версий баз, очередей, cron‑задач, feature‑флагов, настроек воркеров и конфигураций интеграций. Тест по оплате может пройти в тонком окружении и всё равно упасть в проде, потому что поменялся один секрет вебхука или один воркер запущен с другим образом.
Полная копия также требует регулярного ухода. Команды часто закладывают бюджет на сервера и забывают про еженедельное обслуживание. Кто‑то должен обновлять замаскированные данные, держать секреты в порядке, обновлять конфигурации после изменений в проде и проверять, что почта, хранилище, поиск и мониторинг всё ещё работают как нужно.
Три задачи обычно решают, останется ли настройка полезной: регулярное обновление безопасных тестовых данных, синхронизация секретов и сервисных настроек с production и обновление стейджинга при изменениях архитектуры продакшна. Если за этим никто не следит, окружение быстро устаревает. Люди перестают доверять результатам, и смысл пропадает.
Это не должно быть по‑умолчанию для каждой небольшой команды. Если большинство релизов — низкорисковые (правки текста, маленькие формы, интерфейс или внутренние инструменты), обслуживание может стоить дороже, чем баги, которые вы предотвращаете. В таком случае лучше облегчённое окружение или preview‑сборки. Оставьте полную копию для частей продукта, где ошибка дорогая.
Когда достаточно облегчённого окружения
Облегчённое стейджинг‑окружение работает хорошо, когда команда выпускает часто, но не может позволить полную копию production. Вы по‑прежнему тестируете части, которые чаще всего ломаются, не платя за зеркалирование каждого сервиса и каждой фоновой задачи.
Для большинства небольших команд это означает держать близко к реальности три вещи: приложение, структуру базы данных и небольшой набор живых интеграций. Выберите интеграции, которые могут остановить релиз, например логин, оплату, доставку почты или хранение файлов. Если одна из них падает, пользователи это заметят быстро.
Остальное можно заглушать. Внутренние инструменты, низкорисковые вебхуки, редкие админ‑флоу и внешние сервисы, которые почти никогда не меняются, не всегда требуют живого подключения в стейджинге. Стаб или мок обычно подходят, если этот участок редко ломается и баг там не блокирует обычных пользователей.
Эта настройка работает только если команда честно признаёт, что она не тестирует. Запускайте основные пользовательские пути каждый день. Короткий ежедневный прогон ловит больше проблем, чем большая сессия тестирования прямо перед релизом. Для типичного продукта это значит: создать аккаунт, войти, завершить основную задачу, проверить письма или уведомления и убедиться, что данные попали в базу.
Простое правило помогает:
- Держите реальные сервисы для действий, влияющих на выручку, доступ или сохранённые данные.
- Заглушайте сервисы, которые поддерживают пограничные случаи или редкие сценарии.
- Часто обновляйте тестовые данные, чтобы база оставалась реалистичной.
- Пересматривайте пропуски перед крупным релизом.
Последний пункт важнее, чем команды ожидают. Облегчённое окружение может скрыть проблему, если отсутствующие куски накапливаются со временем. Перед крупным запуском проверьте, что вы заглушили, что изменилось с прошлого релиза и не превратился ли низкорисковый сервис в реальную угрозу.
Для многих команд это практичный золотой середины. Это снижает расходы, фокусирует тестирование и избегает ложного комфорта полной копии, которую никто не может поддерживать.
Когда превью‑сборки приносят наибольшую пользу
Preview‑сборки лучше всего работают, когда команде нужны быстрые просмотры изменений, а не полная репетиция production. Они отлично подходят для страниц, флоу, текста и небольших фронтенд‑обновлений, где кто‑то может кликнуть и заметить проблему за несколько минут.
Продукт‑менеджер может посмотреть новый шаг регистрации во вторник. Дизайн проверит расстояния и состояния в среду. Разработчик исправит шероховатости до того, как изменение попадёт в общий стейджинг. Этот короткий цикл экономит больше времени, чем большинство команд ожидает.
Для небольших команд превью‑сборки часто самые дешёвые: у каждой ветки своя временная версия. Никто не ждёт, пока разделяемое окружение освободится. Двое людей могут одновременно проверять два разных изменения, не мешая друг другу.
Они особенно полезны, когда приложение часто меняется на уровне интерфейса. Команда на React или Next.js, например, может создавать превью для каждого пулл‑реквеста и позволять продукту и дизайну утверждать реальные экраны вместо того, чтобы догадываться по скриншотам.
У превью‑сборок есть явные ограничения. Они обычно не достаточно близки к production для тяжёлого интеграционного тестирования. Если фича зависит от оплаты, фоновых задач, внешних API, сложных прав или реального поведения базы, превью может дать ложную уверенность. Страница может выглядеть правильно, но более глубокий флоу при этом ломаться.
Используйте их для проверки интерфейса, правок текста, контроля макета на реальных устройствах, быстрого утверждения продуктом или дизайном и базового smoke‑тестирования. Держите их временными. Старые превью быстро накапливаются, путают ревьюеров и тратят деньги. Правило — удалять их при закрытии ветки или через несколько дней.
Preview‑сборки лучше всего работают как быстрый фильтр: они ловят очевидные проблемы рано и освобождают основное стейдж‑окружение для тестов, которым нужно больше доверия.
Как выбрать настройку шаг за шагом
Начните с ущерба, а не с инструментов. Хорошая настройка защищает выручку, доверие клиентов и скорость релизов, не сжигая деньги на серверах, которыми никто не пользуется.
Запишите конкретные сбои, которые причинят наибольший вред. Формулируйте чётко. «Пользователи не могут оплатить», «новые аккаунты не могут войти» или «заказы синхронизируются с неверными суммами» дают куда больше, чем расплывчатые ярлыки вроде «проблема с чек‑аутом» или «баг API».
- Перечислите сбои, которые стоили бы вам денег, времени поддержки или гнева клиентов.
- Для каждого спросите, что нужно, чтобы честно его протестировать. Баг макета может потребовать только превью‑сборки. Поток биллинга, фоновые задачи или миграция данных часто требуют реальных сервисов, реальных очередей и базы, которая ведёт себя как production.
- Установите месячный потолок бюджета до того, как кто‑то начнёт создавать окружения. Стек стейджинга может тихо превратиться во второй счёт за продакшн.
- Выберите самое дешёвое решение, покрывающее реальный риск. Часто это превью‑сборки для дизайна и контента плюс облегчённое окружение для флоу, затрагивающих аутентификацию, оплату, задачи или изменения данных.
- Добавляйте больше только по факту. Если пропущенная проблема попала в прод и ваша текущая настройка не могла её поймать — расширяйтесь. Если нет — оставьте как есть.
Это держит разговор на земле. Вы не выбираете между «простым» и «серьёзным». Вы сопоставляете глубину теста с бизнес‑риском.
Команды, которые работают экономно, обычно получают лучшие результаты таким способом. Это та же логика, которую использует Oleg Sotnikov в AI‑first инженерии: защищайте пути, которые могут сломать бизнес, держите инфраструктуру маленькой и расширяйте её только при наличии доказательств.
Простой пример для команды с еженедельными релизами
Команда из пяти человек релизит каждый четверг. Большую часть недель они меняют экраны онбординга, подправляют фильтры, чинят мелкие баги или корректируют тексты. Такие изменения нужно проверять, но не обязательно держать полную копию production с каждым сервисом и кейсом.
Их настройка состоит из трёх слоёв, у каждого — своя роль. Это снижает расходы и избегает типичной ситуации, когда каждое изменение ждёт одного тяжёлого окружения.
Во‑первых, для каждой фичи есть превью‑сборка. Продукт и дизайн смотрят UI, проходят новый флоу и ловят очевидные проблемы на ранней стадии. Если кнопка не там или страница ломается на мобильных — это видно за минуты, а не после слияния.
Для ежедневного QA команда использует облегчённое окружение. В нём приложение, база и несколько важных сервисов. Оно не зеркалирует все фоновые задачи и внешние интеграции. Этого достаточно для большинства еженедельных задач, потому что ежедневная проверка простая: ведёт ли фича себя как ожидают пользователи?
Полную копию оставляют для изменений, затрагивающих биллинг, подписки или права аккаунтов. Когда дело касается денег или доступа, тонкое окружение может скрыть серьёзные проблемы. Перед такими релизами команда прогоняет флоу в окружении, близком к production, и тестирует от начала до конца.
Это работает потому, что усилия соответствуют риску. Быстрая проверка интерфейса — в превью. Повседневное QA — в облегчённом окружении. Более рискованные изменения получают дорогой путь тестирования только по необходимости.
Ошибки, которые тратят время и деньги
Большинство потерь начинается ещё до деплоя. Команды попадают в беду, когда сначала создают окружение, а потом решают, что в нём тестировать.
Так возникает привычка копировать production по умолчанию. Полная копия кажется безопасной, но она стоит реальных денег в облаке, требует настройки и поддержки. Если релиз меняет одну страницу оплаты или один маршрут API, вам вряд ли нужны все фоновые задачи и региональные настройки, работающие всю неделю.
Данные создают больше проблем, чем команды ожидают. Стейджинг без реалистичных seed‑данных или тестовых аккаунтов даёт ложное чувство безопасности. Люди кликают, видят пустые экраны и помечают сборку как нормальную. Потом в проде ломается то, что связано с запущенными клиентскими записями, истёкшими подписками или пользователями с неправильными правами.
Preview‑сборки тоже могут тратить деньги. Они дешёвы в создании и легко забываются. Через несколько недель у вас накопятся старые ветки, затёртые базы и половинчатые окружения. Кто‑то откроет неактуальную версию и заведёт баги, которые уже не имеют значения.
Ещё одна распространённая ошибка — относиться к стейджингу как к общему «ящику для барахла». Дизайнеры пытают там эксперименты, разработчики ставят побочные проекты, один человек тестирует миграцию, другой проверяет релиз. Вскоре никто не доверяет результатам, потому что окружение больше ни на что не похоже.
Решение простое: решите, для чего нужно каждое окружение, загрузите seed‑данные, отражающие реальное поведение пользователей, создайте тестовые аккаунты для случаев, которые обычно ломаются, установите срок жизни превью‑сборок и назначьте одного ответственного за очистку, исправления и правила доступа.
Владение важнее, чем команды думают. Если никто не отвечает за очистку, сломанные сборки остаются, тестовые пользователи накапливаются, и стейджинг отклоняется от production. Небольшие команды обычно лучше работают с меньшим количеством окружений, понятными правилами и одним человеком, который закрывает цикл каждую неделю.
Быстрые проверки перед созданием окружения
Прежде чем кто‑то запустит новые серверы, ответьте на несколько простых вопросов. Если ответы расплывчаты, настройка скорее всего будет стоить дороже, чем экономить.
Начните с багов, которые вы хотите, чтобы стейджинг поймал. Назовите их вслух: сломанный чек‑аут, неверные права, неудачная доставка почты или медленный запрос после изменения схемы. Если команда не может перечислить важные сбои — вы предполагаете.
Затем проверьте, насколько хрупкая сама настройка. Попросите одного инженера восстановить её с нуля по текущей документации, скриптам и процессу со секретами. Если это занимает больше дня, окружение будет дрейфовать, ломаться и превращаться в побочную работу, которой никто не захочет заниматься.
Короткий чеклист помогает:
- Можем ли мы описать несколько типов сбоев, которые это окружение должно ловить?
- Может ли один человек воссоздать его за один рабочий день?
- Соотвествует ли ежемесячная трата стоимости возможного плохого релиза?
- Покрывают ли наши тесты потоки, приносящие деньги?
- Удаляем ли мы старые окружения по расписанию?
Вопрос бюджета — это не только хостинг. Речь и о последствиях. Если провал релиза блокирует платежи или вредит данным клиентов, платить за более точную копию production обычно оправданно. Если же большинство релизов касаются контента, макета или низкорисковых админских экранов, более лёгкая настройка часто достаточна.
Пути генерации выручки требуют реального тестового покрытия. Команды часто платят за стейджинг и всё равно пропускают самые важные потоки: регистрацию, чек‑аут, продление подписки, выставление счёта и сброс пароля. Если автоматические тесты обходят эти пути, стейджинг может выглядеть безопасным, а бизнес — уязвимым.
Очистка — последняя простая проверка, которую команды пропускают. Старые превью‑сборки, неиспользуемые базы и забытые тестовые файлы тихо повышают счёт и путают QA. Введите правило истечения, чтобы устаревшие окружения удалялись вовремя.
Если два‑три пункта из списка провалились — исправьте это в первую очередь. Более простая настройка с понятными правилами лучше, чем красивая, но ненадёжная.
Что делать дальше
Большинство небольших команд ждут слишком долго, потому что каждый вариант кажется наполовину правильным. Часто это стоит дороже, чем выбор разумного дефолта и обучение на нескольких реальных релизах.
Выберите один дефолт на квартал. Для многих команд это превью‑сборки для быстрых продуктовых проверок и облегчённое стейджинг‑окружение для всего, что затрагивает общие сервисы, аутентификацию, биллинг или миграции. Если приложение ломается только в условиях продакшн‑инфраструктуры, для таких релизов переходите на полную копию.
Запишите выбор в одном коротком примечании, чтобы все могли следовать: что используется по умолчанию, какие изменения требуют дополнительных тестов, кто может запросить полнее окружение и когда настройку пересмотреть.
Опишите также сигналы, по которым следует расширяться. Будьте конкретны. Если вы видите две‑три ускользнувшие ошибки в квартал, связанные с конфигами, фоновыми задачами, миграциями данных или внешними интеграциями — это веская причина для апгрейда. Если дни релиза всё время растягиваются из‑за ручных проверок, считайте это сигналом тоже.
Отслеживайте баги и расходы в одном месте. Многие команды фиксируют ускользнувшие баги и забывают про цену окружения, или считают расходы и игнорируют время инженеров. Поместите оба показателя в одну таблицу, трекер задач или дашборд: ежемесячная стоимость стейджинга, часы на поддержку, задержки релизов и ускользнувшие баги. Смотреть на обе стороны одновременно проще для оценки компромисса.
Если выбор всё ещё неочевиден, внешний аудит может сэкономить много времени. Oleg Sotnikov на oleg.is работает со стартапами и малыми компаниями по архитектуре, инфраструктуре и AI‑ориентированным рабочим процессам — и подобные решения по стейджингу как раз в его зоне практики.
Выберите дефолт, определите триггер для более полного окружения и пересмотрите показатели через квартал. Тогда следующее решение будет основано на реальных данных, а не предположениях.


