Стоимость архитектуры MVP: почему стартапы переплачивают слишком рано
Расходы на архитектуру MVP быстро растут, когда команды копируют стеки больших компаний, рано дробят простые приложения и строят инфру до появления спроса.
Содержание
Почему на раннем этапе стоимость MVP так бьёт по бюджету
У зрелой компании может быть время пережить плохое техническое решение. У MVP такого времени обычно нет.
Если в стартапе 120 000 долларов на счету и трата 15 000 в месяц, у команды 8 месяцев на обучение. Добавьте ещё 3 000 в месяц на инструменты и облако — и остаётся около 6,7 месяцев. Это не мелкая смена хостинга. Это больше месяца потерянных экспериментов.
Урон обычно не от одной огромной покупки, а от кучи мелких платежей, которые по отдельности выглядят безобидно. Управляемая база данных, платная авторизация, логирование, мониторинг, CI, email, аналитика, feature flags, поиск и несколько сервисов ИИ могут превратить дешёвую первую версию в дорогой стек до того, как пользователи докажут, что им это нужно.
Ещё дороже стоит инженерное время. Команды часто считают работу по настройке бесплатной, потому что нет счёта. Но это тоже съедает запас средств. Если основатели тратят неделю на стыковку сервисов, исправление проблем с деплоем или изучение стека, который им мало знаком, они не разговаривают с пользователями и не выпускают изменения продукта.
Именно это замедление и вредит. Ранним продуктам нужны постоянные изменения: сократить поток регистрации, изменить шаг онбординга, новая ценовая логика, простой дашборд. При простой настройке команда может быстро тестировать такие изменения. При множестве частей даже мелкое правка может затронуть несколько сервисов, сломать интеграцию и потребовать долгого ретеста.
Поэтому ранняя сложность дорога, даже если счёт в облаке пока кажется умеренным. Она привязывает команду к медленным решениям, редким релизам и меньшему числу шансов найти product‑market fit. Стартапы редко умирают из‑за того, что один провайдер выставил счёт на несколько сотен долларов. Они гибнут, потому что потраченный впустую запас средств не оставляет времени, чтобы узнать, за что пользователи готовы платить.
Решения, которые привязывают стартап к высоким расходам
Много расходов MVP приходит от решений, которые в первую неделю кажутся умными, а к третьему месяцу — тяжёлыми. Шаблон прост: команда строит на масштаб, крайние случаи и техническую аккуратность до того, как реальные пользователи этого потребовали.
Одна распространённая ошибка — разделение продукта на множество сервисов слишком рано. Регистрация становится отдельным сервисом, биллинг — другим, уведомления получают собственного работника, поиск — отдельный стек. Позже это может иметь смысл. Для MVP с несколькими сотнями или даже тысячей пользователей это обычно означает больше хостинга, больше конфигураций, больше точек отказа и больше времени на интеграцию.
То же самое с данными. Команды создают отдельные базы данных, потому что на диаграмме это выглядит аккуратно. На практике простые продукты часто нормально работают с одной базой и понятными таблицами. При небольшой нагрузке одна надёжная база проще в управлении, дешевле в эксплуатации и легче бэкапится.
Расходы растут и когда основатели покупают инструмент под каждую проблему с первого дня. Платная авторизация до появления логинов. Хостинг логов до появления частых ошибок. Управляемые очереди до появления сложных задач. Поиск до того, как кому‑то реально нужен поиск. Система задач, которая выполняет несколько задач в час. Каждый инструмент добавляет ежемесячный счёт, время настройки, новые лимиты и ещё одну панель, которую кто‑то должен понимать в два часа ночи.
Кастомная инфраструктурная работа — ещё одна ловушка. Команде с десятью пользователями не нужна хитрая логика деплоя, мульти‑региональный фейловер или самостоятельная система событий. Такая работа может выглядеть впечатляюще, но она не помогает доказать спрос. Она задерживает обучение продукту — а это задача MVP, которую нужно выполнять быстро.
Самый дорогой выбор — подобрать стек не потому, что команда хорошо в нём работает, а потому что он популярный. Знакомый инструмент с несколькими шероховатостями обычно дешевле, чем модный стек, который замедляет каждую фичу. Если разработчики могут быстро выпускать с одной кодовой базой, одной базой данных и небольшим набором скучных инструментов — это часто правильный выбор.
Когда планирование «на будущее» превращается в мусор
Большая часть ранних архитектурных потерь идёт от строительства для будущего, которое может никогда не наступить. Команда читает статью о компании с миллионами пользователей и копирует её настройку для продукта с 50 тестировщиками.
Разрыв быстро становится дорогим. Управляемые кластеры, дополнительные окружения, сложные очереди, фейловер базы, тяжёлая наблюдаемость — всё это требует времени и денег. Хуже — добавляет движущиеся части, которые замедляют каждый релиз.
Kubernetes — частый пример. До тех пор, пока один сервер не становится явно перегружен, Kubernetes часто создаёт больше работы, чем пользы. Кто‑то должен управлять деплоем, конфигами, секретами, сетью, логами и алертами. Если трафик низкий, а приложение простое, один надёжный сервер с бэкапами и базовым мониторингом обычно делает свою работу.
Та же ошибка проявляется в планировании трафика. Основатели представляют себе пик запуска, вирусный рост или запросы от энтерпрайз‑клиентов и проектируют систему на в десять раз большую нагрузку, чем их дорожная карта может принести. Рост не приходит из архитектурных диаграмм. Рост приходит из продукта, который люди продолжают использовать.
Планировать наперёд — нормально. Строить наперёд — там, где появляется трата. Можно подготовиться к изменениям, не платя за них сейчас. Выбирайте инструменты, которые легко заменить, держите систему понятной и ждите реальной «пробки» по использованию, деплою или надёжности.
Та же логика касается отказов. Если короткий простой сбой разозлит пару тестовых пользователей, это не то же самое, что падение для тысяч платящих клиентов. Раннее важнее быстрое восстановление, а не идеальная избыточность.
Простое правило помогает:
- Решайте проблему, которая есть в этом месяце.
- Оставляйте возможность заменить один слой позже.
- Измеряйте нагрузку перед покупкой дополнительной ёмкости.
- Добавляйте операционную сложность только когда она экономит больше времени, чем стоит.
Oleg Sotnikov часто работает с командами, которые хотят корпоративную инфраструктуру до появления стабильного спроса. Его совет обычно прост: держите первую версию лёгкой, выпускайте быстрее и тратьте деньги только тогда, когда использование доказывает нужду.
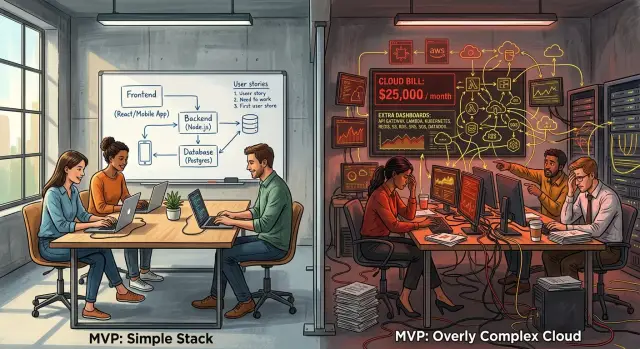
Простой стек для первой версии
Для большинства MVP самый дешёвый набор — тот, который ваша команда понимает в два часа ночи, когда что‑то ломается.
Если продукт позволяет, начните с одного приложения и одной базы данных. Одна кодовая база и экземпляр PostgreSQL могут довести многие продукты гораздо дальше, чем основатели ожидают. Вам не нужны микросервисы потому, что вы можете вырасти позже. Вам нужна настройка, которая позволяет выпускать, исправлять баги и менять продукт каждую неделю.
Хостинг важен не меньше. Выберите то, что текущая команда умеет администрировать без выделенного специалиста по инфре. Управляемый хостинг приложений, простой VM или одна небольшая контейнерная настройка часто достаточны. Если разработчики уже хорошо знакомы с одним вариантом, этот выбор обычно выигрывает у якобы «лучшего» стека, который никто из команды быстро не отладит.
Фоновые задачи тоже должны оставаться простыми. Для ранних отправок писем, отчётов, вебхуков и импортов базового job‑runner'а или воркера внутри того же приложения обычно хватает. Многие команды слишком рано прыгают на Kafka, отдельные кластеры очередей и event‑bus'ы. Это добавляет расходы, время настройки и ещё места, где простые задачи могут упасть.
Перед тем как добавлять длинный список инструментов, покройте скучные основы:
- автоматические резервные копии
- проверки доступности и трекинг ошибок
- несколько алертов на упавшие задания, высокий CPU и недостаток диска
Этот небольшой слой спасёт больше проблем, чем ещё одна платформа. Если бэкапы не работают или алерты не приходят — красивая архитектура вас не спасёт.
Держите поток данных простым для трассировки. Когда пользователь регистрируется, платит или отправляет данные, один человек в команде должен уметь проследить этот путь без открытия шести панелей и трёх репозиториев. Ранние продукты быстро меняются. Простой стек делает эти изменения дешевле.
Бережный MVP — не про экономию ради экономии. Он про покупку времени, чтобы узнать, чего хотят пользователи, прежде чем инфраструктурные расходы станут ежемесячной привычкой.
Как выбирать архитектуру пошагово
Большинство команд переплачивают потому, что проектируют под масштаб прежде, чем кто‑то знает, что пользователи будут делать на самом деле. Лучшее правило простое: стройте на первый месяц, в котором вы ожидаете выжить, а не на доклад, который надеетесь дать через год.
Запишите несколько действий, которые пользователи должны совершить в первый день. Обычно это регистрация, вход, создание одной записи, её редактирование, оплата и получение письма. Если архитектурный выбор не помогает хотя бы одному из этих действий работать хорошо — отложите его.
Потом превратите догадки в числа. Не говорите «большой трафик». Скажите «200 ежедневных пользователей, 20 одновременных, 5 ГБ загрузок, 10 писем в поддержку в неделю». Эти цифры будут приблизительными, но лучше страха. Они также связывают стоимость инфраструктуры с реальным спросом.
Простой процесс работает так:
- Перечислите пользовательские сценарии, которые должны работать в первый месяц.
- Поставьте грубые цифры на использование, файлы, фоновые задания и время поддержки.
- Выберите одну настройку, которая покрывает эти числа с запасом на небольшие ошибки.
- Проверяйте раз в месяц, выглядят ли стоимость, аптайм и скорость релизов здоровыми.
- Разделяйте сервисы только тогда, когда какая‑то часть явно замедляет команду или не выдерживает нагрузку.
Для многих команд правильная первая настройка — одно приложение, одна база, один фоновой работник и базовый мониторинг. Это часто достаточно для первой версии SaaS‑продукта. Вы выпускаете быстрее, отлаживаете быстрее и избегаете архитектурной работы, которая никогда не окупится.
Команды попадают в беду, когда рано вводят разделение. Микросервис, вторая база данных и очередь сообщений могут звучать безопасно, но каждый из них добавляет работу по деплою, алерты, точки отказа и время инженеров. Если никто не может указать на текущую узкую шею, эти части — просто плата за жильё.
Именно так опытные fractional CTO снижают расходы в облаке. Они сначала подбирают инфру под текущие потребности, затем расширяют только там, где продукт действительно нуждается. Этот порядок держит команду сосредоточенной на product‑market fit, а не на дорогих догадках.
Если пользователи растут быстрее, чем ожидалось, горячую дорожку можно выделить позже. До тех пор скучная архитектура обычно — разумный выбор.
Реальный пример от небольшой SaaS‑команды
Пятеро в команде сделали MVP для внутренних согласований. Два основателя, три инженера и никакого явного product‑market fit. Тем не менее они начали с микросервисов, управляемой очереди, Kubernetes, отдельного сервиса авторизации и нескольких окружений, потому что хотели «сделать всё правильно» с первого дня.
На бумаге всё выглядело аккуратно. На практике простые изменения быстро становились запутанными. Простая функция вроде добавления одного шага согласования затрагивала фронтенд, API, воркер, очередь и правила авторизации.
Команда тратила удивительно много времени на работу, которую пользователи не видели:
- исправление порядка деплоев между сервисами
- погоня за багами синхронизации авторизации между системами
- помощь друг другу в запуске локальных настроек
- выяснение, почему сервис работал в staging, но падал в production
Эти накладные расходы вредили больше, чем счёт за облако. Инженеры теряли часы каждую неделю на настройку и релизы, пока обратная связь от пользователей оставалась базовой. Пользователям нужны были изменения рабочих процессов, меньше кликов и простые уведомления. Для этого не требовалась сложная архитектура, но она замедляла каждый релиз.
Через несколько месяцев команда приняла жёсткое, но умное решение. Они вернулись к одному приложению с одной базой и оставили только то, чем реально пользовались. Фоновые задачи остались, но запускались внутри основного приложения. Убрали Kubernetes, отключили несколько платных сервисов и сократили инфраструктуру, добавленную для масштаба, который так и не пришёл.
Разница почувствовалась почти сразу. Локальная настройка упростилась. Деплои перестали казаться рискованными. Изменения продукта стали выходить за дни, вместо того чтобы тянуться через несколько сервисов и передачу ответственности. Счёт упал, но больший выигрыш был в скорости.
Именно поэтому стоимость MVP часто кажется несправедливой. Стартапы обычно не терпят неудачу потому, что их первая версия не выдержит 10 миллионов пользователей. Они терпят неудачу, потому что тратят время и деньги до того, как узнают, чего хотят пользователи.
Простой стек не впечатлит других инженеров так сильно, как сложная диаграмма. Но он даёт небольшой команде возможность менять направление без платы за каждую догадку.
Повторяющиеся ошибки команд
Много стартап‑траты начинается на встречах, а не в коде. Основатель слышит вопрос инвестора про масштаб, безопасность, мульти‑региональный фейловер или корпоративные контролы, и команда воспринимает это как приказ к строительству. MVP несёт расходы для клиентов, которых ещё нет.
Вопросы инвесторов важны, но они не являются требованиями продукта. Если ваш продукт тестируют десять пользователей, вам не нужна та же настройка, что у компании с десятью тысячами платящих клиентов. Команды тратят месяцы, отвечая на будущие опасения, в то время как текущие пользователи ждут базовых исправлений.
Ещё одна проблема — более человеческая, чем техническая: инженеры строят то, что хотят видеть в своём резюме. Кастомная система событий, сложный Kubernetes‑стек или раннее разделение на микросервисы могут выглядеть впечатляюще. Для молодого продукта это обычно добавляет панели, работу по деплою и способы ломать простые фичи.
Основателям нужен чёткий критерий: каждая новая часть технологии должна решать боль, которую команда уже испытывает, а не ту, которую они представляют в следующем году.
Покупка инструментов идёт не так именно по этой же причине. Команда платит за мониторинг, аналитику, feature flags, поддержку, автоматизацию и сканеры безопасности до того, как у кого‑то выстроится процесс вокруг них. Инструменты остаются полуподключёнными. Алерты никуда не уходят. Отчёты накапливаются. Счёт приходит.
Хорошая проверка скучная, и поэтому она работает:
- Кто будет пользоваться этим каждую неделю?
- Какое решение это изменит?
- Какую ручную работу это заменит прямо сейчас?
- Что случится, если мы подождём 60 дней?
Работа над надёжностью смешивается с срочным продуктовым — команды называют всё «стабильностью» и дают тому же приоритет, что и поломанной регистрации или неудавшимся платежам. Часть работы по надёжности необходима. Большая часть может подождать, пока реальное использование не покажет слабое место.
Vendor lock‑in — тихая цена, которую многие игнорируют. Хостинговый сервис может выглядеть дешево в начале, но уход позже может означать переписывание моделей данных, потоков авторизации, фоновых задач или внутренних инструментов. Это не значит избегать всех вендоров, но стоит задать простой вопрос перед покупкой: если цена удвоится, насколько болезненным будет выход?
Самая дешевая ранняя архитектура редко умна. Это та, которую маленькая команда может понять, менять и заменить без драм.
Быстрая проверка стоимости перед каждым новым решением
Большинство команд не переплачивают из‑за одной большой ошибки. Они делают это рядом мелких решений, которые по отдельности выглядят разумно. Новая ступень базы данных, инструмент логирования, очередь, второй сервис, платная авторизация, управляемый поиск — каждое решение кажется дешёвым. Вместе они поднимают расходы до того, как продукт что‑то доказал.
Простое правило: если новая технология не решает реальную проблему сейчас, относите её к будущим идеям, а не к текущим нуждам. Планировать наперёд — нормально. Платить наперёд — обычно нет.
Перед добавлением чего‑либо задайте пять простых вопросов:
- Потянет ли одно приложение следующие 12 месяцев при медленном росте трафика?
- Устраняет ли этот инструмент узкое место, которое вы уже ощущаете в этом квартале?
- Сможет ли ваша команда запустить это в 2 a.m., когда что‑то сломается?
- Если использование останется плоским на шесть месяцев, сколько будет стоить это решение ежемесячно?
- Если вы передумаете позже, можно ли убрать это без большого переписывания?
Эти вопросы проходят через много стартап‑иллюзий. Двухчленная команда часто говорит, что ей нужны микросервисы ради масштаба. На практике одно надёжное приложение, одна база и базовый мониторинг могут держать продукт гораздо дольше, чем ожидают основатели.
Третий вопрос важнее, чем думают. Инструмент, требующий редких навыков, быстро становится дорогим, даже если счёт небольшой. Если ваша команда хорошо знает Postgres, а никто не понимает Kafka, добавление Kafka создаёт операционный долг с первого дня. В экстренной ситуации знакомство побеждает элегантность.
Четвёртый вопрос показывает плохие предположения. Основатели часто моделируют стоимость под рост, но реальная проверка — плоское использование. Если полгода никто не приходит, будет ли это всё ещё разумным тратой? Тогда многие «временные» инструменты выглядят постоянными и расточительными.
Стоимость отмены — последний фильтр. Одни решения легко откатить. Другие распространяются по коду, деплою и привычкам команды. Если из‑за решения трудно откатиться, требуйте более высокого обоснования. Это держит расходы на инфре привязанными к доказательствам, а не к оптимизму.
Что делать, прежде чем добавлять ещё технологий
Когда расходы начинают расти, прекратите покупки и аудитируйте то, что уже есть. Посмотрите на каждый сервис, плагин, базу и платную платформу в стеке. Задайте жёсткий вопрос: зачем это нужно прямо сейчас?
Если ответ «возможно, понадобится позже», — сделайте паузу. На раннем этапе каждая дополнительная часть добавляет время настройки, алерты, счета и вещи, которые понимает только один человек.
Простой тест помогает. Для каждого инструмента попробуйте написать его задачу в одном предложении, кто использует его каждую неделю и что сломается в этом месяце, если вы его уберёте. Если никто не может ясно ответить — инструмент, вероятно, преждевременен.
Напишите правила апгрейда прежде, чем апгрейдить
Команды принимают лучшие решения, когда заранее задают несколько правил перед следующей покупкой или миграцией:
- Разделяйте сервис только когда отдельные релизы действительно блокируют друг друга.
- Обновляйте инфраструктуру только когда пользователи чувствуют проблему, а не когда график выглядит «занятым».
- Добавляйте новую базу данных только когда текущая реально достигает лимита.
- Покупайте автоматизацию только когда она экономит повторяющееся время команды каждую неделю.
Эти правила останавливают эмоциональные решения и делают технические дебаты короче.
Приостанавливайте любую новую покупку, пока команда не сможет просто назвать текущую узкую шею. «Деплой занимает 35 минут» — это узкая шея. «Нужно подготовиться к масштабу» — нет. «Поддержка пропускает ошибки из‑за разбросанных логов» — узкая шея. «Более сложный стек будет выглядеть серьёзнее» — это просто дорогая тревога.
Небольшая SaaS‑команда может многого добиться на одном приложении, одной базе, базовом логировании и чистом процессе деплоя. Это часто достаточно, чтобы узнать, чего хотят пользователи.
Цель проста: учиться у пользователей быстрее, чем вы тратите деньги.
Если хотите второе мнение перед добавлением технологий, Oleg Sotnikov даёт обзоры стеков как Fractional CTO и советник стартапов. На oleg.is его работа фокусируется на помощи небольшим командам держать инфру практичной, сокращать траты и внедрять ИИ так, чтобы он ускорял разработку, а не добавлял инструментов.
Часто задаваемые вопросы
Достаточно ли для MVP одного приложения и одной базы данных?
Для многих MVP — да. Одно приложение и одна база данных PostgreSQL позволяют небольшой команде быстро выпускать, отлаживать и менять функции. Разделяйте систему позже, когда какая‑то часть явно замедляет релизы или не выдерживает реальную нагрузку.
Когда стоит переходить на микросервисы?
Разделяйте только при реальной «узкой шее». Если часть продукта требует отдельного цикла релизов, достигает пределов нагрузки или постоянно вызывает сбои для остальной системы, тогда разделение может окупиться. До этого лишние сервисы обычно добавляют расходы и задержки.
Kubernetes — это слишком много для раннего стартапа?
Для большинства ранних продуктов — да, это избыточно. Kubernetes добавляет много настройки и операционной работы, которая большинству небольших команд не нужна. Если один сервер или простая контейнерная конфигурация справляется с трафиком — оставьте это и тратьте время на продукт.
За что стоит платить в первую очередь?
Начните с резервных копий, проверок доступности, трекинга ошибок и нескольких алертов. Эти инструменты помогают быстро восстановиться при проблемах. Платный поиск, сложные очереди и расширенная аналитика можно подключить позже, когда появится реальная необходимость.
Как понять, стоит ли добавлять новый инструмент?
Спросите прямо: какую проблему это решает в этом месяце? Если никто не может назвать текущую «узкую шею», инструмент, вероятно, преждевременен. Также проверьте, сможет ли команда администрировать его при аварии и убрать по необходимости без глобального переписывания.
Что дороже на ранних этапах: облачные расходы или время инженеров?
Чаще всего дороже обходится инженерное время. Небольшой счёт в облаке неприятен, но медленные релизы быстрее «съедают» запас средств, потому что команда меньше учится от пользователей. Если настройка отнимает время у основателей и разработчиков, продукт теряет ценное время.
Стоит ли проектировать на вирусный рост с первого дня?
Нет. Планируйте разумный рост, а не фантастический трафик. Делайте архитектуру, которую можно улучшить позже, но не платите за масштаб, пока люди не начнут реально пользоваться продуктом.
Как сократить расходы, не сделав продукт хрупким?
Оставляйте стек компактным, но не пренебрегайте базой. Один кодовый репозиторий, работающие резервные копии, мониторинг ошибок и простые откаты при деплое — это то, что нужно. Быстрое восстановление ценнее идеальной избыточности, когда у вас маленькая тестовая группа.
Как выглядит практичная архитектура на первый месяц?
Часто это выглядит как одно приложение, одна база данных, один background worker и базовый мониторинг. Такой набор покрывает регистрацию, платежи, отправку писем и привычные изменения продукта без горы панелей и шагов при деплое.
Как думать о vendor lock‑in на этапе MVP?
Используйте поставщиков обдуманно. Хостинг может сэкономить время на старте, но подумайте, насколько болезненен выход, если цена вырастет или сервис перестанет подходить. Если уход потребует большого переписывания — повышайте планку перед покупкой.


