SQLModel против SQLAlchemy для растущих Python-сервисов
SQLModel и SQLAlchemy: простое и понятное сравнение для команд, которые строят Python-сервисы, с разбором скорости разработки, запросов и миграций.
Содержание
Почему этот выбор становится сложнее по мере роста сервиса
В начале этот выбор кажется небольшим. Вам нужны модели, несколько таблиц и несколько API-эндпоинтов, которые умеют создавать, читать, обновлять и удалять данные без лишней церемонии. На этом этапе SQLModel против SQLAlchemy может восприниматься как вопрос вкуса.
Это ощущение быстро проходит.
Молодой сервис обычно имеет чистые данные, одну базу и небольшой набор запросов. Большинство путей в коде выглядят очевидно. Вам не приходится работать с отчётными запросами, странными join-ами, фоновыми задачами или схемой, которая уже изменилась пять раз вместе с продуктом.
Базовое CRUD-приложение скрывает многое. Первая версия таблицы клиентов проста. Шестая — уже нет. Появляются soft delete, поля аудита, история статусов, владение командами, правила биллинга и фильтры поиска. Потом кто-то просит дашборд, который тянет данные из четырёх таблиц, с сортировкой, пагинацией и правилами доступа по ролям. Вот тут ORM начинает показывать свой настоящий характер.
Когда команда растёт, это ощущается сильнее. Пока один разработчик ведёт весь проект, шероховатости остаются терпимыми. Этот человек знает обходные пути, помнит, почему поле работает именно так, и быстро чинит сломанный запрос. Когда приходит больше разработчиков, цена меняется. Новым коллегам нужны понятные шаблоны. Им важно понимать, где живёт валидация, как модели связаны с таблицами и насколько можно доверять type hints, прежде чем они упрётся в пограничный случай базы данных.
Удобство со временем тоже меняет смысл. Ход, который экономит 20 минут на первой неделе, может потом съесть часы, если через три месяца код станет труднее читать или расширять. Поэтому настоящий вопрос не в том, какая библиотека приятнее в туториале. Вопрос в том, как код ведёт себя, когда над ним работают несколько человек и у них жёсткий срок.
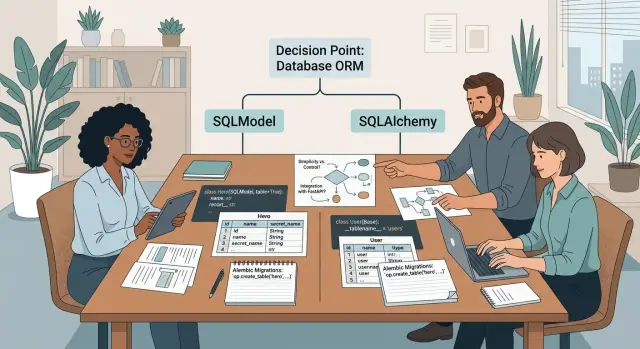
SQLModel обычно кажется дружелюбнее в первый день. Он убирает boilerplate и оставляет модели данных рядом с кодом приложения, который многие команды и так уже пишут. SQLAlchemy обычно даёт больше явного контроля, когда сервис становится тяжелее и слой запросов перестаёт быть простым.
Вот и весь tradeoff. Удобство сейчас или контроль потом. Ни один вариант не плох сам по себе. Ошибка — думать, что ваш сервис навсегда останется таким же маленьким и аккуратным, как в первый месяц.
Что даёт SQLModel в первый день
SQLModel хорошо ощущается, когда хочется выпустить первую версию до конца недели. Вы описываете поля один раз, держите валидацию и структуру таблицы рядом и переходите от идеи к рабочему CRUD-коду с меньшими усилиями.
Главная идея простая: один класс делает две задачи. Он описывает данные, которые вы принимаете в Python, и строку, которую храните в базе. Для небольшой команды это убирает много дублирования. Вам не нужно так часто следить, чтобы Pydantic-модель, ORM-модель и названия полей совпадали.
Type hints помогают больше, чем многие признают. Редактор подсказывает поля, рано ловит неправильные типы и делает рефакторинг менее рискованным. Когда приходит новый разработчик, он может прочитать модель и быстро понять, как устроена фича. Это важно в стартапе, где один человек утром может править API-код, а после обеда — логику базы данных.
Экономия времени здесь очень практичная. Вы пишете меньше файлов моделей, базовые CRUD-эндпоинты получаются короче, типы полей хорошо видны в редакторе, а простые тесты на создание или чтение легче настраиваются.
Это удобство реально. Команды, которые делают внутренние инструменты, админ-панели или ранний SaaS-backend, часто двигаются быстрее с SQLModel. Пока продукт ещё доказывает, что он вообще нужен рынку, короткий путь от идеи схемы до работающей функции имеет большое значение.
Но ограничение тоже видно довольно рано, если за ним следить. Когда запросы становятся более кастомными или когда вам нужен чёткий раздел между API-схемами и моделями базы, подход «одна модель для всего» может начать жать. На серьёзных приложениях можно строить и с SQLModel, но по мере роста сервиса абстракция становится заметнее.
Так что SQLModel — не худший вариант. Он даёт более спокойный старт. Он убирает boilerplate, хорошо работает с typed Python и делает первые релизы проще в управлении. Если сервис ещё маленький, а модель данных всё ещё меняется, это очень сильный аргумент в его пользу.
Где SQLAlchemy даёт больше пространства позже
SQLAlchemy поначалу может казаться медленнее, потому что требует большей явности. Вы аккуратнее задаёте модели, раньше думаете о связях и яснее определяете правила работы с сессиями. Эта дополнительная настройка в первую неделю может раздражать. Через шесть месяцев она часто экономит споры.
Он спокойно справляется с обычным CRUD. Если нужно вставить строку, загрузить пользователя по ID или обновить статус заказа, SQLAlchemy делает это без проблем. Разница проявляется тогда, когда запросы перестают быть простыми.
Сервис, который начинается с пользователей и проектов, часто вырастает в отчёты, права доступа, audit logs, правила биллинга и фоновые задачи. Вот тут SQLAlchemy обычно ощущается менее тесным. Сложные join-ы становятся частью обычной работы, а не тем, ради чего приходится ломать инструмент. Можно объединять несколько таблиц, добавлять фильтры на каждом шаге, выбирать только нужные колонки и при этом оставлять запрос читаемым, если команда дисциплинированно следует стилю.
Важно и поведение загрузки связанных данных. Можно выбрать, когда связанные данные загружаются сразу, когда только если код к ним обратится, а когда вообще не попадают в запрос. Это помогает избежать классической проблемы, когда один эндпоинт незаметно начинает тянуть сотни лишних строк и становится медленнее после каждой новой фичи.
Управление сессиями — ещё одна причина, почему опытные команды держатся за SQLAlchemy. Можно точно задавать границы транзакций, момент flush, повторы и то, как долго объекты остаются привязанными к сессии. Технические детали важны, потому что важен и практический результат: меньше сюрпризов, когда один запрос обновляет несколько записей и что-то ломается на середине.
Некоторым командам нравится и более явная настройка моделей, потому что она делает связи, default-значения, ограничения и типы заметнее. Новым разработчикам может понадобиться больше времени на изучение, но отлаживать обычно легче, потому что ORM меньше угадывает за кулисами.
Вот почему SQLModel против SQLAlchemy часто выглядит по-разному позже, чем в первый день. Ранняя простота приятна. Но контроль над запросами, более понятное поведение и меньше сюрпризов при миграциях обычно важнее, когда сервис растёт.
Как ощущаются миграции после нескольких релизов
После двух или трёх релизов изменения в базе перестают быть простым редактированием класса. Вы начинаете переименовывать колонки, делить одно поле на два, ужесточать правила null, переносить старые данные в новую форму. Именно здесь разницу между SQLModel и SQLAlchemy почувствовать проще.
С SQLModel изменение модели часто кажется быстрым, потому что один класс содержит и поля, связанные с API, и маппинг таблицы. На раннем этапе это приятно. Вы правите класс, запускаете Alembic и получаете черновик миграции. Проблема начинается тогда, когда одно маленькое изменение модели на деле означает три задачи сразу: изменить схему, перенести существующие данные и сохранить старые записи рабочими во время деплоя.
С SQLAlchemy команды часто держат ORM-модели и изменения схемы более отчётливо разделёнными. Кода нужно больше, и сначала это ощущается медленнее. Но такое разделение окупается, когда изменение — это не просто добавление колонки. Например, переименование обычно должно остаться именно переименованием в файле миграции. Если Alembic воспримет это как «удалить старую колонку, создать новую», вы можете потерять данные, если никто вовремя не заметит.
Alembic требует проверки в обоих случаях
Alembic полезен в обеих схемах, но autogenerate даёт черновик, а не готовую миграцию. Всё равно нужно читать каждый файл и спрашивать себя: «Это действительно то, что я имею в виду, или только то, что Alembic смог заметить?»
Файлы миграций трудно доверять, когда изменения касаются смысла, а не только структуры. Переименования колонок, изменения enum-ов, обновления default-значений, смена nullability на живых, уже неидеальных данных, а также backfill-ы и разделение полей требуют внимательной проверки.
Растущему сервису нужна история миграций, которую уставший инженер сможет понять через шесть месяцев. Ясное разделение помогает, потому что модель описывает, как код использует данные, а миграция — как база меняется со временем. Звучит как мелочь. Но это спасает от очень реальной боли, когда деплой падает на середине и кому-то приходится чинить всё под давлением.
Как выбирать шаг за шагом
Начинайте со формы приложения, а не с API ORM. Внутренний admin tool с несколькими таблицами обычно требует скорости и простых моделей. Публичный API или SaaS-продукт часто вырастает в отчётные запросы, фоновые задачи, audit trail, проверки прав и неприятные пограничные случаи. Эти требования влияют на выбор ORM намного сильнее, чем первая неделя программирования.
Потом посмотрите на горизонт в 12 месяцев. Запишите запросы, которые вы ожидаете, даже если список приблизительный. Включите обычный CRUD, фильтрованные списки, join-ы по нескольким таблицам, поиск, агрегаты, tenant scoping и массовые обновления, если они вероятны. Если большая часть работы — это простые экраны создания и чтения, SQLModel может сохранить код аккуратным. Если вы уже ожидаете кастомные join-ы и более тяжёлую логику запросов, SQLAlchemy обычно приносит меньше сюрпризов потом.
Команда важна не меньше самого приложения. Если люди, которые будут поддерживать сервис, уже хорошо знают SQLAlchemy, это должно реально влиять на решение. Знакомые инструменты экономят время каждую неделю. Если команда только начинает работать с ORM и хочет сильнее опираться на типы при меньшей настройке, SQLModel может сначала ощущаться проще. Но поддержка длится гораздо дольше, чем настройка, поэтому комфорт первого дня не должен решать всё.
Задайте себе ещё один вопрос: насколько явным вы хотите видеть код? Одним командам нужен прямой контроль над моделями, сессиями и запросами, даже если это означает больше boilerplate. Другим важнее самый короткий путь к рабочим эндпоинтам. Оба подхода работают. Боль начинается тогда, когда команда выбирает удобство сейчас, а позже ожидает полного контроля без изменения структуры кода.
Помогает простой чек-лист. Назовите тип приложения, перечислите паттерны запросов на ближайший год, отметьте, кто будет поддерживать код, и решите, что вам важнее — удобство или явный контроль. Потом зафиксируйте выбор до начала разработки. Краткой заметки в репозитории достаточно. Запишите принятый tradeoff и что станет поводом пересмотреть решение.
В случае SQLModel против SQLAlchemy лучший выбор обычно тот, который подходит сервису, который вы ожидаете видеть через год, а не демо, которое можно показать на этой неделе.
Простой пример из команды, которая растёт вместе с продуктом
Представьте небольшой SaaS API с тремя важными таблицами в первый день: users, subscriptions и reports. Приложение позволяет клиенту зарегистрироваться, подключить платный тариф и посмотреть отчёт по использованию в дашборде. Большинство запросов — обычные чтения и записи, а команде нужно быстро выпустить продукт, не дублируя одинаковые описания полей.
В такой ситуации SQLModel ощущается хорошо. Разработчик может описать модели один раз, использовать их в FastAPI и держать поля запроса и поля базы рядом. Для молодого продукта это реально экономит время. Если API нужно только создать пользователя, обновить подписку и получить отчёт по ID, код остаётся коротким и понятным.
Поэтому SQLModel часто выигрывает первый раунд. Он убирает трение, пока продукт ещё доказывает базовый спрос.
Через несколько месяцев тот же продукт перестаёт быть аккуратным. Команда добавляет фильтры вроде «покажи неуспешные платежи за последние 90 дней» и «сгруппируй отчёты по тарифу и региону». Фоновая задача начинает ночью собирать месячные отчёты. Поддержка просит admin view, где видны удалённые аккаунты, повторные инвойсы и пользователи, сменившие тариф в середине биллингового цикла.
Теперь одному экрану отчёта уже мало простой модели-запроса. Ему могут понадобиться join-ы между users и subscriptions, подзапрос для последнего платежа каждого клиента и кастомная сортировка для аккаунтов с отсутствующими данными. Другой задаче могут понадобиться массовые обновления внутри транзакции, чтобы пересчитывать отчёты безопасно.
Именно здесь выбор перестаёт быть абстрактным. Команде начинает хотеться более прямых SQLAlchemy-паттернов, потому что сам запрос становится важнее всего. Нужны видимые join-ы, фильтры и границы транзакций, а не скрытые внутри моделей, которые сначала создавались ради удобства API.
Это не значит, что SQLModel был неправильным стартом. Это значит, что приложение изменилось. Когда продукту нужны только базовые чтения и записи, удобство важнее всего. Когда накапливаются правила отчётности, фоновые задачи и крайние случаи, команды часто хотят SQLAlchemy, потому что он даёт более жёсткий контроль и меньше сюрпризов.
Ошибки, которые потом создают боль
Первая ловушка — выбрать SQLModel только потому, что ранний код выглядит короче. Это реальное преимущество, но короткие файлы моделей мало говорят о том, какие запросы понадобятся через шесть месяцев изменений продукта.
Маленький сервис может жить на простых фильтрах и вставках. Растущий сервис часто нуждается в join-ах по нескольким таблицам, частичных обновлениях, отчётных запросах и SQL, который завязан на конкретную базу данных. Если выбрать SQLModel, не проверив будущие потребности, можно в середине дедлайна внезапно начать изучать обычный SQLAlchemy.
Другая ошибка — пытаться засунуть слишком много в один класс. Команды начинают с модели для базы, а потом добавляют в неё валидацию запросов, форматирование ответа, default-значения для форм и куски бизнес-логики. Сначала это выглядит аккуратно. Позже одно изменение поля может одновременно затронуть API, админ-панель и миграцию в одном релизе.
Обычно лучше живёт более чистое разделение: модели таблиц — для таблиц и связей, API-схемы — для входа и выхода, а код запросов и бизнес-правила — вне слоя модели.
Миграции создают отдельный тип проблем. Автосгенерированные файлы экономят время, но они всего лишь черновики. Если доверять им, не читая каждую строку, можно не заметить удалённый индекс, неверный default или rename, который превратился в «удалить колонку, добавить колонку». Это может повредить данные, а не только код.
Одна команда узнаёт это на практике, когда переименовывает customer_name в full_name и выпускает сгенерированную миграцию без изменений. Релиз работает, но старые имена исчезают, потому что инструмент не распознал переименование. Потом кто-то проводит вечер, восстанавливая строки из бэкапов.
Последняя распространённая ошибка — смешивать подходы в середине проекта без плана рефакторинга. Команда начинает с SQLModel или SQLAlchemy как со стилевого решения, а потом вперемешку использует SQLModel-модели, raw SQL и обычный SQLAlchemy всякий раз, когда появляется более сложный запрос. После нескольких релизов никто уже не знает, какой подход стандартный, и каждая новая фича занимает больше времени, чем должна.
Быстрые проверки перед тем, как окончательно решить
Выбирать ORM проще, когда перестаёшь смотреть на первые две модели и представляешь сервис через шесть месяцев. Ранняя простота ощущается отлично. Но именно повторяющиеся изменения схемы, комментарии на code review и запросы на отчёты обычно решают, окупится ли эта простота дальше.
Для многих команд SQLModel против SQLAlchemy — это не столько вопрос вкуса, сколько вопроса, где вы хотите держать сложность. Можно оставить настройку короткой сейчас, а можно сделать структуру более явной сейчас и избежать уборки позже.
- Если скоро ожидаются сложные join-ы или отчётные запросы, склоняйтесь к SQLAlchemy.
- Если несколько разработчиков будут работать со слоем данных каждую неделю, выбирайте паттерны, которые остаются понятными на code review.
- Если команда не может уверенно читать файлы миграций, исправьте это до того, как начнёте оптимизировать синтаксис моделей.
- Если вам нужна жёсткая граница между API-схемами и моделями базы, SQLAlchemy вместе с отдельными Pydantic-моделями обычно остаётся чище.
- Если более явная настройка сегодня кажется чуть неудобной, это может быть хорошим знаком. Дополнительная ясность часто экономит часы после третьего или четвёртого релиза.
Помогает и простое мысленное упражнение. Представьте, что следующая admin-фича должна показать users, subscriptions, invoices и audit events на одном экране. Если уже сейчас в голове всплывают кастомные запросы, аккуратные миграции и отдельные схемы ответа, выбирайте инструмент, который делает эти части очевидными.
Команды часто недооценивают и ревью миграций. Один разработчик пишет изменение, другой его одобряет, а продакшн живёт с результатом. Если команда может прочитать миграцию и точно предсказать, что произойдёт, это хороший знак. Если нет, выбирайте схему, где меньше пространства для догадок.
Что делать дальше
Выбирайте инструмент, который соответствует форме вашего сервиса, а не только первой неделе работы. SQLModel имеет смысл, когда вам нужна быстрая настройка, более чистый код моделей и меньшая умственная нагрузка для команды, которая в основном делает стандартный CRUD. SQLAlchemy — более безопасная долгосрочная база, если вы ожидаете кастомные запросы, необычные связи, логику отчётности или поведение базы, которое со временем станет более специфичным.
Практичный способ решить — собрать одну реальную фичу в двух вариантах. Возьмите что-то слегка неудобное, а не игрушечный пример. Хорошо подойдут экран заказов с фильтрами, карточка клиента со связанными таблицами или admin-отчёт.
Сравните оба варианта на одной и той же задаче: описания моделей и валидацию, один простой запрос на чтение и один сложный join, одно изменение схемы с миграцией и настройку тестов вокруг этого.
Это упражнение скажет вам о SQLModel против SQLAlchemy больше, чем десять спорных тредов. Вы увидите, где код остаётся понятным, где начинает раздражать и где команда начинает бороться с инструментом.
И ещё один шаг перед запуском: рано подготовьте примеры миграций. Не ждите, пока production-данные заставят разбираться с этим. Добавьте миграцию, которая переименовывает поле, заполняет значение или делит одну таблицу на две. Потом напишите запрос, который точно понадобится позже, например фильтрованный поиск, пагинацию по связям или отчётный запрос с группировкой. Если уже эти примеры выглядят тяжеловато, боль не уменьшится после шести релизов.
Для большинства команд работает простое правило. Если сервис небольшой, схема всё ещё быстро меняется, а запросы скучные, SQLModel обычно достаточно. Если сервис уже важен для бизнеса или вы знаете, что слой базы станет требовательнее, SQLAlchemy чаще даёт меньше сюрпризов позже.
Если вам нужна вторая точка зрения до того, как эти паттерны закрепятся в привычку, fractional CTO-работа Oleg на oleg.is помогает с практическими вопросами архитектуры Python, миграций, инфраструктуры и AI-ассистированных рабочих процессов разработки. Такой разбор особенно полезен до того, как временный компромисс станет стандартным способом работы команды.
Часто задаваемые вопросы
С чего лучше начать: с SQLModel или SQLAlchemy для нового приложения?
Начните с SQLModel, если в приложении в основном обычный CRUD, схема данных ещё часто меняется, а команде нужна более простая настройка. Выбирайте SQLAlchemy, если уже сейчас ожидаете отчётность, сложные join-ы, фоновые задачи или более жёсткий контроль над сессиями и транзакциями.
Когда SQLModel начинает ощущаться ограниченным?
Ощущение ограничений обычно появляется, когда одна модель начинает делать слишком много. Если один и тот же класс отвечает за маппинг в базе, валидацию запросов, формат ответа и бизнес-логику, простые изменения перестают быть простыми. Сложные запросы и неудобные миграции обычно быстро показывают эту проблему.
Не слишком ли SQLAlchemy сложен для простого CRUD-приложения?
Нет. SQLAlchemy отлично справляется и с CRUD. Просто он просит более явную настройку, поэтому на старте может казаться медленнее, зато в больших кодовых базах часто проще отлаживается и развивается.
Нужны ли отдельные API-схемы и модели базы данных?
Для маленького приложения одна модель может сэкономить время. Но по мере роста сервиса отдельные схемы обычно живут дольше, потому что отделяют вход и выход API от деталей таблиц. Такой раздел делает рефакторинг и миграции понятнее.
Что лучше подходит для сложных join-ов и отчётов?
Для сложных join-ов, подзапросов, выборочной загрузки колонок и контроля транзакций SQLAlchemy обычно даёт больше свободы. Если приложению нужны дашборды, отчёты или админские экраны, которые тянут данные из нескольких таблиц, там он часто ощущается понятнее.
Как правильно работать с миграциями в обоих вариантах?
К любой миграции Alembic относитесь как к черновику, а не как к готовому изменению. Проверяйте каждую строку, особенно при переименованиях, изменении nullability, обновлении enum-ов и backfill-операциях. Неправильная миграция может повредить данные, даже если код приложения выглядит нормально.
Можно ли позже перейти с SQLModel на SQLAlchemy?
Да, но лучше не ждать, пока кодовая база станет неаккуратной. Чем дольше вы смешиваете подходы без плана, тем больше потом придётся чистить. Если вы думаете, что SQLModel может оказаться временным решением, рано разделите код запросов и API-схемы, чтобы переход был менее болезненным.
Что важнее: опыт команды или возможности библиотеки?
Выбирайте инструмент, который команда сможет поддерживать под нагрузкой. Если люди уже хорошо знают SQLAlchemy, этот опыт часто важнее, чем более короткий туториал. Если команда только начинает работать с ORM и приложение остаётся простым, SQLModel может помочь быстрее двигаться в начале.
Как проверить выбор, прежде чем окончательно на нём остановиться?
Сделайте одну реальную задачу в двух вариантах и сравните результат. Возьмите что-то немного сложное, например админский экран с фильтрами или отчёт с связанными таблицами. Включите код моделей, один сложный запрос, одну миграцию и тест. Такое упражнение быстро покажет, где код остаётся понятным, а где начинает мешать.
Что можно считать безопасным выбором по умолчанию для растущего Python-сервиса?
Если вы ожидаете растущий SaaS с отчётностью, audit trail-ами и более сложной логикой запросов, SQLAlchemy обычно безопаснее по умолчанию. Если приложение остаётся небольшим, запросы простые, а важнее всего быстро выпускать фичи, SQLModel часто более чем достаточно.


