Сократите расходы на инфраструктуру с помощью более удачных системных решений
Узнайте, почему охота за дешёвыми серверами редко окупается, и как чёткие границы, меньше сервисов и разумные настройки помогают по-настоящему снизить расходы на инфраструктуру.
Содержание
Почему низкие цены всё равно превращаются в большие счета
Низкая ежемесячная цена легко вводит в заблуждение. Сервер выглядит дешёвым, у базы данных есть бесплатный тариф, а первый счёт кажется безобидным. Потом растёт хранилище, скачет трафик, накапливаются резервные копии, и кому-то уже нужна платная поддержка, потому что в команде никто не знает, как разгрести этот беспорядок в 2 часа ночи.
Вот почему небольшие команды часто не видят настоящий счёт. Они сравнивают ценники, а не операционные расходы. Сервис, который начинается с $15, в итоге может обойтись гораздо дороже, если добавить логи, снимки, мониторинг, дополнительные регионы и время, которое люди тратят на то, чтобы всё это поддерживать.
Количество инструментов тоже важно. Каждый новый сервис добавляет настройку, правила доступа, алерты, обновления и ещё одно место, где может что-то сломаться. Одна база данных, одна очередь, один слой хостинга и одна система мониторинга часто вполне достаточны для раннего продукта. Пять отдельных сервисов могут выглядеть современно, но они же создают пять мест, где нужно искать баги, ставить патчи и платить за работу.
Плохие границы только усугубляют ситуацию. Простому продукту с несколькими экранами и умеренной базой пользователей не нужно вести себя как огромная компания. Но многие команды уже на раннем этапе делят его на микросервисы, отдельные админки, дополнительные кеши и сложные пайплайны — задолго до того, как они действительно нужны. В итоге маленькое приложение начинает вести себя как большое, со всеми затратами и без пользы.
Краткосрочные скидки редко спасают. Стартап может сэкономить 40% на три месяца за счёт кредитов или промотарифа, но это не убирает лишнее, заложенное в саму архитектуру. Если система слишком активно гоняет данные между сервисами, хранит одни и те же записи в трёх местах или зависит от инструментов, которыми никто толком не пользуется, счёт начнёт расти сразу после окончания скидки.
Если хотите снизить расходы на инфраструктуру, начинайте со структуры, а не с купонов. Более простые границы, меньше движущихся частей и разумные настройки по умолчанию обычно экономят больше денег, чем погоня за самой низкой рекламной ценой. Это менее захватывающе, чем облачная акция, но именно так маленький продукт остаётся недорогим, когда начинает расти.
Куда в первую очередь утекают деньги
Большинство команд не сливают бюджет на одной огромной ошибке. Они теряют деньги в пяти скучных местах, а потом удивляются, почему ежемесячный счёт всё время растёт. Боль в том, что каждый пункт по отдельности выглядит разумно.
Одна из частых утечек — дублирующие хранилища данных. Одна команда держит Postgres для приложения, добавляет вторую базу для аналитики, а потом поднимает Redis, потому что «вдруг пригодится кеширование». В итоге они платят за три системы, за резервные копии для всех трёх и за дополнительное время инженеров, чтобы всё это синхронизировать. Если никто не может объяснить, зачем каждый из них существует, одним предложением, скорее всего, что-то лишнее пора убрать.
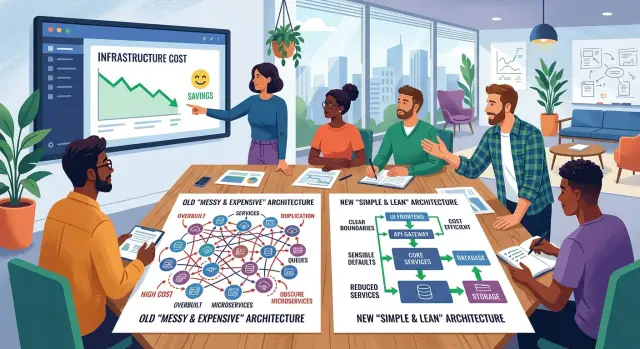
Другая утечка начинается, когда небольшой продукт слишком рано режут на множество сервисов. Сервис авторизации, сервис биллинга, сервис уведомлений и админ-сервис могут красиво выглядеть на схеме. На практике каждый сервис добавляет шаги развёртывания, логи, алерты, секреты, сетевые правила и точки отказа. Для раннего продукта один хорошо устроенный app часто дешевле и проще в обслуживании, чем шесть маленьких.
Управляемые инструменты тоже могут стоить дороже, чем ожидалось. Команды покупают hosted search, очереди, observability, feature flags и workflow-инструменты, но оставляют почти все настройки по умолчанию. Они хранят слишком много данных, берут слишком большие тарифы или платят дважды за функции, которые уже есть в другом месте. Заплатить за инструмент — это одна статья расходов. Заплатить за инструмент, который никто не настраивает, — ещё хуже.
Старое хранилище — ещё одна тихая статья расходов. Неиспользуемые тома, забытые снимки, долгий срок хранения логов и бакеты с артефактами редко ломают production, поэтому их никто не замечает. Они просто продолжают списывать деньги каждый месяц.
Полные staging-среды создают ту же проблему. Многие команды держат полную копию production днём и ночью, даже когда никто там не тестирует. Если staging нужен дважды в неделю, поставьте его на сон, уменьшите или замените часть на превью-сборки.
Обычно быстрый первый список проверок помогает найти экономию:
- Перечислите все базы данных и спросите, кто пользуется каждой из них каждый день.
- Посчитайте, сколько разворачиваемых сервисов вы держите для одного продукта.
- Откройте каждый платный инструмент и проверьте объём хранения, срок хранения данных и размер тарифа.
- Удалите не подключённые тома, старые снимки и старые логи.
- Измерьте, как используется staging, в течение двух недель, прежде чем продлевать что-либо.
Команды, которые хотят снизить расходы на инфраструктуру, часто начинают со скидок и зарезервированных инстансов. Это помогает, но архитектурные решения важнее. Обычно именно с этого и начинается первый аудит у временного CTO, потому что такой подход сокращает расходы и не тормозит команду.
Сначала проводите границы, потом добавляйте инструменты
Большинство команд слишком рано делят систему на части. Они создают API-сервис, worker-сервис, auth-сервис, cron-сервис и отдельную базу данных для каждого из них ещё до того, как появляется реальный трафик. Диаграмма выглядит аккуратно, но счёт быстро растёт.
На старте часто достаточно одного приложения и одной базы данных. Если одно web-приложение может справляться с регистрациями, биллингом, админскими задачами и базовой аналитикой, лучше оставить всё вместе. Тогда вы платите за меньшее число серверов, меньшее количество алертов, меньшее число резервных копий и тратите меньше времени на выяснение, какой сервис сломался.
Делите части только тогда, когда они меняются по разным причинам. Если клиентская панель обновляется каждую неделю, а логика биллинга — два раза в год, это позже может оправдать границу. Если всё выкатывается вместе, зависит от одних и тех же данных и имеет одного владельца, принудительное разделение обычно добавляет расходы, не решая реальной проблемы.
Фоновые задачи — частый пример. Многие команды переносят письма, импорты и генерацию отчётов в отдельный worker уже в первый день. Это имеет смысл только тогда, когда такие задачи замедляют основное приложение или требуют другого масштабирования. До этого простой job runner внутри основного приложения часто оказывается более дешёвым и спокойным вариантом.
Перед тем как создать сервис, запишите, зачем он вообще нужен. Сделайте заметку короткой:
- Что этот сервис делает такого, чего не должно делать основное приложение?
- Какая нагрузка или риск оправдывают разделение?
- Кто отвечает за него каждый день?
- Какие данные ему нужны?
- Что сломается, если он упадёт?
Эта маленькая привычка может снизить расходы на инфраструктуру сильнее, чем ещё один раунд cloud-скидок. Сервис без ясной причины обычно превращается в дополнительный хостинг, дополнительный мониторинг и дополнительное время инженеров.
Олег на практике показывает это в операциях с приоритетом на ИИ: более простые границы часто сокращают расходы сильнее, чем агрессивная охота за купонами. Стартапу с одним продуктом, одной командой и одним потоком релизов редко нужны пять отдельных сред выполнения. Начинайте просто. Делите позже, когда нагрузка даст вам понятную и скучную причину.
Выбирайте меньше сервисов осознанно
Большая часть облачных перерасходов начинается с одного небольшого решения: добавить ещё один сервис, потому что это кажется быстрее, чем исправлять то, что уже есть.
Новый поставщик может выглядеть дешёвым на бумаге. Ежемесячная цена может быть низкой или даже временно нулевой. Но настоящая стоимость проявляется позже: в настройке, алертах, логинах, счетах, продлениях, контроле доступа и во времени, которое команда тратит на изучение ещё одной панели.
Чтобы снизить расходы на инфраструктуру, выбирайте один сервис, который достаточно хорошо решает задачу, и оставайтесь с ним, пока не появится явная причина менять. Подход «лучшее в классе» часто становится ловушкой для маленьких команд. Пять отличных сервисов могут стоить больше внимания, чем один просто нормальный стоит денег.
Помогает простое правило: если новый сервис решает маленькую проблему, но создаёт новую систему, которой нужно управлять, сделайте паузу перед покупкой.
Считайте полную стоимость, а не только подписку:
- время на настройку и миграцию
- время дежурств и поддержки
- обучение команды
- точки отказа во время инцидентов
- внешнюю помощь, которая может понадобиться позже
Последний пункт важнее, чем многие думают. Если команда не может сама запустить сервис, отладить его и заменить без вызова специалиста, значит, этот инструмент, скорее всего, слишком сложный для текущего этапа.
Хороший пример — мониторинг. Если у команды уже есть одна система для логов, метрик и ошибок, добавление отдельных узкоспециализированных сервисов для каждой дыры может замедлить инциденты, а не ускорить их. Один человек смотрит в одну панель, другой — в другой инструмент, и никто не видит картину целиком. Более компактному стеку проще доверять.
Поэтому опытные технические лидеры часто специально оставляют стек скучным. Олег Сотников на практике показывал это, запуская production-системы на бережной связке инструментов вроде GitLab CI, Sentry, Grafana и Prometheus вместо того, чтобы наращивать перекрывающиеся сервисы. Смысл не в том, чтобы избегать всех платных продуктов. Смысл в том, чтобы не платить дважды за одну и ту же работу.
Если два инструмента очень похожи, выбирайте тот, который команда уже знает. Знакомые инструменты обычно экономят больше денег, чем хитрые.
Ставьте разумные настройки с первого дня
Чтобы снизить расходы на инфраструктуру, настройки по умолчанию важнее скидок. Команды перерасходуют бюджет, когда каждый новый сервер изначально слишком большой, каждый лог хранится вечно, а каждый тестовый окружение работает уже после того, как им перестали пользоваться.
Начинайте с малого и повышайте лимиты только после того, как реальный трафик докажет, что вам действительно нужно больше. Маленькому приложению в первый день редко нужны большие инстансы. Если CPU долго остаётся низким, а по памяти есть запас на две недели, оставляйте меньший размер. Многие делают наоборот: сначала покупают комфорт, а потом забывают уменьшить.
Настройки хранения тихо превращаются в ежемесячную утечку. Логи, метрики, резервные копии, артефакты сборки и снимки базы данных по отдельности кажутся недорогими. Вместе они превращаются в заметный счёт. Держите срок хранения логов коротким, если только закон или правила клиента не требуют иного. То же самое касается резервных копий. Вам не нужны шесть месяцев тестовых данных, если их никто не читает.
Простаивающие среды — ещё один частый источник расходов. Превью-сборки и тестовые серверы кажутся безобидными, но они сжигают деньги каждый час простоя. Поставьте их на расписание. Выключайте ночью, по выходным или после фиксированного периода без активности. Одна небольшая команда может заметно сэкономить каждый месяц только благодаря этому правилу.
Пути развёртывания тоже важны. Если у вас есть один pipeline для production, используйте тот же путь и для staging и превью, когда это возможно. Вторая система развёртывания часто означает дополнительные серверы, дополнительное хранилище и дополнительные ошибки. Один понятный CI/CD-путь проще поддерживать и дешевле обслуживать.
Алерты по расходам не должны прятаться в биллинговой панели, которую открывает только один человек. Выносите их туда, куда команда и так смотрит каждый день, например в чат или на почту. Поставьте несколько простых порогов и назначьте ответственного. Когда скачок расходов виден в тот же час, команды быстро его исправляют. Когда его замечают в конце месяца, деньги уже ушли.
Проверяйте стек по простой схеме
Чтобы снизить расходы на инфраструктуру, начните с простого инвентаря. Откройте биллинговую панель, менеджер паролей и облачный аккаунт. Затем выпишите все платные сервисы и одну задачу, которую каждый из них решает.
Последний пункт важен. Если инструмент делает «мониторинг, логи, алерты, дашборды и чат для инцидентов», описание слишком размыто. Разбейте его на одну понятную задачу. После этого пересечения становятся очевидны почти сразу.
Обычно лучше всего работает такой порядок проверки:
- Перечислите все сервисы, подписки и облачные продукты, за которые вы платите.
- Для каждого напишите одно предложение: что сломается, если его выключить?
- Отметьте инструменты, которые делают одну и ту же работу, даже частично.
- Сравните объём вычислений, хранения и базы данных с реальным использованием за последние 30–90 дней.
- Убирайте или понижайте по одному расходу за раз, а потом в течение недели-двух следите за ошибками, задержками и неудобствами для команды.
У большинства команд первыми находятся дубликаты. Они платят за один инструмент для логов, другой для метрик и третий потому, что одному инженеру понравилась его панель. Или продолжают держать и managed CI, и собственные runners ещё долго после завершения миграции. Счёт кажется нормальным, пока вы не сгруппируете сервисы по задаче, а не по поставщику.
Следующая победа — это размер. Многие выбирают размер инстансов и уровни базы данных в загруженную неделю, а потом больше никогда к ним не возвращаются. Через шесть месяцев трафик стоит на месте, а машины всё ещё слишком большие. С хранилищем происходит то же самое. Старые снимки, неиспользуемые тома и долгий срок хранения логов могут тихо стоить больше, чем само приложение.
Меняйте только одну вещь за раз. Если вы уберёте три сервиса за одно утро, а система начнёт шуметь, вы не поймёте, что именно вызвало проблему. Медленные изменения экономят время, потому что делают причину и следствие понятными.
Включайте в проверку и время инженеров. Более дешёвый сервис не является дешёвым, если он добавляет пять часов в неделю ручных исправлений, неудобных деплоев или запутанных алертов. Я видел, как команды экономили $200 на хостинге и теряли намного больше на времени разработчиков.
Бережливый стек проще обслуживать, проще отлаживать и ему проще доверять. Если у сервиса есть понятная задача и он действительно заслуживает своё место, оставьте его. Если никто не может объяснить, зачем он вообще нужен, начните с него.
Пример для небольшой продуктовой команды
Небольшая SaaS-команда запустилась с большим числом сервисов, чем ей было нужно. У продукта были отдельные серверы приложения, кеш, очередь, поисковый сервис и две базы данных. Каждый выбор по отдельности казался разумным, но трафик оставался умеренным, а команда инженеров — небольшой.
Счёт за облако не взлетел в первый день. Взлетела работа. Каждый деплой проходил через слишком много частей. Когда что-то начинало тормозить, команде приходилось проверять логи, workers, нагрузку на базу данных, промахи кеша, состояние поиска и шум алертов, прежде чем они находили настоящую причину.
Их стек выглядел так:
- сервис приложения для основного продукта
- кеш Redis
- worker'ы очереди для фоновых задач
- отдельный поисковый сервис
- PostgreSQL плюс вторая база данных для отчётности
Большую часть времени эти сервисы простаивали, но всё равно стоили денег каждый час. А ещё они создавали мелкие налоги повсюду: больше резервных копий, больше дашбордов, больше секретов для управления и больше мест, где релиз может сломаться.
После аудита команда серьёзно упростила стек. Они оставили один сервис приложения и одну базу PostgreSQL. Очередь заменили запланированными фоновыми задачами, которые запускались каждые несколько минут. Для поиска они использовали поиск в базе данных, потому что продукту нужны были только базовая фильтрация и совпадение по тексту.
Ежемесячный счёт снизился не потому, что команда нашла лучшую скидку, а потому, что система стала проще. Они убрали дублирующее хранилище, лишний мониторинг и простаивающие вычисления. Конфигурация, которая стоила около $1,800 в месяц, опустилась ближе к $900.
Экономия времени была не менее важной. Деплои перестали ломаться странным образом. Алертов стало меньше. Один инженер больше не тратил часть каждой недели на проверку worker'ов и поиск проблем по нескольким сервисам.
Именно так команды и снижают расходы на инфраструктуру в реальной жизни. Они проводят более удачные границы, оставляют меньше движущихся частей и рано выбирают разумные настройки по умолчанию. Иногда временный CTO видит это быстрее самой команды, потому что он не привязан к исходной конфигурации.
Ошибки, из-за которых счёт продолжает расти
Команды, которые пытаются снизить расходы на инфраструктуру, редко терпят неудачу потому, что вычисления слишком дорогие. Чаще они проигрывают потому, что продолжают утяжелять продукт, который всё ещё маленький.
Одна из самых частых ошибок — слишком рано копировать дизайн крупной компании. Молодому продукту с умеренным трафиком не нужен такой же набор сервисов, очередей, кешей, поисковых слоёв и правил развёртывания, как компании, которая обслуживает миллионы пользователей. Каждый дополнительный сервис добавляет ежемесячный счёт, работу по настройке, алерты и новые точки отказа. Дешёвые сервисы перестают выглядеть дешёвыми, когда инженеры тратят часы на их обслуживание.
Ещё одна тихая утечка — оставлять все окружения включёнными всё время. Staging, превью-приложения, тестовые системы и демонстрационные стенды часто работают днём и ночью, даже когда после работы к ним никто не прикасается. Один лишний сервер выглядит безобидно. Шесть — уже нет. Расписания, авто-сон и короткоживущие окружения часто сокращают перерасход быстрее, чем поиск более дешёвого хоста.
Команды также любят готовиться к масштабу, которого у них ещё нет. Они добавляют Redis, очередь и поисковый движок ещё до того, как измерят, где именно приложение тормозит. А потом выясняется, что настоящая проблема была в плохом запросе к базе данных, слишком больших изображениях или в слишком большом количестве API-вызовов между сервисами. Более простая архитектура обычно выигрывает, пока цифры не докажут обратное.
Наблюдаемость — ещё одно место, где мелкие перерасходы быстро превращаются в серьёзный счёт. Логи, трассировки, метрики и события об ошибках растут вместе с трафиком, повторными попытками и шумным кодом. Если никто не задаёт лимиты хранения, правила выборки и разумные дашборды, мониторинг может стоить больше, чем приложение, которое он наблюдает. Олег Сотников запускал Sentry на более чем 25 миллионах событий в день, и это очень ясно показывает: мониторингу нужны лимиты и дисциплина, а не бесконечный сбор данных.
Последняя ошибка — гнаться за более низкой ценой хостинга, игнорируя время инженеров. Экономия $80 в месяц на инфраструктуре не является победой, если команда тратит ещё пять часов на неудобные деплои, слабые инструменты или хрупкие серверы. Временный CTO обычно видит это быстро, потому что в итоговый счёт входит и зарплата, а не только cloud-инвойсы.
Паттерн простой. Большинство растущих счетов появляется из-за преждевременной сложности, постоянно включённых окружений, неограниченного мониторинга и ложной экономии. Если более дешёвый сервер каждый неделю создаёт больше работы, он никогда не был более дешёвым вариантом.
Быстрая проверка расходов на эту неделю
Вы можете заметить перерасход за 20 минут, если положите счёт за прошлый месяц рядом со списком сервисов, которыми пользуется команда. Не начинайте со скидок. Начните с пересечений, простаивающих систем и данных, которые никому не нужны. Такой аудит помогает снизить расходы на инфраструктуру сильнее, чем очередная охота за купонами.
Сначала ищите сервисы, которые делают одну и ту же работу. Многие команды добавляют один инструмент для хостинга приложения, другой для фоновых задач и третий для задач по расписанию, хотя основной хост может справиться со всеми тремя. Если один сервис может взять это на себя без лишней путаницы в эксплуатации, уберите лишний счёт.
Потом проверьте системы, которые остаются включёнными, хотя почти никто ими не пользуется. База данных для отчётности, копия staging или тестовая среда часто работают днём и ночью, даже если команда использует их всего несколько часов в неделю. Если staging нужен только в рабочее время, таймер может сократить время работы примерно на 70%.
Используйте этот короткий чек-лист:
- Отметьте каждый сервис, который дублирует другой платный сервис.
- Обведите базы данных, у которых большую часть дней низкий трафик.
- Выделите хранилище логов, к которому вы не возвращаетесь после первого дня.
- Составьте список тестовых систем, которые можно выключать ночью или по выходным.
- Спросите себя, какой сервис вы убрали бы первым, если бы счёт в следующем месяце удвоился.
Последний вопрос полезен тем, что заставляет говорить честно. Если инструмент был бы первым, от которого вы бы отказались при бюджетном шоке, значит, сейчас он, скорее всего, не нужен.
Логи заслуживают отдельного внимания. Команды часто хранят полные debug-логи, долгий срок хранения и несколько копий в разных инструментах. Это быстро становится дорогим. Оставляйте только те логи, которые реально нужны для исправления production-проблем. Уменьшайте срок хранения шумных логов и переставайте собирать данные, которые никто не читает.
Помогает простое правило: если сервис простаивает, дублируется или его игнорируют, ему нужна причина, чтобы остаться. Если никто не может назвать эту причину одним предложением, добавьте его в список на удаление уже на этой неделе.
Что делать дальше
Большинству команд не нужна большая программа по снижению затрат. Им нужно одно ясное решение. Выберите ту часть стека, которая каждый месяц создаёт больше всего перерасхода, даже если сама цифра кажется небольшой.
Это могут быть два сервиса, которые делают одну и ту же работу, CI-пайплайн, который запускается на каждое мелкое изменение, или уровень базы данных, рассчитанный на трафик, которого у вас нет. Одно такое изменение часто помогает снизить расходы на инфраструктуру сильнее, чем ещё один раунд охоты за скидками.
Прежде чем что-то менять, запишите на одной странице три вещи. Назовите текущую ежемесячную стоимость. Оцените новую ежемесячную стоимость. Затем простыми словами опишите риск, например более медленные деплои, более слабые варианты отката или меньшее пространство для скачков трафика. Если вы не можете объяснить риск просто, значит, вы пока не до конца понимаете изменение.
Короткой ежемесячной проверки достаточно для большинства небольших команд:
- Выберите только одну область: хостинг, CI/CD, observability, фоновые задачи или сторонний SaaS.
- Запишите текущую стоимость и ожидаемую экономию.
- Выберите одну метрику безопасности, например uptime, частоту ошибок или время деплоя.
- Проверьте результат через 30 дней.
Так работа остаётся честной. И это не даёт сделать обычную ошибку — изменить пять вещей сразу и ничего не понять по результату.
Когда компромиссы кажутся неочевидными, попросите опытного временного CTO о коротком ревью. Хороший внешний взгляд быстро покажет, где сложность действительно помогает, а где это просто дорогая привычка. Для этого не нужен длинный контракт. Иногда одна аккуратная проверка экономит месяцы медленного дрейфа.
Олег Сотников помогает стартапам сокращать расходы за счёт более понятной архитектуры, бережливой инфраструктуры и более простых решений по поставке. Он делал это в реальных production-системах, включая запуск глобального ПО с очень маленькой командой, усиленной ИИ, и строгой инфраструктурной дисциплиной. Если счёт продолжает расти, а причина всё ещё неясна, короткий аудит часто оказывается самым быстрым следующим шагом.


