Снизьте простои, убрав одну зависимость перед покупкой инструментов
Хотите сократить простои? Начните с удаления одной зависимости из пути запроса, а затем решите, нужны ли дополнительные инструменты мониторинга.
Содержание
Почему дополнительные дашборды не исправляют хрупкий путь
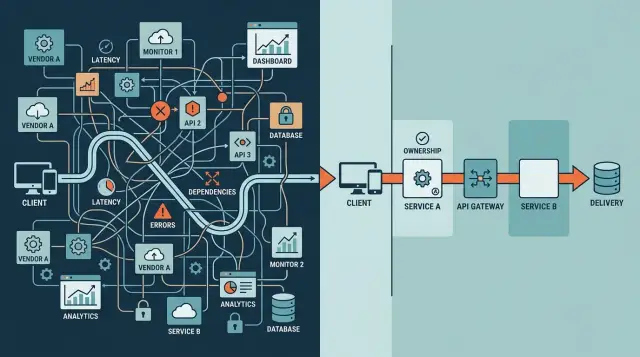
Одно действие пользователя часто проходит через больше систем, чем команда ожидает. Один клик по «Войти» или «Оформить заказ» может затронуть CDN, веб‑файрвол, сервер приложений, хранилище сессий, сервис аутентификации, систему флагов функций, очередь сообщений, базу данных и одного‑двух внешних вендора. Если какой‑то шаг зависает или возвращает неверные данные, пользователь видит одно: приложение сломалось.
Поэтому дополнительные дашборды часто кажутся полезными, но мало что меняют. Они облегчают наблюдение за отказом. Они не убирают сам проблемный переход.
Каждый добавленный сервис создаёт ещё одну возможность для таймаута, неверной конфигурации, просроченного сертификата, лимита запросов, сетевой проблемы или проблемы с биллингом. Риск растёт даже если каждый сервис кажется надёжным сам по себе. Путь с тремя шагами обычно ломается реже, чем путь с девятью. Очевидно, да, но команды всё ещё добавляют инструменты быстрее, чем убирают зависимости.
Мониторинг помогает увидеть красные индикаторы раньше. Он не сокращает путь запроса. Если ваш поток входа зависит от сторонней проверки личности, вызова фичевого флага и кэша, который должен ответить до загрузки страницы, ваша доступность зависит от всех этих компонентов. Десять аккуратных дашбордов не изменят эту математическую зависимость.
Команды часто путают видимость с безопасностью. Это не одно и то же. Аллерт может сказать, что сервис номер семь таймаутит, но пользователь уже получил ошибку. Короткий путь предотвращает простой или ограничивает ущерб меньшей частью приложения.
Возьмём страницу оформления заказа. Она может вызвать ваше приложение, налоговый сервис, инструмент борьбы с мошенничеством, сервис учёта запасов, промо‑движок и платёжный шлюз перед подтверждением успешной покупки. Если промо‑движок медлит, вся продажа может провалиться, хотя платёж прошёл. Дашборд покажет замедление. Удаление проверки промо из живого пути или перевод её в опциональную проверку может сохранить продажу.
Если вы хотите снизить простои — считайте зависимости прежде, чем покупать инструменты. Доступность обычно улучшается быстрее, когда вы убираете один хрупкий шаг, чем когда покупаете ещё один экран, чтобы наблюдать за его падением.
Как выглядит путь запроса простыми словами
Путь запроса — это полный путь от клика пользователя до ответа, который возвращает ваше приложение. Это цепочка передач. Чем длиннее цепочка, тем больше мест, где может возникать замедление, отказ или неожиданное значение.
Представьте клиента, который нажимает «Оплатить сейчас» в веб‑приложении. Запрос может пройти через браузер, слой edge или балансировщик, API‑сервер, базу данных или кэш, и один или несколько внешних сервисов для оплаты, почты или входа. Иногда очередь или вебхук обновляют финальное состояние до того, как приложение вернёт результат.
Большинство команд недооценивают длину такого пути. Одна кнопка может затронуть шесть‑семь систем, хотя на виду всё кажется простым.
Отметьте каждую третью сторону в этом потоке. Платёжные инструменты, провайдеры аутентификации, почтовые сервисы, флаги функций, аналитические скрипты, CAPTCHA и облачное хранилище — всё считается. Если у кого‑то из них плохий час, пользователь всё равно получит ошибку. Пользателя не волнует, какой вендор виноват.
Затем ищите части, которые скрывают проблему. Повторы могут удваивать или утраивать трафик, когда сервис начинает таймаутить. Очереди могут отложить проявление ошибки на несколько минут, что усложняет поиск причины. Вебхуки могут тихо проваливаться, если отправитель думает, что доставка прошла, а ваше приложение так и не обработало событие.
Важна также ответственность. Для каждого шага задайте простой вопрос: кто исправит это, когда сломается? Если никто не отвечает быстро — этот шаг уже рисковый. Ясный владелец сокращает простои. Неясный владелец создаёт путаницу в чатах, пока клиенты ждут.
Полезная карта пути запроса должна помещаться на одну страницу и использовать простые метки: «Пользователь нажал купить», «API проверяет склад», «провайдер оплаты подтверждает», «отправка письма с заказом». Если нужно гигантское поле, чтобы объяснить поток, система уже содержит слишком много движущихся частей.
Как найти зависимость с наибольшим риском
Начните с одного реального действия пользователя, а не с диаграммы системы. Выберите что‑то привычное, например вход или оформление заказа, и проследите каждый сервис, к которому обращается запрос до получения ответа.
Запишите путь простыми словами. Обычно запрос проходит через DNS, CDN, сервис аутентификации, ваше приложение, базу данных, сервис фичевых флагов и сторонний API. Посчитайте каждого внешнего вендора в цепочке. Большинство команд недооценивают это, пока не увидят весь путь на одной странице.
Затем спросите, какие части могут остановить весь ответ. Некоторые инструменты раздражают при сбоях. Другие останавливают запрос. Если страница не может загрузиться из‑за того, что сервис флагов отвечает медленно, этот сервис уже не побочный — он часть основного пути.
Короткий чеклист:
- Если сервис падает, ждёт ли пользователь или видит ошибку?
- Может ли команда обойти его менее чем за час?
- Есть ли другой инструмент, выполняющий ту же работу?
- Понимает ли кто‑то в команде, как это изменить?
Последний вопрос важнее, чем многие думают. Зависимость становится рискованной, когда никто не умеет её исправить, отключить или заменить быстро. Часто это случается с «чёрными ящиками», которые понимал только один бывший инженер, или с инструментами, где для изменений нужны тикеты в поддержку.
Дубликаты инструментов заслуживают повышенного подозрения. Два агента мониторинга, два слоя аутентификации или две очереди на бумаге кажутся безопасными. На практике они добавляют дрейф конфигураций, лишние алерты и ещё одну точку отказа. Если оба инструмента делают почти одно и то же, оставьте тот, которым команда может управлять, а второй удалите.
Небольшой аудит зависимостей обычно выявляет очевидную цель. Это часто вендор, который находится в середине каждого запроса, блокирует весь ответ при замедлении и не может быть изменён командой срочно. Уберите его первым — и вы часто сократите простои больше, чем ещё один дашборд.
Практический способ сначала убрать одну зависимость
Начните с одного пользовательского действия, которое происходит ежедневно. Выберите что‑то простое для подсчёта: вход, отправка формы или завершение покупки. Не берите редкий крайний случай, который падает два раза в месяц. Начните там, где небольшое исправление поможет многим.
Возьмите лист бумаги и нарисуйте полный путь запроса от клика до успеха. Пусть будет некрасиво и честно. Запишите каждый шаг в порядке: браузер, CDN, приложение, сервис аутентификации, база данных, очередь, почтовый вендор и всё остальное, что участвует в действии. Если шаг может замедлить запрос или вернуть ошибку — он на карте.
Теперь пометьте каждый шаг одной из четырёх меток: оставить, если действие действительно необходимо; заменить, если другая часть уже делает ту же работу; объединить, если два инструмента делят одну задачу; удалить, если никто не может объяснить, зачем он там.
Вот и есть упрощение пути запроса на практике. Меньше переходов обычно значит меньше шансов на отказ. Команды часто находят лёгкую победу: возможно сервис флагов проверяет настройку, которую приложение может читать из своей базы; возможно ещё один прокси добавляет логи и проверки безопасности, которые ваш основной edge уже выполняет.
Не режьте самый загруженный поток первым. Протестируйте короткий путь в зоне с низким риском или пропустите через него небольшой процент трафика. Малые команды могут сделать это быстро, наблюдать неделю и откатить, если нужно.
Измерьте три вещи до и после: процент ошибок, время ответа и обращения в поддержку. Добавьте краткую заметку о релизе, чтобы знать, что изменилось. Если ошибок стало меньше, страницы быстрее загружаются, и в поддержку приходит меньше «почему это упало?» — оставьте короткий путь. Если нет — откатите и протестируйте следующую зависимость.
Реалистичный пример: короткий путь работает лучше
Представьте форму регистрации в SaaS. Пользователь вводит почту, пароль и нажимает «Создать аккаунт».
Этот один клик часто делает больше, чем просто создание записи. Приложение может записать пользователя в БД, вызвать внешнее API для оценки мошенничества, создать контакт в CRM, отправить аналитическое событие, создать профиль в саппорт‑инструменте и попросить почтовый сервис прислать приветственное письмо. На бумаге каждый вызов выглядит маленьким. На практике теперь регистрация зависит от каждого из них.
Обычный поток выглядит так:
- Сохранить нового пользователя
- Проверить риск мошенничества через внешний API
- Создать контакт в CRM
- Отправить аналитическое событие
- Отправить приветственное письмо
Теперь представьте, что CRM начинает таймаутить на 12 секунд. Пользователя не волнует CRM, но запрос всё равно ждёт. Кнопка регистрации крутится, затем падает. В поддержку поступают тикеты. Команда открывает дашборды и видит таймаут, но пользователи уже пострадали, потому что путь оказался слишком длинным.
Решение часто скучно, и в этом его сила. Оставьте только шаги, которые пользователю нужны прямо сейчас: сохранить аккаунт, создать сессию и показать дашборд. Всё остальное может выполняться после ответа.
Короткий поток прост: сначала сохранение аккаунта, затем вход, а фоновые задания — позже. Обновление CRM можно делать из очереди. Приветственное письмо отправлять спустя несколько секунд. Аналитику повторять, если вендор недоступен. Если проверка мошенничества полезна, но не нужна всегда, приложению можно выполнять её после регистрации и блокировать только подозрительные аккаунты.
Разница ощущается легко. В исходном потоке таймаут одного вендора блокировал всё действие. В коротком потоке тот же таймаут превращается во внутреннюю задачу для повтора. Пользователь всё равно попадает в систему.
Так упрощение пути запроса снижает простои. Вам не нужны идеальные вендоры. Нужно меньше вендоров в части системы, которая напрямую смотрит на клиента.
Мониторинг по‑прежнему важен, но такое изменение даёт вам не очередной алерт, а путь, который продолжает работать, когда один сервис падает.
Ошибки, которые держат команды в тупике
Команды, стремящиеся снизить простои, часто предполагают, что проблема в видимости. Поэтому они покупают ещё один дашборд до того, как нарисуют полный путь запроса. Это выбор кажется безопасным, потому что новый инструмент легче согласовать, чем удаление зависимости, но он редко исправляет слабое место.
Ещё одна ловушка — сохранять вендора только потому, что одна команда выбрала его годы назад. Оригинальное решение уже никому не принадлежит, а вендор всё ещё сидит в логине, биллинге, поиске или почтовом потоке, и каждый запрос по‑прежнему ждёт его. Старые инструменты остаются дольше, чем нужна их причина.
Некоторые команды выносят бизнес‑правила в сервис, которым не управляют. Они могут хранить логику ценообразования во внешнем workflow‑инструменте или маршрутизировать проверки аккаунта через стороннюю edge‑функцию. Когда этот сервис замедляется, приложение выглядит сломанным, а команда не может починить напрямую. Они ждут, догадываются и обновляют страницы статуса.
Цепочки fallback‑ов создают другой вид хаоса. На бумаге они выглядят аккуратно. На практике часто превращают один отказ в длинный след повторов, промахов кэша, отложенных задач и дублирующих алертов. Во время инцидента никто не знает, какой шаг упал первым.
Эти паттерны часто появляются вместе:
- Команда мониторит десять переходов, но не может назвать ключевой.
- Старый вендор остаётся, потому что его сложнее убрать, чем кажется.
- Логика повторов и фолбеков скрывает реальную причину.
- Алерты доходят до многих людей, но никто не владеет исправлением.
Последний пункт важнее, чем многие признают. Наблюдение за всеми метриками не поможет, если запрос пересекает пять систем и три команды, прежде чем кто‑то сможет действовать.
Короткий путь проще объяснить, протестировать и починить. Если один человек не может за две минуты нарисовать упавший запрос и назвать, кто исправляет каждый шаг, система, вероятно, перегружена. На этом многие команды застревают.
Где мониторинг всё ещё полезен
Мониторинг окупается после того, как вы подрежете путь. Когда в запросе меньше шагов, небольшой набор проверок укажет, где начинаются проблемы за минуты, вместо того чтобы гонять людей по шести дашбордам и трём вендорам.
Когда пользователи говорят «вход не работает» или «оплата зависла», вам нужно доказательство первого падающего шага. Хороший мониторинг это показывает: начинается ли проблема на edge, в приложении, в базе данных или в одном оставшемся внешнем сервисе.
Начните с видимых пользователю сигналов
Большинство команд отслеживает слишком много и при этом пропускает то, что чувствуют пользователи. Лучше наблюдать за потоками, которыми люди реально пользуются, и выбрать несколько сигналов, привязанных к этим потокам.
Практичный набор часто включает: процент успешных основных действий, время ответа на первом эндпойнте приложения, частоту ошибок для базы данных или внешнего API в этом потоке, и глубину очереди или сбои задач, если пользователи ждут результата.
Эти сигналы полезны, потому что они указывают на сломанный поток, а не только на загруженный сервер. Сигнализируйте о паттернах отказов, которые блокируют пользователей — например падение процента успешных покупок или таймауты запросов логина в течение пяти минут. Не будите людей из‑за каждого краткого всплеска CPU или одной фоновой ошибки, которую пользователи не замечают.
Здесь имеют смысл бережные инструменты мониторинга. Продукты вроде Sentry, Grafana, Prometheus и Loki полезны, когда каждый алерт отвечает на ясный вопрос и ведёт к конкретному действию.
Оставляйте только дашборды, которые меняют решение
Дашборд должен помогать кому‑то действовать. Если график интересный, но никто им не пользуется во время инцидента — это украшение.
Применяйте простое правило для каждого дашборда: кто открывает его при поломке, какое решение он принимает и какое действие делает дальше. Если никто не ответит на эти вопросы — удаляйте дашборд или встраивайте важный график в другой вид.
Меньше экранов делает инциденты спокойнее. Люди тратят меньше времени на поиски и больше на исправление.
Быстрая проверка перед покупкой ещё одного инструмента
Многие команды покупают ещё один дашборд, когда реальная проблема сидит в пути запроса. Если ваш чек‑аут, регистрация или форма поддержки прыгают через шесть сервисов и три вендора, лучшие графики лишь покажут, где всё упало. Они не сделают систему проще.
Возьмите одно действие, которое важно пользователю, и проследите каждый вызов. Выберите что‑то простое, вроде «отправить оплату» или «создать аккаунт». Если путь выглядит перегруженным, у вас больше шансов сократить простои, убрав один шаг, чем добавляя очередной алерт.
Задайте прямые вопросы:
- Может ли действие обойтись с меньшим числом внешних вызовов?
- Есть ли у каждой зависимости ясный владелец в команде?
- Может ли команда обойти или отключить падающий вендор за считанные минуты?
- Делают ли два инструмента одну и ту же работу?
- Если один шаг замедлится, сможет ли пользователь всё равно завершить действие?
Этот обзор не займёт много времени. Один инженер, один продукт‑менеджер и белая доска часто достаточно. Пройдите путь, отметьте каждую внешнюю службу, затем обведите те, которые можно удалить, объединить или отключить в случае проблем.
Если вы ответите «нет» хотя бы на два вопроса — приостановите покупку инструмента. Сначала уберите или изолируйте одну зависимость, затем наблюдайте путь неделю. Меньше вызовов часто значит меньше алертов, меньше обращений в поддержку и короче созвоны по инцидентам.
Следующие шаги для более спокойной системы
Выберите один запрос, который сильно болит при падении: вызов оформления, поток входа, загрузка портала клиента или внутренняя админ‑операция. Запланируйте 30 минут и проследите путь от первого клика до финального ответа.
Запишите каждый переход простым языком. Включите приложение, очередь, кэш, сервис аутентификации, сторонний API, правило CDN и всё остальное, что трогает запрос. Большинство команд обнаруживает хотя бы один шаг, который добавляет риск, но даёт мало пользы.
Затем сделайте одно небольшое сокращение. Уберите сервис, который сидит в середине и не решает реальную проблему. Объедините дублирующие проверки, если они обращаются к двум системам за одним ответом. Перенесите хрупкий lookup ближе к приложению, если вы уже владеете данными. Или отключите одну опциональную проверку на неделю и посмотрите результат.
Не пытайтесь полностью переработать всё сразу. Если одно изменение укоротило путь и сохранило пользовательский опыт — это прогресс. Обычно это лучше, чем покупка ещё одного дашборда.
После изменения ведите заметки две недели. Отслеживайте количество алертов, как часто путь замедлялся, сколько длилось восстановление и стало ли дежурство проще. Числа важны, но и краткие заметки команды тоже ценны.
Запишите два списка: что улучшилось и что всё ещё мешает. Эта запись облегчит следующее решение и остановит привычную дискуссию, где каждый по‑разному помнит инцидент.
Если команда хочет второе мнение, Oleg Sotnikov at oleg.is работает со стартапами и малыми бизнесами в роли fractional CTO и советника. Его работа фокусируется на архитектуре продукта, бережной инфраструктуре и практическом внедрении AI — это подходит для такого аудита зависимостей.
Один укороченный путь запроса, задокументированный до и после, даёт вам не ещё один инструмент, а доказательство.
Часто задаваемые вопросы
Почему дополнительные дашборды не уменьшают простои?
Потому что панели показывают проблему уже после того, как пользователи её почувствовали. Если запрос зависит от слишком многих сервисов, одно замедление всё равно может сломать вход или оформление, даже если все графики выглядят нормальными.
Что такое путь запроса?
Путь запроса — это полная цепочка от клика пользователя до ответа приложения. В неё входят ваше приложение, базы данных, кэши, очереди и все внешние сервисы, которые задействованы в действии.
Как найти зависимость с наибольшим риском?
Начните с одного реального действия, например входа, регистрации или оплаты. Запишите каждый шаг в порядке выполнения на листе бумаги, затем отметьте, какие шаги могут заблокировать ответ и какие из них ваша команда не сможет быстро изменить.
Какую зависимость следует убрать в первую очередь?
Удалите шаг, который блокирует пользователя, приносит мало ценности в этот момент и не имеет быстрого обхода. Старые вендоры, дублирующие инструменты и опциональные проверки часто соответствуют этому описанию.
Должен ли каждый вызов внешнего сервиса оставаться в живом запросе?
Нет. Оставляйте только те шаги, которые пользователю действительно нужны прямо сейчас — например сохранение заказа или подтверждение оплаты. Побочные действия вроде обновления CRM, отправки аналитики и приветственной почты можно вынести из живого пути.
Стоит ли переносить часть работы в фоновые задания?
Да, если результат не нужен пользователю до завершения страницы. Очереди и фоновые работы сокращают путь и превращают таймаут вендора в внутренную повторную попытку, а не в ошибку для пользователя.
Что нужно мониторить после упрощения пути?
Следите за сигналами, которые ощущают пользователи: процент успешных действий, время ответа на первом конечном пункте приложения, частота ошибок для базы данных или внешнего API в этом потоке, и сбои фоновых задач, если пользователю приходится ждать результата. Эти метрики помогают действовать быстро, не утопая в графиках.
Нужны ли повторы и механизмы запасных вариантов?
Повторы помогают при кратких сбоях, но они также увеличивают трафик и могут усугубить плохой час. Если оставляете повторы, делайте их короткими, с жёстким лимитом и так, чтобы пользователь всё равно мог завершить действие при отказе побочного сервиса.
Как безопасно протестировать укороченный путь?
Изменяйте один распространённый поток за раз и сначала отправляйте небольшую долю трафика через короткий путь. Сравните уровень ошибок, время ответа и обращения в поддержку в течение недели, затем сохраните изменение или откатите.
Когда имеет смысл обратиться к fractional CTO за помощью?
Привлекайте внешнего специалиста, когда команда не может назвать полный путь, никто не отвечает за падающий шаг или старые вендоры стоят в середине каждого запроса. Fractional CTO поможет нанести карту, убрать одну рискованную зависимость и оставить прощеё мониторинг и меньше сюрпризов.


