Скрытые облачные расходы в логах, базах данных и простаивающих приложениях
Скрытые облачные расходы часто появляются в логах, передаче данных, управляемых базах и простаивающих тестовых окружениях. Узнайте, где растут счета и как их сократить.
Содержание
Почему счёт растёт, когда трафик остаётся прежним
Облачный счёт может увеличиваться даже при почти неизменном пользовательском трафике. Обычно причина проста: многие сервисы берут плату за хранение, копии и фоновые задания, которые работают круглосуточно вне зависимости от посетителей.
Большинство команд смотрит в первую очередь на вычисления. Размер сервера, число контейнеров и графики CPU кажутся очевидными драйверами. Это упускает большую часть расходов. Многое из потерь приходит от удобных сервисов, которые сначала кажутся дешёвыми, а потом тихо накапливаются.
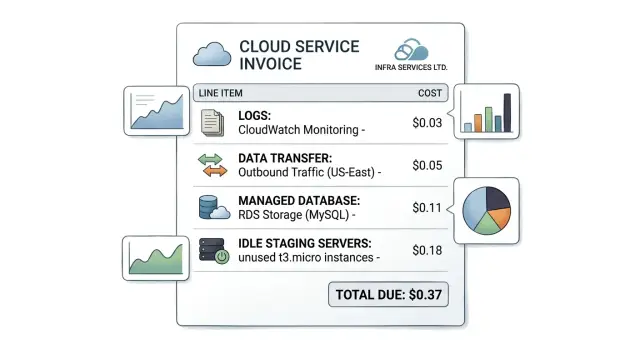
Обычные виновники знакомы: логи хранятся дольше, чем кто-то их читает. Бэкапы и снепшоты копятся, потому что значение по умолчанию не поменяли. Данные перемещаются между регионами, зонами и сторонними инструментами. Базы остаются рассчитанными на прошлый пик вместо текущего трафика. Staging и тестовые приложения работают круглосуточно.
Каждый из этих расходов сам по себе не выглядит катастрофическим. Проблема в стеке. Пара долларов в день на логи, ещё немного за передачу, растущее хранилище и база, которая не сокращается — вместе они держат счёт высоким долго после окончания активного периода.
Пиковый трафик также оставляет длинный хвост. Команда масштабируется для релиза, миграции или демо. Трафик падает, но большая база остаётся, правила хранения логов не тронули, а дополнительные окружения продолжают работать, чтобы никто ничего не сломал перед следующим выпуском.
Вот почему счёт часто кажется несвязанным с реальным использованием. Приложение может выглядеть тихим, но облачный аккаунт всё ещё выполняет работу в фоне и сохраняет данные, которые никому не нужны. Когда трафик не растёт, а счёт — да, причина редко в одной дорогой машине. Чаще это кластер мелких расходов по разным сервисам.
Логи хранят больше данных, чем нужно большинству команд
Логи сначала кажутся дешёвыми. Через несколько месяцев трафик ровный, а счёт всё равно растёт. В большинстве случаев рост — не из-за редких инцидентов, а из-за объёма и времени хранения.
Начните с хранения сырых логов. Многие команды сохраняют каждый запрос 30, 90 или 365 дней, потому что так было по умолчанию. Большинству нужны полные сырые логи только несколько дней или пару недель. После этого сводки, метрики и события ошибок обычно отвечают на те же вопросы, но стоят дешевле.
Обычные запросы и ошибки не должны храниться одинаково долго. Обычный 200-ответ с методом, путём и таймингом полезен для коротких проверок. Ошибка оплаты, падение или таймаут важны дольше. Храните вторую группу дольше и сильно урежьте первую.
Дублирование логов — ещё одна тихая утечка. Приложение пишет запрос, шлюз записывает тот же запрос, слой контейнера пишет его снова. Затем трекер ошибок хранит часть ещё один раз. Команды, которые уже используют Sentry, Grafana и Prometheus, часто нуждаются в меньшем количестве сырых логов, чем думают, потому что метрики и трейсы уже покрывают большую часть повседневной диагностики.
Отладочные логи должны иметь срок жизни. Команды включают их во время релиза и забывают на месяцы. Это быстро увеличивает расходы, потому что debug-строки шумные и постоянные. Задайте временной лимит. Отключайте их после недели релиза или делайте настройку истекающей, пока кто-то её не продлит.
Где прячется счёт за логирование
Поставщики логирования редко берут плату за что-то одно. Они берут за инжест, хранение и запросы. Можно уменьшить объём хранимых данных и всё равно переплачивать, если дашборды постоянно запускают широкие поиски.
Быстрый обзор обычно начинается с четырёх проверок:
- сколько гигабайт каждый сервис принимает в день
- как долго каждый тип логов хранится
- не поступает ли одно и то же событие из нескольких источников
- какие сохранённые запросы сканируют слишком много данных слишком часто
Это один из самых лёгких для пропуска расходов, потому что сервис кажется автоматическим. Он растёт в фоне. Одна дополнительная debug-полe в каждом запросе или один скопированный поток логов с gateway могут добавить сотни долларов, прежде чем кто-то заметит.
Плата за передачу данных появляется между обычными инструментами
Сетевые расходы часто прячутся на виду. Команда видит стабильный трафик, считает, что расходы должны оставаться прежними, а затем получает увеличенный счёт. Приложение не стало оживлённее — просто данные переместились больше и по большим путям.
Это случается, когда части стека находятся в разных регионах, зонах или даже в разных облаках. Веб-приложение в одном регионе, реплика базы в другом, объектное хранилище в третьем и внешняя аналитика создают плату на каждом переходе. Каждый шаг кажется маленьким сам по себе. Вместе они становятся одной из самых распространённых скрытых облачных трат.
Начните с картирования путей данных. Серверы приложений могут обращаться к базам через зоны или регионы. Сервисы могут вызывать друг друга много раз для одного действия пользователя. Файлы и изображения могут скачиваться снова и снова без кэширования. Бэкапы копируются в другой регион или облако. Ночные аналитические задания экспортируют большие таблицы.
«Говорящие» (chatty) сервисы заслуживают особого внимания. Если одна загрузка страницы вызывает 20 внутренних API-вызовов, и каждый вызывает одни и те же данные, затраты на передачу быстро растут. Ситуация усугубляется, когда сервисы находятся в разных зонах или сетях. Небольшая фикса, например объединение запросов или короткий кэш, может снизить и задержку, и стоимость.
Повторные загрузки создают ту же проблему. Если пользователи запрашивают одни и те же изображения, файлы или отчёты, кэшируйте их ближе к пользователям, чтобы не слать их с origin каждый раз. Это уменьшит публичный egress и обычно сделает продукт быстрее.
Бэкапы и аналитические задания тоже требуют внимания. Команды часто смотрят только на пользовательский трафик и не замечают ночные экспорты, кросс-региональные снепшоты, передачу логов и синхроны BI. Эти задания перемещают много данных без наблюдения.
Публичный egress получает максимум внимания, но приватный сетевой трафик не всегда дешев. Кросс-зонный трафик, NAT-шлюзы и межрегиональная репликация могут стоить больше, чем ожидают. Сравните оба показателя. Иногда размещение сервисов ближе экономит больше, чем гонка за чуть меньшей ценой вычислений.
Простая схема помогает: расположите все сервисы на одной странице, проведите стрелки и подпишите, кто кому отправляет данные. Дорогие части обычно видны быстро.
Управляемые базы данных остаются больше, чем нужно
Управляемая база часто сохраняет размер, который был нужен во время релиза, миграции или одного сильного пика. Через месяцы приложение спокойнее, но база всё ещё работает на том же большом инстансе, с премиальным диском и дополнительными репликами. Это одна из самых частых причин расточительства.
Обычная ошибка — смотреть на одну метрику в отрыве. CPU может быть 15%, а память при этом загружена, или хранилище выглядит дешёвым, а IOPS тащат счёт вверх. Смотрите CPU, память, хранилище и производительность диска вместе. База может казаться занятой по одной метрике и одновременно быть слишком большой в целом.
Пиковые часы важнее средних значений. Если трафик поднимается на два часа в рабочие дни, не платите за высший tier круглосуточно. Многие команды держат большие инстансы, потому что помнят одну медленную ситуацию месячной давности. Это дорогостоящая привычка.
Короткий обзор часто находит расточительство в одних и тех же местах:
- старые read replicas, оставшиеся от отчётов, тестов или заброшенных экспериментов
- хранение бэкапов дольше, чем требуют бизнес или соответствие
- премиальные диски там, где стандартного хватает
- лимиты автоскейлинга и минимальные размеры, которые никто не пересматривал после релиза
Малые SaaS-команды часто попадают в эту ловушку. Они берут большую базу «на всякий случай», добавляют реплику для отчётов и ставят долгую ретенцию бэкапов ещё до роста датасета. Через год использование ровное, а счёт отражает настройки для экстренных ситуаций, а не реальный спрос.
Эта часть стека обычно хорошо реагирует на аккуратные изменения. Начните с недели метрик по реальным пиковым часам, затем протестируйте меньший класс инстанса, меньше реплик или более дешёвые диски в безопасной среде. Если время запросов и ошибки не растут, это веский аргумент для уменьшения и в продакшне.
Простаивающие окружения сливают деньги ежедневно
Staging-сервер, к которому никто не заходил две недели, всё равно начисляет плату каждый час. То же самое — превью из старого pull request, демонстрационная база, которую никто не почистил, и балансировщик, привязанный к тестовому стеку. Простаивающие окружения легко пропустить, потому что они кажутся временными, а расходы продолжают идти как в продакшне.
Выключение ночью и по выходным обычно быстро сокращает расходы на staging. Многие команды нуждаются в staging только в рабочее время, так что нет смысла держать приложения, базы и фоновые воркеры 24/7. Если команда работает с понедельника по пятницу, автоматическое выключение убирает большую часть потерь без вреда для работы.
Preview-приложения должны иметь срок жизни. Если они остаются после тестирования, они тихо накапливаются. Один забытый preview ещё заметен, а пятнадцать — с хранилищем, логами и небольшой базой — превращаются в стабильную месячную утечку.
Демо-настройки требуют той же дисциплины. Редкое демо продаж вряд ли нуждается в полном продакшн-стеке. Один маленький инстанс приложения, крошечная база и фейковые фоновые задания часто достаточны. Клонируя продакшн под каждое демо, вы платите продакшн-цены за что-то, что работает несколько часов в неделю.
Для каждого окружения вне продакшна установите простое правило: назначьте владельца, задайте время выключения, добавьте дату истечения для preview и тест-стеков, держите минимальный размер инстанса и базы, которые работают, и удаляйте оставшиеся снепшоты, тома и балансировщики.
Остатки важнее, чем ожидают команды. Люди часто удаляют сервер и забывают об подключённом хранилище, старом снапшоте базы или публичном балансировщике с почасовой платой. Эти мелкие элементы скучны — поэтому они остаются в счёте.
Если никто не может ответить, кто владеет окружением, зачем оно нужно и когда выключается, скорее всего его не должно быть.
Как пошагово найти самое большое расточительство
Начните с данных счёта, а не с догадок. Облачный счёт может казаться случайным, но шаблоны обычно видны, если экспортировать последние три месяца в таблицу. Один месяц может обмануть релизом, инцидентом или бэкапом. Три месяца показывают, что повторяется, а что — пиковое.
Затем сгруппируйте каждые расходы так, чтобы команда могла на них влиять. Сортируйте по сервису, окружению и по команде или продуктовой области. Это даст пометки вроде production database, staging logs или internal analytics вместо одной общей суммы. Скрытые расходы часто сидят в общих аккаунтах, где никто за них не отвечает.
Далее разделите счёт на две корзины. Некоторые расходы почти не меняются месяц к месяцу, даже если трафик ровный. Другие растут и падают вместе с запросами, хранилищем или сетью. Это экономит время, потому что показывает, с чего начать. Постоянный платёж часто указывает на слишком большие базы, постоянно работающие воркеры или простаивающий staging.
Не гоняйтесь пока за крошечными экономиями. Посмотрите на десять крупнейших позиций и задайте простой вопрос для каждой: зачем это здесь и почему это так дорого? Команды часто тратят часы на экономию нескольких долларов на хранении, в то время как одна строка за логирование или передача данных съедает сотни.
Простая ритмика работает хорошо:
- выберите одну крупную статью расходов
- сделайте одно изменение
- измерьте стоимость, скорость и надёжность
- оставьте изменение, если оно помогает
- переходите к следующей статье
Держите тест чистым. Если вы сократите ретенцию логов с 90 до 14 дней, проверьте, не ухудшилась ли поддержка и отладка. Если уменьшаете класс базы, наблюдайте латентность и ошибки в течение недели.
Одно аккуратное изменение лучше пяти догадок. Так вы находите самые большие потери, не ломая те части стека, на которые люди опираются каждый день.
Простой пример от небольшой SaaS-команды
Пятеро в команде выпускают новую фичу и ожидают напряжённую неделю, поэтому включают очень подробное логирование. Каждый запрос, повтор и фоновая задача пишет дополнительные строки. Это помогает поймать две реальных ошибки быстро, но после недели релиза настройки логирования остаются прежними.
Трафик возвращается к норме. Счёт в облаке — нет. Большая часть новой траты приходит от хранения и инжеста логов, а не от большего числа клиентов. Так накапливается расточительство: временная мера безопасности превращается в месячную статью расходов.
То же происходит и с базой. Во время релиза команда переходит на более высокий managed-tier, чтобы избежать медленных запросов и лимитов. Через месяц использование спокойно, но никто не хочет трогать план базы, потому что кажется рискованным. Они продолжают платить за ёмкость, которой больше не пользуются.
Staging добавляет ещё одну утечку. Оно зеркалит продакшн, что полезно при интенсивном тестировании, но окружение работает 24 часа в сутки. Ночи, выходные и праздники проходят, а серверы приложений, фоновые воркеры и база почти простаивают.
Ещё одна статья — бэкапы. Команда хранит ночные бэкапы в другом регионе ради безопасности. Это разумно, но каждая копия добавляет плату за передачу поверх хранения. Счёт растёт немного каждую ночь, и никто не замечает, потому что расход дробится по нескольким позициям.
Простой ежемесячный обзор решает большинство проблем:
- держать подробные логи короткое время, затем возвращаться к обычной ретенции
- уменьшать размер managed-базы после окончания всплеска
- выключать staging вне рабочих часов
- подобрать расписание бэкапов под реальные потребности восстановления
Клиенты не увидят изменений в функциональности. Приложение работает как прежде. Команда просто перестаёт платить за старые решения, которые имели смысл неделю релиза и потом были забыты.
Ошибки, которые держат счёт высоким
Многие команды ищут более дешёвые серверы и пропускают медленные утечки. Вычисления легко заметить, поэтому на них направлено внимание. Между тем логи, бэкапы, снепшоты и старые данные продолжают расти.
Небольшая SaaS-команда может сократить траты на серверы на 30% и почти не заметить изменения в счёте. Почему? Они сохранили 90 дней логов, ежедневные бэкапы базы, две staging-базы и кучу старых томов. Так расточительство переживает каждую оптимизацию.
Значения по умолчанию наносят большой вред. Облачные провайдеры делают легко хранить данные дольше, копировать чаще и размещать в нескольких местах. Если никто не меняет правила ретенции, окна бэкапов или размер базы после релиза, счёт продолжит расти.
Разброс сервисов по регионам создаёт ту же проблему. Некоторые команды так делают ради «безопасности», а не потому что этого требуют пользователи. Данные двигаются между регионами, бэкапы дублируются, поддержка усложняется. Multi-region имеет смысл для некоторых продуктов, но нужна чёткая причина.
Старые ресурсы — ещё одна тихая утечка. Диски остаются прикреплёнными ни к чему. Статические IP простаивают. Тестовые базы живут после конца эксперимента. Staging работает ночью и по выходным, даже если его никто не трогает. Каждая позиция кажется маленькой, поэтому никто не занимается ею. В сумме они быстро набегают.
Проблема ответственности
Счёт держится высоким, когда обзор расходов — это ответственность всех и ни одного. Инжиниринг думает, что финансы поймают утечки. Финансы видят общие суммы, но не техническую причину. Продукт фокусируется на доставке и оставляет настройки по умолчанию.
Простое правило помогает: один человек должен просматривать расходы в облаке каждый месяц. Каждая команда должна помечать, что она владеет. Всё без владельца должно быть удалено или обосновано. Настройки ретенции и бэкапов нужно проверять после каждого крупного релиза.
Эта работа не гламурна, но она экономит реальные деньги. В многих стеках цена управляемой базы, затраты на логирование и простаивающие окружения наносят больший вред, чем один чуть больший сервер.
Быстрые проверки перед следующей оплатой
Большинство скрытых расходов не требуют полного финансового ревью. Один аккуратный проход по счёту за прошлый месяц может поймать самые большие утечки.
Начните со счёта, а не с архитектурной диаграммы. Отсортируйте расходы по сумме и сосредоточьтесь на пяти крупнейших строках. Мелочи создают шум. Крупные позиции обычно объясняют большинство сюрпризов.
Короткий чеклист:
- выпишите топ‑5 расходов за прошлый месяц с названием сервиса и суммой
- для каждой позиции спросите, зачем она и кто её владеет
- внимательно проверьте затраты на логирование: правила ретенции, объём и сохранённые запросы
- сопоставьте цену управляемой базы с реальной нагрузкой за последние недели
- выключите одно простаивающее окружение на этой неделе
Эта проверка недолгая. Небольшая SaaS-команда может сделать её за 30 минут и найти очевидную правку. Иногда сервера дешёвые, но хранение логов и поиски по ним стоят больше, чем ожидают. В других случаях staging-база почти того же размера, что и продакшн, хотя никто её не открывал всю неделю.
Быстро движущиеся команды часто пропускают это, потому что каждая позиция кажется нормальной отдельно. Именно поэтому счёт дрейфует вверх. Спросите, кто владеет каждой большой строкой, урежьте ретенцию логов, подгоните размер базы под текущий спрос и выключите одно простаивающее окружение сейчас. Следующая оплата должна отличаться.
Что делать дальше
Начните с одной строки счёта, а не со всего облака. Выберите самый шумный сервис и задайте ему жёсткий месячный бюджет. Команды обычно находят наибольшее расточительство в логах, размере базы или тестовых окружениях, которые никто не выключает.
Бюджет лучше работает, когда за него отвечает конкретный человек. Если никто не проверяет число, оно снова превратится в фоновый шум. Простое правило: когда сервис приближается к лимиту, команда проверяет ретенцию, размер инстанса и трафик между инструментами, прежде чем согласовать дополнительные расходы.
Делайте рутину скучной и регулярной. 20 минут обзора раз в месяц достаточно для многих маленьких команд. Сравните этот месяц с прошлым, отметьте изменения и запишите по одному действию на каждый сюрприз.
Некоторые правила должны быть в письменном виде, даже если помещаются на полстраницы. Храните только те логи, которые вы реально читаете или которые нужны для аудита. Уменьшайте managed-базы, когда использование остаётся низким неделями. Выключайте staging и демо по ночам или на выходных. Тегируйте каждое окружение, чтобы счёт показывал владельца. Удаляйте инструменты, которые создают лишний трафик за небольшую выгоду.
Маленькие правила останавливают повторяющиеся ошибки. Они также делают сокращение расходов менее эмоциональным, потому что команда следует политике, а не спорит по каждому счёту.
Если счёт по‑прежнему кажется запутанным, внешний обзор экономит время. Oleg Sotnikov at oleg.is работает со стартапами и небольшими компаниями как fractional CTO, помогая с архитектурой, инфраструктурой и практическими инженерными изменениями. Для команд, которые хотят сократить траты без риска для аптайма, короткий обзор часто достаточно, чтобы обнаружить большие базы, шумные логи и дорогие облачные сервисы.
Следующая оплата не должна вас удивлять. Если удивит — ужесточите одно правило и проверьте снова через 30 дней.
Часто задаваемые вопросы
Why does my cloud bill rise when traffic stays flat?
Обычно фоновые расходы продолжают расти, даже если трафик пользователей не меняется. Логи, бэкапы, снепшоты, реплики и простаивающие окружения могут работать круглосуточно и накапливать плату, пока приложение кажется тихим.
Should I check logging first when costs jump?
Да. Для многих команд логи дают быстрый выигрыш: уменьшите шумные request-логи, сократите время хранения и отключайте debug-логи после релиза.
How long should we keep cloud logs?
Для большинства команд полные сырые логи запросов нужны лишь несколько дней или пару недель. Ошибки и аудитные записи хранят дольше, если этого требуют поддержка, безопасность или соответствие требованиям.
How do I find duplicate logging?
Проверьте, не записывают ли одно и то же запрос или ошибка приложение, шлюз, контейнер и трекер ошибок одновременно. Если два-три инструмента дают ту же самую картину, сохраните один источник и сокращайте остальные.
Where do hidden data transfer fees usually come from?
Нарисуйте карту ежедневных путей данных: копии между регионами, трафик между зонами, ночные экспорты, синхроны аналитики, многократные загрузки изображений и NAT-трафик часто вызывают сюрпризы.
When should I shrink a managed database?
Когда реальные пики нагрузки остаются ниже ожидаемых несколько недель подряд. Смотрите CPU, память, хранилище и активность диска вместе, а затем протестируйте меньший класс инстанса в безопасной среде перед изменением продакшна.
Should staging stay online all the time?
Нет — если команда использует staging только в рабочие часы, лучше отключать его ночью и по выходным. Это часто сильно сокращает расход без вреда для доставки фич.
What old resources keep charging after a project ends?
Ищите старые тома, снепшоты, балансировщики нагрузки, статические IP, preview-приложения, тестовые базы и забытые реплики. Часто удаляют сервер, но оставляют подключённое хранилище или другие ресурсы.
What is a simple monthly cloud cost review?
Экспортируйте три последних месяца счёта и отсортируйте по сумме расходов. Затем выясните, кто владеет каждой крупной статьёй и зачем она нужна сейчас.
When should a small team ask for outside help with cloud costs?
Когда счёт кажется запутанным, у команды нет времени или никто не уверен в безопасных изменениях. Короткий аудит от опытного CTO помогает найти большие источники переплаты — громкие логи, большие базы и простаивающие сервисы.


