Шаблоны задач Tokio, чтобы избежать скрытой конкуренции в Rust
Шаблоны задач Tokio для общего состояния, обратного давления в каналах и отмены, которые помогают асинхронному Rust оставаться отзывчивым при смешанной CPU- и I/O-нагрузке.
Содержание
Почему асинхронный Rust замедляется в реальных сценариях
Сервис на асинхронном Rust может выглядеть здоровым ровно до того момента, когда пользователи начинают замечать замедление. Загрузка CPU остаётся умеренной, задачи продолжают опрашиваться, логи идут потоком, но один занятый mutex или одна переполненная очередь заставляют всё ждать своей очереди.
Именно поэтому такие проблемы так хорошо прячутся. Ничего не обязано падать. Запросы всё равно завершаются. Но задержка незаметно растёт с 20 мс до 200 мс, глубина очереди увеличивается, а пропускная способность становится неровной. Один worker выглядит перегруженным, а другие в это время просто ждут.
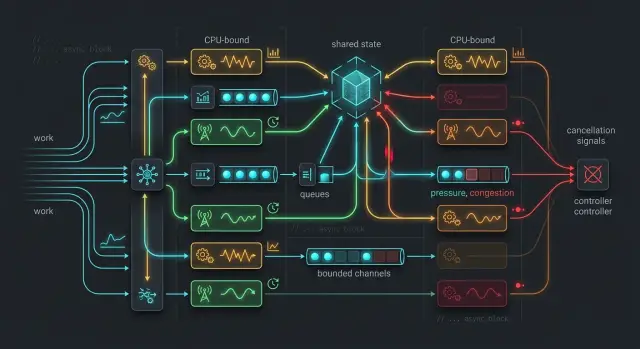
Смешанная CPU- и I/O-нагрузка очень быстро выявляет мелкие узкие места. Задача может прочитать данные из сети, распарсить полезную нагрузку, обновить общее состояние и записать что-то в хранилище. По отдельности каждый шаг кажется дешёвым. Под нагрузкой паузы складываются. Короткое удержание lock превращается в очередь ожидающих задач. Ограниченный канал заполняется. Медленный потребитель ниже по потоку делает задачи выше по потоку занятыми, даже когда на самом деле они в основном заблокированы.
Один распространённый случай сначала выглядит безобидно. Обработчик запроса записывает метрики в общее состояние, кладёт задачу в канал, а потом ждёт ответа от базы данных. Если lock для метрик остаётся занятым чуть дольше, отправка происходит позже. Если канал почти заполнен, отправка ждёт. Пока этот запрос ждёт, приходят новые запросы и повторяют тот же сценарий. Приложение всё ещё работает, но теперь движется со скоростью самого медленного общего узла.
Обычно симптомы появляются вместе:
- задержка растёт ещё до того, как CPU выходит на максимум
- очереди увеличиваются, хотя задачи кажутся активными
- одни запросы завершаются быстро, а другие зависают
- пропускная способность идёт рывками, а не остаётся стабильной
Хорошие шаблоны задач Tokio помогают держать работу в движении, не превращая код в научный проект. Цель проста: держать общие участки короткими, не врать о состоянии очередей и останавливать работу раньше, если результат уже никому не нужен. Этого часто достаточно, чтобы асинхронный Rust снова стал быстрым под реальным трафиком.
Где начинается скрытая конкуренция
Скрытая конкуренция обычно начинается в коде, который выглядит безобидно. Один Mutex вокруг map, кэша или реестра соединений кажется простым и часто нормально работает при небольшой нагрузке. Потом одна задача держит эту блокировку чуть дольше, пока читает, обновляет данные или ждёт чего-то ещё. Остальные задачи выстраиваются за ней в очередь, и задержка скачет, хотя CPU выглядит нормальным.
Это часто случается с общим состоянием в Tokio. Обработчик запроса проверяет кэш, обновляет состояние соединения, пишет метрики и трогает map сессий. Каждый шаг по отдельности маленький. Но если всё это находится за одним горячим lock, десятки задач начинают ждать у одной узкой калитки.
Чаще всего это проявляется в таких местах:
- общий hash map для состояния по пользователям
- кэш, где чтение, запись и вытеснение живут под одним lock
- менеджер соединений, который ведёт сокеты, повторы и проверки связи вместе
- задача, которая захватывает состояние, а потом делает async-работу до его освобождения
Каналы создают другой тип пробки. Один медленный получатель может затормозить многих быстрых отправителей, особенно когда производители работают параллельно. Отправители продолжают что-то делать, отправлять сообщения и будить друг друга. С виду всё занято, но полезная работа падает, потому что узким местом становится очередь.
Неограниченные каналы делают ситуацию ещё хуже, потому что какое-то время скрывают проблему. Ничто не блокируется, и система кажется здоровой. Потом растут память, задержка в очереди, а старые сообщения всё быстрее теряют актуальность. К тому моменту, как вы это замечаете, накопленный хвост уже изменил поведение системы.
Ошибки отмены добавляют ещё один слой. Долгая задача, которая игнорирует завершение, продолжает работать после того, как остальной системе пора остановиться, перезагрузиться или сбросить нагрузку. Она может продолжать держать permit, заполнять очередь или повторять работу, которая больше никому не нужна. В смешанных сценариях такая устаревшая работа съедает время у свежих запросов.
Если под нагрузкой вы видите случайные зависания, ищите места, где многим задачам приходится ждать одну общую вещь: один lock, один получатель, одну очередь или одну задачу, которая не хочет завершаться. Обычно именно там и начинается скрытая конкуренция.
Общие данные без пробки
Большая часть медленного кода на Tokio тормозит не потому, что async сам по себе медленный. Он замедляется из-за того, что слишком много задач трогают одни и те же данные одинаковым образом.
Частая ошибка — сложить всё в один общий Arc<Mutex<AppState>> и дать каждой задаче брать его в работу. Сначала это кажется аккуратным. Под нагрузкой превращается в очередь у входа.
Лучше работает чёткое владение. Если одна задача обновляет очередь заданий, пусть эта задача и владеет очередью. Если другой задаче нужен только конфиг, дайте ей дешёвую копию конфига вместо доступа ко всему объекту состояния. Хорошие шаблоны задач Tokio обычно начинаются с вопроса, кто должен владеть каждой частью данных, а не как поделить всё сразу.
Разделяйте часто изменяемые данные и «холодные» данные. Например, счётчик запросов, map активных сессий и очередь работы меняются постоянно. Статический конфиг, флаги функций и шаблоны почти не меняются. Держите их в разных структурах, чтобы горячий lock не блокировал чтение, которое должно быть дешёвым.
Не меньшее значение имеет и область действия блокировки. Возьмите lock, скопируйте или обновите нужное и отпустите его до любого await. Если держать блокировку во время сетевого I/O, дискового I/O или отправки в канал, которая может ждать, остальные задачи будут простаивать без причины.
На практике хорошо работает небольшой шаблон:
- одна задача-владелец обрабатывает записи для общего ресурса
- другие задачи отправляют запросы через канал
- читатели получают снимки или копии данных только для чтения
- атомарные переменные отслеживают простые счётчики и флаги остановки
Передача сообщений часто проще, чем общий lock, если записи должны идти по порядку. Одна задача-записыватель может обновлять состояние, объединять работу в пакет и сохранять согласованность без борьбы множества задач за mutex.
Атомарные переменные помогают, но только для маленьких задач. Используйте их для счётчиков, флагов здоровья или сигнала завершения. Не стройте на атомарных переменных сложную машину состояний, если не любите разбирать странные гонки в 2 часа ночи.
Хорошая проверка простая: если десять занятых задач проснутся одновременно, смогут ли они сделать большую часть работы, не ожидая одну и ту же блокировку? Если нет, разделите состояние ещё раз.
Шаг за шагом: перерабатываем горячий участок
Горячий участок обычно замедляется по простой причине: слишком много задач трогают одно и то же состояние, а один медленный шаг заставляет остальных ждать. Хорошие шаблоны задач Tokio начинаются с владения, а не с добавления новых задач.
Возьмите один запрос и проследите его от начала до конца. Запишите каждую задачу, которая выполняется, какие данные она читает и какая задача имеет право записывать каждую часть состояния. Если две или три задачи могут менять один и тот же map, кэш или набор счётчиков, у вас уже есть пробка.
Затем проверьте каждую блокировку по жёсткому правилу: никакого парсинга, никаких сетевых вызовов и никакого дискового I/O, пока lock удерживается. Эти шаги могут задержаться куда сильнее, чем вы думаете. Mutex вокруг маленького обновления map — это нормально. Mutex вокруг «распарсить, получить, обновить, сохранить» — это место, где пропускная способность рушится.
Часто рефакторинг выглядит так:
- Держите парсинг на собственных данных вне lock.
- Перенесите общие записи в одну задачу-владелец, которая принимает команды.
- Если одна задача-владелец становится слишком занятой, разделите состояние по user ID, tenant ID или другому стабильному признаку.
- Поместите ограниченный канал между быстрыми производителями и более медленным записывателем.
- Воспринимайте заполненный канал как сигнал, а не как проблему, которую нужно скрыть.
Представьте API-воркер, который принимает полезную нагрузку, парсит JSON, обновляет map в памяти и пишет запись аудита. В медленной версии каждый воркер блокирует map, парсит внутри критической секции, а потом ждёт дисковый I/O, прежде чем отпустить lock. В лучшей версии воркер сначала парсит данные, создаёт небольшое сообщение об обновлении и отправляет его в выделенную задачу, которая владеет map и записью аудита. Остальные воркеры остаются свободны и могут обрабатывать новые запросы.
Ограниченный канал важен, потому что превращает перегрузку в заметное давление. Если производители могут отправлять бесконечно, память растёт, а задержка ведёт себя странно. Если у канала фиксированный размер, производители замедляются, когда потребители не успевают. Это проще объяснить и намного проще исправить.
Измеряйте до и после, иначе вы просто гадаете. Два показателя быстро расскажут всю историю:
- глубина очереди во времени
- время ожидания блокировки под нагрузкой
- задержка
send()в ограниченном канале - задержка запросов по p95 или p99
Если рефакторинг сработал, время ожидания lock уменьшается, глубина очереди перестаёт бесконечно расти, а всплески задержки становятся короче. Если очередь всё ещё растёт, задача-владелец по-прежнему слишком широкая. Разделите её ещё раз или уменьшите работу, которую вызывает каждое сообщение.
Как справляться с давлением в канале
Канал, который никогда не создаёт обратного давления, может долго скрывать перегрузку. Приложение вроде бы всё ещё «работает», но память растёт, задержка ведёт себя странно, а воркеры тратят больше времени на догоняние, чем на полезную работу. В Tokio ограниченные каналы обычно безопаснее по умолчанию, когда производители могут обогнать потребителей.
Небольшой буфер заставляет выбрать политику заранее. Это кажется жёстким, но лучше, чем потом выяснить под нагрузкой, что один быстрый производитель может залить весь процесс.
Выберите политику до того, как очередь заполнится
Когда ограниченный канал переполняется, коду нужно чёткое правило.
- Ждать, если важен каждый элемент и допустимы короткие задержки.
- Отбрасывать, если новые данные делают старые бесполезными, например при частых обновлениях интерфейса или метрик.
- Объединять, если можно собрать много маленьких обновлений в один пакет.
- Сбрасывать работу, если система уже опаздывает и дополнительные задачи только замедлят восстановление.
Разным сценариям нужны разные решения. Событие биллинга, скорее всего, должно ждать. Поток обновлений «пользователь печатает», скорее всего, должен отбрасываться или объединяться.
Контрольным сообщениям нужна своя полоса. Если stop, reload или health-сигналы стоят за тысячами массовых задач, система кажется зависшей, даже если код корректен. Используйте один канал для управления и другой для данных, чтобы маленькие сигналы оставались быстрыми.
Размер полезной нагрузки важнее, чем многие команды ожидают. Если каждое сообщение несёт большой struct или копию данных, очередь становится дорогой ещё до того, как станет длинной. Отправляйте ID задачи, маленькую команду или shared pointer вроде Arc<T>, когда это подходит. Пусть воркер забирает полные данные только тогда, когда начинает задачу.
За давлением нужно следить и во время нагрузочных тестов, а не только после релиза. Два показателя говорят очень многое: как долго ждёт send() и насколько глубокой становится очередь во время всплесков. Если вы уже собираете runtime-метрики с помощью Prometheus и Grafana, постройте графики для обоих. Очередь, которая минутами почти полная, — это уже не буфер. Это линия задержки.
Хорошие шаблоны задач Tokio делают перегрузку заметной заранее. Это даёт время замедлить производителей, сократить объём работы или разделить горячие пути ещё до того, как пользователи почувствуют зависание.
Отмена, которая действительно останавливает работу
Отмена не срабатывает, если она останавливает только родительскую задачу. Дочерние задачи продолжают опрашиваться, циклы повторных попыток продолжают просыпаться, а завершение работы затягивается. Один из самых полезных шаблонов задач Tokio прост: создайте один token отмены вверху и передайте его во все порождённые задачи.
Общий token даёт всем задачам один и тот же сигнал остановки. Если отменить только обработчик запроса, фоновый воркер может всё ещё держать lock или продолжать читать из очереди. Такой «полузавершённый» shutdown и создаёт зависания, которые люди потом винят в async Rust.
use tokio::select;
use tokio_util::sync::CancellationToken;
async fn worker(token: CancellationToken) {
loop {
select! {
_ = token.cancelled() => break,
_ = do_one_unit_of_work() => {}
}
}
}
Проверять отмену один раз за цикл — хороший старт, но часто этого мало. Если тело цикла делает три дорогих шага, проверяйте между ними. Задача, которая получает данные, парсит их и записывает дальше, должна уметь остановиться между каждым шагом. Это может сократить время завершения с секунд до нескольких миллисекунд.
Код повторных попыток нуждается в том же подходе. Типичная ошибка выглядит безобидно: при ошибке подождать 5 секунд и попробовать снова. Во время завершения такая задача всё равно ждёт весь сон, если не заставить sleep соревноваться с отменой. У фонового опроса та же проблема. Если началось завершение, перестаньте опрашивать сразу.
Порядок тоже важен. Обычно безопасна такая последовательность:
- отменить корневой token
- остановить новый вход, закрыв отправителей или слушатели
- дать воркерам закончить ту маленькую часть работы, которую они уже начали
- дождаться дочерних задач
- быстро отказаться от очистки, которая не нужна для корректности
Если ждать задачи до закрытия их очередей, они могут вечно сидеть на recv(). Если выполнять тяжёлую очистку после отмены, завершение работы само становится узким местом. Сохраняйте только то, что действительно нужно для согласованности. Пропускайте очистку кэша, большие пакетные записи и всё, что можно восстановить позже.
Это часто проявляется у небольших продакшен-команд. Сервис весь день нормально держит нагрузку, а во время деплоя внезапно зависает, потому что старые задачи так и не остановились по-настоящему. Быстрое завершение — это часть производительности runtime, а не отдельная тема.
Реалистичный пример смешанной нагрузки
Представьте сервис на Tokio, который принимает входящие запросы, получает дополнительные данные из внешнего API, парсит ответ, обновляет кэш и пишет финальную запись в хранилище. На бумаге каждый шаг выглядит нормально. Под нагрузкой такие сервисы часто замедляются так, как не видно на маленьких тестах.
Частая ошибка — держать и кэш, и запись за общими блокировками. Один запрос быстро обогащается данными, а потом натыкается на медленную запись. Пока эта задача ждёт хранилище, она держит lock дольше, чем должна. Ещё несколько запросов накапливаются за ней. И вот уже быстрые запросы начинают ждать медленные, хотя сам поиск в кэше почти ничего не занимает.
Исправление — отдать владение тем задачам, которым оно нужнее всего. Держите lock кэша коротким и узким: прочитайте нужное, скопируйте данные и сразу отпустите lock. Не позволяйте записи в хранилище сидеть за тем же общим состоянием.
Лучший вариант выглядит так:
- задачи запросов читают или обновляют небольшой кэш с очень коротким временем удержания lock
- задачи запросов отправляют готовые записи в ограниченный канал
- одна задача-записыватель владеет клиентом хранилища и выполняет записи по порядку
- небольшой пул воркеров обрабатывает тяжёлый CPU-парсинг
Этот ограниченный канал важен. Если хранилище замедлится, очередь заполнится и начнёт тормозить вызывающих. Это гораздо лучше, чем позволить памяти расти без ограничения или создавать больше работы, чем машина может завершить.
Парсингу тоже нужен свой предел. Если каждый запрос парсит большой payload прямо на async runtime, задержка очень быстро становится рваной. Используйте фиксированный пул воркеров или ограничьте парсинг семафором, чтобы одновременно работало только небольшое число парсинговых задач. Остальные запросы всё равно смогут двигаться дальше, пока эти воркеры заняты.
К отмене нужен такой же внимательный подход. Во время деплоя вы хотите, чтобы работа в полёте останавливалась чисто, а не зависала до тех пор, пока случайно не опустеют все очереди. Дайте токены отмены и задачам запросов, и задачам воркеров. Если началось завершение, перестаньте принимать новые запросы, перестаньте отправлять новые элементы в задачу записи и позвольте ей завершить только те записи, которые уже у неё в работе. Остальное отбрасывайте явно.
Этот шаблон прост, но хорошо держится под смешанной нагрузкой. Медленные записи изолированы, парсинг ограничен, а отмена действительно выполняет работу, а не существует для галочки.
Ошибки, которые приводят к зависаниям
Плохие шаблоны задач Tokio часто выглядят безобидно на ревью, потому что каждый по отдельности кажется мелочью. Под смешанным трафиком они складываются и превращают короткие ожидания в очереди.
Одна ошибка встречается постоянно: обработчик запроса берёт lock, а потом попадает на await до того, как отпустит его. Пока задача ждёт вызов базы данных или другой сервис, все остальные задачи, которым нужно то же состояние, стоят в очереди. Держите заблокированную часть короткой. Скопируйте нужное, отпустите блокировку, а потом уже делайте await.
CPU-работа создаёт другой тип зависания. Если задача парсит большой файл, хэширует крупную полезную нагрузку или крутит длинный цикл прямо на async runtime, она отнимает время у задач, которым нужен только быстрый poll. Tokio может скрывать это на лёгких тестах. В продакшене это уже не пройдёт. Перенесите тяжёлую работу в spawn_blocking или в ограниченный пул воркеров и задайте предел тому, сколько может работать одновременно.
Ещё одна простая ошибка — запускать крошечные задачи для работы, которая спокойно помещается в один вызов функции. Каждый spawn добавляет накладные расходы на планирование, больше пробуждений и больше мест, где отмена начинает вести себя грязно. Если работа короткая и ей не нужна собственная жизнь, вызывайте функцию напрямую.
Один глобальный канал может вредить не меньше. Команды часто отправляют логи, повторы, фоновые задания и пользовательскую работу через одну очередь, потому что это кажется простым. Потом один всплеск заполняет канал, и несвязанные задачи начинают ждать. Разделяйте трафик по назначению или приоритету и по возможности используйте ограниченные каналы, чтобы давление проявлялось раньше.
Повторы могут тихо превратить медленную зависимость в полную остановку сервиса. Если один downstream API начинает тормозить, а код бесконечно повторяет попытки без ограничения, нагрузка быстро умножается. Добавьте backoff, задайте бюджет повторов и остановитесь после ясного лимита.
Короткая проверка ловит большинство таких проблем:
- Найдите любой
awaitвнутри заблокированного участка. Если задача держитMutexилиRwLockи потом ждёт I/O, sleep или другую задачу, по возможности вынесите этотawaitза пределы lock. - Осознанно проверьте ёмкость каждого канала. Неограниченные каналы могут скрывать проблему, пока не вырастет память. Слишком маленькие ограниченные каналы могут весь день тормозить производителей. Выбирайте размер по реальному трафику, а не наугад.
- Прочитайте каждый фоновый цикл и убедитесь, что он умеет останавливаться. Циклу, который ждёт только
recv()илиsleep(), нужен сигнал завершения, token отмены или путь через закрытый канал. - Найдите CPU-тяжёлую работу и посчитайте, сколько её можно запускать одновременно. Парсинг больших payload, сжатие, работа с изображениями и большие преобразования JSON не должны скапливаться на worker threads Tokio.
- Убедитесь, что в метриках видны глубина очереди, ожидание lock и время выполнения задачи. Если задержка скачет, вам нужно понимать, ждали ли задачи lock, сидели ли в очереди или просто работали слишком долго.
Небольшая проверка перед релизом может сэкономить часы догадок позже. Представьте сервис, который выглядит нормально в staging, а потом замедляется, когда всплеск загрузок приходит одновременно с обычным API-трафиком. Одна ограниченная очередь заполняется, воркеры ждут общий map, а отменённые запросы продолжают что-то делать в фоне. Исправление обычно не драматичное. Нужно просто увидеть точки давления раньше пользователей.
Если команда не может ответить на эти пять пунктов за одну встречу, система ещё не готова.
Следующие шаги для продакшена
Производственную настройку лучше проводить, когда вы выбираете один горячий путь и сначала исправляете одно узкое место. Команды часто меняют lock, каналы и расклад задач одновременно, а потом не могут понять, что именно помогло. Начните с пути, который обрабатывает больше всего трафика или даёт худшую хвостовую задержку.
Хорошая первая цель обычно заметна сразу. Возможно, один mutex слишком много чего охраняет. Возможно, один воркер получает все сообщения через один канал. Возможно, отменённые запросы продолжают работать ещё секунду. Исправьте одно из этих мест, измерьте снова и оставьте изменение, если цифры стали лучше.
Небольшие нагрузочные тесты заранее выявляют много проблем. Смешивайте всплески трафика с одной медленной downstream-зависимостью, потому что реальные системы почти никогда не ломаются в чистой лаборатории. Например, отправьте короткий пик запросов, пока один вызов базы данных или внешний API замедляется, и смотрите на глубину очереди, число задач, использование памяти и задержку p95.
Короткая письменная схема каждой группы задач помогает сильнее, чем многие команды ожидают:
- Кто владеет каждой частью общего состояния
- Какие каналы ограничены и каковы их лимиты
- Что происходит, когда очередь заполняется
- Как начинается завершение работы и кто останавливается первым
- Когда задача должна сбросить работу и выйти
Если эта схема кажется размытой, скрытая конкуренция, скорее всего, всё ещё есть в дизайне. Шаблоны задач Tokio остаются здоровыми, когда владение простое, очереди явные, а у отмены есть понятный путь.
Записывайте эти правила простым языком рядом с кодом. Тогда новые участники команды увидят, почему одна задача держит состояние, почему другая только отправляет сообщения и зачем вообще нужен ограниченный канал. Это снижает число случайных регрессий во время последующих рефакторингов.
Если вашей команде нужен ещё один взгляд со стороны, Oleg Sotnikov может посмотреть архитектуру Tokio, backpressure и настройку runtime в рамках Fractional CTO advisory. Такой разбор особенно полезен после того, как вы соберёте несколько трассировок, результаты тестов и одну чётко сформулированную проблему.


