Шаблоны Go-сервисов, которые не создают боль от привязки к framework
Шаблоны Go-сервисов помогают командам сохранять единообразие маршрутизации, конфигурации и наблюдаемости, при этом каждый сервис остаётся компактным и без привязки к framework.
Содержание
Почему сервисы, скопированные по шаблону, со временем расходятся
Копирование кажется самым быстрым решением в первый день. Вы берёте один рабочий сервис, дублируете его, переименовываете пару пакетов и отправляете в работу. Неделю или две это действительно помогает.
Потом копии начинают расходиться. В одном репозитории появляются middleware для таймаутов и request ID. В другом их нет, потому что сроки поджимали. В третьем добавляют свою проверку авторизации, про которую потом никто не помнит при следующем копировании.
Так и начинается дрейф. Не из-за одного большого решения по архитектуре, а из-за множества мелких правок, которые разные люди вносили в разное время.
Следом обычно ломается конфигурация. В одном репозитории используется PORT, в другом HTTP_PORT, а в третьем читаются оба варианта, потому что кто-то хотел сохранить обратную совместимость. Настройки базы данных, флаги функций и API-ключи продолжают расти, но имена так и не приводятся к порядку. Через несколько месяцев разработчики уже гадают, какие переменные среды ещё важны, а какие остались в наследство.
Логи расходятся ещё быстрее. Один сервис пишет обычный текст. Другой — JSON. Третий использует разные имена полей для одного и того же, например request_id, traceId или просто id. Во время инцидента это отнимает реальное время. Нельзя нормально фильтровать, сравнивать сервисы рядом или быть уверенным, что одно и то же поле означает одно и то же везде.
Code review тоже замедляется. Проверяющие перестают смотреть только на бизнес-логику. Им приходится ещё проверять, одинаково ли работает завершение работы, совпадают ли health-endpoint'ы с другими сервисами и продолжают ли метрики использовать те же метки. Мелкие различия накапливаются, и обычные ревью превращаются в археологию.
Простая настройка Go-монолита из микросервисов должна делать общие вещи скучными. Если каждая команда копирует целый сервис и правит его как хочет, шаблон становится снимком, а не стандартом. Именно здесь многие Go service templates и начинают ломаться.
Это чувствуется уже на четырёх сервисах. В production случается баг, и первые двадцать минут уходят на вопросы, на которые ответ должен быть очевиден: какой logger использует этот сервис, есть ли у него такая же health-check, какая переменная среды включает debug mode? Дрейф превращает простую работу в расследование.
Что должно быть общим у каждого сервиса
Небольшие Go-сервисы остаются удобными в эксплуатации, когда скучные части везде выглядят одинаково. Каждый репозиторий должен стартовать в одном и том же порядке: загрузить конфигурацию, создать logger, настроить метрики и трассировки, собрать зависимости, зарегистрировать маршруты, запустить сервер и затем корректно завершиться. Когда все сервисы идут по одному сценарию, новому человеку не нужно полчаса искать логику запуска.
С конфигурацией нужен такой же понятный порядок. Выберите его один раз и используйте везде. Часто хорошее правило такое: сначала значения по умолчанию, потом переменные среды, потом секреты. Это кажется мелочью, но команды теряют время, когда один сервис берёт таймаут из HTTP_TIMEOUT, другой использует SERVER_TIMEOUT, а третий игнорирует оба варианта, потому что локальный файл оказался важнее.
Health- и readiness-проверки тоже должны означать одно и то же в каждом репозитории. Health отвечает на один вопрос: жив ли процесс? Readiness отвечает на другой: может ли сервис прямо сейчас делать полезную работу? Если база данных недоступна, readiness должен падать. Если процесс всё ещё работает и может восстановиться, health может оставаться успешным. Такое разделение сильно упрощает деплои и разбор инцидентов.
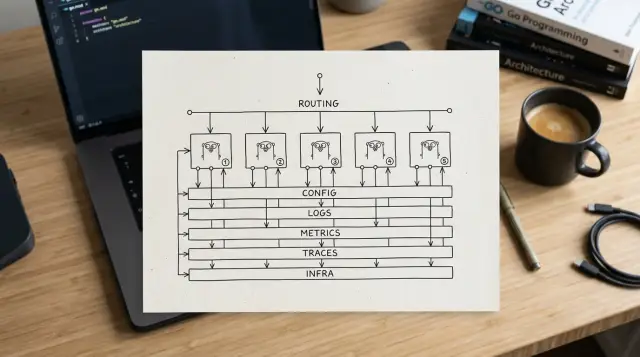
Общий контракт прост. У сервисов должен быть одинаковый поток запуска и завершения работы, одинаковые правила именования конфигурации и приоритетов, одинаковое поведение health-check'ов и одинаковые базовые поля в логах, метриках и трассировках.
Наблюдаемость особенно важна, когда что-то ломается в два часа ночи. Логи должны иметь одинаковую структуру во всех сервисах. Метрики должны следовать одним и тем же правилам именования. Трассировки должны нести одинаковые поля запроса и trace через хендлеры и внешние вызовы. Тогда одна панель сможет сравнивать сервисы без кучи ручных правок.
При этом не обязательно навсегда использовать один и тот же router или отдавать под шаблон все метрики подряд. Делитесь контрактом, а не каждым внутренним решением. Командам нужны знакомые правила запуска, конфигурации и наблюдаемости, но при этом каждый сервис должен оставаться достаточно небольшим, чтобы его можно было менять позже.
Многие шаблоны не выдерживают этот баланс. Они пытаются делиться слишком многим. Делитесь только тем, на что разработчики и операторы опираются каждый день, а остальное оставляйте локальным.
Что каждый сервис должен решать сам
Сервис лучше всего работает, когда он сам владеет словами, правилами и структурами данных своей предметной области. Billing-сервис должен говорить об invoice, refund и статусе платежа. Auth-сервис должен говорить о session, token и ролях. Как только общий шаблон начинает определять эти модели, каждый новый сервис начинает подстраиваться под чужие решения.
Рабочие части держите рядом. Хендлеры, код хранения данных и бизнес-правила должны жить внутри сервиса, если только два сервиса действительно не выполняют один и тот же алгоритм. Команды часто делятся слишком рано, а потом месяцами разбирают всё обратно, когда аккуратный пакет превращается в узкое место.
Большинству сервисов нужна свобода в нескольких областях: модель предметной области и правила валидации, доступ к базе и стиль миграций, сторонние пакеты, от которых они зависят, а также собственные задачи, кэши и внешние клиенты.
Эта свобода важнее, чем кажется. Сервис для отчётности может хотеть сырой SQL и простые read models. Сервис для обработки webhooks может почти не нуждаться в хранилище вообще. Если шаблон заставляет оба сервиса использовать один и тот же repository layer или ORM, он перестаёт помогать.
То же правило относится к зависимостям. Выбирайте пакеты для каждого сервиса отдельно, а не для шаблона целиком. Если одному сервису нужен клиент очереди, добавьте его туда. Если другой только читает из PostgreSQL и пишет логи, пусть он останется таким же маленьким. Хорошие Go service templates дают чистую точку старта, а дальше позволяют каждому сервису быть скучным по-своему.
Простой пример делает это очевидным. Допустим, вы строите auth, billing и file import. Auth нужен подпись токенов и rate limit. Billing нужен аккуратный контроль транзакций. File import нужен CSV-парсер и цикл worker'а. Если все трое наследуют один и тот же cache layer, ORM-хелперы и пакет фоновых задач, двое из них получат код, которого они не просили.
Добавляйте пакеты только тогда, когда сервису они действительно нужны. Каждая дополнительная зависимость — это обновления, баги, конфигурация и лишняя нагрузка на голову. Шаблон должен стандартизировать маршрутизацию, загрузку конфигурации и логи, но не должен решать, как думает каждый сервис.
Собирайте шаблон по шагам
Начинайте с минимального количества общего кода, которое вам действительно нужно. Хорошие Go service templates остаются простыми: один небольшой пакет main, один пакет конфигурации, один пакет наблюдаемости и только несколько правил, которые соблюдают все сервисы.
Сделайте main тонким. Его задача — прочитать конфигурацию, создать зависимости, зарегистрировать маршруты, запустить сервер и корректно остановиться. Если бизнес-логика просачивается в main, каждый новый сервис становится уникальным, а шаблон перестаёт помогать.
Делайте общий слой узким
Самый безопасный шаблон использует небольшие интерфейсы для запуска и маршрутизации, а не огромный app container. Сервис может, например, иметь один метод для регистрации HTTP-хендлеров и другой — для запуска стартовых проверок. Этого достаточно для единообразия, но не заставляет все команды навсегда жить в одном router или одном layout пакетов.
Специально держите контракт роутера небольшим. Если общий слой должен знать все возможности конкретного framework, значит, привязка уже началась. Большинству сервисов достаточно сопоставлять пути, подключать middleware и отдавать health-endpoint'ы.
Загружайте переменные среды в одну структуру конфигурации на раннем этапе, а затем передавайте её дальше. Избегайте разрозненных вызовов os.Getenv по всему коду. Когда конфигурация живёт в одном месте, людям видно значения по умолчанию, обязательные поля и правила именования, не нужно искать их по файлам.
Хороший поток запуска короткий и легко читается: разобрать переменные среды в типизированную структуру конфигурации, проверить обязательные настройки до старта сервера, собрать logger и telemetry из этой конфигурации, создать зависимости, зарегистрировать маршруты, выполнить одну стартовую проверку и только потом принимать трафик.
Наблюдаемость оборачивайте легко
Логи, метрики и трассировки должны находиться за тонкими helper'ами. Думайте о небольших адаптерах, а не о большом внутреннем framework. Helper для логов может добавлять общие поля вроде имени сервиса и версии. Helper для метрик может открывать счётчики и таймеры задержки с общими названиями. Helper для трассировки может создавать spans вокруг запросов и исходящих вызовов.
Так повседневная работа остаётся простой. Новый сервис получает тот же формат логов и тот же сигнал health, но код хендлеров всё равно выглядит как обычный Go.
Прежде чем считать шаблон готовым, добавьте две страховки. Напишите один smoke test, который поднимает сервис с тестовой конфигурацией и проверяет, что /health возвращает успех. Затем добавьте одну стартовую проверку, которая быстро падает при плохой конфигурации или отсутствии зависимостей.
Команды, которые строят лёгкие системы, очень выигрывают от такого подхода, потому что он рано ловит сломанные деплои без большого количества лишнего кода. Именно поэтому инженеры вроде Oleg Sotnikov так много внимания уделяют простым операционным правилам: небольшие, стабильные проверки обычно лучше, чем большой внутренний framework.
Три сервиса, одна основа
Три Go-сервиса могут стартовать одинаково и при этом вести себя совершенно по-разному там, где это важно. В этом и есть удачная точка: общая структура, небольшой код и никакой привязки к framework.
Представьте команду с orders, billing и notifications. Каждый сервис загружает конфигурацию одинаково, запускает HTTP-сервер с одинаковыми middleware, отдаёт одинаковые health-роуты и пишет логи в одном формате.
Новый инженер может открыть любой репозиторий и быстро увидеть базу. Он поймёт, откуда берётся конфигурация, как сервис запускается и останавливается, какие health-endpoint'ы есть и как подключены логи, метрики и трассировки.
Это однообразие экономит реальное время. Не приходится полдня разбираться, почему один сервис использует переменные среды, другой читает YAML, а третий пишет обычный текст без request ID.
Один и тот же каркас, но разные правила
Сервис orders может иметь более строгую обработку запросов. Он проверяет авторизацию на каждом write route и использует idempotency keys, чтобы клиент мог повторить покупку без создания дублей. Его бизнес-правила живут в хендлере и service layer, а не в магии framework.
Billing выглядит похоже при запуске, но его риск находится в другом месте. Он обращается к внешним платёжным системам, поэтому ему нужны правила повторных попыток, ограничения по таймаутам и понятное сопоставление ошибок. Общий шаблон может дать базовый helper для retry, но billing сам должен решать, когда повторять запрос, а когда остановиться.
У notifications ещё другая форма. Он может отдавать небольшой API, но большая часть работы происходит в worker'ах очереди. При этом он всё равно использует тот же загрузчик конфигурации, тот же logger и те же health-endpoint'ы. Поверх этого он добавляет настройки параллельности worker'ов и rate limit, чтобы одно шумное событие не завалило email- или SMS-провайдеров.
Польза становится особенно заметной, когда чего-то не хватает. Если billing уже пишет трассировки, а notifications экспортирует метрики очереди, новый инженер быстро заметит, что orders забыли подключить telemetry на новом endpoint'е. Пробел виден сразу, потому что все сервисы следуют одной базе.
В этом и есть вся идея. Делитесь запуском, конфигурацией и наблюдаемостью. А каждый сервис пусть сам владеет своими правилами.
Маршрутизация, конфигурация и логи на практике
Когда сервис ломается в production, боль обычно связана не с Go, а со слабыми привычками. Команды теряют время, когда маршруты спрятаны, имена конфигурации меняются от репозитория к репозиторию, а в логах нет того самого поля, которое нужно прямо сейчас.
Делайте группы маршрутов неглубокими. Один раз сгруппируйте по предметной области, а потом остановитесь. Пути вроде /api/v1/users и /api/v1/invoices легко читать. Слишком глубокая вложенность превращает маленький сервис в лабиринт. Хороший шаблон делает карту маршрутов очевидной в одном месте, даже если хендлеры лежат в отдельных файлах.
Это ещё и помогает избежать привязки к фреймворку в Go. Если позже заменить один router на другой, расположение маршрутов всё равно должно иметь смысл, потому что структура принадлежит сервису, а не framework.
С конфигурацией нужна такая же дисциплина. Выберите одно правило префикса и используйте его везде. Если сервис называется billing, используйте имена вроде BILLING_HTTP_PORT, BILLING_DB_DSN и BILLING_QUEUE_URL. Не смешивайте APP_PORT, PORT и BILLING_PORT между разными сервисами. Одно правило убирает догадки при локальной настройке, деплоях и разборе инцидентов.
Логи должны быстро отвечать на простые вопросы: какой запрос не прошёл, какой сервис его обработал и какая ошибка произошла? Добавляйте request ID в каждый лог запроса. Добавляйте и имя сервиса. Когда пишете ошибку, включайте структурированные поля вроде имени операции, status code, зависимости и текста ошибки. Обычный текстовый лог сначала кажется проще, но при росте трафика его становится трудно фильтровать.
Метрики показывают тренды, которые логам не видно. Измеряйте задержку запросов, число ошибок и обращения к внешним зависимостям. Если checkout-endpoint начинает тормозить, нужно понять, медленный ли у вас хендлер или тормозит платёжный API. Это сильно экономит время во время аварии.
Трассировки соединяют весь путь. Начинайте span на границе, как только запрос входит в сервис. Затем оборачивайте каждый запрос к базе, обращение к cache или внешний API в дочерние spans. С такой настройкой три небольших Go-сервиса всё ещё читаются понятно, когда одно пользовательское действие затрагивает все три.
Команде не нужно ничего сильно сложнее этого. Делайте маршруты достаточно плоскими, чтобы их можно было быстро просмотреть, используйте один префикс конфигурации на сервис, логируйте request ID и имя сервиса, отслеживайте задержку и ошибки и начинайте трассировку на входе и вокруг исходящих вызовов. Обычно такой степени единообразия уже достаточно.
Как команды сами создают привязку
Обычно привязка возникает случайно. Сначала команда начинает с аккуратного шаблона, а потом превращает его в правило, которому каждый сервис должен подчиняться во всех деталях. Через несколько месяцев маленькие Go-сервисы уже не кажутся маленькими.
Первая ошибка — позволить одному web framework расползтись по всем пакетам. Хендлер импортирует типы framework, общий код начинает от них зависеть, и даже маленький фоновый сервис тащит за собой HTTP-багаж, который ему не нужен. Позже заменить router уже почти значит переписать всё.
Другая частая проблема начинается в middleware. Команды помещают auth, validation, tenant rules, pricing rules и другие бизнес-решения в длинные цепочки middleware, потому что это выглядит аккуратно. На деле — нет. Когда бизнес-правила живут там, никто уже не может понять, что именно делает запрос, не пройдя через пять слоёв обёрток.
Тот же беспорядок может создать общий модуль конфигурации. Если один пакет загружает все переменные среды для всех сервисов, каждый бинарник тащит за собой настройки, которые ему вообще не нужны. В итоге появляются шум, скрытая связанность и деплои, когда безобидное изменение в одном сервисе ломает запуск другого.
Большая часть боли рождается из нескольких привычек: всё строится вокруг одного framework, продуктовые правила прячутся внутри middleware, все переменные среды собираются в один глобальный пакет конфигурации, общие helper'ы добавляются раньше, чем они действительно нужны двум сервисам, и имена полей логов меняются от сервиса к сервису.
Последняя вещь выглядит мелочью, но мешает каждый день. Если один сервис пишет request_id, другой — reqId, а третий — trace, дашборды и поиск очень быстро превращаются в хаос. Единые имена полей экономят реальное время, когда что-то ломается поздно вечером.
Исправление очень скучное, и в этом его сила. Оставьте шаблон тонким. Делитесь интерфейсами, правилами логов, шаблонами конфигурации и базовой формой запуска. А каждому сервису оставьте право выбирать свои маршруты, структуру пакетов и бизнес-логику.
Что проверить, прежде чем команда примет шаблон
Если шаблон экономит час сегодня, но ловит команду в ловушку через месяц, это плохой шаблон. Перед тем как сделать его стандартом, проверьте несколько простых вещей.
Поднимите новый сервис с нуля и засеките время. Один инженер должен суметь запустить его, добавить один маршрут, загрузить конфигурацию и начать писать логи менее чем за пятнадцать минут. Если на это уходит заметно больше времени, шаблон требует слишком многого.
Потом попросите двух инженеров собрать один и тот же маленький API на этом шаблоне. Если у них получатся разные группы маршрутов, разные имена папок или разный порядок middleware, значит, правила всё ещё слишком расплывчаты.
Когда оба сервиса уже работают, откройте дашборды. Для каждого из них вы должны видеть одни и те же базовые сигналы: количество запросов, задержку, уровень ошибок и версию сервиса. Затем замените router в тестовой ветке. Если после этого изменение расползается в хендлеры, бизнес-логику и загрузку конфигурации, значит, router сидит слишком глубоко в коде.
Есть ещё одна полезная проверка: удалите то, что никому не нужно, например код очереди или лишний middleware. Если команде страшно это убирать, значит, в шаблоне уже слишком много скрытой связанности.
Для большинства команд это важнее, чем они готовы признать. Шаблон часто выглядит чистым, когда его делает один человек, но настоящие проблемы появляются, когда два человека используют его параллельно. Один кладёт health-check'и в /internal, другой — в /system. Один пишет request ID в middleware, другой добавляет их в хендлерах. Эти мелкие различия превращаются в дрейф уже после трёх или четырёх сервисов.
Хорошие Go service templates держат общие части скучными. Маршрутизация должна жить в тонком адаптере. Конфигурация должна загружаться одинаково каждый раз. Логи и метрики должны использовать одни и те же имена полей, чтобы никому не приходилось гадать, что в production означают service, env или trace_id.
Самая полезная проверка всё ещё простая: замените router, но оставьте хендлеры. Если это работает с небольшим изменением только на краю сервиса, вы избежали привязки к framework. Если это занимает день, шаблон слишком категоричен.
Самый безопасный шаблон обычно меньше, чем людям хочется.
Как внедрять его без лишней драмы
Начинайте с одного нового сервиса, а не с переписывания. Выберите что-то небольшое, но реальное, например внутренний webhook receiver или фоновый worker, и соберите его по шаблону с самого начала. Так команда сможет безопасно проверить подход, не таща старый код в эксперимент.
Хороший пилот должен затронуть именно те части, которые обычно расходятся первыми: маршрутизацию, загрузку конфигурации, логи, health-check'и и базовые метрики. Если сервис выходит в production, и две недели никто не спорит о layout папок или полях логов, это хороший знак. Если люди продолжают обходить шаблон, сначала исправьте шаблон, а уже потом распространяйте его дальше.
Запишите короткий набор правил и остановитесь. Большинству команд достаточно нескольких пунктов: каждый сервис стартует одинаково и отдаёт одни и те же health-endpoint'ы, конфигурация следует одному порядку источников и одному стилю именования, логи содержат одни и те же базовые поля, метрики и трассировки следуют одному шаблону именования, а команды могут менять router, storage или job runner через небольшой локальный интерфейс.
Не добавляйте правила под проблемы, с которыми команда ещё даже не столкнулась. Тонкие правила живут долго. Толстые своды правил просто игнорируют.
Через месяц сделайте дрейф проверкой специально. Сравните пилотный сервис со вторым и задайте простые вопросы: какие общие части люди оставили, какие обошли и какие файлы так и не тронули? Мёртвый код удаляйте быстро. Если какой-то helper-пакет казался умным в шаблоне, но им никто не пользуется, уберите его.
Такая проверка ещё и показывает, остаются ли ваши Go service templates компактными. Если общий код начинает затаскивать бизнес-логику в один общий пакет, разделите его обратно. Шаблон должен экономить время на старте, а не прятать связанность.
Практичный ритм работает хорошо: пилот на первой неделе, правила на второй, второй сервис на третьей и четвёртой неделях, затем проверка дрейфа в конце месяца. К этому моменту команда обычно уже понимает, помогает шаблон или просто добавляет ритуалы.
Если перед более широким запуском вам нужен внешний взгляд, oleg.is — хороший пример того, какой формат Fractional CTO сюда подходит. Oleg Sotnikov фокусируется на архитектуре, наблюдаемости и бережливой AI-first разработке, и это особенно полезно, когда шаблон ещё достаточно маленький, чтобы изменить его за один день.
Часто задаваемые вопросы
Что должен разделять каждый Go-сервис?
Сделайте общие, скучные части одинаковыми. Используйте один и тот же поток запуска, одинаковые правила загрузки конфигурации, одинаковое поведение health и readiness, а также одинаковые базовые поля в логах, метриках и трассировках, чтобы каждый репозиторий ощущался знакомо.
Что каждый сервис должен решать сам?
Пусть каждый сервис сам владеет своей доменной моделью, правилами валидации, выбором хранилища, внешними клиентами и логикой задач. Billing-сервис, auth-сервис и импортёр должны запускаться одинаково, но не должны делить бизнес-правила только потому, что шаблон это позволяет.
Сколько кода должен включать шаблон Go-сервиса?
Держите шаблон меньше, чем вам хочется. Обычно достаточно тонкого main, одного типизированного пакета конфигурации и лёгких вспомогательных модулей для наблюдаемости, чтобы получить большую часть пользы, не превращая шаблон во фреймворк.
Как избежать привязки к фреймворку?
Держите типы фреймворка на краю системы. Если хендлеры, бизнес-логика или общие пакеты слишком глубоко зависят от одного роутера, потом его будет больно менять. Небольшой локальный адаптер вокруг маршрутизации делает этот выбор проще.
Как стандартизировать конфигурацию между сервисами?
Выберите одно правило именования и одно правило приоритета и используйте их везде. Сначала загружайте значения по умолчанию, потом переменные среды, потом секреты, и не смешивайте PORT, APP_PORT и сервисные варианты между репозиториями.
В чём разница между health и readiness?
Health должен отвечать на вопрос, жив ли процесс. Readiness должен отвечать на вопрос, может ли сервис прямо сейчас делать полезную работу. Если база недоступна, readiness должен падать, даже если процесс всё ещё работает.
Какая наблюдаемость должна быть у каждого сервиса по умолчанию?
Начните с request ID, имени сервиса, статуса, текста ошибки и имени операции в логах. Отслеживайте количество запросов, задержку и процент ошибок в метриках, а затем добавьте спаны на входе запроса и вокруг вызовов к базе или внешним API, чтобы можно было проследить один запрос через несколько сервисов.
Как понять, что шаблон слишком навязчивый?
Сначала замерьте, как быстро можно поднять новый сервис. Один инженер должен суметь запустить его, добавить один маршрут, загрузить конфигурацию и начать писать логи за короткое время. Если это занимает слишком долго, шаблон требует слишком много подготовки.
Стоит ли выносить бизнес-логику в middleware или общие пакеты?
Нет. Правила авторизации, ценообразования, tenant-логики и других продуктовых решений должны жить там, где код сервиса показывает их явно. Длинные цепочки middleware и ранние общие пакеты скрывают поведение и создают лишнюю связанность.
Как безопасно внедрить новый шаблон?
Начните с одного небольшого реального сервиса, а не с переписывания. Используйте его несколько недель, сравните со вторым сервисом и оставьте только те общие части, которыми люди реально пользуются. Если командa постоянно обходит какой-то helper, удалите его или упростите.


