Семплирование трассировок между сервисами без слепых зон
Семплирование трассировок между сервисами помогает видеть ошибки, медленные участки и вызовы ИИ, не сохраняя каждую трассировку и не раздувая бюджет.
Содержание
Почему трассировки исчезают, когда растёт трафик
Настройка трассировки может отлично выглядеть на стенде, а уже на неделе, когда трафик вырастает, начать разваливаться. Проблема редко в самой трассировке. Команды снижают долю семплирования, чтобы сдержать расходы, и как раз пропавшая трассировка часто показывает, почему случился сбой, таймаут или плохой пользовательский опыт.
Больше всего это бьёт по редким ошибкам. Если падает один запрос из 2 000, а вы храните только маленькую часть трафика, всё решает удача: увидите вы его или нет. Логи и метрики, возможно, у вас останутся, но полный путь через сервисы, базы данных, очереди и внешние API пропадёт.
Потоки трафика создают и более тихую проблему. Один шумный сервис может съесть большую часть бюджета трассировки. Болтливый edge-сервис, проверка аутентификации или фоновый воркер могут создавать куда больше спанов, чем остальная система. В итоге система хранит массу обычных трассировок и выбрасывает необычные. Вы платите за данные, но теряете именно тот запрос, который был нужен.
Повторы делают историю ещё сложнее. Пользователь отправляет один запрос, а система может запустить три внутренних повтора, один переход через очередь и одну отложенную задачу. Если контекст трассировки не проходит через эти шаги чисто, запрос распадается на отдельные фрагменты. Каждый из них по отдельности выглядит безобидно, но вместе они объясняют, почему пользователь ждал 18 секунд.
Вызовы ИИ часто исчезают первыми. Многие команды добавляют трассировку вокруг веб-запроса и базы данных, а потом забывают про вызов модели, сборку промпта, векторный поиск или вызов инструмента. Так появляется слепая зона. Функция на базе ИИ может добавить большую часть задержки и стоимости, особенно если запрос разветвляется на несколько моделей или повторяется после таймаута.
На скромной инфраструктуре это становится ещё болезненнее, потому что каждый сохранённый спан имеет цену. Поэтому семплирование нужны правила, а не один общий процент. Если каждый сервис семплирует сам по себе, общая картина быстро ломается. Вы не получаете одну полную трассировку. Вы получаете обрывки, а обрывки трудно разбирать, когда клиенты ждут ответа.
Что должен добавлять в трассировку каждый сервис
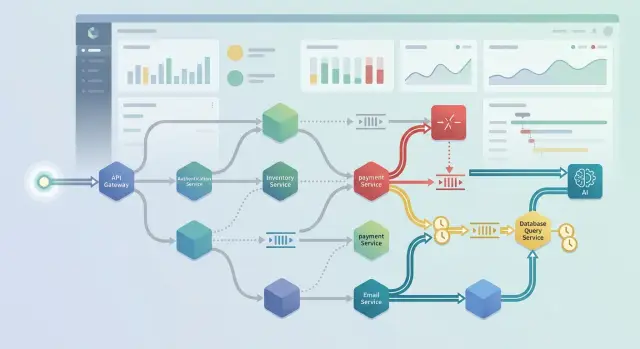
Трассировка работает только тогда, когда каждый сервис сохраняет одну и ту же идентичность запроса. Edge-сервис должен один раз создать trace ID, а затем передавать его через каждый API-вызов, сообщение воркера и фоновый шаг. Если один сервис потеряет его, временная линия распадётся на фрагменты, и вы лишитесь той части, которая обычно нужна больше всего.
Каждый сервис должен добавлять один и тот же небольшой набор данных каждый раз, когда обрабатывает запрос. Держите всё просто и одинаково. Сложные теги не заменяют базовые данные.
Записывайте имя сервиса и точный маршрут или операцию. Записывайте результат — успех, ошибку клиента или ошибку сервера. Записывайте время начала и общую длительность в миллисекундах. Отмечайте, был ли это повтор, переход через очередь или внешний вызов. Добавляйте контекст только тогда, когда он меняет то, как вы читаете трассировку, например tenant, регион или название модели.
Имя сервиса звучит очевидно, но команды часто его пропускают или используют названия, которые меняются каждые несколько недель. Выберите одно стабильное имя для каждого сервиса. Для endpoints записывайте шаблон маршрута, а не полный URL с ID пользователя или случайными токенами.
Статус и длительность делают основную работу, когда вы просматриваете трассировку. По одной строке можно заметить 500-ю ошибку. Можно также увидеть, провёл ли запрос 40 мс в аутентификации и 4 200 мс в ожидании ИИ-модели.
Повторы должны иметь собственную отметку. Без неё медленный запрос может выглядеть нормальным, хотя система пыталась выполнить один и тот же шаг три раза. Переходы через очередь важны по той же причине. Если API-вызов превращается в задачу, добавьте этот факт в трассировку, чтобы задержка не исчезла между сервисами.
Внешние вызовы тоже должны быть отмечены ясно. Запрос к базе данных, вызов платёжного провайдера и запрос к модели не должны выглядеть одинаково. Для наблюдаемости ИИ записывайте название модели, если от него зависят поведение или стоимость. Теги региона и tenant тоже полезны, но только если они действительно что-то объясняют, например почему в одном регионе всё медленнее или один tenant отправляет гораздо более длинные промпты.
Чистые метаданные делают каждое правило семплирования эффективнее. Каждый спан должен объяснять, что произошло, где это произошло и почему этот шаг занял время.
Правила, которые помогают видеть ошибки, медленные пути и вызовы ИИ
Дешёвая настройка трассировки ломается, когда одинаково относится ко всем запросам. Большинство запросов скучные. Но несколько из них показывают, где утекают деньги, где ждут пользователи или где релиз пошёл не так. Именно такие трассировки и нужно сохранять.
Начните с жёсткого правила: сохраняйте каждую трассировку, которая заканчивается ошибкой. Не уменьшайте долю для таких случаев. Редкий баг в одном сервисе часто начинается за два или три шага до ошибки, поэтому полная трассировка важнее, чем финальный stack trace.
То же самое для медленных запросов. Выберите один порог задержки, который легко запомнить, и сохраняйте всё, что его превышает. Для многих команд это может быть 1 секунда для пользовательских API и более высокий порог для фоновой работы. Самое важное здесь не точное число, а единая и понятная граница для всех сервисов.
Для вызовов ИИ нужно отдельное правило. Обычный чтение из кэша или простой запрос к базе данных может жить с меньшей долей семплирования. Но модельные вызовы — нет. Они дороже, сильнее отличаются друг от друга и ломаются куда более непредсказуемо. Если один пользовательский запрос обращается к LLM, векторному хранилищу и reranker, эта трассировка полезнее десяти удачных обращений к кэшу.
Обычно работает простая политика:
- Сохраняйте 100% трассировок с любым статусом ошибки.
- Сохраняйте 100% трассировок выше порога задержки.
- Семплируйте трассировки, связанные с ИИ, в несколько раз чаще, чем обычные чтения.
- Повышайте семплирование для новых релизов, платёжных потоков и хрупких endpoints.
- Жёстко сокращайте семплирование для health check, polling и шумного cron-трафика.
Окна релизов заслуживают временного повышения. Если вы выкатываете новый поток поиска в пятницу, соберите больше трассировок для этого пути на день или два. Дополнительные расходы обычно невелики, а сэкономить они могут часы, если что-то странное проявится только на реальном трафике.
Health check и polling, наоборот, требуют противоположного подхода. Они создают объём, повторяют один и тот же путь и скрывают те трассировки, которые вы действительно хотите изучить. Оставляйте только столько, чтобы убедиться, что они работают.
Именно так политика семплирования остаётся полезной при ограниченном бюджете: сохраняйте всё необычное, больше — из того, что дорого, и как можно меньше — из шума.
Постройте политику шаг за шагом
Начните на входе. Первое решение о семплировании принимайте на API gateway, ingress или в первом публичном сервисе и передавайте его дальше по цепочке. Так вы сразу ограничите объём и не дадите каждому сервису выбирать случайным образом.
Сначала достаточно небольшой базовой доли. Семплируйте 2%–5% обычного трафика, чтобы у вас всегда был стабильный фон, но хранилище не забивалось в загруженные дни.
Затем добавляйте правила после завершения запроса, когда уже известны код статуса и длительность. Сохраняйте все серверные ошибки. Сохраняйте запросы, которые превысили порог задержки. Сохраняйте вызовы ИИ, которые упали, зависли, повторились или оказались дороже обычного, даже если исходный запрос попал в низкую долю семплирования.
Небольшие команды часто слишком рано усложняют схему. Напишите одно правило для каждого случая и задайте каждому правилу понятный приоритет. Если запрос подходит под два правила, решите заранее, какое победит, ещё до запуска в прод.
Такая политика легко читается:
- Семплируйте 3% обычных запросов на входе.
- Сохраняйте 100% ответов 5xx.
- Сохраняйте 100% запросов медленнее 2 секунд.
- Сохраняйте 100% неудачных или медленных вызовов ИИ-модели.
- Сохраняйте одно и то же решение о трассировке во всех downstream-сервисах.
Последнее правило важнее, чем кажется. Если frontend выбросит трассировку, а worker или AI proxy оставит лишь часть, вы получите обрывки. Эти обрывки съедают бюджет и всё равно оставляют вас в догадках.
Задавайте бюджет в числах, за которыми можно следить, а не на ощущениях. Выберите дневной лимит спанов или лимит хранилища, например 15 миллионов спанов в день или 40 ГБ в день. Если вы скажете только «семплируйте понемногу», политика будет уползать до тех пор, пока кто-то не получит неожиданный счёт.
После этого посмотрите на целую неделю трафика. Одного дня мало — он слишком шумный. Ищите маршруты, которые постоянно остаются чуть ниже порога медлительности, всплески ошибок в одном сервисе и вызовы ИИ, которые раздувают трассировки из-за повторов или разветвления.
Меняйте по одному параметру за раз. Поднимите порог медлительности, снизьте базовую долю семплирования или исключите шумный health check. Затем посмотрите на следующую неделю и проверьте, по-прежнему ли сохранённые трассировки отвечают на реальные вопросы об отладке.
Держите асинхронные задачи и разветвлённые запросы в поле зрения
Асинхронная работа ломает трассировки чаще, чем HTTP. Чистая трассировка запроса может исчезнуть в тот момент, когда приложение кладёт задачу в очередь или передаёт работу cron-задаче. Семплирование работает только тогда, когда вы переносите контекст трассировки вместе с сообщением, а не только через веб-заголовки.
Когда API-вызов создаёт фоновую задачу, сохраняйте trace ID, span ID и небольшой набор меток вместе с метаданными или payload сообщения. Затем пусть воркер продолжает эту же трассировку как дочернюю, а не как новую корневую. То же самое делайте для запланированных задач. Cron-запуск может начать собственную корневую трассировку, а все задачи, которые он создаёт, должны быть связаны с этим запуском.
К разветвлениям нужно относиться так же внимательно. Если один запрос отправляет работу трём воркерам, вызывает API модели и отправляет webhook, держите все эти ветки под одним родительским спаном. Вам нужна одна трассировка, которая показывает разветвление, медленную ветку и повтор, который съел 12 секунд. Без этой связи parent-child каждая ветка выглядит нормальной сама по себе, а реальное узкое место остаётся скрытым.
Фоновые воркеры тоже нуждаются в большем контексте, чем веб-запросы. Воркер, который обработал 1 элемент, и воркер, который обработал 5 000, не должны выглядеть одинаково в данных трассировки. Записывайте размер пакета, задержку в очереди, число повторов и тип задачи, если это не нарушает ваши правила приватности. Эти поля объясняют, почему один запуск занял 40 мс во вторник и 9 минут в пятницу.
Считайте вызовы модели и webhooks отдельными спанами, даже внутри воркера. У спана модели должно быть своё время, название модели, число токенов и результат по таймауту. У спана вебхука должны быть свой endpoint и история повторов. Когда растут расходы или скачет задержка, эти спаны покажут, виновата ли очередь, модель или callback.
Сохраняйте и часть успешной фоновой работы. Если семплировать только сбои, вы потеряете базовую картину. Даже 1%–5% семплирования здоровых задач может показать нормальную задержку в очереди, нормальные размеры пакетов и то, где разветвление обычно заканчивается.
Простой пример одного пользовательского запроса
Клиент открывает страницу биллинга и спрашивает встроенного помощника ИИ: «Почему мой счёт изменился в этом месяце?» Один клик запускает больше работы, чем ожидает большинство команд.
Приложение проверяет личность через сервис аутентификации, загружает данные счёта из billing, подтягивает несколько связанных записей из search и отправляет вопрос клиента вместе с контекстом аккаунта в API модели. В тихий день вы могли бы хранить только небольшую долю таких запросов и всё равно узнавать достаточно.
Но этот запрос другой. Billing тормозит на 2,7 секунды, потому что один запрос к базе данных зависает. Вызов модели тоже падает с первой попытки, ждёт немного и успешно проходит со второй. Если полагаться только на случайное семплирование, эта трассировка может исчезнуть, хотя именно она объясняет и медленный экран, и более высокий счёт за ИИ.
Простая политика это сохраняет:
- Сохраняйте любую трассировку с ошибкой или повтором.
- Сохраняйте любую трассировку, где спан billing работает дольше вашего порога медлительности.
- Сохраняйте любую трассировку, которая включает вызов API модели.
- Сохраняйте всю трассировку целиком, а не только совпавший спан.
Последнее правило важнее всего. Если вы сохраните только медленный спан billing, вы потеряете цепочку вокруг него. Вы не увидите, что аутентификация завершилась за 40 мс, search ответил быстро, задержку на странице вызвал billing, а повтор ИИ добавил ещё 900 мс. Полная картина показывает одну проблему пользователя, а не четыре отдельных события.
Вот здесь семплирование перестаёт быть абстрактным. Одна сохранённая трассировка может ответить сразу на несколько вопросов: почему страница тормозила, почему выросло потребление токенов, сработала ли логика повторов и какая команда должна чинить первое узкое место.
Хорошие правила помогают и держать бюджет под контролем. Вам не нужны все обычные billing-запросы и каждый короткий промпт к ИИ. Нужны те, что пересекли порог, повторились или упали. Небольшой набор хорошо выбранных трассировок обычно рассказывает историю яснее, чем гигантская куча случайных.
Если ваша команда работает экономно, такой набор правил окупается быстро. Вы храните меньше шума, а трассировки, которые остаются, — это как раз те, что люди открывают во время инцидента.
Ошибки, из-за которых появляются слепые зоны
Большинство слепых зон начинается с правила, которое кажется аккуратным и дешёвым. Потом трафик растёт, одна команда меняет настройку по умолчанию, и трассировка ломается посередине.
Первая ошибка — позволить каждому сервису семплировать самому по себе. API сохраняет трассировку, воркер её выбрасывает, а спан базы данных так и не появляется. В итоге у вас остаются фрагменты, которые по отдельности выглядят нормально, но в целом ничего не объясняют. Хорошее семплирование требует одного общего решения в начале запроса, и каждый downstream-сервис должен его соблюдать.
Универсальное правило 1% создаёт другую проблему. Оно звучит справедливо, но ставит здоровый запрос на 120 мс в один ряд с падающим checkout или таймаутом на 9 секунд. Редкие сбои исчезают. Медленные пути пропадают именно тогда, когда они нужнее всего. Если нужно защитить бюджет распределённой трассировки, держите быстрый и здоровый трафик на низкой доле, но всегда сохраняйте ошибки и запросы, которые пересекают чёткий лимит задержки.
Команды часто перегибают палку с вызовами ИИ. Они решают, что каждый вызов модели надо сохранять, потому что такие спаны дороги и их сложно отлаживать. Сама мысль верная. Ошибка в том, что рядом со спаном ИИ выбрасывают сам пользовательский запрос. Тогда вы видите количество токенов и задержку модели, но не видите, что именно вызвало этот вызов, какой сервис подготовил промпт или что произошло после ответа. Если сохраняется спан ИИ, должен сохраняться и родительский запрос.
Очереди, повторы и промахи кэша тоже ускользают из поля зрения. Многие медленные запросы не падают на первом HTTP-этапе. Они разветвляются в job queue, повторяются три раза, мимо кэша идут к базе данных под нагрузкой. Если вы не переносите контекст трассировки в этот путь, трассировка выглядит чистой, пока пользователь ждёт.
Несколько проверок помогают поймать это раньше:
- Примите одно решение о семплировании на входе и передавайте его в каждый сервис.
- Сохраняйте все ошибки, таймауты и запросы выше порога медлительности.
- Если сохраняется дочерний спан ИИ, сохраняйте и родительскую трассировку.
- Передавайте trace ID через очереди, повторы и пути отката кэша.
- Проверяйте изменения правил на росте хранилища и объёме алертов до запуска в прод.
Изменение порогов тоже может создать слепые зоны. Если вы сдвинете порог медлительности с 2 до 5 секунд, хранилище быстро разгрузится, но вы можете скрыть плохую регрессию. Если опустить его слишком низко, вы переполните хранилище и научите людей игнорировать алерты. Запустите короткое испытание, сравните, что вы ловите, и посмотрите, сколько это стоит, прежде чем закреплять правило.
Быстрые проверки перед запуском
Политика семплирования может отлично выглядеть на дашборде и всё равно провалиться в первый раз, когда на неё пойдёт реальный трафик. Короткая проверка перед релизом помогает увидеть пробелы, которые потом будут стоить вам часов.
Цель простая: сохранять те трассировки, которые вам действительно нужны, и убирать шум. Перед релизом отправьте несколько тестовых запросов специально. Один должен упасть, второй — тормозить, а третий — пройти через все основные этапы вашей системы.
- Запустите известную ошибку и убедитесь, что полную трассировку можно найти за несколько минут, а не после долгого поиска в логах.
- Проведите один запрос от API до любой фоновой задачи, воркера очереди, webhook и вызова модели. Если трассировка рвётся на любом переходе, исправьте перенос контекста до запуска.
- Добавьте задержку в одну зависимость и проверьте, показывает ли трассировка точный спан, который вызвал замедление. Медленная трассировка мало полезна, если в ней написано только «запрос занял 9 секунд».
- Создайте или разверните новый сервис из того же шаблона и проверьте, что у него тот же шаблон имени сервиса, тег окружения, тег версии и правила семплирования, что и у остальных.
- Запустите короткий всплеск трафика и посмотрите на объём трассировок, хранилище и скорость приёма. Бюджет трассировок должен оставаться в пределах лимита, при этом ошибки и медленные запросы по-прежнему должны сохраняться.
Вызовы ИИ заслуживают отдельной быстрой проверки. Запрос к модели в один момент может быть быстрым, а в следующий — дорогим. Убедитесь, что в трассировке видны сборка промпта, задержка модели, повторы и любой путь отката. Если воркер вызывает больше одной модели, держите эту цепочку видимой.
Одного пропущенного перехода достаточно, чтобы появилась слепая зона. Запрос входит чисто, а потом исчезает внутри job runner или помощника ИИ, и команда начинает гадать. В этот момент лучше остановить релиз и починить трассировку, потому что реальный прод-трафик только усложнит поиск проблемы.
Если эти проверки пройдены, политика обычно выдерживает давление.
Дальнейшие шаги для экономной трассировки
Не разворачивайте это везде в первый же день. Хорошая политика трассировки обычно начинается с одного загруженного пути запроса, а потом растёт после того, как вы проверите, что именно сохранили.
Начните с трёх правил:
- Сохраняйте каждую трассировку, которая заканчивается ошибкой.
- Сохраняйте трассировки для запросов, которые медленнее вашего целевого p95.
- Сохраняйте трассировки, в которые входит вызов ИИ.
Эти правила ловят большую часть важных сбоев, не заставляя хранить каждую трассировку. Ошибки быстро показывают, что что-то сломалось. Медленные запросы показывают боль пользователя ещё до аварии. Для вызовов ИИ нужно отдельное правило, потому что стоимость, задержка, повторы и проблемы с промптом могут прятаться внутри вполне обычного запроса.
Выберите один путь с устойчивым трафиком, например регистрацию, checkout или обработку документов. Запустите на нём политику на неделю. Следите за двумя числами: сколько трассировок вы сохраняете и как часто эти трассировки объясняют реальную проблему без дополнительного копания. Если инженеры всё равно бегут в логи при каждом инциденте, правило слишком мягкое или спаны слишком бедные.
Затем сравните сохранённые трассировки с инцидентами за последний месяц. Вам нужно прямое совпадение. Если в прошлом месяце был таймаут платежа, задержка очереди или плохой ответ модели, вы должны суметь указать на трассировку, которая выжила бы при новой политике. Если не можете — исправьте правило до масштабирования.
После этого перенесите политику на следующий загруженный путь, а не на всю систему сразу. Маленькие шаги помогают увидеть, какой сервис создаёт шум, какой теряет контекст и где счёт за трассировку начинает расти.
Если на этом этапе вам нужен второй взгляд, Oleg Sotnikov на oleg.is просматривает бюджеты трассировки, границы сервисов и пути вызовов ИИ как Fractional CTO. Такой разбор особенно полезен, когда трассировки уже идут потоком, но вам всё ещё нужно сохранить те, что объясняют реальные инциденты, и убрать те, которые никто не читает.
Часто задаваемые вопросы
Почему трассировки исчезают, когда трафик растёт?
Трафик быстро выявляет слабые правила семплирования. Если у вас один и тот же процент для всех запросов, редкие ошибки и медленные пути исчезают как раз тогда, когда нагрузка растёт. Один шумный сервис тоже может съесть почти весь бюджет. Сохраняйте все ошибки, сохраняйте медленные запросы, повышайте долю для ИИ-путей и жёстко урезайте шумные health check и polling.
Должен ли каждый сервис семплировать трассировки сам по себе?
Нет. Пусть edge-сервис принимает одно решение о трассировании и передаёт его дальше во все API-вызовы, сообщения очереди и воркеры. Если каждый сервис подбрасывает свою монетку, вы получаете сломанные трассировки и платите за фрагменты, которые не объясняют весь запрос.
Что должен включать каждый спан?
Держите базу маленькой и одинаковой. Добавьте стабильное имя сервиса, шаблон маршрута или название операции, статус результата и общую длительность в миллисекундах. Отмечайте повторы, переходы через очередь и внешние вызовы, а затем добавляйте tenant, регион или название модели только тогда, когда это действительно помогает понять трассировку.
С какой базовой доли семплирования лучше начать?
Начните с низкой фоновой доли, обычно 2%–5% обычного трафика. Так у вас всегда будет стабильный фоновой срез без быстрого заполнения хранилища. Потом добавьте правила, которые сохраняют 100% ошибок и медленных запросов.
Как выбрать порог для медленного запроса?
Выберите одно число, которое легко запомнить, и применяйте его к каждому типу запроса. Для пользовательских API многие команды начинают примерно с 1–2 секунд, а для фоновых задач можно поставить более высокий порог. Сохраняйте всё, что выходит за эту границу, а потом посмотрите на полную неделю трафика и скорректируйте правило, если шума слишком много или реальные проблемы всё ещё теряются.
Почему для вызовов ИИ нужна более высокая доля семплирования?
Вызовы модели ведут себя куда менее предсказуемо, чем простой запрос к кэшу или базе. Они добавляют задержку, повторы, разветвления и стоимость в рамках одного и того же запроса, поэтому случайная низкая доля семплирования слишком многое пропускает. Если вы сохраняете спан ИИ, сохраняйте и родительский запрос, иначе потеряется причина, по которой этот вызов вообще произошёл.
Как оставить queue jobs и workers в одной трассировке?
Переносите контекст трассировки вместе с сообщением, а не только в HTTP-заголовках. Сохраняйте trace ID и span ID в метаданных или payload очереди, а затем пусть воркер продолжает ту же трассировку как дочернюю. То же самое делайте для cron-запусков и разветвлённых задач, чтобы один запрос по-прежнему читался как одна история.
Стоит ли хранить только медленный или упавший спан?
Сохраняйте всю трассировку. Один медленный спан биллинга или неудачный вызов модели показывает только часть истории, а полная трассировка показывает, что было до него и после. Именно полный путь обычно и отвечает, виноваты ли аутентификация, биллинг, повторы или внешний вызов.
Какие ошибки создают самые большие слепые зоны?
Команды обычно ломают трассировки предсказуемыми способами. Они позволяют каждому сервису семплировать самому по себе, используют одно плоское правило 1% для всего, сохраняют спаны ИИ, но теряют родительский запрос, либо теряют контекст трассировки на повторах, в очередях и при откате кэша. Изменения порогов тоже вредят, если делать их без короткого испытания.
Что стоит проверить перед запуском новой политики семплирования?
Перед релизом отправьте три тестовых запроса: один должен упасть, второй — работать медленно, а третий — пройти через все основные этапы. Убедитесь, что вы быстро находите полную трассировку, можете проследить её через воркеры и вызовы модели, а также видите точный медленный спан после добавления задержки в одну зависимость. Потом запустите короткий всплеск трафика и проверьте, что бюджет трассировок остаётся в пределах лимита.


