Самостоятельно размещённый GitLab для стартапов: когда это окупается
Разбираетесь, нужен ли стартапу self-hosted GitLab? Узнайте, когда одна система для кода, CI и registry экономит время, а когда администрирование обходится дороже.
Содержание
Почему у команд накапливается слишком много инструментов
Большинство команд не выбирают раздутый набор инструментов специально. Он накапливается по одному маленькому решению за раз.
Один инструмент хранит Git. Другой запускает CI. Третий хранит контейнерные образы. Четвёртый ведёт задачи. Каждый выбор сам по себе выглядит разумно, поэтому никто не останавливается и не спрашивает, как будет ощущаться вся эта схема через полгода.
Боль редко появляется в первый день. Она проявляется, когда работа переходит из одной системы в другую. Разработчик пушит код в одном месте, пайплайн запускается в другом, собранный образ попадает в registry со своими правилами доступа, а тикет лежит на отдельной доске. И вот одна сломанная доставка означает проверку четырёх мест.
Все эти лишние переходы создают много мелких задач: больше входов в систему, больше правил доступа, больше токенов и webhook, и больше страниц настроек, которые понимает только один человек. По отдельности это не выглядит серьёзно. Вместе это съедает часы каждую неделю.
Сложнее становится и разбирать сбои сборки, когда следы лежат в разных системах. Можно увидеть коммит в одной вкладке, логи CI в другой, а отсутствующий тег образа — в registry, который никто не открывал на прошлой неделе. Исправление часто простое. Найти проблему — вот что сложно.
Небольшие команды чувствуют это быстрее крупных. Обычно у них нет отдельной DevOps-команды, которая могла бы переварить весь этот хаос. Те же два-три человека пишут код, чинят пайплайны, управляют секретами и отвечают на вопросы по продукту. Если один инженер становится единственным человеком, который понимает всю схему, каждый отпуск и каждый больничный превращаются в риск.
Именно поэтому self-hosted GitLab начинает казаться привлекательным для стартапов. Дело не только в меньшем числе поставщиков. Дело в меньшем количестве разрывов между шагами, в меньшем числе мест, где теряется контекст, и в меньшем количестве админских задач, которые незаметно становятся нормой. Если ваша команда постоянно говорит: «Я знаю, что сборка где-то прошла, мне только нужно её найти», вы уже платите за эту проблему.
Что GitLab собирает в одном месте
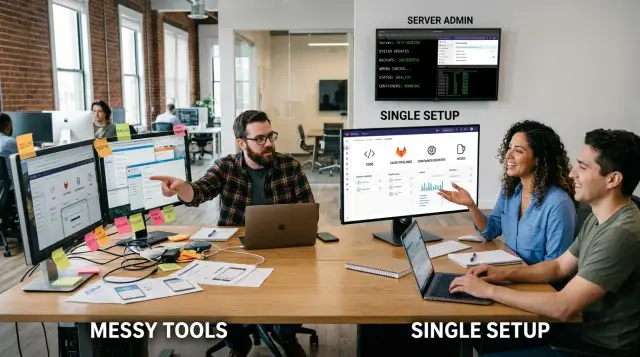
Многое из того, что тормозит стартапы, сводится к скучной проблеме: работа живёт в слишком большом числе систем. Код в одном приложении, merge requests в другом, логи CI где-то ещё, а контейнерные образы лежат в registry со своими правилами. Люди тратят время только на то, чтобы восстановить картину произошедшего.
GitLab собирает несколько таких задач в одной системе. Репозиторий, merge requests, CI-пайплайны, package и container registry, issues и базовый контроль доступа могут находиться в рамках одного проекта. Для маленькой команды это часто важнее, чем любая продвинутая функция.
Когда кто-то пушит код, остальная цепочка может оставаться в том же месте. Ветка уже принадлежит проекту. Merge request показывает ревью. Пайплайн запускается по этому репозиторию. Образ попадает в registry проекта. Коллега может отследить изменение, не прыгая между вкладками и не сверяя названия по памяти.
Общий контекст важнее, чем кажется. Нужно меньше glue code, меньше цепочек webhook и меньше разовых правок, чтобы держать названия, токены и права доступа синхронизированными между продуктами. Стартап обычно ощущает эту пользу сразу.
Управление доступом тоже становится проще. Один каталог пользователей и одна модель прав доступа означают меньше мелких ошибок, например когда доступ к образам случайно получают не те люди или когда CI-доступ не убрали после ухода подрядчика. Такие ошибки кажутся мелкими, пока их не накопится слишком много.
Ещё один плюс — меньше переключений. Если деплой падает, разработчик может открыть merge request, посмотреть пайплайн, проверить артефакт и взглянуть на тег образа из одного и того же проекта. Это экономит реальное время. Даже пять минут на каждое изменение быстро складываются в течение недели.
Вот в чём реальная ценность GitLab CI и container registry в одном месте. Речь не только о стоимости подписки. Речь о том, чтобы держать код, пайплайны, образы и права доступа достаточно близко друг к другу, чтобы компания из шести человек могла проследить изменение от коммита до деплоя без игры в детектива в десяти вкладках браузера.
Когда self-hosting имеет смысл
Self-hosted GitLab лучше всего подходит, когда команда уже воспринимает инфраструктуру как обычную работу. Если вы обслуживаете Linux-серверы, обновляете их по графику, делаете резервные копии и знаете, кто просыпается, когда на диске заканчивается место, добавить GitLab — это логичное продолжение того, что вы уже делаете. Он намного менее привлекателен, если каждая серверная проблема превращается в пожар.
Контроль — ещё одна веская причина. Некоторые команды хотят держать код, контейнерные образы, runners и правила доступа под одной крышей. Это особенно важно, когда вы работаете с данными клиентов, используете закрытые сети или вам нужны жёсткие ограничения на то, кто может добраться до машин сборки. В такой схеме, когда GitLab находится рядом с остальным стеком, повседневная работа может стать проще.
Это также окупается, когда ваши сборки идут по повторяемой схеме. Стартап с несколькими сервисами, одним потоком деплоя и стабильными шагами тестирования может много выиграть от общих runners, общих шаблонов и одного registry. Вы тратите меньше времени на склейку инструментов и меньше времени на поиски того, где именно живёт сломанная сборка, образ или настройка доступа.
Простой тест помогает принять решение. Self-hosting обычно подходит, если верно большинство пунктов ниже:
- Ваша команда уже обслуживает обновления, резервные копии и мониторинг других систем.
- В репозиториях похожие шаги сборки и деплоя.
- Вам нужна одна модель доступа для кода, CI и образов.
- Вы планируете использовать эту схему как минимум год.
Последний пункт важнее, чем многие основатели ожидают. Переезжать в GitLab, а потом съезжать оттуда через шесть месяцев — значит дважды тратить время. Польза появляется тогда, когда команда достаточно долго держит один рабочий процесс, чтобы стандартизировать его.
Хороший пример — продуктовая команда из шести человек. Если у них уже есть staging и production, Docker-образы собираются одинаково для всех сервисов, а для внутренних деплоев нужны private runners, self-hosting может убрать множество мелких раздражителей. Одно место для репозиториев, пайплайнов и образов управляется проще, чем пять отдельных инструментов с пятью разными моделями доступа.
Когда администрирование съедает выгоду
GitLab может заменить целую связку отдельных инструментов. Но есть один простой подвох: кто-то должен поддерживать его в норме каждую неделю. Если никто не отвечает за обновления, резервные копии, хранилище, доступ и сбои runners, мелкие проблемы накапливаются, пока не начинают мешать работе.
Стартапы чаще всего замечают это тогда, когда основатели становятся администраторами по умолчанию. Основатель чинит один сломанный runner, а потом весь пятничный вечер освобождает место на диске, проверяет логи и перезапускает задания. Такая сделка быстро становится плохой, если продажи, найм или работа над продуктом начинают страдать из-за того, что сервер постоянно требует внимания.
Ситуация становится хуже, когда пайплайны зависят от слишком большого числа внешних частей. Возможно, сборки берут пакеты из private mirror, отправляют образы в отдельный registry, подтягивают секреты из другой службы и полагаются на кастомные скрипты, которые понимает только один инженер. GitLab по-прежнему находится в центре, но каждый сбойный пайплайн отправляет команду сразу в четыре системы искать причину. Вы не убрали раздутый стек. Вы просто спрятали его за одним логином.
Краткие простои тоже бьют сильнее, чем многие ожидают. Если GitLab падает, одновременно может остановиться ревью кода, сборка и деплой. Даже 20 минут простоя могут заморозить релиз или заставить инженеров ждать, пока они уже закончили свою часть работы.
Обычно первые тревожные сигналы выглядят так:
- Ни у кого нет письменного плана для резервных копий, тестов восстановления и обновлений.
- Состояние runners зависит от того, заметит ли один человек сбой в чате.
- Команда продолжает добавлять разовые правки, чтобы пайплайны наконец проходили.
- Основатели тратят на серверные задачи больше времени, чем на продуктовые решения.
Self-hosted GitLab окупается тогда, когда администрирование остаётся скучным и предсказуемым. Если оно постоянно превращается в аварийную работу, математика меняется быстро. В таком случае проще взять hosted-вариант или помощь человека, который уже обслуживает GitLab в масштабе, чем терять часы команды.
Как принять решение по шагам
Начните с аудита времени, а не со списка функций. Self-hosted GitLab стоит усилий тогда, когда он убирает ежедневное трение, а не просто выглядит аккуратнее на схеме.
Запишите все инструменты, с которыми ваша команда работает для кода, CI, контейнерных образов, секретов и контроля доступа. Учитывайте и мелочи, о которых часто забывают: отдельный host для runners, password vault или скрипт, которым кто-то переносит образы между registry.
Потом посмотрите, где ломаются переходы. Если pull requests живут в одном месте, пайплайны — в другом, а образы — в третьем, посчитайте реальные точки отказа: сломанные webhook, проблемы с правами, дублирующиеся пользователи, нерабочие токены, медленное переключение контекста и время, теряемое во время релизов.
- Составьте список всех инструментов и их владельцев.
- Отметьте сбои между инструментами за последний месяц.
- Оцените время на обновления, резервные копии, рост хранилища, обслуживание runners и доступы пользователей.
- Сначала перенесите один некритичный проект.
- Сравните сэкономленные часы с часами, потраченными на поддержку GitLab.
Будьте предельно честны в оценке администрирования. Самостоятельно размещённая схема требует патчей, резервных копий, которые вы реально тестируете, планирования места под артефакты и образы, обслуживания runners и некоторой работы по безопасности. Если никто в команде не может спокойно тратить на это пару часов в неделю, математика быстро меняется.
Пилот расскажет больше, чем длинный спор. Возьмите один активный проект с обычными коммитами, небольшим пайплайном и контейнерной сборкой. Запустите его на несколько недель. Посмотрите, как часто команда просит помощи, сколько времени занимают пайплайны и становится ли выпуск проще или просто другим.
Простые часы помогают принять решение. Если команда экономит 12 часов в месяц за счёт сокращения раздутого набора инструментов, но один основатель теперь тратит 10 часов на администрирование GitLab, это почти не победа. Если компетентный инженер может держать эту нагрузку на уровне двух-трёх часов, сделка выглядит намного лучше.
Выбирайте схему, которая даёт команде меньше движущихся частей, не превращаясь в новую полставки.
Пример команды из шести человек
Возьмём небольшую SaaS-команду из шести человек. Они выпускают один основной продукт, каждую неделю выкатывают исправления и уже чувствуют, как тормозит использование отдельных инструментов для репозиториев, сборок и контейнерных образов. На бумаге ничего не сломано. На практике люди постоянно теряют время на мелкие нестыковки.
У одного истекает токен, и сборки останавливаются. Меняется webhook, и статусы перестают появляться там, где их ждут. Сборка проходит, но registry образов не совпадает с веткой или коммитом, который команда считает правильным. Кто-то ещё ломает build context, и теперь два разработчика по полчаса гадают, проблема в репозитории, пайплайне или шаге с образом.
Это трение не выглядит драматично, но быстро накапливается. В команде из шести человек потеря даже 20 минут в день на нескольких людей может съесть заметную часть спринта.
Тогда они делают один небольшой шаг. Они не мигрируют сразу все продукты, все runners и все старые репозитории. Они берут один активный сервис и переносят только его в self-hosted GitLab. Остальное остаётся на месте, пока пилот не докажет свою пользу.
Разницу легко почувствовать. Merge request, лог пайплайна и собранный образ теперь живут в одном потоке работы. Когда сборка падает, команда открывает одно место и видит коммит, вывод задания и тег образа вместе. Уже этого достаточно, чтобы сильно уменьшить низкоуровневую путаницу.
Деплой тоже проще отследить. Если версия 1.8.4 ведёт себя странно в staging, команда может пройти по цепочке обратно к точному пайплайну и образу, не прыгая между инструментами и не перепроверяя старые уведомления.
Через месяц они спрашивают не «Нравится ли нам GitLab больше?», а более жёсткий вопрос: может ли один человек спокойно это поддерживать?
Если один инженер может заниматься обновлениями, проверкой runners, резервными копиями и очисткой диска, не становясь для команды полставки администратором, они оставляют схему. Если тот же человек каждую пятницу чинит runners или читает заметки к обновлению, выгода исчезает. Для маленькой команды именно это и есть важная граница.
Ошибки, которые команды совершают в самом начале
Чаще всего команды попадают в неприятности, когда воспринимают self-hosted GitLab как большой переключатель, а не как постепенный запуск. Они переносят все репозитории за одну неделю, меняют процесс релиза и просят всю команду адаптироваться сразу. Это быстро создаёт напряжение. Один сломанный пайплайн или отсутствующее право доступа может остановить работу для всех.
Более спокойный подход работает лучше. Начните с одного активного репозитория, одного низкорискового сервиса и одной небольшой группы разработчиков. Пусть они первыми найдут шероховатости. Потом копируйте то, что сработало.
Ещё одно слепое пятно — резервные копии. Новый сервер может выглядеть стабильным неделями, и команда решает, что jobs резервного копирования работают нормально. А потом слишком поздно выясняется, что файл бэкапа есть, но процесс восстановления падает или занимает намного больше времени, чем ожидалось. Резервная копия считается настоящей только тогда, когда вы проверили восстановление.
Хранилище пропускают по той же причине. Репозитории обычно маленькие. Build cache, job artifacts и container images — нет. Команда, которая на каждой ветке собирает несколько образов, может забить диск намного быстрее, чем ожидает, особенно если GitLab CI и container registry включены с первого дня. Итог неприятный: сбои push, сломанные задания и ночная очистка.
Настройку runners тоже часто откладывают в корзину «сделаем потом». Это звучит безобидно, пока задания не начинают копиться, а все ждут десять минут, чтобы стартовало трёхминутное задание. Сервер GitLab может быть в порядке, но команда всё равно чувствует медлительность, потому что runners слишком слабые, неправильно размечены или их просто мало.
Более безопасный старт
- Сначала перенесите один-два репозитория.
- Проверьте полное восстановление из резервной копии до того, как команда начнёт зависеть от системы.
- Оцените место под образы, кэш и артефакты, а не только исходный код.
- Добавьте достаточно runners для обычных пиковых часов, а не только для тихих дней.
- Оставьте стандартный процесс, пока команда не поработает с ним какое-то время.
Последняя распространённая ошибка — слишком ранняя кастомизация. Команды добавляют собственные шаблоны, правила согласования, трюки с ветками и схемы именования ещё до того, как кто-то освоит стандартный поток. Обычно это усложняет обучение, а не упрощает его. Начните с скучной настройки. Меняйте её только тогда, когда у команды появится реальная боль, которую нужно лечить.
Быстрые проверки перед переездом
Слишком ранний переезд создаёт новый хаос: инструментов на бумаге меньше, а работы каждую неделю — больше. Небольшой команде стоит относиться к переходу на GitLab как к любому другому изменению продукта. Если никто им не владеет, процесс начнёт расползаться.
Начните с понятной ответственности. Один человек не обязан делать всё вечно, но один человек должен отвечать за обновления, резервные копии и тесты восстановления. Если резервная копия запускается каждую ночь, но никто не проверял восстановление, у вас не план бэкапа. У вас надежда.
То же относится и к runners. Решите заранее, где они будут жить, ещё до миграции. Runner на случайной VM часто превращается в забытую машину со старыми пакетами и слишком широким доступом. Выберите host, определите, кто ставит патчи, и задайте простой график обновлений.
Короткая проверка перед переездом помогает держать всё честно:
- Назовите человека, который отвечает за обновления, jobs резервного копирования и одно упражнение по восстановлению.
- Решите, где будут работать runners, и кто обновляет host и образы runners.
- Задайте лимит хранения для артефактов и container images, чтобы хранилище не росло незаметно.
- Приведите пайплайны к повторяемому прохождению без ручных правок.
- Запишите, как вы откатитесь, если пилот добавит работы вместо того, чтобы убрать её.
Хранилище — это то, что команды чаще всего пропускают. Артефакты, логи и container images накапливаются быстро, особенно когда каждая ветка собирает образ. Задайте правила хранения до первого загруженного месяца. Даже грубый лимит лучше, чем ждать предупреждения о диске.
Качество пайплайнов не менее важно. Если ваши текущие CI-задания зависят от знаний, которые хранятся только у команды в голове, self-hosting это не исправит. Он просто сделает проблему удобнее для владельца, но проблемой она останется. Приведите пайплайн к простому пути: сборка, тест, упаковка, деплой. Если люди часто перезапускают задания вручную или в спешке меняют переменные, сначала исправьте это.
Самый безопасный путь — пилот с планом отката. Перенесите один сервис, ведите заметки две-три недели и считайте дополнительное администрирование. Если команда тратит больше времени на обслуживание, чем на использование, остановитесь и начните заново.
Что делать дальше
Сделайте первый шаг маленьким. Если self-hosted GitLab выглядит подходящим вариантом, начните с одного активного репозитория, одного runner и одного числа, которое покажет, сработал ли пилот. Выберите что-то конкретное: время деплоя, количество инструментов, которые трогают на одном релизе, или часы, уходящие каждую неделю на исправление CI.
Этот небольшой тест быстро покажет компромисс. Если один репозиторий может пройти путь от коммита до пайплайна и хранения образа в одном месте, схема, возможно, заслуживает своего места. Если runner падает дважды в неделю и никто не хочет брать его на себя, это тоже полезный ответ.
Перед тем как расширять схему на всю команду, запишите то, что люди обычно пропускают:
- как вы делаете резервные копии данных GitLab и куда они попадают
- как вы восстанавливаете их на чистой машине
- как вы обновляетесь, не ломая работу в середине недели
- кто разбирает проблемы с runners, registry или входом в систему
Сделайте эти заметки короткими, а потом проверьте их один раз. План резервного копирования по-настоящему существует только тогда, когда кто-то может из него восстановиться.
Дайте пилоту месяц. Этого достаточно, чтобы поймать скучные проблемы: drift у runners, рост хранилища, медленные обновления и мелкие админские задачи, которые накапливаются. В конце месяца сравните результат с исходной точкой.
Оставляйте только то, что экономит реальные деньги или время. Если GitLab заменяет два-три других сервиса, ежедневная работа может стать проще. Если команде всё равно нужны старые сервисы, самостоятельный хостинг GitLab может добавить больше забот, чем убрать.
Если хотите получить второе мнение перед тем, как окончательно решиться, Oleg Sotnikov на oleg.is консультирует стартапы по lean infrastructure, CI/CD и AI-first software operations. Он работал с self-hosted GitLab, runners и production observability в масштабе, поэтому обычно может быстро сказать, подходит ли схема маленькой команде или более лёгкий вариант окажется проще в жизни.
Хороший пилот заканчивается простым ответом: расширять, оставить узким или отказаться.
Часто задаваемые вопросы
Подходит ли самостоятельно размещённый GitLab для небольшого стартапа?
Да, если ваша команда уже спокойно обслуживает серверы. Самостоятельно размещённый GitLab особенно полезен, когда одни и те же люди уже отвечают за обновления Linux, резервные копии, мониторинг и Docker-сборки. Если любой серверный вопрос сразу превращается в аврал, hosted-вариант обычно разумнее.
Когда самостоятельно размещённый GitLab действительно экономит время?
Он окупается, когда убирает ежедневные мелкие неудобства. Если вашей команде приходится прыгать между отдельными инструментами для репозиториев, CI, хранения образов и правил доступа, GitLab может сэкономить время, потому что всё находится в одном месте. Выигрыш обычно заметен в меньшем числе передач между системами, меньшем количестве сломанных токенов и более быстрой диагностике проблем.
Что GitLab может заменить для стартап-команды?
GitLab может заменить репозиторий, merge requests, CI-pipelines, container registry, issues и управление доступом в одной системе. Это уменьшает количество связок и webhook-цепочек, которые небольшие команды часто строят между отдельными продуктами. При этом отдельные инструменты для секретов, облачного хостинга или observability вам всё ещё могут понадобиться.
Стоит ли переносить все репозитории сразу?
Не делайте миграцию одним большим скачком. Начните с одного активного репозитория, одного обычного пайплайна и одного runner. Так команда безопасно найдёт слабые места до того, как вы начнёте менять все проекты сразу.
Когда админская работа перекрывает пользу?
Администрирование начинает съедать выгоду, когда один человек тратит слишком много времени на обновления, резервные копии, очистку диска, сбои runners и вопросы доступа. Если основатель теряет пятницы на серверные дела, система стоит дороже, чем приносит пользы. Небольшой команде нужна спокойная, предсказуемая поддержка, а не постоянное тушение пожаров.
Сколько времени стоит запускать пилот перед решением?
Дайте пилоту около месяца. Обычно этого достаточно, чтобы проявились скучные, но важные проблемы: рост хранилища, drift у runners, медленные обновления и пробелы в восстановлении. Двухдневный тест часто выглядит отлично просто потому, что не успевает показать реальные рабочие привычки команды.
Что нужно измерять во время пилота?
Считайте обычные часы, а не количество функций. Измеряйте, сколько инструментов люди трогают на одном релизе, сколько времени занимает деплой, как часто CI падает по причинам настройки и сколько часов кто-то тратит на поддержку GitLab. Если пилот экономит время и не превращается в ещё одну полставки администратора, можно двигаться дальше.
Нужен ли отдельный DevOps-инженер, чтобы самостоятельно разместить GitLab?
Нет, но вам обязательно нужен понятный владелец процесса. Один человек должен отвечать за обновления, резервные копии, тесты восстановления и состояние runners, даже если в работе помогают другие. Если эти задачи ничьи, система очень быстро начнёт расползаться.
Какие проблемы обычно появляются первыми после миграции?
Чаще всего первыми бьют по больному месту хранилище и runners. Артефакты, логи, кэши и container images растут быстрее, чем ожидают многие команды, а слабые runners создают очередь даже для коротких задач. Настройте правила хранения заранее и рассчитывайте runners на часы пик, а не на тихие дни.
Когда лучше не переходить на самостоятельно размещённый GitLab и оставить hosted-вариант?
Оставайтесь на hosted-решении, если у команды нет времени на обслуживание, если пайплайны меняются каждую неделю или если система по-прежнему зависит от слишком многих внешних сервисов. Если GitLab лишь прячет хаос за одним входом, вам всё равно придётся искать ошибки по нескольким системам. В таком случае более лёгкий стек или внешняя помощь обойдутся дешевле.


