Fan-out событий S3 с очередями и workers, которые можно отследить
Fan-out событий S3 становится проще, когда загрузки отправляются в очередь, а workers обрабатывают каждый шаг. Узнайте о понятной схеме, которую легко отслеживать.
Содержание
Почему прямые триггеры S3 быстро становятся неудобными
Прямые триггеры S3 выглядят аккуратно, когда поток небольшой. Одна загрузка приходит, несколько функций запускаются, и схема кажется опрятной. Но реальные системы долго такими не остаются.
Один PDF может запускать извлечение текста, генерацию превью, проверку на malware и обновление базы данных. У каждого шага свои таймауты, правила повторных попыток, логи и сценарии отказа. Если один шаг выполнится дважды, можно получить дублирующиеся записи, двойное списание или файл, который обработался лишь частично.
Повторные попытки добавляют ещё один слой путаницы. Они помогают при кратких сбоях, но при этом скрывают первую ошибку. К тому моменту, как кто-то откроет логи, он может увидеть timeout на третьей попытке и пропустить настоящую причину с первого раза, например неверные метаданные или ошибку парсинга.
Потом логирование превращается в следующую головную боль. Одна загрузка может затронуть события S3, метрики очереди, логи воркеров и записи в базе данных. Ни один из этих источников не показывает всю картину целиком. Разработчик может потратить 40 минут, переключаясь между вкладками, чтобы ответить на простой вопрос: мы этот файл обработали, пропустили или сломались на середине?
Команды поддержки чувствуют это не меньше. Клиент спрашивает, что случилось с файлом, а команда может ответить только обрывками. Что-то сработало. Что-то повторилось. Один шаг, возможно, завершился. Полный путь от загрузки до результата всё ещё не виден.
Поэтому прямые триггеры редко остаются простыми под реальной нагрузкой. Для демо они подходят. Но когда нужны понятная ответственность, меньше дублей и возможность отследить один файл без догадок, всё быстро усложняется.
Паттерн, который остаётся понятным
Более чистая схема начинается с одного простого правила: когда файл попадает в S3, отправьте одно сообщение в одну входную очередь.
Не позволяйте событию загрузки решать весь workflow. Первый шаг должен быть скучным. А потом один intake worker читает это сообщение и решает, что делать дальше.
Этот worker может посмотреть на тип файла, размер, источник или метаданные и создать только те задачи, которые действительно нужны. Для PDF это может быть извлечение текста и картинки-превью. Для CSV — проверка и импорт. Для изображения — изменение размера и модерация.
Так вся логика ветвления остаётся в одном месте. Если правила потом изменятся, вы обновите intake worker, а не будете искать нужные триггеры по всей системе.
Дальше каждая следующая задача должна делать только одно дело. Worker, который только извлекает текст, легко повторить. Worker, который только делает миниатюры, легко масштабировать. А worker, который за один запуск пытается и сканировать, и конвертировать, и классифицировать, и уведомлять, обычно становится слишком сложным для понимания.
Здесь хорошо работает простая модель: одна загрузка, одна родительская запись и несколько дочерних задач.
Создайте родительскую запись сразу, как только файл попал в систему. Каждая дочерняя задача должна нести тот же parent ID, а также свой job ID и status. Так вы быстро ответите на вопросы, которые люди реально задают: какая загрузка запустила эту работу, какие задачи завершились, какая сломалась и что нужно повторить.
Такая структура помогает и с защитой от дублей. Если S3 пришлёт одно и то же событие дважды или worker повторит попытку после timeout, система сможет проверить, не создала ли она уже дочерние задачи для этого parent ID.
Вам не нужен огромный стек, чтобы всё это работало хорошо. Часто достаточно очереди, intake worker, нескольких узкоспециализированных workers и небольшой job table. На бумаге это может выглядеть медленнее, чем прямые триггеры. На практике такую схему проще отслеживать, проще тестировать и гораздо легче чинить в 2 часа ночи.
Что делает каждый элемент
У понятного upload pipeline всего несколько частей, и у каждой своя узкая задача.
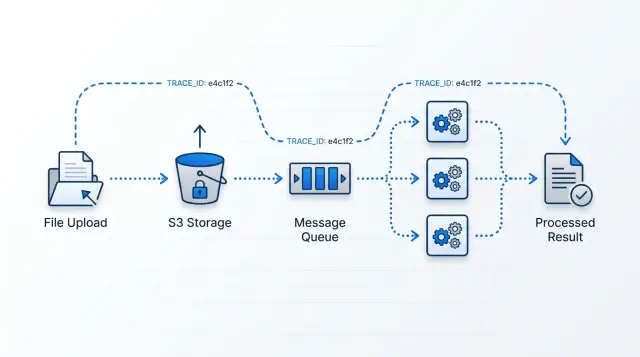
S3 хранит файл и отправляет одно событие о входящей загрузке. Это событие должно означать только одно: «пришёл новый файл». S3 не должно вести себя как workflow engine. Как только хранилище начинает само решать, что делать дальше, отладка становится сложнее.
Очередь — это буфер. Если приходит 20 файлов, workers справляются. Если приходит 20 000 файлов, очередь удерживает лишнюю работу вместо того, чтобы заставлять каждый worker масштабироваться мгновенно. Она также даёт простой обзор того, что ждёт, что выполняется и что застопорилось.
Router worker читает событие о входящем файле и создаёт дочерние задачи, которые этому файлу действительно нужны. Одному файлу могут понадобиться «extract text», «make preview images» и «scan metadata». Для другого типа файла набор будет другим. Router должен оставаться лёгким. Он принимает решение, записывает его и передаёт работу дальше. Сам он не должен выполнять тяжёлую обработку.
Task workers выполняют реальную работу, но каждый worker должен фокусироваться на одном типе задачи. Это звучит строго, но быстро окупается. PDF text extractor ломается не так, как thumbnail generator. Если оба задания живут в одном коде worker’а, небольшие изменения начинают ломать несвязанные задачи.
Job table — это общая память всего pipeline. В ней хранятся status, детали ошибки, число попыток, временные метки и пути к результатам. Когда кто-то спрашивает: «Что случилось с этой загрузкой?», вы должны открыть одну запись и увидеть понятный путь: файл получен, задачи созданы, worker запустился, worker завершился с ошибкой или успехом, результат записан.
Небольшой job table обычно требует только базового набора полей: ID исходного файла или путь к объекту S3, тип задачи и текущий статус, число повторных попыток, последнее сообщение об ошибке, путь к результату, а также время создания и обновления.
Когда эти части разделены, каждая остаётся скучной. И это хороший знак. Скучные системы проще обслуживать и дешевле чинить.
Как работает поток
Хороший upload pipeline — это в основном дисциплина. Каждый файл должен проходить один путь, и каждый шаг должен оставлять достаточно следов, чтобы потом можно было объяснить, что произошло.
Начните с имени объекта. Сохраняйте файл по пути, который понятен людям, а не только машинам. Имя вроде incoming/2026/04/customer-481/invoice-8842.pdf гораздо проще отлаживать и чистить, чем случайная строка.
Как только загрузка приземлилась, создайте для этого файла один trace ID. Используйте его везде: в записи job, логах, сообщениях очереди и в результате, который будет записан позже. Если клиент спросит: «Что случилось с моим файлом?», этот trace ID должен быстро дать ответ.
Держите сообщение в очереди маленьким. Чаще всего там нужны только имя bucket, путь к объекту, trace ID и, возможно, ещё одно поле вроде типа файла или account ID. Файл уже хранится в S3, так что нет смысла набивать очередь тяжёлыми payload’ами.
Обычный поток выглядит так:
- S3 получает загрузку, а приложение создаёт запись job со статусом
queued. - Приложение отправляет короткое сообщение в очередь с местоположением файла и trace ID.
- Worker забирает сообщение, помечает job как
processingи записывает время начала. - Worker читает файл из S3, выполняет работу и записывает результат по пути для результатов.
- Worker обновляет job до
doneилиfailed, при необходимости добавляя детали ошибки.
Это обновление статуса важнее, чем многие команды ожидают. Без него людям приходится читать логи из трёх мест, чтобы понять, стартовал ли worker, упал или завершился. Небольшая таблица jobs часто экономит больше времени, чем сложная автоматизация.
Повторные попытки должны оставаться незаметными, пока они помогают. Если worker сталкивается с короткой сетевой проблемой или временным сбоем API, дайте очереди несколько раз повторить попытку. Когда попытки закончатся, отправьте сообщение в dead letter queue и поднимите alert.
Так шум снижается, а реальные сбои становится легче заметить. Одна загрузка, один trace ID, одна запись job, один понятный результат.
Простой пример с PDF
Представьте, что клиент загружает в S3 PDF-счёт. Приложение сразу создаёт запись файла с file ID, customer ID и статусом вроде «processing». Затем событие загрузки создаёт отдельные задачи вместо того, чтобы просить одного worker’а сделать всё за один проход.
Одна задача уходит к text worker. Он открывает PDF, извлекает текст и сохраняет его, чтобы приложение потом могло искать по нему. Если кто-то ищет номер счёта или имя поставщика, приложение быстро находит файл.
Вторая задача уходит к image worker. Он рендерит первую страницу как изображение-превью, и списки документов, а также административные экраны, становятся гораздо удобнее для просмотра.
Третья задача уходит к validation worker. Он проверяет простые вещи: открывается ли файл, действительно ли это PDF и похож ли он на счёт, а не на договор или папку с фотографиями. Сначала эту проверку можно сделать очень простой, например искать типичные признаки счёта: суммы, даты, позиции и данные поставщика.
Польза в том, что эти workers не зависят друг от друга. Если генерация превью идёт медленно, извлечение текста всё равно может завершиться. Если проверка не проходит, приложение всё равно может сохранить текст и превью, пометив документ на ручную проверку.
Приложение должно помечать файл как готовый только тогда, когда каждая обязательная задача вернулась с результатом. Небольшой status table обычно достаточно хорош, чтобы отслеживать текст, превью, валидацию и общий статус файла.
Именно этот последний шаг важен. Не помечайте загрузку завершённой только потому, что один worker справился. Делайте это только тогда, когда все ожидаемые результаты уже есть.
Такой паттерн остаётся понятным. Если ломается worker превью, вы повторяете только эту задачу. Вам не нужно заново обрабатывать весь PDF.
Как отследить один файл от начала до конца
Многие команды усложняют tracing сильнее, чем нужно. Один файл должен нести один ID с момента, когда он попал в S3, и до завершения последнего worker’а.
Создайте этот ID в момент загрузки. Поместите его в metadata объекта, а затем скопируйте то же значение в каждое сообщение очереди, созданное из этой загрузки. Если один PDF создаёт задачу извлечения текста, задачу генерации миниатюры и задачу индексации, все три всё равно должны нести один и тот же parent trace ID.
Достаточно простого формата, например trace_01J8.... Красивые названия не помогают. Помогает последовательность.
Поместите ID везде
Если worker пишет десять строк логов по одной задаче, все десять должны содержать trace ID. Не полагайтесь только на имена файлов. Имена меняются, пользователи загружают дубликаты, и командам поддержки не нужно гадать, какой именно invoice.pdf вызвал проблему.
Каждый worker должен также записывать несколько временных меток в небольшое хранилище jobs: когда задача началась, когда произошёл retry, когда она упала и когда завершилась. Эти четыре точки уже рассказывают почти всю историю. По ним видно, лежала ли задача в очереди, упала сразу или продолжала сбоить 20 минут.
Сделайте одну небольшую страницу статуса
Небольшая внутренняя страница статуса помогает больше, чем куча сырых логов. Ищите по trace ID и показывайте наверху родительскую загрузку, а ниже — все дочерние задачи с их текущим состоянием: queued, running, retrying, failed, finished.
Если поддержка получает от клиента один ID, она должна находить весь путь за секунды. Ей не должны быть нужны имя bucket, имя worker’а или точное время загрузки.
Представьте пользователя, который загружает tax-return.pdf. Загрузке назначается trace ID trace_7F3K2. S3 сохраняет этот ID в metadata. Сообщение очереди переносит trace_7F3K2. OCR worker пишет в логах trace_7F3K2. Через две минуты происходит retry, и это видно на странице статуса. Когда indexing worker завершает работу, support может увидеть всю цепочку под одним ID без собирания подсказок из пяти разных систем.
Это и есть цель: один файл, один ID, никаких догадок.
Ошибки, которые создают дублирующуюся работу
Дублирующаяся работа обычно появляется не из-за одной драматичной ошибки. Она начинается с мелких решений, которые кажутся безобидными, когда трафика мало.
Одна частая ошибка возникает сразу после загрузки. Система создаёт дочерние задачи ещё до того, как проверит, должен ли файл вообще проходить через pipeline. Кто-то загружает PDF, JPG и временный файл из той же папки, а pipeline создаёт работу для всех трёх. Позже один worker их отклоняет, но очередь уже потратила время и деньги на бесполезное перемещение задач.
Размер сообщения тоже создаёт проблемы. Команды часто запихивают в очередь полные метаданные, извлечённый текст или куски содержимого файла. Это замедляет retries, делает сбои менее читаемыми и подталкивает людей пересылать всё сообщение заново, если меняется одно поле. Лучше делать сообщение простым: object key, bucket, version или ETag, job ID и небольшой объём routing data. Тяжёлые данные храните в storage.
Workers создают ещё больше дублей, когда пропускают проверки idempotency. Повторные попытки — это нормально. Timeouts — это нормально. Worker должен исходить из того, что одно и то же сообщение может прийти дважды. Если он пишет записи, отправляет письма или создаёт новые дочерние задачи без проверки, происходило ли это уже, одна загрузка может превратиться в два или пять результатов.
Слишком раннее удаление исходного файла создаёт более тихий беспорядок. Первая попытка падает, сообщение повторяется, а worker уже не может прочитать исходный объект. Кто-то вручную загружает файл ещё раз, и pipeline запускается во второй частичный проход.
Детали ошибок часто исчезают в логах worker’а. Тогда в очереди видно число повторов, но никто не может понять, на чём именно сломалось: на проверке файла, OCR, antivirus или записи в базу данных. Когда команды не видят причину ошибки рядом с записью job, они запускают работу заново вслепую.
Более безопасная схема проста: проверяйте файл до fan-out, держите сообщения очереди маленькими, давайте каждой задаче стабильный idempotency key, сохраняйте исходный объект до завершения retries и обработки dead letter queue и храните статус ошибки там, где оператор может быстро его запросить.
Если одна загрузка PDF создаёт одно дерево jobs с одной понятной цепочкой, дублирующаяся работа быстро сокращается.
Проверки перед выпуском
Проверяйте систему, думая об одной реальной загрузке и одном сложном дне. Схемы с очередями и workers выглядят просто на диаграмме, но мелкие пробелы создают дублирующиеся задачи, зависшие файлы и тикеты в поддержку, на которые никто не может ответить.
Сложность не в том, чтобы перемещать сообщения. Сложность в том, чтобы доказать, что случилось с одним файлом, и повторно запустить одну неудачную задачу, не трогая всё остальное.
Перед выпуском попросите кого-то, кто не строил этот pipeline, отследить один файл. Он должен найти время загрузки, job ID, текущий шаг, число повторов и финальный результат меньше чем за минуту. Если для этого нужны три дашборда и догадки, история с tracing всё ещё слабая.
Несколько проверок ловят большую часть проблем:
- Убедитесь, что один и тот же file ID есть в metadata объекта, сообщении очереди, логах worker’а и записи результата.
- Принудительно сломайте одного worker’а на середине и проверьте, что повторная попытка не создаёт дубликаты файлов, строк в базе или уведомлений.
- Отправьте всплеск загрузок и наблюдайте за глубиной очереди, временем работы worker’ов и возрастом самого старого сообщения.
- Повторно запустите одну неудачную задачу и убедитесь, что не нужно обрабатывать весь пакет заново.
- Попросите сотрудника поддержки проверить статус job, не открывая AWS.
Если эти проверки кажутся неудобными, исправьте дизайн до роста трафика. Команды, которые держат эту часть скучной, обычно спят спокойнее на неделе запуска.
Что делать дальше
Начинайте с малого и добавляйте части только тогда, когда можете указать на реальное узкое место. Для большинства команд это означает одну очередь для событий загрузки, одного router worker’а, который решает, какие jobs создавать, и одну job table, которая записывает каждый файл, его статус, число попыток и любую ошибку.
Этого достаточно, чтобы доказать, что паттерн работает. И этого же достаточно, чтобы весь flow было легче понимать, потому что у каждого файла есть одно место, где команда может посмотреть, что произошло и что должно случиться дальше.
Хорошая первая версия проста: отправляйте каждое новое событие загрузки в одну очередь, пусть один router worker создаёт или обновляет запись job, дайте каждой задаче стабильный file ID или trace ID, и пусть workers обновляют одну и ту же job table по мере продвижения работы.
Разделяйте очереди позже, а не раньше. Делайте это, когда image work блокирует анализ PDF, когда большие файлы задерживают маленькие или когда одному worker’у нужны совсем другие правила повторных попыток.
Заранее пропишите, кто за что отвечает, ещё до релиза. Кто-то должен отвечать за retries. Кто-то — за alerts. Кто-то — за очистку зависших jobs, старых payload’ов и сообщений из dead letter queue. Если за это никто не отвечает, система будет выглядеть нормально, пока сломанная работа тихо не начнёт накапливаться.
Один простой тест ловит много слабых решений: загрузите один файл в staging и проследите его до конца. Вы должны быстро ответить на пять вопросов. Когда он пришёл? Какую job вы создали? Какой worker его забрал? Сколько раз был retry? Куда попал финальный результат?
Если на такой trace уходит десять минут и три дашборда, упростите дизайн до роста трафика.
Если вашей команде нужен внешний взгляд, Oleg Sotnikov на oleg.is может оценить дизайн очередей, workers и tracing в короткой консультации Fractional CTO. Он много лет строит компактные production-системы с понятной операционной видимостью, поэтому обычно быстро замечает дублирующуюся работу, слабую логику retries и недостающие точки trace.
Начните с самой маленькой версии, которую можно отследить от начала до конца. Обычно именно её команда потом сможет спокойно поддерживать и через шесть месяцев.


