Rust serde для нестабильных API: паттерны, которые переживают изменения
Rust serde для нестабильных API помогает разбирать частичные поля, сохранять неизвестные значения и не паниковать, когда поставщики добавляют, переименовывают или меняют JSON.
Содержание
Почему ломаются ответы поставщика
Клиент может работать месяцами, а потом сломаться из-за того, что одна upstream-команда внесла «небольшое» изменение. Возможно, amount раньше был числом, а теперь приходит строкой. Возможно, customer_email исчезает, когда поставщик добавляет правила конфиденциальности. Возможно, поле, в котором всегда было значение, внезапно возвращается как null для старых записей.
Ни одно из этих изменений не выглядит драматично на панели поставщика. В вашем Rust-коде они могут сразу остановить десериализацию.
Так происходит потому, что API-ответы меняются неаккуратно:
- поля исчезают
- поля становятся
null - числа превращаются в строки
- у enum появляются новые значения
- без предупреждения появляются дополнительные объекты
Жёсткая модель хороша, когда вы контролируете обе стороны. На границе API она может быть слишком хрупкой. Если ваша структура говорит, что поле обязательно и должно быть целым числом, serde отклонит весь ответ, когда поставщик пришлёт что-то другое. Внутри собственной системы это часто правильно. Для внешних данных это часто слишком жёстко.
Частая ошибка выглядит так: вам нужны только id, status и created_at, но модель пытается описать весь ответ, потому что так выглядит аккуратно. Позже поставщик меняет не связанное с вами вложенное поле с объекта на массив. Ваш код ломается, хотя три нужных вам поля по-прежнему приходят точно так же.
Вот почему Rust serde для нестабильных API требует другого мышления. Цель не в том, чтобы «принимать всё». Это скрывает реальные ошибки. Цель уже: принимать безвредные изменения, отклонять настоящие нарушения контракта и сохранять достаточно сырых данных, чтобы позже можно было разобраться с новыми случаями.
Хорошие API-клиенты проводят эту границу осознанно. Они остаются строгими к полям, которые влияют на бизнес-логику, например к типу события или статусу платежа. И остаются гибкими ко всему остальному, особенно к необязательным метаданным и дополнительным данным от поставщика.
Такой баланс позволяет клиенту выживать, когда структура данных уезжает, и при этом ловить изменения, которые могут испортить состояние или запустить неправильное действие.
Решите, что должно оставаться строгим
Когда ответ поставщика меняется каждые несколько недель, не делайте все поля одинаково жёсткими. Оставьте строгий разбор для полей, которые управляют поведением. ID, стабильные ссылки и значения статуса обычно относятся именно к ним. Если id отсутствует или статус биллинга приходит в форме, которую приложение не понимает, ранний провал часто безопаснее.
Всё остальное какое-то время может оставаться более свободным. Подписи, заметки, отображаемые имена, теги и случайные метаданные часто меняются первыми. Эти поля редко должны блокировать весь запрос. На практике Option<T>, значения по умолчанию или поле для «всего остального» в JSON дают вам пространство продолжать выпускать изменения, пока поставщик продолжает что-то менять.
Вот практическая сторона Rust serde для нестабильных API. Строгость должна следовать за влиянием на бизнес, а не за личными предпочтениями.
Хороший подход — держать две модели. Первая модель отражает ответ поставщика как сырые входные данные. Вторая — это очищенный взгляд вашего приложения на эти данные. Такое разделение важно. Сырая модель может принимать отсутствующие заметки, неизвестные дополнительные поля и странное форматирование. А модель приложения всё ещё может говорить: «мы обрабатываем только записи с корректным внутренним ID и поддерживаемым статусом».
#[derive(serde::Deserialize)]
struct VendorOrder {
id: String,
status: String,
label: Option<String>,
note: Option<String>,
#[serde(default)]
extra: serde_json::Value,
}
Эта сырая структура не решает, можно ли оплачивать заказ, активен ли он или безопасно ли его показывать. Это решает уже ваш код позже. Так вы держите шум поставщика подальше от бизнес-правил.
Помогает простой тест:
- Если поле меняет поведение приложения, держите его строгим.
- Если поле меняет только отображаемый текст, сделайте его необязательным.
- Если сегодня вы не используете поле, сохраняйте его или игнорируйте.
- Если новое поле может скоро понадобиться, сохраните сырое значение хотя бы на один релиз.
Последний пункт экономит много сил. Допустим, поставщик добавляет review_note или priority_label. Сегодня вам они не нужны. Но если вы сохраняете сырой ответ или собираете неизвестные поля, позже сможете посмотреть реальные данные без срочного хотфикса. Строго там, где приложение может сломаться, и гибко там, где оно должно адаптироваться. Именно такой баланс продлевает жизнь клиентам.
Преднамеренно разбирайте только нужные поля
Большинство ответов поставщика недолго остаются аккуратными. Поле исчезает, число становится строкой, или один endpoint возвращает более короткую версию того же объекта. Если ваши Rust-типы слишком близко повторяют весь JSON, небольшие изменения на стороне поставщика могут сломать код, которому на самом деле нужны были только два поля.
Начинайте с малого. Разбирайте только те поля, которые ваш код действительно использует, и делайте отсутствие данных явным с помощью Option<T>. Если phone, middle_name или deleted_at могут появляться и исчезать, Option подсказывает Serde принимать оба варианта без догадок.
use serde::Deserialize;
#[derive(Deserialize)]
struct CustomerSummary {
id: String,
email: Option<String>,
deleted_at: Option<String>,
}
Значения по умолчанию требуют большей осторожности. #[serde(default)] подходит, когда запасной вариант действительно совпадает с реальностью. Пустой список часто уместен. Отсутствующий статус, цена или временная метка — обычно нет. Если вы молча превращаете отсутствие данных в 0 или "active", вы скрываете изменение у поставщика и усложняете поиск ошибок.
Смена типа тоже встречается часто. В один день API присылает "42", на следующий — 42. Вместо того чтобы разбрасывать специальные случаи по всему приложению, разберите оба варианта в один локальный тип на самой границе.
use serde::Deserialize;
#[derive(Deserialize)]
#[serde(untagged)]
enum StringOrInt {
Str(String),
Int(i64),
}
Такой обёртка удерживает остальной код в спокойствии. Можно добавить небольшой метод, который один раз приведёт значение к строке или числу, а потом использовать его везде дальше.
Ещё помогает держать по одной маленькой структуре на каждый формат ответа. Список, детальная карточка и webhook могут описывать одного и того же клиента, но часто делают это по-разному. Отдельные структуры менее «умные», и это хорошо. Когда поставщик меняет один ответ, вы трогаете только один парсер.
Небольшая модель на границе обычно живёт дольше, чем одна огромная общая структура. Она также делает поломки заметными там, где это важно, и гибкими там, где так и должно быть.
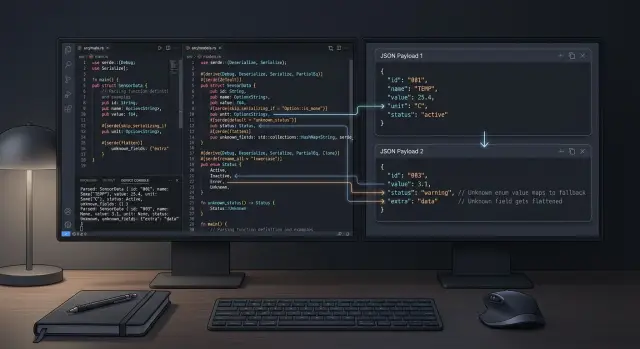
Сохраняйте неизвестные данные на потом
Поставщики всё время добавляют поля. Если ваш клиент сохраняет только знакомые поля, вы теряете полезные подсказки в тот самый момент, когда ответ меняется.
Простое решение — оставить известные поля типизированными и собрать всё остальное в map. serde легко делает это с помощью flatten.
use serde::Deserialize;
use serde_json::Value;
use std::collections::HashMap;
#[derive(Debug, Deserialize)]
struct Customer {
id: String,
#[serde(default)]
email: Option<String>,
#[serde(flatten)]
extra: HashMap<String, Value>,
}
Так вы получаете стабильную модель для полей, которые используете сегодня, а extra сохраняет новые поля на завтра. Это один из самых безопасных паттернов Rust serde для нестабильных API, потому что вам не нужно срочно выпускать новую версию в тот же момент, когда поставщик добавляет region, tags или вложенный объект preferences.
Иногда map недостаточно. Если поставщик постоянно переставляет поля местами, сохраните и весь сырой JSON. Сначала разберите типизированную структуру из клонированного Value, а затем сохраните исходный ответ для анализа. Это помогает, когда через три дня прилетает обращение в поддержку, и вам нужно увидеть, что именно прислал поставщик.
Логирование здесь важно, но пусть оно будет узким. Логируйте имена неизвестных полей, их количество и, возможно, небольшой зацензуренный пример. Не валите запрос только потому, что в ответе есть сюрприз.
Хорошо работает такой небольшой порядок действий:
- разберите ответ в типизированную структуру
- если
extraне пустой, залогируйте имена полей - прикрепите сырой JSON к отладочному выводу или сохраните его на потом
- перед записью в логи скройте персональные данные
Ещё лучше сравнивать неизвестные поля между несколькими примерами ответов. Возьмите десять или двадцать реальных ответов одного и того же endpoint, соберите имена из extra и посмотрите на закономерности. Одно поле может появляться только у enterprise-аккаунтов. Другое может меняться со строки на объект во время выкладки. Так вы замечаете изменения заранее, не ломая production.
Если вы делаете API-клиенты для стартапов или небольших команд, такой подход экономит много времени. Вы остаётесь строгими там, где приложение зависит от данных, но при этом сохраняете то, чего пока ещё не понимаете.
Безопасно принимайте новые значения enum
Enum ломаются быстро, когда поставщик добавляет ещё один статус, которого вы не ожидали. Если ваш клиент считает список значений у поставщика закрытым, одно новое значение может превратить безобидное изменение в ошибку разбора.
Безопасный подход простой: держите обычный enum для известных случаев и добавьте вариант Unknown, который хранит сырое значение. Так код продолжит работать, логи останутся полезными, и вы сможете изучить новые случаи позже, а не потерять их.
Небольшой enum-паттерн, который надолго
use serde::{Deserialize, Deserializer};
use serde_json::Value;
#[derive(Debug, Clone)]
pub enum VendorStatus {
Active,
Paused,
Unknown(String),
}
impl<'de> Deserialize<'de> for VendorStatus {
fn deserialize<D>(deserializer: D) -> Result<Self, D::Error>
where
D: Deserializer<'de>,
{
let raw = Value::deserialize(deserializer)?;
match raw {
Value::String(s) => match s.as_str() {
"active" => Ok(VendorStatus::Active),
"paused" => Ok(VendorStatus::Paused),
other => Ok(VendorStatus::Unknown(other.to_owned())),
},
Value::Number(n) => Ok(VendorStatus::Unknown(n.to_string())),
other => Ok(VendorStatus::Unknown(other.to_string())),
}
}
}
Это обрабатывает и строки, и числа, а это важнее, чем ожидает многие команды. Поставщик может сегодня отправлять "active", а завтра — 1 для одного из партнёрских потоков. Не обязательно любить такой выбор. Нужно уметь его пережить.
Держите enum поставщика как можно ближе к границе API. Затем как можно раньше преобразуйте его в свои внутренние состояния. Например, Active может стать Enabled, Paused — Suspended, а Unknown(_) — NeedsReview или безопасным вариантом по умолчанию, который не запускает рискованное поведение.
Такой шаг преобразования успокаивает остальную часть приложения. Бизнес-логика не должна везде по коду сопоставлять все варианты поставщика. Лучше один раз централизовать match и отдать наружу более простой внутренний enum, который отражает ваши правила, а не меняющийся словарь поставщика.
Хороший запасной вариант — скучный специально. Если статус биллинга неизвестен, не списывайте деньги. Если статус отгрузки неизвестен, не отправляйте товар. Сохраните сырое значение, зафиксируйте его и двигайтесь дальше.
Стройте модель шаг за шагом
Начинайте с тех ответов, которые вы действительно получили в продакшене. Документация часто запаздывает, примеры слишком чистые, а тестовые фикстуры не показывают тех странных случаев, которые ломают реальные клиенты. Сохраните небольшой набор сырых ответов с разных дат, аккаунтов и состояний ошибок.
Затем сделайте небольшую строгую структуру только для тех полей, которые вашему коду действительно нужны. Если приложению нужны только id, status и created_at, смоделируйте сначала их и остановитесь. Маленькой модели проще доверять, и она даёт стабильную основу, когда поставщик добавляет вокруг неё шум.
Если примеры расходятся, сделайте поле необязательным ещё до того, как писать собственный парсинг. Так модель остаётся читаемой и обычно решает больше случаев, чем ожидают. В Rust serde для нестабильных API Option<T> часто — первый инструмент, к которому стоит тянуться, а не кастомный десериализатор.
use serde::Deserialize;
use serde_json::Value;
use std::collections::HashMap;
#[derive(Debug, Deserialize)]
struct VendorEvent {
id: String,
status: String,
created_at: Option<String>,
amount: Option<i64>,
#[serde(flatten)]
extra: HashMap<String, Value>,
}
Это поле extra важно. Добавьте его до того, как писать ручной парсинг. Часто вы обнаружите, что кастомная логика вообще не нужна. Неизвестные поля остаются доступными для логов, отладки или более поздней выкладки, а новые поля поставщика перестают ломать ваш клиент.
Хороший рабочий процесс выглядит просто:
- соберите 5–10 реальных ответов
- постройте самую маленькую строгую структуру, которая подходит для всех из них
- превратите различающиеся поля в
Option<T> - сохраните остальное через
#[serde(flatten)] - только после этого добавляйте собственный парсинг для действительно сложных полей
Проверяйте одну и ту же модель на старых и новых примерах каждый раз, когда меняете её. Один фикстура-файл из прошлого месяца и один из этой недели могут поймать большинство регрессий. Если оба десериализуются, а ваши основные поля по-прежнему ведут себя одинаково, вы в гораздо лучшей форме, чем клиент, который зеркалит всю схему поставщика и надеется, что она не изменится.
Такой пошаговый подход скучный, и именно поэтому он работает. Он делает клиент компактнее, даёт пространство для изменений у поставщика и помогает не переусложнять поля, которыми код даже не пользуется.
Пример реального ответа, который постоянно меняется
Обычное изменение ответа поставщика выглядит безобидно, пока не попадает в production. API месяцами отправляет "price": "19.95", а потом переключается на "price": 19.95. Позже, во время отложенной синхронизации, он присылает "price": null и добавляет "status": "pending".
{"price":"19.95","status":"ready"}
{"price":19.95,"status":"ready"}
{"price":null,"status":"pending"}
Если ваша Rust-модель ожидает только String или только f64, клиент упадёт из-за изменения, которое пользователи могут даже не заметить. Более устойчивый вариант — разобрать сырое поле как serde_json::Value, сохранить соседний status и нормализовать оба значения в один обёрточный тип.
use rust_decimal::Decimal;
use serde_json::Value;
use std::str::FromStr;
#[derive(Debug, Clone)]
enum PriceField {
Amount(Decimal),
Pending(String),
Raw(Value),
}
fn parse_price(price: Value, status: Option<String>) -> PriceField {
match price {
Value::String(s) => Decimal::from_str(&s)
.map(PriceField::Amount)
.unwrap_or(PriceField::Raw(Value::String(s))),
Value::Number(n) => Decimal::from_str(&n.to_string())
.map(PriceField::Amount)
.unwrap_or(PriceField::Raw(Value::Number(n))),
Value::Null => PriceField::Pending(status.unwrap_or_else(|| "unknown".to_string())),
other => PriceField::Raw(other),
}
}
PriceField::Amount обрабатывает и строковый, и числовой вариант, так что остальной код видит один тип цены. PriceField::Pending придаёт null реальный смысл, когда поставщик ещё и отправляет статус. PriceField::Raw ловит всё неожиданное, например объект или массив, не валя весь запрос.
Этот небольшой enum делает больше, чем просто удерживает разбор от падения. Он не даёт особенностям поставщика просачиваться в логику оформления заказа, отчёты или кеширование. Эти части приложения должны отвечать только на один вопрос: у нас есть сумма, состояние ожидания или что-то, что надо залогировать и изучить?
Я предпочитаю это Option<String>. None слишком многое скрывает. Оно может означать отсутствие данных, временное состояние или совершенно новый формат от поставщика. Обёрточный тип разделяет эти случаи, и Rust serde для нестабильных API остаётся спокойным, когда ответ снова меняется.
Ошибки, из-за которых клиенты становятся хрупкими
Многие Rust API-клиенты ломаются по вполне банальным причинам. Код предполагает, что поставщик будет вечно присылать одну и ту же структуру, а затем небольшое изменение ответа превращает безобидный JSON в ошибку.
Первая частая ошибка — строить одну огромную структуру для всех endpoints. Сначала это выглядит аккуратно, но связывает между собой несвязанные ответы. Когда одно поле меняется только в одном endpoint, вам приходится трогать модели, которые раньше были в порядке. Небольшие структуры под конкретный endpoint обычно читаются проще и безопаснее меняются.
Отсутствующие данные и пустые данные тоже нужно обрабатывать по-разному. Если поставщик не прислал поле, это часто означает не то же самое, что пустая строка, пустой массив или null. Если всё это свести к одному состоянию, вы теряете смысл и усложняете отладку. Option<T> вместе с аккуратным десериализатором часто лучше, чем попытка загнать всё в значение по умолчанию.
Где serde используют слишком широко
Ещё одна ошибка — каждый раз тянуться к untagged enum, когда ответы не совпадают. В узких случаях они помогают, но также делают разбор неоднозначным и усложняют ошибки. Если поле часто меняет форму, разбирайте его отдельно или держите как serde_json::Value, пока не поймёте, что именно вам нужно.
Команды также слишком рано выбрасывают неизвестные поля. Это пустая трата. Если завтра поставщик добавит status_details, вам оно может быть пока не нужно, но его сохранение может сэкономить инцидент в production на следующей неделе. Частый приём — складывать дополнительные поля в map и логировать их при первом появлении.
Будьте строже там, где это важно
Одно плохое поле не должно всегда убивать весь ответ. Если вам важны id, status и created_at, разбирайте их строго. Если notes или metadata пришли в испорченном виде, сохраните остальное и пометьте это поле как сырое или отсутствующее.
Простой принцип работает хорошо:
- держите критические поля типизированными
- держите нестабильные поля гибкими
- сохраняйте неизвестные поля
- моделируйте каждый endpoint отдельно
- изучайте сюрпризы до того, как их удалять
Такой подход даёт клиент, который гнётся, когда поставщик меняет что-то мелкое, вместо того чтобы ломаться при первом несоответствии.
Быстрые проверки перед релизом
Перед выпуском клиента выполните несколько проверок, которые ловят тихие сбои. Большинство поломок происходит не из-за драматической смены схемы. Они возникают из-за одного нового значения enum, одного отсутствующего поля или одного значения по умолчанию, которое превращает плохой ввод в ложный успех.
Для Rust serde для нестабильных API старые ответы важны не меньше, чем свежие. Сохраните реальные ответы с разных дат и запускайте одни и те же тесты против всех из них. Поставщик может поменять поле в апреле, а потом частично откатить это в июне. Если вы тестируете только самый свежий пример, вы упускаете этот хаос.
Короткий чеклист перед релизом работает хорошо:
- Повторно запустите тесты разбора на фикстурах, собранных в разное время.
- Проверьте каждое
#[serde(default)]и подумайте, что плохого оно может скрыть. - Просмотрите логи или сохранённые примеры на поля и значения enum, которые код ещё не обрабатывает.
- Храните JSON-фикстуры рядом со структурами и тестами, которые их используют.
- Убедитесь, что сообщения об ошибках называют путь к полю, на котором всё сломалось.
К значениям по умолчанию нужно относиться особенно настороженно. Если count превращается в строку, а модель падает назад к 0, программа продолжает работать, но данные уже неверны. Это хуже, чем честный сбой. Используйте значения по умолчанию только для действительно необязательных данных, а не для маскировки полей, от которых вы зависите.
Логи помогают раньше замечать изменения у поставщика. Если вы сохраняете неизвестные поля, время от времени смотрите на них, а не игнорируйте навсегда. Одно новое поле может ничего не значить. Десять новых полей обычно означают, что ответ уезжает, и модели нужен ещё один проход.
Сообщения об ошибках тоже заслуживают быстрой проверки. Если фикстура не смогла распарситься, сообщение должно указывать на что-то вроде items[3].status, а не заставлять вас гадать. Это экономит время позже, особенно когда production-ответ ломается в 2 часа ночи и нужно исправить одно поле, а не читать весь JSON вручную.
Что делать дальше
Если ваш клиент уже зависит от API поставщика, который меняется без предупреждения, поставьте жёсткую границу между этим ответом и собственным приложением. Разбирайте ответ поставщика в слое адаптера, а затем переводите его в доменные типы. Так приёмы с serde, запасными enum и хранением сырого JSON не будут расползаться по остальной части кодовой базы.
Вот где Rust serde для нестабильных API действительно окупается. Вы перестаёте считать схему поставщика обещанием и начинаете относиться к ней как к входным данным, которые нужно проверять.
Запишите, что означает каждое поле для вашей системы. Короткой заметки в репозитории достаточно. Для каждого принятого поля решите, будете ли вы:
- доверять ему и падать, если оно неверно
- использовать его, когда оно есть, но обходиться без него
- сохранять его на потом, не полагаясь на него
- игнорировать его специально
Этот маленький список экономит время на ревью. Он также останавливает медленный дрейф, когда поле начинается как «неплохо бы иметь» и незаметно становится обязательным, пока никто этого не замечает.
Когда поставщик меняет форму ответа, назначьте короткий разбор вместо ожидания баг-репорта. Двадцати или тридцати минут часто хватает. Сравните один новый пример ответа со старой фикстурой, прогоните тесты адаптера и проверьте места, которые ломаются чаще всего: значения enum, null, переименованные ключи, вложенные объекты и временные метки.
Если API меняется часто, держите примеры ответов в тестах и обновляйте их осознанно. Один реальный пример с прошлого месяца и один с этой недели расскажут вам больше, чем длинный комментарий.
Второе мнение может помочь, когда слой адаптера уже стал запутанным. Oleg Sotnikov занимается такой работой с практической стороны Fractional CTO: проверяет границу Rust-кода, убирает хрупкие участки и решает, где AI-assisted delivery помогает команде двигаться быстрее, не делая парсер менее надёжным.
Начните с одного endpoint, а не со всего клиента. Отделите адаптер от доменной модели, сохраняйте неизвестные поля и запишите уровень доверия к каждому используемому полю. Эта привычка делает следующее изменение у поставщика не дорогим, а просто раздражающим.


