Rust и C++ FFI: безопасные границы для постепенной переработки
Для Rust и C++ FFI нужны чёткое владение памятью, узкие API, надёжные тесты и безопасные шаги релиза, когда команды заменяют по одному модулю.
Содержание
Где начинаются ловушки памяти
Rust и C++ могут хорошо работать вместе, но проблемы начинаются там, где одна сторона перестаёт понимать, кто владеет значением. Rust освобождает память, когда владелец выходит из области видимости. C++ может копировать, перемещать, разделять или удалять значение похожего типа совсем по-другому. Если обе стороны считают, что должны очистить память, вы получите падение. Если ни одна не сделает этого, появится утечка.
Это несоответствие легко не заметить, потому что каждый язык сам по себе выглядит корректно. Код на Rust может проходить проверку заимствований. Код на C++ может компилироваться без ошибок и даже пройти ревью. Ошибка живёт в месте передачи данных.
Один из частых примеров — функция Rust возвращает указатель на данные, а C++ считает, что этот указатель навсегда принадлежит ему. Другой вариант — C++ создаёт объект, передаёт его в Rust, а потом удаляет, хотя Rust всё ещё держит на него ссылку. Оба случая могут работать при простом тестировании, а затем ломаться под нагрузкой или спустя несколько дней.
Почему смешанные переработки рискованны
Команды часто сталкиваются с этим во время постепенной миграции на Rust. Они заменяют один модуль, оставляют остальное на C++ и думают, что новая граница — это лишь мелкая техническая деталь. Это не так. Граница — это место, где встречаются две модели памяти, и маленькие допущения быстро превращаются в дорогие ошибки.
Такие ошибки встречаются часто:
- Rust выделяет память, а C++ освобождает её через
delete - C++ передаёт заимствованный буфер, а Rust хранит его дольше, чем живёт вызов
- Одна сторона перемещает значение, а другая всё ещё использует старый дескриптор
- На одной стороне путь ошибки пропускает очистку
- Строки или структуры переходят через границу с разными предположениями о layout
Одного неверного правила очистки достаточно. Двойное освобождение может быстро привести к падению. Утечка может тихо жить в продакшене и расти неделями. А use-after-free ещё хуже, потому что выглядит случайным. Команда обвиняет новый модуль на Rust и тратит время на поиск не там, где нужно.
Истинная причина обычно проще: контракт никто не записал. Если граница не говорит, кто выделяет память, кто освобождает её, как долго живёт указатель и можно ли перемещать или копировать значение, код работает на удаче.
Именно поэтому ловушки памяти появляются рано, даже в маленьких переработках. Первый безопасный шаг — не новый код. Это ясное правило владения для каждого значения, которое пересекает границу.
Сначала задайте правила владения, потом пишите код
В Rust и C++ FFI ошибки с памятью обычно возникают из-за одной простой проблемы: обе стороны думают, что владельцем является другая сторона, или не думает ни одна. Исправьте это до того, как начнёте писать обёртки, структуры или пути ошибок.
Для каждого значения, которое проходит через границу, запишите два факта: кто его выделяет и кто его освобождает. Сделайте это для строк, буферов, структур, обратных вызовов и объектов ошибок. Если Rust создаёт строку, а C++ её читает, Rust должен также предоставить функцию для освобождения. Если C++ передаёт буфер, чтобы Rust его заполнил, C++ сохраняет владение, если только API не говорит иначе.
Совместный доступ требует другого правила. Если один вызов создаёт данные, а несколько последующих вызовов читают или обновляют их, передавайте не сырой указатель, а дескриптор. Дескриптор может указывать на структуру Rust, объект C++ или boxed state object, но контракт остаётся простым: создать, использовать, уничтожить. Это гораздо проще проверять, чем указатель, чьё время жизни зависит от пяти точек вызова.
Комментарии здесь важнее, чем многим хотелось бы. Пишите правило времени жизни рядом с каждой экспортируемой функцией, простыми словами. Короткой пометки достаточно:
// Возвращает новое выделенное значение. Rust владеет выделением.
// Вызвавшая сторона должна освободить его через pricing_result_free().
PricingResult* pricing_calculate(const PricingInput* input);
То же самое делайте для заимствованных данных. Указывайте, должен ли указатель быть валиден только на время вызова, до завершения callback или до явного вызова destroy. Если функция сохраняет указатель после возврата, напишите это прямо.
Небольшой команде помогает одна таблица в репозитории:
- тип значения
- кто выделяет
- кто освобождает
- заимствованное или собственное
- валидно до
Это звучит скучно. И это хорошо. Скучный FFI-код реже течёт, реже падает и даёт вам границу, которую можно менять по одному модулю за раз, не гадая, кто потом уберёт последствия.
Делайте границу маленькой и скучной
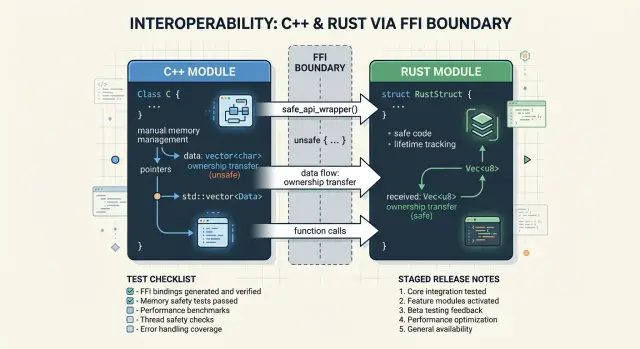
Самый безопасный FFI-код обычно выглядит немного уныло. Это хороший знак. Если вашей границе между Rust и C++ одновременно нужны шаблоны, наследование, исключения, собственные аллокаторы и callbacks, значит, на ней слишком много риска.
Для Rust и C++ FFI чаще всего лучше всего подходит небольшой C-подобный слой. Экспортируйте небольшой набор функций с узкими задачами. Передавайте простые структуры с фиксированными полями. Оставляйте типы Rust внутри Rust, а классы C++ — внутри C++.
Хорошие границы обычно следуют нескольким простым правилам:
- Используйте простые данные, а не иерархии классов или виртуальные методы.
- Преобразуйте строки на границе, вместо того чтобы делиться нативными строковыми типами.
- Преобразуйте enums и ошибки в небольшие значения, которые понятны обеим сторонам.
- Используйте непрозрачные дескрипторы, если одной стороне нужно хранить состояние между вызовами.
Это кажется старомодным, но так вы избегаете многих проблем с памятью. Если Rust отдаёт в C++ String, Vec или Box напрямую, кто-то потом должен это освободить. Если это правило хотя бы немного размыто, утечки и падения появятся быстро. Тонкая обёртка убирает эту неопределённость.
То же касается ошибок. Не позволяйте Rust panic пройти в C++. Не позволяйте исключению C++ проскочить через Rust. Ловите проблемы на той стороне, где они возникли, а затем превращайте их в код статуса или небольшую структуру ошибки.
Тонкие обёртки также упрощают переработку. Предположим, вы заменяете один модуль расчёта цен или парсинга на Rust, а остальная часть продукта остаётся на C++. Если граница отдаёт только функции вроде create, run и free, остальная программа почти не замечает изменений. Если же граница раскрывает внутренние классы, общие контейнеры и строковые типы конкретного языка, каждое маленькое обновление превращается в переговоры.
Скучная граница даёт каждому языку пространство для самостоятельных изменений. Именно это и нужно, когда вы модернизируете по одному модулю за раз.
Переносите один модуль по понятным шагам
Выберите модуль, который уже ведёт себя предсказуемо. Хорошие кандидаты принимают ясные входные данные, возвращают ясный результат и не залезают в половину кодовой базы через общие глобальные переменные. Если модуль меняется каждую неделю, пока пропустите его. Нужен скучный вариант.
Часто хорошо подходят парсер, функция скоринга, движок правил для биллинга или шаг преобразования файлов. Команда уже знает, что считается "правильным", а это снижает количество споров во время переработки.
До того как трогать Rust, зафиксируйте текущее поведение тестами. Добавьте примеры для обычных случаев, неприятных крайних случаев, пустого ввода, плохого ввода и больших данных. Если в текущем C++ коде есть особенности, на которые полагаются пользователи, зафиксируйте и их тоже. Переработка, которая исправляет скрытые баги, всё равно может сломать продакшен.
Затем сохраните границу без изменений. Если C++ вызывает функцию с простой структурой и получает код результата плюс данные, Rust должен работать по тому же контракту. Не переделывайте API в середине миграции. Именно тогда появляются и ловушки памяти, и срыв сроков.
Хорошо работает такой порядок:
- выберите один модуль с низкой частотой изменений и стабильным поведением
- напишите тесты, сверяясь с текущим выводом C++
- добавьте реализацию на Rust за той же FFI-границей
- направьте один путь вызова в Rust и сравните оба результата
- расширяйте трафик только после того, как значения совпадут
Шаг сравнения важнее, чем ожидают команды. Если можете, какое-то время запускайте обе версии параллельно. Оставьте C++-путь живым, но отправляйте те же данные в Rust в теневом режиме и логируйте любые расхождения. Если Rust и C++ расходятся в одном случае из десяти тысяч, вы нашли блокер релиза до того, как это сделали пользователи.
Когда результаты совпадут, расширяйте выкладку небольшими порциями. Сначала внутренние пользователи, одна группа клиентов или один worker-процесс. Следите за количеством ошибок, использованием памяти и задержками. Если что-то уходит в сторону, верните этот путь обратно на C++ и сначала проверьте границу.
Такой ритм одного модуля кажется медленным, но обычно он движется быстрее, чем широкая переработка. Команды продолжают выпускать продукт, пользователи видят меньше сюрпризов, а слой Rust и C++ FFI остаётся достаточно маленьким, чтобы его можно было осмыслить.
Пример: замена модуля расчёта цен
Модуль расчёта цен — удачное место для старта, потому что вход и выход обычно понятны. C++ приложение уже задаёт простой вопрос: если у нас есть эта корзина, этот клиент и этот регион, какую цену показывать? На первом этапе оставьте этот вызов без изменений.
Вызывающий код на C++ по-прежнему должен собирать тот же запрос и вызывать одну экспортируемую функцию. Rust берёт на себя работу только за этой границей. Это быстро снижает риск, потому что остальной кодовой базе не нужно знать, на каком языке теперь считается ответ.
На границе используйте простые структуры запроса и ответа. Подойдут поля вроде item_count, subtotal_cents, region_id и customer_tier, а также явные длины для любого текстового поля. Избегайте классов C++, Vec из Rust и всего, что скрывает правила выделения памяти.
Сторона Rust должна заполнить выходную структуру и вернуть небольшой код статуса. Значение должно быть простым и неизменным:
0— успех1— неверный ввод2— отсутствует правило ценообразования3— внутренняя ошибка
Такой подход сохраняет владение понятным. C++ владеет входной памятью, которую он отправляет. C++ также владеет выходным буфером, который он предоставляет. Rust читает запрос, записывает результат и возвращает управление, не заставляя ни одну сторону гадать, кто что освобождает.
Небольшой пример помогает. Допустим, старый модуль на C++ считает скидки для оптовых покупателей. Вы можете оставить процесс оформления заказа как есть, отправить данные корзины в Rust и попросить Rust вернуть final_price_cents, discount_cents и tax_cents. Если вызов неудачный, C++ может откатиться к старой логике.
Не переключайте весь трафик сразу. Некоторое время запускайте старый код расчёта цен на C++ и новый код на Rust параллельно. Сравнивайте оба результата для одного и того же запроса и логируйте расхождения с идентификатором запроса и короткой причиной, например различием в округлении или отсутствием данных правила.
Когда расхождения опустятся до приемлемого уровня, начните с небольшой доли живого трафика. Так команда получит доказательство, что модуль на Rust работает в продакшене, прежде чем трогать следующий модуль.
Тестируйте границу, а не только код на Rust
Код на Rust может выглядеть чисто и всё равно сломаться в тот момент, когда C++ вызовет его не так, как ожидалось. В Rust и C++ FFI большинство багов начинается не в бизнес-логике. Они начинаются тогда, когда одна сторона отправляет данные, которых другая сторона не ждёт, освобождает память слишком рано или продолжает использовать указатель после смены владельца.
Хорошая тестовая схема прогоняет одни и те же входные данные через обе реализации и сравнивает результат. Если вы заменяете один модуль за раз, это даёт понятную базовую линию. Передайте старой C++ функции и новой Rust функции одни и те же строки, числа и буферы. Затем сравните выходные данные, коды ошибок и любые изменения состояния.
Небольшие крайние случаи ловят удивительно много ошибок:
- пустые строки и буферы нулевой длины
- null-указатели там, где API это допускает
- очень большие буферы и длинные строки
- невалидный UTF-8, если текст проходит через границу
- повторяющиеся циклы allocate/free
Не останавливайтесь на одном чистом вызове. Ошибки FFI часто проявляются не на первом, а на 5000-м вызове. Напишите стресс-тесты, которые вызывают границу в цикле и проверяют, что память остаётся стабильной. Затем запустите параллельные вызовы из нескольких потоков, если ваш API заявляет потокобезопасность. Если она не поддерживается, проверьте, что ваша обёртка отвергает такой сценарий, а не ломается случайным образом.
CI должен запускать эти тесты с санитайзерами на стороне C++ и debug-проверками на стороне Rust. AddressSanitizer и UndefinedBehaviorSanitizer быстро находят многие ошибки с указателями. Debug-сборки Rust помогают выявить ошибки границ, неверные предположения и panic, которые релизная сборка могла бы скрыть. Запускайте обе стороны вместе в одном пайплайне, а не как отдельные миры.
Один практический приём сильно помогает: держите общий набор сложных входных данных. Когда в продакшене появляется баг, превращайте точный вход, который его вызвал, в тест границы ещё до исправления кода. Со временем набор перестаёт пропускать простые регрессии и сложные тоже.
Команды, которые делают это хорошо, относятся к границе как к контракту. Они не просто спрашивают: «работает ли код на Rust?» Они спрашивают: «останется ли этот вызов корректным, если C++ передаст плохие данные, большие данные или десять вызовов одновременно?» Именно этот вопрос предотвращает утечки и падения, которые реально видят пользователи.
Ошибки, которые приводят к утечкам и падениям
Большинство ошибок на границе Rust и C++ не являются хитрыми. Они возникают потому, что одна сторона гадает насчёт владения, обработки ошибок или layout данных.
Rust и C++ FFI становится безопаснее, когда граница ведёт себя как строгий контракт. Если контракт размытый, утечки и падения появляются быстро.
Один из частых сбоев — double free. C++ удаляет буфер, а потом Rust освобождает ту же аллокацию, или наоборот. Обычно это начинается с API, который возвращает сырой указатель, но не говорит, кто должен его освобождать.
Правило должно быть простым: память освобождает та сторона, которая её выделила. Если объект создаёт Rust, Rust же предоставляет функцию уничтожения. Если объект создаёт C++, то C++ отвечает за очистку.
Ещё одна классическая ошибка — вернуть указатель после того, как владелец уже исчез. Функция Rust может передать C++ указатель внутрь String или Vec, а затем функция завершится, и буфер исчезнет. C++ может сделать то же самое с временным объектом, чей срок жизни закончится раньше, чем Rust его использует.
Если вызывающей стороне нужны данные после завершения функции, передайте ей собственную память, скопируйте данные в буфер, предоставленный вызывающей стороной, или верните непрозрачный дескриптор. Не возвращайте указатели на данные стека, временные контейнеры или поля объектов, которые могут переместиться.
Исключения вызывают другой тип сбоя. Если C++ бросит исключение через FFI-границу в Rust, процесс может аварийно завершиться или повредить состояние. То же предупреждение относится и к panic из Rust, который попадает в C++.
Ловите ошибки до того, как они пересекут границу. Превращайте их в коды ошибок, помеченные структуры результата или nullable-дескрипторы с отдельной функцией для текста ошибки.
Изменения layout структур тише, но не менее опасны. Перестановка полей, новое значение enum или другая выравнивающая схема могут заставить другую сторону читать мусор без предупреждения компилятора.
Несколько привычек помогают этого избежать:
- используйте
#[repr(C)]для общих структур Rust - предпочитайте непрозрачные дескрипторы большим общим структурам
- добавляйте версию API и повышайте её при изменении layout
- проверяйте размер структур и предположения о полях в тестах на обеих сторонах
Небольшой пример: в версии 1 структуры ценообразования есть price, затем currency. Кто-то добавляет discount в середину для версии 2, выпускает только сторону Rust, а C++ всё ещё читает старый layout. Результат — не аккуратная ошибка. Это плохие данные, случайные падения или и то, и другое.
Перед релизом каждый тип на границе должен в одном предложении отвечать на три вопроса: кто им владеет, кто его освобождает и что происходит при ошибке. Если хотя бы один ответ расплывчатый, баг уже существует.
Релиз без риска большого взрыва
Релиз со смешанными C++ и Rust должен ощущаться скучным. Если запуск зависит от одного идеального переключения, план слишком хрупкий.
Начните с выпуска слоя-обёртки до того, как переключите реальную логику. Оставьте старый путь на C++, а новому коду Rust дайте возвращать те же формы данных, те же коды ошибок и то же поведение в крайних случаях. Это даст команде время наблюдать за логами, временем работы и использованием памяти, пока продакшен всё ещё живёт на старом пути.
Поместите путь Rust за feature flag, который можно менять без пересборки. Для работы с Rust и C++ FFI это важнее, чем многим кажется. Если новый модуль под реальной нагрузкой наткнётся на ошибку владения, вам нужен один быстрый возврат к реализации на C++, а не ночной hotfix-релиз.
Небольшой rollout лучше драматичного. Направьте путь Rust сначала на внутренний трафик или на одну низкорисковую группу клиентов, если у вас есть чёткая изоляция. Модуль расчёта цен — хороший пример. Вы можете зеркалировать запросы, сравнивать результаты и убедиться, что обе стороны согласны, прежде чем результат Rust начнёт влиять на биллинг.
Этот процесс релиза хорошо работает так:
- Выпустите код границы и оставьте его неактивным.
- Включите путь Rust для сотрудников или тестовых арендаторов.
- Расширьте до небольшого процента трафика и следите за ошибками, задержками и памятью.
- Увеличивайте постепенно только после того, как команда посмотрит diff и журналы инцидентов.
Откат требует практики, а не надежды. До первого запуска проведите в staging тренировку, которая имитирует плохой релиз Rust. Выключите feature flag, проверьте, что путь C++ всё ещё работает, и убедитесь, что форматы данных, кэши и метрики остаются согласованными. Команды часто пропускают это, потому что старый код всё ещё на месте. А потом слишком поздно выясняется, что изменение конфигурации, схемы или формы API незаметно привязало их к новому пути.
Одно правило помогает больше всего: не позволяйте плану релиза зависеть от того, что Rust владеет чем-то, что старая система не может безопасно игнорировать. Общие файлы, кэши и форматы сообщений должны оставаться стабильными, пока модуль Rust какое-то время не проработает на реальном трафике. Так постепенная миграция на Rust остаётся постепенной, а не превращается в вынужденную переработку под давлением.
Быстрые проверки перед каждым релизом
Смешанная сборка может пройти обычные тесты и всё равно сломаться из-за одного плохого указателя. В Rust и C++ FFI короткий чек-лист перед релизом экономит больше нервов, чем длинный разбор после инцидента.
Начните с владения. Каждая экспортируемая функция должна иметь одно понятное правило для памяти: кто выделяет, кто освобождает, владеет ли вызывающая сторона результатом и что происходит с null или пустым вводом. Поместите это правило в заголовок C++ и комментарии к обёртке Rust. Если кому-то в команде приходится гадать, кто освобождает буфер, релиз пока не готов.
Затем проверьте саму границу под нагрузкой. Тестов на счастливый путь недостаточно. Отправляйте невалидные enum, null-указатели там, где API это допускает, пустые строки, слишком большие буферы, нулевые длины и несоответствующие пары указатель-длина. Проверьте точный предел, а затем ещё на шаг дальше. Большинство падений прячется во входах, которые выглядят почти корректно.
Быстрый предпродажный проход должен подтвердить несколько вещей:
- Каждая экспортируемая функция говорит, кто и как освобождает память.
- Тесты покрывают невалидный ввод, пустой ввод, граничные размеры и несоответствия длины.
- В логах видно, Rust или C++ создали каждый результат.
- Команда может быстро выключить путь Rust с помощью флага или настройки.
Пункт про логирование важнее, чем кажется. Если после релиза поддержка сообщит о неверном результате, вам нужно знать, какая сторона его сгенерировала, не читая час сырые трассы. Простое поле вроде engine=rust или engine=cpp может сильно сократить время отладки.
Не менее важен и путь отката. Не привязывайте новый модуль Rust к полному redeploy, если можно этого избежать. Feature flag, переключатель версии или runtime-настройка позволяют команде вернуться к старому пути C++ за минуты, пока проблема изучается.
Если хотя бы одна из этих проверок не проходит, держите старый путь активным и сначала исправьте обёртку. Ошибки на границе становятся очень дорогими, когда их находит реальный трафик.
Что делать дальше
Выберите один модуль с узким API и понятными тестами. Движок расчёта цен, парсер или evaluator правил обычно лучше, чем общий слой утилит. Если код трогает глобальное состояние, собственные аллокаторы или цепочки обратных вызовов в пяти местах, пока пропустите его.
На этой неделе составьте одностраничную таблицу владения до того, как кто-то начнёт писать Rust. Сделайте её простой:
- какая сторона выделяет каждый объект
- какая сторона его освобождает
- проходит ли данные как копия, заимствование или непрозрачный дескриптор
- какой поток может к нему обращаться
- какое значение ошибки возвращается, если что-то не так
Эта таблица предотвращает многие ошибки Rust и C++ FFI ещё до их появления. Она также даёт ревьюерам что-то конкретное для обсуждения вместо споров на основе памяти.
После этого выберите один стиль границы и сохраняйте его для всего модуля. Если используете непрозрачные дескрипторы с C ABI, продолжайте использовать их. Если передаёте копируемые буферы туда и обратно, не смешивайте это с заимствованными указателями без очень веской и понятной причины.
Если команда чувствует неуверенность, привлеките внешнее ревью до релиза. Свежий взгляд может поймать ошибки времени жизни, утечки через исключения, несовпадения ABI и shortcuts, которые на спринте выглядят безобидно, а потом превращаются в отчёты о падениях. В смешанном коде короткое ревью часто экономит больше времени, чем ещё одна неделя программирования.
Oleg Sotnikov может помочь с такой подготовкой в роли Fractional CTO или советника. Он работает с командами над AI-first software development, архитектурой, инфраструктурой и постепенной модернизацией, так что может помочь задать правила FFI, сформировать план тестирования и выстроить поэтапный запуск по одному модулю.
Сделайте первый релиз небольшим. Поместите новый путь за флаг, сравнивайте результаты со старым модулем и следите за использованием памяти, падениями и частотой ошибок в продакшене. Если всё стабильно, переносите следующий модуль по той же схеме. Переиспользуйте таблицу владения, переиспользуйте тесты и держите границу скучной.


