Роли CTO и COO в автоматизации, которые помогают удержать пилот в рамках
Чёткие роли CTO и COO в automation помогают разделить правила процесса, системный дизайн и внедрение, чтобы пилот оставался сфокусированным и управляемым.
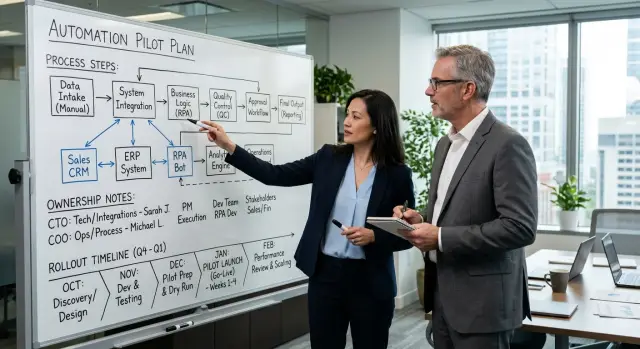
Содержание
Что заставляет пилот уходить в сторону
Большинство automation-пилотов проваливаются не потому, что софт слабый. Они сбиваются с курса, потому что команда смешивает две разные задачи: решает, как должен работать бизнес, и одновременно решает, как система должна поддерживать эту работу. Как только эти вещи начинают размываться, каждая встреча меняет и процесс, и разработку.
Обычно всё начинается с небольшого исключения. Менеджер говорит: "Можно добавить ещё один путь для VIP-клиентов?" Инженер отвечает: "Да, это можно сделать в workflow." Через неделю уже никто не понимает, откуда взялось это правило: из operations, из разового запроса или из технического обходного решения.
Вот тут и начинается путаница с ответственностью. COO должен отвечать за правила процесса, людей и исключения. CTO должен отвечать за то, как система применяет эти правила стабильно и прозрачно. Если один человек продолжает менять обе стороны, пилот перестаёт быть тестом и превращается в постоянно меняющийся scope.
Ранние признаки обычно заметны сразу:
- Команда спорит об edge cases, прежде чем согласует обычный процесс.
- Правила утверждения меняются, но никто не фиксирует, кто одобрил изменение.
- Новые запросы продолжают попадать в пилот до завершения первого цикла тестирования.
- Rollout начинается без понятного критерия успеха.
Дополнительные запросы вредят сильнее, чем ожидает большинство команд. Ранние пилоты притягивают идеи, потому что люди наконец видят, что что-то уже работает. Позже это полезно. Но на первом тесте это ломает базовую линию. Если команда добавляет дашборды, уведомления или ещё один путь согласования до завершения полного цикла, уже невозможно понять, что именно дало такой результат.
Показатели успеха не менее важны. Команды часто говорят, что пилот "выглядит многообещающе", но это почти ничего не значит. До rollout выберите одну-две метрики. Если вы автоматизируете утверждение invoice, успехом может быть сокращение времени проверки с двух дней до четырёх часов или уменьшение ручных касаний с пяти до двух. Потом тестируйте только это.
Ответственность тоже нужно зафиксировать письменно. Кто может менять бизнес-правило? Кто может менять build? Кто может приостановить rollout? Если ответы существуют только в разговоре, пилот начнёт дрейфовать, как только вырастет давление.
За что должен отвечать COO
Чёткая ответственность начинается с того, что COO описывает работу простым языком. Это значит: записать текущий процесс шаг за шагом так, как люди реально делают его сейчас, а не так, как это написано в policy manual. Пропустите этот шаг — и пилот быстро превратится в угадывание.
Карту процесса стоит наполнять скучными деталями, о которых люди обычно забывают: кто запускает задачу, где происходит approval, что проверяет staff и что происходит, когда что-то выглядит подозрительно. Для первого пилота обычно достаточно потока на 5–10 шагов. Если процесс нужно объяснять с помощью трёх whiteboards, он слишком широкий для первого раунда.
COO также должен выбрать первую команду и первый use case. Это бизнес-решение, а не техническое. Начинайте там, где работа происходит часто, правила довольно стабильны, а руководитель команды хочет помочь. Команда finance operations, которая проверяет invoice, намного лучше для пилота, чем смешанный отдел с разными привычками и неясной ответственностью.
Бизнес-правила тоже принадлежат COO. COO решает, что система должна делать, чего она никогда не должна делать и когда должен подключаться человек. Сюда входят пути исключений: отсутствующая информация, необычный размер заказа, необходимость второго approval или записи клиента, которые не совпадают.
COO также заранее определяет, как выглядит нормальное ежедневное использование до rollout. Всё должно быть просто. Сотрудники должны пользоваться инструментом каждый день, выполнять задачу за шесть минут вместо двенадцати и отправлять меньше кейсов на переделку. Если после первой недели люди избегают tool, значит пилот не работает, даже если demo выглядело гладко.
Обучение, обновление policy и обратная связь от staff тоже остаются на стороне COO. Fractional CTO может помочь собрать workflow, но operations всё равно должна объяснить людям, когда начинается новый процесс, что меняется в их работе и куда сообщать о проблемах. Обычно staff быстрее говорят правду operations, чем engineering.
Разделение простое: COO отвечает за то, как должна происходить работа.
За что должен отвечать CTO
В automation project CTO отвечает за машинную сторону работы. COO определяет процесс. CTO превращает этот процесс в software, data flow, controls и support, которым люди могут доверять.
Всё начинается с system design. CTO решает, куда входят inputs, куда попадают outputs, в какой system хранится source of truth и где человеку нужно подтвердить шаг. Если два инструмента могут редактировать одну и ту же запись, CTO должен исправить это до начала пилота.
CTO также должен заранее описать integrations. Это включает системы, которые подключаются напрямую, те, которым нужен buffer, и права доступа, которые получает каждый tool или bot. Доступы важнее, чем думают команды. Пилот может провалиться, потому что bot видит слишком много, или потому что у никого нет нужного доступа, чтобы исправить зависшую задачу.
Пути сбоев тоже входят сюда. Если API зависает, model возвращает неверный format или одна system обновляется, а следующая нет, у команды должен быть заранее продуманный ответ ещё до запуска. Ждать первого инцидента — значит превратить пилот в серию пожарных тревог.
Logging, alerts и rollback steps — часть той же работы. Demo может обойтись без них. Реальный пилот — нет. Команде нужны logs, которые показывают, что произошло, alerts, которые срабатывают, когда задачи зависают или растёт error rate, и быстрый способ приостановить или отменить изменение.
Lean-команды обычно строги в этом не просто так. У маленьких команд нет времени целый день присматривать за хрупкой автоматизацией. Поэтому advisors вроде Oleg Sotnikov на oleg.is так много внимания уделяют observability и handling failures, когда помогают компаниям переводить процессы в AI-assisted workflows.
CTO также должен честно оценивать трудозатраты. Workflow может занять три дня на разработку и пять часов в неделю на поддержку. Эта нагрузка на поддержку важна не меньше, чем время build. Она влияет на стоимость, staffing и на то, сколько изменений команда вообще сможет переварить.
Управление scope часто тоже ложится на CTO. Как только люди видят, что пилот работает, запросы начинают накапливаться очень быстро. Кому-то нужно сказать "нет". Если пилот обрабатывает invoice intake, он не должен в том же sprint разрастаться до vendor onboarding и reporting.
Хороший CTO делает больше, чем просто запускает automation. CTO следит за тем, чтобы она безопасно ломалась, оставалась понятной и давала бизнесу чёткий ответ, стоит ли расширять решение.
Где оба лидера принимают решения вместе
Некоторые решения требуют присутствия обеих сторон. COO знает, как работа должна идти день за днём. CTO знает, что система может выдержать без появления новых точек отказа. Пилот остаётся на курсе, когда оба лидера заранее согласуют несколько общих решений до того, как к нему прикоснутся реальные пользователи.
Начните с одного предложения, которое определяет цель. Оно должно быть достаточно конкретным, чтобы менеджер, analyst и engineer повторили его одинаково. Подойдёт: "Сократить время утверждения invoice с двух дней до четырёх часов для одной finance team". Не подойдёт: "Улучшить operations с помощью automation". Размытые цели провоцируют лишние запросы и бесконечные споры.
Изменения правил тоже должны идти по понятному пути утверждения. Многие пилоты уходят в сторону, потому что люди продолжают добавлять исключения после запуска. Sales хочет один путь, finance — другой, а support добавляет особый случай для одного клиента. Нужно зафиксировать, кто может утверждать изменения во время пилота. Во многих командах COO запрашивает изменение правила, а CTO решает, может ли system безопасно это обработать, прежде чем кто-то включит изменение.
Используйте один weekly scorecard. Если operations следит за speed в одном месте, а engineering — за errors в другом, пилот быстро превращается в хаос. Соберите показатели вместе: cycle time, error rate, manual handoffs, complaints пользователей и downtime. Когда оба лидера смотрят на одну и ту же страницу, настоящую проблему обычно проще увидеть.
Команда также должна согласовать три точки принятия решений до запуска:
- Stop — если новый процесс создаёт больше ручной работы, чем убирает.
- Fix — если цель всё ещё выглядит достижимой, но одно правило, handoff или integration постоянно ломается.
- Expand — если команда достигает цели в течение заданного периода и пользователи могут работать без ежедневной помощи.
Именно здесь overlap работает лучше всего. COO защищает бизнес-правило. CTO защищает system design и темп rollout. Каждый weekly review должен заканчиваться одним простым ответом: stop, fix или expand.
Как вести пилот
Начните с одного процесса, который происходит часто, достаточно болезненный, чтобы его стоило исправить, и связан с небольшой группой людей. Попробуйте автоматизировать сразу три workflow — и люди начнут смешивать проблемы, пока уже никто не поймёт, что именно сломалось. Пилот работает лучше, когда одна команда может использовать его каждый день и давать прямую обратную связь.
До того как кто-то начнёт проектировать экраны, bots или approval flow, запишите правила простым языком. Кто запускает процесс? Какие данные обязательно должны быть на месте? Когда работа останавливается? Кто может изменить результат? Документ должен быть коротким, но достаточно понятным, чтобы два человека приняли по нему одинаковое решение.
Хорошо работает простой порядок:
- Выберите один процесс и одну команду.
- Запишите бизнес-правила и исключения.
- Соберите самую маленькую версию, которая может выполнить задачу.
- Запустите её для ограниченной группы.
- Каждую неделю анализируйте результаты и убирайте лишнее.
Именно здесь многие пилоты остаются аккуратными или начинают дрейфовать. Команды часто спешат сделать красивый интерфейс, потому что это похоже на прогресс. Обычно это приводит к переделкам. Если правила слабые, tool просто начнёт быстрее принимать плохие решения.
Когда testing начался, не тратьте всё время на лёгкий путь. Используйте грязные кейсы: отсутствующие поля, дублирующиеся запросы, поздние approvals, неверные inputs и людей, которые пропускают шаги. Реальная работа полна таких вещей. Если пилот проходит только чистые тестовые данные, он ещё не готов.
Сначала запускайте решение на небольшой группе, даже если build выглядит стабильным. Десять реальных пользователей научат вас большему, чем целая комната мнений. Они же покажут, где люди игнорируют tool, обходят его или продолжают просить "ещё одно правило".
Назначьте фиксированный weekly review с COO и CTO. Сделайте его коротким и прямым. Спросите, где люди застревали, какое правило вызвало путаницу, какой ручной workaround появился, чем никто не пользовался и что можно убрать на этой неделе.
Быстро убирайте лишнее. Пилот — не место для nice-to-have идей, кастомных экранов для каждого manager или отчётов, которые никто не смотрит. Жёсткий scope делает rollout честным и сильно упрощает следующее решение.
Простой пример: approval invoice
Approval invoice — хороший первый пилот. Это происходит часто, шаги людям уже знакомы, а ошибки стоят реальных денег. Так легче увидеть, кто за что отвечает.
COO владеет правилами процесса. Сюда входит решение, какие invoice проходят быстро, какие требуют second review и как долго может ждать каждый этап. Обычный invoice ниже определённой суммы может уходить одному manager. Invoice от нового vendor или с расхождением в цене может уходить в finance на review в течение четырёх часов.
CTO отвечает за систему вокруг этих правил. Это значит: убедиться, что invoices заходят в процесс в чистом формате, попадают к нужному человеку и оставляют traceable record. Это также значит добавить alerts, чтобы команда знала, когда approval слишком долго лежит без движения или когда кто-то обрабатывает задачу по email или chat вместо workflow.
Через неделю или две оба лидера должны смотреть на один и тот же небольшой набор фактов: какие invoice не уложились в target по response time, какие люди переводили вручную, где routing отправил задачу не тому approver и какие exceptions повторялись снова и снова.
Этот review важен, потому что один и тот же симптом может указывать на две разные проблемы. Возможно, правило неправильное, и COO нужно его изменить. А может, правило нормальное, но form слишком запутана, alert приходит слишком поздно или logs слишком мало, чтобы CTO быстро нашёл причину.
Именно поэтому внешние technical advisors часто начинают с такого простого workflow. Скучная работа делает дрейф заметным. Если менеджеры продолжают утверждать одного и того же vendor вне системы или finance продолжает вручную править одни и те же поля, сначала исправьте это. Не расширяйтесь до purchase orders, expenses и refunds только потому, что dashboard выглядит занятым.
Ошибки, которые размывают ответственность
Пилот уходит не туда, когда люди переходят границы, не говоря об этом вслух. COO владеет правилами процесса. CTO владеет system design. Когда любая из сторон начинает менять часть другой стороны в загруженную неделю, команда теряет базовую линию.
Одна частая ошибка — инженеры переписывают бизнес-правила на ходу. Они видят странный кейс, быстро ставят patch и идут дальше. В моменте это кажется полезным, но на деле меняет операционную политику без одобрения. Очень скоро software начинает отражать мнение разработчика, а не то, как бизнес хочет работать.
То же происходит и в обратную сторону. Команды operations часто добавляют новые кейсы в неделю rollout, потому что реальная работа messy и всем хочется, чтобы tool покрывал всё сразу. Так маленький пилот превращается в moving target. COO должен решить, какие исключения важны сейчас. CTO должен сказать, что текущий design может выдержать, не превращая пилот в полный rebuild.
Ещё одна ошибка — измерять output, игнорируя adoption. Dashboard может показывать более быструю обработку или меньше ручных шагов, но staff всё равно избегает tool, ведёт параллельные таблицы или просит managers сделать работу за них. Если люди не доверяют workflow, цифры могут выглядеть хорошо неделю или две, а потом всё развалится.
Обучение пропускают чаще, чем команды признают. Лидеры выпускают tool, думают, что люди сами разберутся, а потом обвиняют продукт, когда ошибки растут. В большинстве случаев staff не сопротивляется automation. Они просто не понимают, что изменилось, когда этим пользоваться и что делать, если система ломается.
Support тоже часто игнорируют. Команды нередко называют пилот завершённым, как только первый workflow начинает работать. Это слишком рано. Держите пилот открытым, пока команда не сможет решать обычные проблемы без паники, вопросы в support не начнут снижаться, а пути исключений не станут понятными.
Если изменения правил появляются в chat вместо decision log, rollout week добавляет больше scope, чем планировалось, использование остаётся низким, хотя dashboards выглядят нормально, или tickets в support начинают расти сразу после объявления успеха, значит пилот ещё не стабилен.
Проверки перед расширением
Не расширяйте пилот только потому, что одно demo прошло хорошо или одна тихая неделя выглядела удачной. Расширяйте тогда, когда работа вокруг automation кажется понятной, повторяемой и немного скучной. Обычно это лучший признак того, что команда действительно контролирует ситуацию.
Начните с ownership правил. На каждый вопрос по правилу должен быть один человек, который может ответить сразу. Если заказ приходит с недостающими данными или request выходит за обычный лимит approval, команда должна точно знать, кто принимает решение. Часто это COO, но главное — скорость и ясность.
Сотрудникам тоже нужна простая инструкция, когда использовать новый flow. Люди не должны угадывать. Короткое правило вроде "используйте automated path для стандартных renewals, а необычные случаи отправляйте на manual review" достаточно, если все понимают его одинаково и действуют так же.
Технической стороне нужна такая же ясность. Команда должна быстро замечать failed runs, а не только на weekly review. Если sync ломается, задача зависает или handoff теряет data, кто-то должен сразу это увидеть и понять, что делать дальше. Обычно это зона ответственности CTO, даже если внешний fractional CTO помогает проектировать систему.
Сделайте manual fallback живым и простым. Именно здесь многие пилоты выглядят сильнее, чем есть на самом деле. Когда automation ломается, staff всё равно должен иметь возможность завершить задачу вручную без паники, путаницы у клиента или долгих задержек. Если fallback живёт только в голове одного человека, вы ещё не готовы к расширению.
Потом смотрите на результаты несколько недель подряд. Один удачный день почти ничего не доказывает. Сравните новый flow со старым по простым метрикам: время выполнения работы, количество ошибок, объём переделок и то, сколько внимания процесс требует от staff.
Если новый flow выигрывает неделя за неделей, расширение имеет смысл. Если ответственность остаётся размытой, сбои слишком долго скрываются или ручной путь уже выглядит хаотичным, сначала остановитесь и исправьте это. Больший объём не решит этих проблем.
Что делать после пилота
После пилота команды часто сразу прыгают к следующей идее. Именно тогда путаница начинается снова. Если вы хотите, чтобы следующий rollout двигался быстрее, сохраните все принятые решения в письменном виде и регулярно обновляйте их.
Сначала обновите две вещи: document с правилами и system map. В документе должно быть показано, как работает процесс, кто может делать исключения и что считается правильным результатом. System map должен показывать, какие tools участвуют в процессе, откуда приходит data и где люди всё ещё вмешиваются вручную.
Не относитесь к этим документам как к уборке после пилота. Если COO меняет approval rule или CTO меняет integration, зафиксируйте это в ту же неделю. Небольшие правки помогают следующему проекту не стартовать со старыми предположениями.
Прежде чем автоматизировать ещё один процесс, оцените его по нескольким простым вопросам:
- Как часто задача возникает каждую неделю?
- Насколько понятны business rules?
- Насколько messy data или handoff между tools?
- Сколько времени или ошибок создаёт текущий процесс?
- Насколько рискованна ошибка, если automation сломается?
Процесс, который происходит каждый день, следует понятным правилам и тратит время staff, обычно лучше как следующий шаг, чем редкий edge case. Так automation остаётся привязанной к бизнес-ценности, а не к тому, кто первым заговорил на meeting.
Сохраняйте такое же разделение и на следующем rollout, если только нет серьёзной причины его менять. COO отвечает за правила, исключения и adoption. CTO отвечает за design, integrations, reliability и план support. Совместные решения остаются совместными, но ежедневная ответственность должна быть понятной.
Если после пилота ответственность всё ещё кажется размытой, пригласите короткий внешний review. Свежий взгляд обычно быстро замечает, где process rules смешиваются с technical choices, или где system design тихо заставляет соблюдать бизнес-правило, которое никто не одобрял.
Для небольшой команды такой review не должен быть тяжёлым. Oleg Sotnikov делает такую работу через oleg.is, помогая компаниям выровнять process rules, system design и rollout до того, как они масштабируют следующий этап. Короткий review сейчас обычно дешевле, чем разбирать более серьёзный беспорядок через несколько месяцев.
Часто задаваемые вопросы
Кто должен отвечать за правила процесса в automation pilot?
COO должен отвечать за правила процесса. Это включает нормальные шаги, исключения, то, кто может утверждать изменения, и когда должен подключаться человек. Если инженеры начнут менять правила на ходу, пилот быстро потеряет базовую линию.
Что должен контролировать CTO во время пилота?
CTO отвечает за системный дизайн, интеграции, доступы, логирование, оповещения и откат. Задача не только в том, чтобы workflow работал, но и в том, чтобы сбои было легко заметить и безопасно обработать.
Как не дать пилоту уйти в сторону?
Начните с одного процесса, одной команды и одной понятной цели. Заморозьте дополнительные запросы до конца первого цикла тестирования и фиксируйте каждое изменение правила вместе с тем, кто его одобрил. Так легче видеть причину и следствие.
Что нужно измерять в первую очередь?
Выберите один или два показателя до запуска. Хорошие первые метрики — это время цикла, количество ручных действий, уровень ошибок или объём переделок. Если в первом раунде отслеживать слишком много, люди начнут спорить о отчётах вместо результата.
Когда стоит добавлять исключения или новые функции?
Подождите, пока пилот завершит полный цикл и вы увидите базовую картину. Ранние дополнения вроде новых дашбордов, ещё одного пути согласования или кастомных экранов мешают понять, что именно повлияло на результат.
Насколько маленьким должен быть первый пилот?
Сделайте первый пилот узким, чтобы одна команда могла пользоваться им каждый день и давать прямую обратную связь. Процесс на 5–10 шагов со стабильными правилами обычно работает лучше, чем широкий workflow, для которого нужно сразу согласие нескольких отделов.
Что делать, если сотрудники продолжают работать вне инструмента?
Считайте это важным сигналом, а не сразу проблемой обучения. Проверьте, не слишком ли запутано правило, не неудобна ли форма, не приходят ли оповещения слишком поздно и не кажется ли ручной путь проще. Исправьте причину, по которой люди обходят flow, а потом снова измерьте использование.
Нужен ли ручной fallback?
Да. Когда automation зависает, сотрудникам всё равно нужен простой способ завершить работу без паники и долгих задержек. Опишите этот fallback и убедитесь, что команда знает, когда его использовать.
Как понять, что пора остановиться, исправить или расширить?
Сверяйте один и тот же scorecard каждую неделю. Останавливайтесь, если пилот создаёт больше ручной работы, чем убирает; исправляйте, если одно правило или одна интеграция постоянно дают сбой, но цель всё ещё достижима; расширяйте только тогда, когда команда достигает цели несколько недель подряд.
Когда стоит привлечь внешнего advisor?
Пригласите внешнего эксперта, когда ответственность размыта, изменения правил накапливаются или команда не может понять, проблема в operations или в build. Короткий review поможет разделить бизнес-решения и технические вопросы, пока небольшой беспорядок не вырос.


