REST hooks против опроса: что выбрать для клиентских интеграций
Выбор между REST hooks и опросом влияет на скорость доставки, политику повторов, настройку файрвола и объём работы поддержки. Используйте это руководство, чтобы выбрать подходящий интерфейс.
Содержание
Какую реальную проблему решает этот выбор
Выбор между REST hooks и опросом сводится к трём вещам: кто должен действовать, как быстро нужно действовать и сколько усилий по настройке готовы вложить ваша команда и клиент.
Некоторые обновления важны в момент их появления. Ошибочный платёж, сигнал о мошенничестве, проблема с отправлением или блокировка аккаунта часто требуют быстрой реакции. Если поддержке или ops‑команде нужно реагировать немедленно, ждать следующего запланированного опроса ощущается как неправильное решение, даже если данные в итоге верные.
Другие изменения могут подождать. Сводачные панели, ночные синхронизации, экспорты и низкорисковые статусы обычно не требуют мгновенной доставки. Если задержка в пять минут ничего не меняет, это указывает на более простой интерфейс и меньше шагов по настройке для клиентов.
Контроль тоже важен. Если вы контролируете и отправителя, и получателя, вы можете строить поток и быстро устранять шероховатости. Если одну сторону контролирует клиент, выбор усложняется: его правила хостинга, ревью безопасности и умения команды имеют такое же значение, как и дизайн API.
Нагрузка на поддержку снова меняет ответ. Один клиент с сильным инженером настроит вебхук быстро. Сорок клиентов с разными правилами файрвола, стейджингами и шагами утверждения превратят тот же выбор в поток тикетов. Опрос часто требует от клиента меньше на старте, но может породить вопросы позже, когда люди заметят задержки или пропуски.
Простой способ принять решение — записать, какие события клиентам действительно нужны сразу, какие обновления могут подождать несколько минут, кто контролирует каждую сторону соединения и сколько клиентов потребуют ручной помощи при настройке.
Обычно это проясняет суть. REST hooks против опроса — это не только технический выбор. Чаще всего это продуктовое и поддерживающее решение с техническими последствиями.
Насколько свежими должны быть данные
Начните с простого вопроса: что ломается, если обновление придёт с опозданием в 30 секунд, 5 минут или час? Если пользователи ожидают, что экран, оповещение или рабочий поток изменятся почти сразу, hooks обычно подходят лучше. Они отправляют событие сразу, поэтому людям не нужно постоянно обновлять страницу и гадать.
Это важно для статуса платежа, проверок на мошенничество, обновлений доставки или всего, что влияет на действия пользователя. Если действие должно разблокировать, заблокировать или уведомить кого‑то немедленно, медленная синхронизация ощущается неправильно, даже если данные корректны.
Polling часто годится, когда небольшая задержка ничего не меняет. Ежедневные отчёты, бэкофис‑синхронизации, сводки по биллингу и низкорисковые проверки статусов обычно хорошо работают по расписанию. Если никого не волнует, придёт ли обновление через 20 секунд или 10 минут, polling проще для рассуждений.
Практический тест — частота. Спросите, как часто принимающая система должна вызывать ваш API, чтобы казаться достаточно свежей. Каждые 5 секунд кажется моментально, но быстро умножается в запросах. Каждые 15 минут снижает нагрузку, но пользователи могут заметить устаревшие данные. Правильный интервал — самый короткий, который не создаёт лишних затрат.
Всплески событий меняют картину. Десять событий в день удобно опрашивать. Десять тысяч событий за пять минут — нет. Задание на опрос может пропустить кратковременные изменения между запусками или постоянно тянуть одни и те же записи, если используется пересекающееся временное окно для безопасности.
У hooks свои режимы отказов. Если получатель медленный или коротко недоступен, события могут прийти с опозданием, не по порядку или повторно после попыток. Это нормально. Получатель должен уметь детектировать дубли и безопасно обрабатывать одно и то же событие несколько раз.
Чаще всего выбор прост: используйте hooks, когда продукт выглядит неправильно без почти реального времени, и polling, когда небольшая задержка не меняет результата.
Как выглядят повторы и отказы
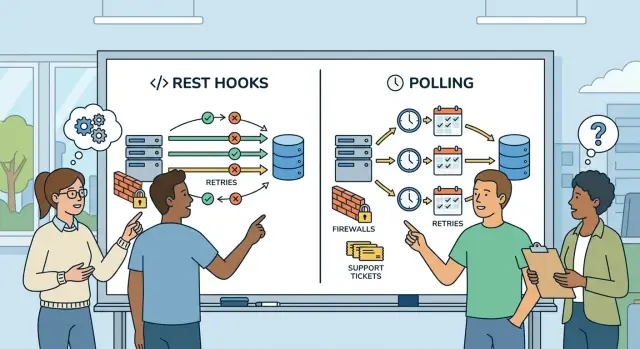
Отказы — часть нормальной работы. В выборе REST hooks vs polling большая часть сложностей — решить, кто замечает отказ, кто повторяет и когда прекращает попытки.
При polling логика повторов остаётся на стороне клиента. Если их последний запрос таймаутится, они просто попросят снова в следующем цикле. Это легко объяснить, но короткие простои могут скрываться, потому что никто не видит неудачную доставку — клиент просто получает текущее состояние позже.
Hooks перекладывают эту ответственность на отправителя. Если destination таймаутится, возвращает 500 или недоступен несколько минут, вашей системе нужна политика повторов до отправки реального трафика. Такая политика должна указывать, какие ошибки считать временными, как часто повторять и когда пометить событие как неудачное. 429 обычно стоит попробовать снова, а 404 — скорее нет.
Идемпотентность важнее, чем многие команды ожидают. Получатель может обработать событие, а затем упасть до отправки 200. Отправитель посчитает доставку неудачной и пришлёт событие ещё раз. Если получатель создаёт второй счёт, отправляет второе письмо или меняет заказ дважды, поддержке придётся разбираться с проблемой, которую код мог предотвратить.
Решение простое по концепции: давайте каждому событию постоянный ID и заставьте получателя считать этот ID уже обработанным. Храните результат достаточно долго, чтобы покрыть окно повторов.
Нарушения порядка тоже раздражают. Новое обновление может прийти раньше старого, если повтор задержал первую посылку. Если получатель применяет события только в порядке прихода, данные могут откатиться назад. Добавьте номер последовательности, версию или временную метку события и заставьте получателя игнорировать более старое состояние.
Также нужна политика повторного воспроизведения. Храните неудачные события достаточно долго, чтобы клиент мог исправить учётные данные, скорректировать правило файрвола или поднять сервис. Несколько часов часто слишком мало. Хранить вечно — обычно пустая трата. Выберите срок хранения, соответствующий реальной работе поддержки, и делайте повтор воспроизведения контролируемым действием.
Команде поддержки нужен трайс доставки, который можно быстро прочитать. Для каждой попытки записывайте ID события, время, назначение, код ответа, произошёл ли таймаут или соединение было установлено чисто, и что система планирует сделать дальше.
Этот лог превращает расплывчатый тикет вроде «мы не получили обновление» в ответ за минуты. Без него каждая ошибка превращается в гадание.
Где файрволы и сетевые правила блокируют вас
В вопросе REST hooks vs polling сетевая политика часто решает выбор быстрее, чем сравнение функций. Вебхук звучит просто, пока вы не узнаете, что клиент не может принимать входящий HTTPS‑трафик вообще. Если их сеть блокирует публичные callback'и, ваш чистый поток событий останавливается ещё до первого теста.
Задайте один прямой вопрос рано: может ли их система принимать входящие запросы из интернета или она может только делать исходящие вызовы? Многие компании разрешают исходящие API‑вызовы, но по умолчанию блокируют входящий трафик. В такой ситуации polling обычно одобряют с меньшими обсуждениями.
Команды безопасности часто добавляют ограничения после общего одобрения: фиксированные исходные IP для allowlist'а, VPN‑туннель, приватный сетевой путь или маршрутизация через прокси. Каждое дополнительное правило увеличивает время настройки и количество точек, где тесты могут упасть.
Короткий звонок с командой безопасности или ИТ клиента сэкономит дни переписки. Спросите про входящий HTTPS, allowlist исходных IP с обеих сторон, требования к VPN или приватной сети, правила прокси, TLS‑инспекцию, кастомные сертификаты и отдельные тестовые и прод‑эндпойнты.
Сертификаты, DNS и тестовые endpoint'ы кажутся мелочью, но часто тормозят команды сильнее, чем код интеграции. Кому‑то нужно создать hostname, выпустить сертификат, подтвердить цепочку и убедиться, что тестовая среда достаточно похожа на прод. Если хоть один шаг отвалится, доставка вебхука провалится, и API обвинят в проблеме.
Polling легче вписывается в жёсткие сети, потому что система клиента сама устанавливает соединение. Эта модель хорошо работает, когда правила безопасности строги или никто не хочет открывать публичный endpoint для одной интеграции. Вы платите свежестью данных за простоту согласования и меньший сетевой налад.
Если клиент может принимать входящие запросы и уже экспонирует публичные API, вебхуки всё ещё могут быть лучшим решением. Если же каждое изменение в файрволе требует тикета, двух ревью и окна работ, polling часто выигрывает по практичности.
Часто задаваемые вопросы
When should I choose hooks instead of polling?
Используйте hooks, когда пользователям или командам операций нужен апдейт практически сразу. Отказы платежей, проверки на мошенничество, блокировки аккаунтов и изменения в доставке обычно попадают в эту категорию.
Выбирайте polling, когда небольшая задержка ничего не ломает. Отчёты, сводки и синхронизации бэкофиса часто нормально работают по расписанию.
When is polling the better default?
Polling хорошо работает, когда клиенты находятся за строгими сетевыми правилами и не могут выставить публичный endpoint. Он также даёт более простую начальную настройку для многих небольших клиентов.
Просто установите интервал, который соответствует бизнес‑требованиям. Если опрашивать слишком редко — данные будут устаревать; если слишком часто — тратите запросы и рискуете упереться в лимиты.
How much delay is too much for polling?
Начните с простого вопроса: что ломается при задержке в 30 секунд, 5 минут или 1 час? Если для работы пользователя нужна свежая информация в течение нескольких минут, polling подойдёт. Если пользователь не может выполнить следующий шаг без свежих данных, выбирайте hooks.
Если действие зависит от самого свежего состояния, лучше не пытаться «замаскировать» задержку частыми опросами.
What usually goes wrong with hooks?
Основные проблемы — повторы и дубли. Получатель мог обработать событие, но упал до отправки 200, и отправитель решит повторить. Если при этом ресивер создаёт второй счёт или дважды меняет заказ, поддержке придётся разбираться.
Давайте каждому событию стабильный ID и требуйте, чтобы получатель игнорировал повторы. Также защищайте систему от прихода сообщений не по порядку — добавляйте sequence, версию или временную метку.
Do hooks always need retries and idempotency?
Да. При использовании hooks нужно заранее продумать политику повторов. Решите, какие ошибки считать временными, как часто повторять и сколько хранить неудачные события.
На стороне получателя необходима идемпотентность. Без неё один таймаут может превратиться в дублированные счета, письма или изменения заказа.
How do firewall rules change the decision?
Часто именно сетевые правила принимают решение ещё до того, как вы начнёте обсуждать API. Многие клиенты позволяют исходящие вызовы API, но блокируют входящие HTTPS‑запросы из интернета.
Если они не могут принимать входящие запросы, polling выигрывает по практичности. Если у клиента уже есть публичные API и они могут добавить ваш трафик в allowlist, hooks всё ещё могут быть подходящим вариантом.
Which option creates more support work?
Hooks обычно создают тикеты на этапе настройки: неверный секрет, проблемы с TLS, таймауты или неправильный ответ endpoint'а. В этот момент нужна детальная запись попыток доставки.
Polling даёт проблемы позже: пользователи спрашивают, почему данные устарели, или клиенты укорачивают интервал и попадают под лимиты. Оба подхода приносят свою нагрузку, просто она проявляется по‑разному.
Should I support both hooks and polling?
Поддерживайте оба варианта только если команда действительно умеет объяснить, протестировать, мониторить и поддерживать их оба. Для многих команд один надёжный дефолт лучше, чем две недоделанные опции.
Оставьте вторую опцию для исключений, если она оправдана реальными потребностями клиентов.
What should I log so support can debug missed updates?
Логируйте достаточно данных, чтобы быстро ответить на тикет. Храните ID события или request ID, временную метку, назначение, код ответа, данные о таймауте, историю повторов и следующее планируемое действие.
Для polling фиксируйте интервал опроса, временное окно и то, что клиент вытащил. Эти детали превращают гадания в конкретные ответы.
What is the simple rule for order status updates?
Если партнёру нужны все промежуточные состояния прямо сейчас — выбирайте hooks. Если ему важен только последний статус с периодической синхронизацией, polling обычно подходит.
Для обновлений заказа задайте один вопрос: нужен ли стороне получателя каждый шаг или лишь текущий статус? Обычно этого достаточно, чтобы принять решение.


