Рефакторинг по бизнес-возможностям — малыми понятными для ревью шагами
Рефакторьте по бизнес-возможностям малыми обозримыми срезами: переносите логику из контроллеров и сервисов в понятные домены, чтобы команда могла легче менять, тестить и ревьюить код.
Содержание
Почему такая структура кода начинает мешать команде
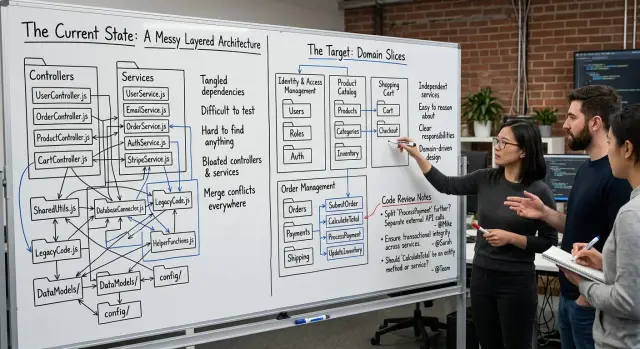
Кодовая база, разделённая на controllers, services, repositories и helpers, может выглядеть аккуратно в первый день. Проблемы начинаются, когда меняется одно бизнес-правило. Это правило редко находится в одном месте.
Часть его сидит в контроллере, потому что кто-то должен был отклонить неверный запрос. Другая часть живёт в сервисе, потому что там считается сумма. Третья — в задании, которое обновляет учёт или отправляет письмо. Через несколько месяцев никто не укажет одно ясное место для «правил возврата». Небольшое изменение политики превращается в поиск.
Из-за этого команды продолжают править одну и ту же логику в трёх местах. Имена папок вроде services и controllers говорят вам, на каком слое выполняется код. Они не говорят, где живёт политика возврата, апгрейд плана или блокировки аккаунта. Это помогает фреймворку больше, чем команде.
Ревью становятся грязными по той же причине. Изменение затрагивает много слоёв, и рецензенту приходится восстанавливать бизнес-правило, прыгая между файлами. Pull request, который должен читаться как одна ясная история, раскидан. Люди пропускают пограничные случаи, потому что полное правило нигде не показывается.
Вы обычно видите цену этого в повседневной работе:
- разработчики спрашивают, кто владеет фичей, и получают три разных ответа
- исправление багов занимает дольше, потому что люди ищут перед тем, как что-то менять
- рецензенты тратят время на проводку и нейминг вместо самого правила
- дублирующиеся проверки ползут, потому что никто полностью не доверяет старым
Нечёткая ответственность усугубляет ситуацию. Если биллинг частично в контроллерах, частично в сервисах и частично в общих утилитах, никто не чувствует полной ответственности. Когда появляется баг, команда его перекладывает друг на друга. Новый разработчик сначала учит архитектурные метки, а уже потом — продукт.
Рефакторинг по бизнес-возможностям это исправляет. Суть не в красивых папках. Суть — вернуть ощущение, что одна область продукта снова является одной областью. Когда код соответствует бизнесу, изменения становятся меньше, ревью проще, а ответственность понятнее.
Как выглядит бизнес-возможность
Бизнес-возможность — это кусок работы, который компания может назвать простыми словами. Биллинг — один. Возвраты — другой. Сброс пароля, отправка заказа и регистрация на пробный период тоже подходят. Люди вне инженерии обычно могут назвать эти вещи, не видя кода.
Это и есть тест. Если продакт-менеджер, основатель или саппорт говорит «Нужно поменять, как работают возвраты», ваша команда должна знать, куда смотреть. Если ответ «частично в контроллерах, частично в сервисах и ещё какие-то хелперы», значит код следует именам слоёв, а не поведению бизнеса.
Контроллер описывает, где код сидит. Сервис часто превращается в бакет для всего, что не поместилось в другое место. Бизнес-возможность описывает, зачем код существует. Эта разница важна. Когда код сгруппирован по возможностям, срез легче ревьюить и легче за ним ухаживать.
Хорошие имена звучат как действия или чёткие области работы: create-invoice, collect-payment, issue-refund, cancel-subscription, send-renewal-reminder. Такие имена говорят читателю, что делает код, ещё до открытия файла. Папки controllers, services или utils этого не делают.
Возвраты — хороший первый пример, потому что большинство команд уже понимает поток. Кто-то просит деньги назад, система проверяет заказ, фиксирует решение, обновляет состояние платежа и отправляет сообщение. Этот путь может касаться обработчика API, бизнес-правил, работы с БД и уведомлений, но всё равно принадлежит одной возможности.
Срез не должен включать все случаи возврата с первого дня. Начните с одного пути, например «вернуть оплаченный заказ в течение 30 дней». Дайте этому пути дом refunds или issue-refund, затем перенесите подпомогающий код. Оставьте несвязанный биллинг там, где он есть, на пока.
Если имя похоже на задачу команды, а не на результат для пользователя, перепишите его. «Payment service» — размыто. «Issue refund» — конкретно. Команды быстрее ревьюят конкретные изменения и тратят меньше времени на споры о том, куда положить новый код.
Выберите первый срез, который можно закончить
Начните с потока, которым команда часто пользуется. Если его меняют каждый спринт, вам уже известно место боли. Это облегчает первое движение и даёт честную проверку, помогает ли подход.
Хорошие первые срезы имеют ясный старт и финиш. Пользователь отправляет запрос на возврат. Заказ подтверждается. Токен сброса пароля проверяется и потребляется. Вам нужен один путь с очевидными входными данными, выходом и небольшим набором правил посередине.
Лучший первый ход редко самый большой проблемный участок. Команды часто указывают на биллинг, авторизацию или самый старый общий модуль и говорят: «надо это починить первым». Обычно это всё замедляет. Большие модули скрывают слишком много побочных эффектов, владельцев и старых допущений.
Выберите что-то поменьше, но важное. Хороший кандидат — один поток, запускаемый одним запросом или одной задачей от начала до конца. Вы должны суметь назвать его вход, результат и правило в одном предложении. Также желательно переместить его в одном pull request или в двух маленьких, без переписывания половины приложения. Существующие тесты должны покрывать поведение, даже если структура поменяется.
Если работа разлетается по половине кодовой базы, сожмите её ещё. «Refunds» может быть слишком широким для первого шага. «Create refund request» лучше. «Payments» слишком велико. «Mark invoice as paid after confirmed webhook» гораздо безопаснее.
Определите финиш до того, как кто-то начнёт писать код. Держите его скучным: вынесите один поток из контроллеров и сервисов, поведение оставьте прежним, старую точку входа поддержите, добавьте или обновите тесты. Если вы не можете описать «готово» в двух предложениях, срез ещё слишком большой.
Команды, которые делают это хорошо, оставляют себе выход. Перенесли один срез — узнали, где скрыты зависимости — остановились. Этого достаточно. Цель не в том, чтобы подчистить всю систему за один заход. Цель — закончить одну часть, которую команда может ревьюить без усталости.
Переносите один срез шаг за шагом
Когда поток пользователя живёт в контроллерах, сервисах, моделях и случайных хелперах, полный ребилд быстро превращается в хаос. Возьмите один путь, проследите все файлы, которые он трогает, и двигайте только этот путь. Чем меньше срез, тем легче ревью. И тем проще откатиться, если что-то сломалось.
Простой порядок действий работает хорошо:
- Составьте карту файлов для потока. Найдите действие контроллера, методы сервисов, которые оно вызывает, код моделей, читающий или записывающий данные, и любые хелперы для валидации, форматирования или прав доступа. Запишите список, чтобы не пропустить мелочи.
- Создайте одну папку или модуль для этой возможности. Назовите его по работе, которая важна бизнесу, а не по слою фреймворка.
order-cancellationпонятнее, чемservicesилиutils. - Переносите бизнес-логику прежде, чем заниматься неймингом. Сначала поместите правила в новый модуль, затем позвольте старому контроллеру или сервису вызывать его. Это отделяет изменения поведения от перестановки файлов.
- Оставьте старые точки входа на какое-то время, но сделайте их тонкими. Контроллер должен читать запрос, вызывать доменный код и возвращать ответ. Если старый сервис всё ещё есть, пусть он будет только обёрткой.
- Останавливайтесь после каждого шага и запускайте тесты. Если поток слабо покрыт тестами, добавьте один-два целевых теста перед тем, как продолжать. Несколько маленьких рефактор-срезов побеждают один гигантский pull request.
Этот порядок важен. Если вы переименуете файлы, переместите папки, перепишете импорты и измените логику в одном проходе, ревьюеру придётся гадать, что именно поменялось. Когда вы сначала перемещаете логику, они могут проверить поведение с меньшим шумом.
Так команды переходят от контроллеров к доменам, не замораживая delivery. Каждый merge делает код чуть понятнее, и никому не нужно одобрять рискованный перепис целиком.
Простой пример с возвратом денег
Поток возврата — хороший первый срез, потому что команды обычно знают, где он начинается и что значит «готово». Клиент просит деньги назад, приложение проверяет несколько правил, общается с платёжным провайдером, фиксирует результат и возвращает ответ.
Во многих кодовых базах контроллер делает слишком многое. Он парсит запрос, проверяет, существует ли заказ, сверяет период возврата, блокирует двойные возвраты, вызывает платёжный API, пишет аудит и триггерит письмо.
Это может работать какое-то время. Затем одно маленькое изменение политики превращается в запутанное ревью, потому что бизнес-правило смешано с деталями HTTP.
До переноса
Представьте RefundController на 120 строк. Вверху он читает JSON. В середине решает, что возвращаемы только оплаченные заказы за последние 30 дней. Внизу вызывает платёжный шлюз и отправляет подтверждение по почте.
Рецензенту теперь нужно ответить на множество вопросов в одном файле. Контроллер безопасно парсит вход? Правило про 30 дней всё ещё верно? Запись аудита должна идти до или после вызова шлюза? Что если заказ уже был возвращён?
Это разные заботы, но код смешивает их вместе. Вот где такой рефактор приносит пользу.
После переноса
Сделайте контроллер скучным. Он читает запрос, вызывает домен возврата и формирует HTTP-ответ.
Домен возврата может держать части, которые действительно определяют возвраты: валидацию, критерии допустимости, отмену платежа, запись аудита и последующие действия вроде письма. Не нужен гигантский ребилд. Переносите по одному кусочку, пока поток возврата не станет читаться как одно бизнес-действие вместо пяти разбросанных шагов.
Ревью становится проще, когда поток имеет один дом. Вместо общих комментариев типа «этот контроллер слишком много знает» рецензенты могут задавать прямые вопросы к правилу: разрешать ли частичный возврат? Должен ли дубликат запросов возвращать тот же результат? Фиксировать ли неудачные попытки в шлюзе?
Это сдвиг важен. Код начинает соответствовать тому, как люди говорят о продукте. Когда спрашивают «Как работают возвраты?», ответ живёт в домене возврата, а не по трём папкам.
Правила ревью, которые сохраняют срез маленьким
Рефактор теряет смысл, когда один pull request просит рецензента судить о пяти вещах одновременно. Перенесите код, переименуйте, почините тесты и почистите старые файлы в одном диффе — бизнес-изменение утонет. Один рецензент должен уметь прочитать PR за 15–20 минут и объяснить, что изменилось для пользователей.
Обычно это значит: один срез = один бизнес-путь. Если вы переносите логику возврата в домен refunds, держите PR только про этот путь. Если работа тянет за собой биллинг, почту и отчётность — остановитесь и разбейте на последующие задачи.
Маленькие архитектурные изменения требуют жёсткой границы. Трогайте только файлы, которые поддерживают срез. Если нужно взаимодействовать со старым кодом контроллеров или сервисов, добавьте тонкий адаптер и двигайтесь дальше. Не используйте срез как предлог для переименования половины проекта.
Переименовывайте только внутри области, которую уже меняете. Локальные имена, соответствующие бизнес-концепции, помогают ревьюеру. Широкие переименования в несвязанных папках делают наоборот: наполняют дифф шумом и скрывают реальные изменения поведения.
Заметки к pull request держите короткими и конкретными. Назовите бизнес-поток. Скажите, что осталось прежним. Скажите, как вы это проверили. Упомяните любой откладываемый клин-ап. Достаточно заметки вроде: "Создание возврата теперь живёт в refund domain. Поведение API не изменилось. Я тестировал полные и частичные возвраты. Старые названия биллинга оставлены для отдельной задачи.".
Держите очистку кода отдельной, даже если старый код раздражает. Мёртвые хелперы, массовые переименования файлов, правка комментариев и стилистические правки могут подождать. Второй маленький PR читать легче, чем один гигантский «пока я тут был».
Команды работают быстрее, когда защищают время на ревью таким образом. Код улучшается, и никому не нужно расшифровывать 2000-строчный дифф, чтобы одобрить одно изменение по возвратам.
Ошибки, которые замедляют рефактор
Большинство рефакторов тянутся по одной и той же причине: команда превращает ясное движение в широкий проект уборки. Если начали с возвратов — держите ветку про возвраты. Как только ветка затрагивает биллинг, настройки аккаунта, общие хелперы и переписывание тестов одновременно, никто не сможет нормально её ревьюить.
Обычная проблема — не сам перенос, а объём. Малый срез даёт рецензентам шанс понять изменение, протестировать и быстро смёржить. Шаблоны провала предсказуемы. Ветка растёт и затрагивает половину приложения. Ревьюеры перестают читать внимательно, комментарии накапливаются, и работа висит днями. Или команда переименовывает папки раньше, чем переносит логику. Это создаёт шум сначала и ясность потом — наоборот. Сначала двигайте поведение, проверьте, что оно работает, затем чистите имена.
Ещё одна частая ошибка — смешивать фичи с рефактором в одном PR. Исправление бага, UI-правка и архитектурное изменение вместе усложняют расследование, если что-то сломалось. Код может попасть в прод, но команда теряет чистое представление о том, что изменилось.
Нейминг тоже создаёт проблемы. Новые папки core, common или shared-domain скрывают ответственность, а не делают её явной. Правило возврата должно жить с возвратами, а не в бакете, который означает всё и ничего одновременно.
Худший вариант — старые правила остаются на старом месте, а новые появляются в новом. Пока приложение работает, команда это игнорирует. Месяц спустя одно налоговое правило меняют в одном месте, но забывают другое — и появляются две версии истины.
Малые команды ощущают это быстрее. Фаундер, ведущий инженер или Fractional CTO часто ревьюят код между другими задачами, так что огромная архитектурная ветка быстро теряет импульс. На практике короткие ветки выигрывают, потому что отвечают на один простой вопрос: мы безопасно перенесли эту возможность или нет?
Если срез начинает разрастаться — сократите его. Уберите переименования, вынесите фичу в отдельную задачу, удалите дублирующее правило. Скучный PR, который можно завернуть за 15 минут, лучше эффектного, который никогда не попадает в мастер.
Проверки перед мержем
Перед мержем откройте дифф и задайте простой вопрос: если кто-то придёт в команду на следующей неделе, сможет ли он найти этот бизнес-поток за минуту?
Срез готов, когда ответ «да». Код одного потока должен жить в одном месте, которое совпадает с тем, как люди говорят о продукте. Если правила возврата в refund domain, но половина логики всё ещё спрятана в контроллерах, хелперах и старых сервисах — срез не готов.
Быстрый осмотр обычно показывает несколько явных признаков:
- контроллер остаётся тонким и вызывает одно доменное действие
- бизнес-правила находятся вместе в одной очевидной папке или модуле
- тесты покрывают правила, а не только HTTP-статусы
- рецензент может описать всё изменение одной фразой
- команда знает, кто будет отвечать на вопросы по этому срезу после мёрджа
Проверка покрытия тестов важнее, чем многие думают. Если вы тестируете только endpoint, можно перенести сломанные правила в красивую папку, и баг проскользнёт. Для потока возврата тестируйте само решение: кто может вернуть, когда возврат блокируется и как система обрабатывает частичный возврат. Эти тесты делают перенос безопаснее и сохраняют честность для будущих правок.
Правило «одна фраза» — хороший фильтр по объёму. Если рецензент говорит: «Это переносит логику решения по возвратам в billing/refunds и оставляет контроллер тонким», то срез, вероятно, достаточно мал. Если нужно целое повествование — дифф делает слишком много.
Ответственность — последняя проверка, и команды часто её пропускают. После мёрджа кто-то должен знать, что эта область — их, чтобы поддерживать порядок. Это не значит, что один человек вечно охраняет её. Это значит, что команда может назвать, кто будет ревьюить следующий изменённый кусок, фиксить дрейф нейминга и не допускать утечки логики обратно в случайные файлы.
Если эти проверки пройдены — мержьте. Если две-три не соблюдены — снова уменьшите срез, пока ветка не станет свежее и проще для ревью.
Что делать с остальной кодовой базой
Когда один срез заработал в проде, не останавливайтесь, чтобы спроектировать идеальное финальное состояние. Выберите следующий срез там, где команда уже чувствует боль. Недавние баги, повторяющиеся правки и потоки, которые ломаются при релизах — лучшие ориентиры, чем большой архитектурный диаграмм.
Хорошая очередь проста: посмотрите последний месяц фиксов и файлы, которые люди постоянно меняли вместе. Если возвраты продолжают тянуть изменения из контроллеров, сервисов и общих хелперов, этот поток стоит переместить раньше, чем тихая часть приложения. Это делает работу практичной, а не побочным проектом.
Установите одно правило именования для новых модулей и держите его скучным. Имена вроде refunds, billing или onboarding легко запомнить. Держите связанные правила, доступ к данным и тесты внутри модуля. Не создавайте новые общие папки вроде misc, common или utils, если команда не договорилась об узкой причине.
Отслеживайте прогресс по бизнес-потокам, а не по числу папок. Сказать «возвраты и чарджебэки теперь живут вместе» для команды гораздо информативнее, чем «мы переместили 18 файлов». Первый вариант показывает, что стало проще менять, тестировать и ревьюить.
Это также помогает продукту и инженерии оставаться на одной волне. Продакт поймёт, что checkout частично мигрирован, а удаление аккаунта всё ещё смешано со старым кодом. Никому вне команды не важно, сколько service-файлов исчезло.
Держите темп ровным. Один-два среза за спринт обычно достаточно, если каждый срез убирает реальную фрустрацию. Команды попадают в проблемы, когда пытаются переименовать всё сразу и оставляют наполовину завершённые границы по базе кода.
Если команде нужна вторая точка зрения перед началом следующего среза, Oleg Sotnikov на oleg.is работает как Fractional CTO и советник для стартапов. Он помогает малым и средним бизнесам с архитектурой продукта, инфраструктурой и практической AI-first разработкой — такой ранний ревью может сэкономить недели переработки позже.
Часто задаваемые вопросы
Что значит рефакторинг по бизнес-возможности?
Это значит группировать код по бизнес-действию, которое он выполняет, например refunds или cancel-subscription, а не по слоям фреймворка вроде controllers или services. Правила для одного потока находятся в одном месте, и их проще найти и ревьюить.
Как выбрать первый кусок?
Начните с одного потока, который команда часто меняет и который можно завершить в одном небольшом pull request. Например, путь «создать запрос на возврат» лучше, чем большой раздел вроде billing или auth.
Стоит ли переписывать весь модуль сразу?
Нет. Сохраните старую точку входа, перенесите один поток за ней и не меняйте поведение. Небольшие изменения принимаются быстрее и дают возможность откатиться, если нужно.
Насколько тонким должен быть контроллер?
Контроллер должен читать вход, вызывать одно доменное действие и возвращать ответ. Уберите из контроллера правила возврата, проверки платежей и последующие шаги — пусть он перестанет принимать бизнес-решения.
Какие тесты добавить перед переносом кода?
Тестируйте само правило, а не только endpoint. Для возвратов покройте тестами, кто может вернуть, когда система блокирует возврат и что происходит при частичных или повторных запросах.
Насколько большим должен быть pull request?
Достаточно маленький, чтобы один ревьюер мог прочитать его за ~15–20 минут и объяснить изменение для пользователя одной фразой. Если diff затрагивает много потоков — разделите работу.
Какие имена папок лучше использовать?
Используйте имена, которые люди в продукте и саппорте уже говорят: refunds, onboarding, chargebacks. Избегайте расплывчатых корзин вроде core, shared-domain или utils — они скрывают ответственность.
Как избежать дублирования правил?
Назначьте одно место для правила и удалите старую копию, как только новый путь заработает. Если обе версии остаются, команда будет редактировать одну и забывать другую.
Что делать с общими хелперами и utils?
Не трогайте общие хелперы и utils, если они не поддерживают переносимый кусок. Если хелпер нужен только для возвратов — переместите его в модуль refunds; иначе оставьте это на потом и держите рефакторинг в фокусе.
Как понять, что кусок готов к слиянию?
Мержьте, когда новый коллега сможет найти этот поток за минуту, контроллер остаётся тонким, бизнес-правила собраны вместе, а тесты покрывают логику принятия решения. Если всё ещё нужно искать по старым файлам — сократите срез снова.


