Как разделить ingress в Kubernetes для публичного, партнёрского и внутреннего трафика
Разделение ingress в Kubernetes начинается с чёткой схемы для публичного, партнёрского и внутреннего трафика, чтобы аутентификацию, лимиты и логи было легко контролировать.
Содержание
Почему один ingress быстро превращается в хаос
На первый взгляд один ingress выглядит аккуратно. Вы складываете все маршруты в одно место, запускаете и идёте дальше. Но спокойствие обычно заканчивается, когда к одному приложению приходит трафик разных типов.
Публичным пользователям, партнёрам и сотрудникам почти никогда не нужны одни и те же правила. Публичному трафику обычно нужны фильтрация ботов, простые лимиты и широкая доступность. Партнёрскому трафику чаще нужны аутентификация по конкретному клиенту, IP-allowlist или более высокие лимиты для пакетных задач. Внутреннему трафику нужны более жёсткий доступ, другие аудиторские следы и гораздо меньшая терпимость к случайному раскрытию.
Когда всё это находится за одним общим ingress, граница размывается. Запросы по-прежнему маршрутизируются, но становится сложнее понять, для кого они вообще предназначены. Ошибка 403 в логах может прийти от клиента, партнёрской интеграции или сотрудника, открывшего админский экран. Если команде каждый раз приходится проверять пути и заголовки, отладка замедляется без всякой пользы.
Чаще всего путаница начинается с маленьких исключений. Одному пути нужен более длинный таймаут. Одному партнёру нужен больший burst limit. Один внутренний endpoint должен пропускать публичное правило. Каждое изменение по отдельности кажется разумным, поэтому команды продолжают добавлять аннотации, сопоставления путей и особые случаи. Со временем никто уже не хочет трогать ingress, потому что одно изменение может сломать сразу три аудитории.
Представьте один host, который обрабатывает /api, /partner и /admin. Публичный трафик резко вырастает из-за акции, партнёрские задачи запускаются каждый час, а сотрудники пользуются админской частью в рабочее время. Если у них одни и те же правила входа и одни и те же логи, шум от одной группы может скрыть проблемы в другой.
Именно поэтому разделение ingress обычно окупается довольно рано. Речь не о красивом YAML. Речь о чётких границах. Правила аутентификации проще понимать, лимиты лучше подходят под клиента, а логи рассказывают более чистую историю, когда что-то ломается.
Определите границу до того, как писать правила
Чистое разделение ingress начинается на бумаге, а не в YAML. Если пропустить этот шаг, публичный, партнёрский и внутренний трафик окажутся смешаны за одной границей, и каждое правило аутентификации превратится в последующее исключение.
Сначала перечислите всех, кто обращается к кластеру. Не останавливайтесь на «пользователях» и «сервисах». Включите браузеры, мобильные приложения, партнёрские вебхуки, сотрудников бэк-офиса, инструменты поддержки, CI-задачи, пользователей офисного VPN и запланированные задания. Команды часто забывают одного тихого клиента, а потом строят весь ingress под неправильную схему.
Затем отметьте каждый маршрут по аудитории. Публичные маршруты смотрят в открытый интернет, поэтому им нужны более сильные механизмы защиты от злоупотреблений и более простое поведение при сбоях. Партнёрским маршрутам нужны стабильные контракты, более понятная проверка личности и логи, которые отвечают на простой вопрос: их система обратилась к вам корректно или сначала сломалась ваша сторона? Внутренние маршруты должны жить на частных путях и не выходить в публичную зону, даже если endpoint выглядит безобидно.
Ещё важно понять, как каждая группа попадает в систему. Браузер может приходить через CDN или load balancer. Партнёр может обращаться по фиксированному hostname с известных IP-диапазонов. Внутренние сотрудники могут заходить через VPN, SSO или частную сеть. От точки входа зависит, каким заголовкам вы доверяете, где применяются лимиты и как читать исходный IP в логах.
Быстрая проверка выявляет большинство ошибок:
- Кто обращается к этому маршруту?
- Откуда они заходят?
- Как они подтверждают личность?
- Какие логи понадобятся, когда что-то сломается?
- Можно ли безопасно делить одну границу с другой аудиторией?
Некоторые маршруты не должны делить одну и ту же границу, даже если трафика там мало. Админские панели, billing callbacks, партнёрские загрузочные endpoints, health-check endpoints и внутренние инструменты — типичные примеры. Если одна плохая конфигурация может их раскрыть, разделите их заранее.
Допустим, у вашего приложения есть публичный API для регистрации, партнёрский webhook для заказов и внутренняя панель для сотрудников. На старте все три маршрута могут быть небольшими. Если они находятся за одним ingress, довольно скоро появляются исключения по путям, пользовательские заголовки, особые лимиты и смешанные логи. Если каждой аудитории с самого начала дать свою дорожку, дальнейшие изменения останутся локальными, а инциденты будет намного проще распутывать.
Выберите схему разделения, которую вашей команде будет легко поддерживать
Лучшая схема разделения ingress — та, которую команда может прочитать за минуту и менять без страха. Если публичные пользователи, партнёры и сотрудники заходят через один и тот же набор правил, небольшие отличия быстро накапливаются. Одно изменение аутентификации для партнёров, один лимит для публичного API, одна правка логирования для внутренних инструментов — и файл начинает сопротивляться.
Хорошее базовое решение — отдельные hosts для разных аудиторий. Дайте публичному сайту свой host, партнёрскому трафику — свой, а внутренние инструменты держите на частном host или на частном сетевом пути. Разным аудиториям нужны разные политики, и отдельные hosts делают это очевидным.
Используйте отдельные ingress-объекты, когда правила различаются. Даже если все они обрабатываются одним controller, разделяйте объекты по аудиториям. Так настройки аутентификации, лимитов, IP allowlist и аннотаций для логов останутся на своих местах вместо того, чтобы смешиваться в одном большом манифесте.
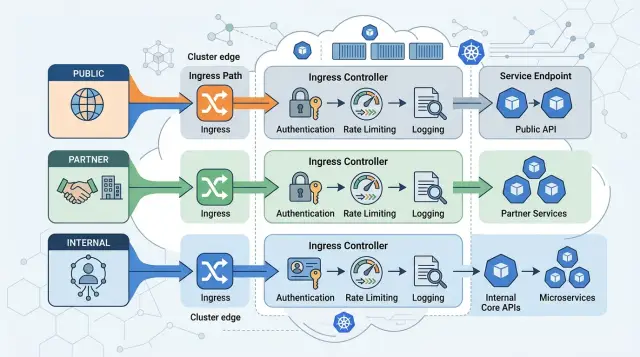
Для многих команд достаточно простой схемы: публичный трафик получает один host и один ingress-объект, партнёрский трафик — другой, а внутренние инструменты вообще не выходят на публичную точку входа. Один ingress controller может поначалу обслуживать все три. DNS, сертификаты и маршрутизация остаются понятными, а изменение для партнёров не затрагивает сотрудников или публичных пользователей.
Внутренние инструменты требуют большей дисциплины, чем ожидает большинство команд. Если дашборд или админская панель находится на той же публичной точке входа, что и клиентский трафик, кто-то рано или поздно будет относиться к ней как к обычному правилу пути. Поместите её за частную сеть, VPN или хотя бы за отдельный приватный load balancer. Одно это решение убирает много будущей ручной работы.
Добавляйте ещё один ingress controller только тогда, когда вам нужна жёсткая изоляция. Хорошие причины — отдельная сетевой граница, другая зона ответственности в эксплуатации, более строгие требования комплаенса или необходимость уменьшить blast radius между публичным и внутренним трафиком. Если у вас нет одной из этих причин, второй controller обычно добавляет больше движущихся частей, чем пользы.
Настройте разделение по шагам
Используйте три дорожки с самого начала: public, partner и internal. Дайте им понятные имена, которые никто не перепутает через шесть месяцев, например public-api, partner-api и internal-api. Если команда использует разные hostnames для каждой дорожки, ошибки во время ревью замечаются быстрее.
Держите один ingress на каждую дорожку и дайте каждому ingress только одну задачу. Это звучит строго, но позже экономит время. Когда публичное правило стоит рядом с внутренним исключением в одном файле, команды начинают добавлять быстрые исправления, и граница постепенно размывается.
Хорошо работает простой план внедрения:
- Создайте публичный ingress для браузеров, мобильных приложений и анонимных пользователей.
- Создайте партнёрский ingress для одобренных клиентов, поставщиков или интеграций с внешними системами.
- Создайте внутренний ingress для инструментов сотрудников, back office-приложений и доступа сервис-к-сервису.
- Добавьте аутентификацию на ingress для каждой дорожки вместо того, чтобы размазывать её по многим сервисам.
- Отправьте логи каждой дорожки в свой поток, чтобы алерты и аудит оставались читаемыми.
Аутентификацию становится проще настраивать, когда вы привязываете её к дорожке, а не смешиваете со всеми маршрутами. Публичному трафику могут понадобиться проверки сессии или базовая защита от ботов. Партнёрскому трафику часто нужны API keys, mTLS или подписанные запросы. Внутренний трафик обычно должен требовать корпоративную учётную запись или сетевые правила. Когда каждый ingress отвечает за свою аутентификацию, вы можете менять одну аудиторию, не ломая остальные.
Лимиты должны исходить из ожидаемого трафика, а не из догадок. Для публичных endpoints чаще нужны более строгие per-IP ограничения, потому что туда может прийти кто угодно. Партнёрский трафик обычно более ровный, поэтому лимиты лучше задавать по реальному использованию или условиям контракта. Внутреннему трафику могут подойти более мягкие ограничения, но защитные рамки всё равно нужны, чтобы один плохой скрипт не залил кластер.
Логи заслуживают такого же разделения. Поместите публичные, партнёрские и внутренние логи в отдельные потоки с одинаковым форматом request ID. Тогда команда сможет быстро отвечать на простые вопросы: этот всплеск вызвало публичное приложение, один партнёр или внутреннее задание?
Небольшая команда может настроить это за один день. Начните с именования, создайте три ingress-объекта, привяжите аутентификацию на уровне ingress, задайте первичные лимиты и отправьте логи в отдельные хранилища. Это первое разделение убирает много будущей ручной работы.
Простой пример для трёх аудиторий
У SaaS-приложения часто один продукт, но три очень разных типа трафика. Клиенты пользуются основным приложением каждый день. Партнёры отправляют API-запросы из своих систем. Сотрудники открывают админскую панель, чтобы исправлять аккаунты, проверять биллинг или разбирать обращения поддержки. Если всё это проходит через одну общую точку входа, правила быстро становятся хаотичными.
Чистая схема обычно начинается с трёх дорожек: один публичный host для входа клиентов и обычного трафика приложения, один партнёрский host только для API-запросов и один приватный host для админской панели.
Публичная дорожка — самая загруженная. Она обрабатывает сессии браузера, вход в систему и обычные колебания клиентского трафика. Её по-прежнему нужно защищать, но приоритет здесь — удобный доступ, стабильные сессии и хорошая обработка ошибок. Если страница входа ломается под нагрузкой, это сразу бьёт по всем пользователям.
Партнёрской дорожке нужен более строгий проход. Каждый запрос должен содержать token или подписанные credentials, а лимит должен соответствовать реальной интеграции. Один партнёрский скрипт может отправить тысячи неверных запросов за несколько минут, если что-то пойдёт не так. Отдельные правила позволяют проще приостановить одного партнёра, не трогая клиентский трафик.
Админская дорожка должна быть труднодоступной. Многие команды разрешают её только через VPN, офисные IP-диапазоны или и то и другое. Это отсекает большую часть нежелательного трафика ещё до того, как кто-то увидит экран входа. И это же держит админскую панель на более низком уровне риска, чем публичное приложение.
Логи и алерты должны следовать тому же разделению. Логи публичного трафика помогают заметить ошибки входа или резкие всплески. В партнёрских логах должно быть видно, какой credentials обратился к какому endpoint и где начались сбои. Внутренние логи должны концентрироваться на попытках доступа, заблокированных IP и необычных действиях внутри панели. Когда у каждой дорожки свои логи и алерты, команда быстрее находит проблемы и не гоняется за шумом от чужой аудитории.
У каждой дорожки — своя аутентификация, лимиты и логи
Разделение ingress работает только тогда, когда у каждой дорожки есть собственные защитные правила. Публичный, партнёрский и внутренний трафик могут попадать в одно приложение, но заходить они должны по-разному. Если относиться к ним как к одному потоку, появляются запутанные правила, шумные логи и сбои, которые трудно объяснить.
Начните с публичной дорожки. Проверяйте идентичность клиента на границе, до того как запрос уйдёт глубже в стек. Обычно это означает session cookies, OAuth или другой способ входа, подходящий вашему продукту. Держите эту логику рядом с публичной точкой входа, чтобы анонимный трафик, просроченные сессии и очевидный бот-шум останавливались там же.
Партнёрскому трафику нужен другой тест. Не пускайте партнёрские запросы к общим сервисам, пока не проверите token, key или подписанный заголовок, который они используют. Плохие credentials должны быстро получать понятный отказ. Это защищает общие API от случайного злоупотребления и упрощает поддержку, когда один партнёр начинает слать сломанный трафик.
Внутренним инструментам нужна самая строгая граница, даже если ими пользуются всего несколько человек. Ограничьте их сетевыми правилами так, чтобы они принимали трафик только из корпоративных диапазонов, VPN или приватных gateway. Затем добавьте поверх корпоративный SSO. Если админская панель доступна из публичного интернета без обеих проверок, кто-нибудь её обязательно найдёт.
Лимиты должны соответствовать дорожке, а не всему приложению целиком. Публичные endpoints нуждаются в защите от всплесков, скрейпинга и brute force при входе. Партнёрским endpoints нужны более ровные квоты, привязанные к каждому клиенту. Внутренним endpoints обычно достаточно мягких лимитов, но защита от злоупотреблений всё равно нужна.
Логи важны не меньше, чем аутентификация. Каждая дорожка должна записывать одинаковый набор ключевых полей, чтобы можно было сравнивать события между системами. Делайте это просто и последовательно: request ID, тип клиента, название дорожки, результат аутентификации и итоговое решение. Когда запрос завершается ошибкой, вы хотите быстро ответить на три вопроса: кто его отправил, какая дорожка его обработала и почему он прошёл или был отклонён.
Разница хорошо видна на практике. Если клиент открывает приложение, публичная дорожка проверяет вход и может ограничить повторные попытки авторизации. Если запускается партнёрская задача синхронизации, партнёрская дорожка проверяет token до того, как запрос попадёт к общим API. Если сотрудник открывает админский инструмент, внутренняя дорожка сначала проверяет сетевой доступ, а затем корпоративный SSO. Один кластер, но совершенно разные правила.
Ошибки, которые потом аукнутся
Большинство проблем с ingress начинается с размытых границ аудитории, а не с битого YAML. Схема может выглядеть аккуратно на диаграмме, но всё равно превращаться в ежедневную возню, когда публичные пользователи, партнёры и сотрудники попадают на одну и ту же границу.
Одна из частых ошибок — ставить каждую аудиторию за один wildcard host. Кажется удобным отправлять всё через *.example.com, но это почти гарантирует дрейф политик. Cookies, CORS-правила, лимиты и фильтры ботов начинают перетекать между аудиториями. Когда одна команда меняет значение по умолчанию, расплачивается за это другая аудитория.
То же самое происходит, когда партнёрские маршруты живут в том же дереве путей, что и публичные API. Путь вроде /api/partner может работать какое-то время, а потом кто-нибудь добавляет rewrite, общее правило аутентификации или catch-all path — и партнёрский трафик начинает вести себя как публичный. Отдельные hosts или отдельные ingress-объекты делают намерение очевидным. Общие пути скрывают различия до тех пор, пока релиз не идёт не так.
Скопированные аннотации тоже наносят тихий ущерб. Команды часто клонируют блок ingress и забывают, что новой аудитории нужны другие аутентификация, размер тела запроса, таймаут или лимит. Публичному трафику могут потребоваться контроль ботов и более жёсткие лимиты. Партнёрским вызовам — стабильные квоты и более понятные коды ошибок. Внутренним инструментам обычно нужны более строгие проверки личности, а не публичные значения по умолчанию.
Логи тоже создают проблемы. Если каждая дорожка пишет одну и ту же бедную строку лога, вы теряете идентичность клиента в тот момент, когда она нужна сильнее всего. Ошибка 401 или 429 означает совсем разные вещи для конечного пользователя, партнёрской учётной записи и сотрудника, который работает в админском инструменте. Оставляйте в логах поля, зависящие от аудитории, например partner ID, service account или роль пользователя, иначе разбор инцидента превратится в гадание.
Самый плохой shortcut — оставить внутренние инструменты публичными, пока вы планируете очистку «скоро». Скоро легко растягивается на месяцы. Search-консоли, админские панели, preview-приложения и страницы метрик должны с самого начала находиться за частным сетевым доступом, VPN или IP-allowlist.
Если маршруту нужны другая аутентификация, другие лимиты или другие логи, дайте ему свою дорожку до того, как трафик вырастет. Такая небольшая структура потом экономит очень много времени.
Короткая проверка перед запуском
Разделение ingress остаётся аккуратным, когда финальная проверка скучная. Вам нужны понятные имена, понятные владельцы и несколько тестов, которые доказывают, что каждая дорожка ведёт себя так, как вы ожидаете.
Пройдитесь по этому списку до того, как кто-то объединит финальные правила:
- Присвойте каждому host и пути метку аудитории. Public, partner или internal должны быть указаны в конфигурации, документации и разговоре команды. Если маршрут не подходит ни к одной дорожке, остановитесь и решите это сейчас.
- Назначьте владельца для каждой дорожки. Это может быть команда или один человек, но кто-то должен отвечать за изменения правил, инциденты и исключения.
- Спровоцируйте несколько ошибок аутентификации и посмотрите, куда они попадают. Неверный публичный логин должен появиться в public-логах. Отклонённый партнёрский token должен попасть в partner-логи. Шум от внутренней аутентификации не должен заполнять тот же поток, который весь день смотрит support.
- Подберите лимиты под реальный трафик, а не под догадки. Публичным endpoints часто нужен более строгий контроль burst. Партнёрский трафик может приходить ровными пакетами. Внутренние задачи могут давать всплески во время деплоя или запланированной синхронизации, поэтому им нужны другие значения.
- Проверьте внутренние маршруты из публичного интернета и убедитесь, что они fail closed. Не ограничивайтесь «скорее всего заблокировано». Отправьте реальный внешний запрос и подтвердите, что маршрут не отвечает, не редиректит и не утечёт заголовками.
Небольшой dry run помогает. Попросите одного человека вне вашей команды пройти публичный путь, ещё одного — отправить партнёрский запрос с правильными credentials и ещё одного — вызвать внутренний маршрут из разрешённой сети. Такая быстрая проверка находит неаккуратные совпадения host и перекрывающиеся пути быстрее, чем длинное совещание.
Если вы работаете со стартапами или небольшими командами, сделайте проверку настолько простой, чтобы новый инженер мог пройти её за десять минут. Сложные ingress-правила быстро стареют. Чёткие границы — нет.
Что делать дальше вашей команде
Начните с доски, а не с YAML. Нарисуйте на одной странице все hosts, пути и аудитории. Отметьте, какие маршруты выходят в публичный интернет, какие используют партнёры и какие должны быть доступны только сотрудникам или back office-инструментам. Если один маршрут сегодня обслуживает две аудитории, обведите его первым. Именно смешанные маршруты позже создают больше всего путаницы.
Лучший первый шаг обычно — сначала изменить границу, а уже потом детали. Сначала разнесите публичный, партнёрский и внутренний трафик по разным дорожкам. Потом добавьте для каждой дорожки подходящую аутентификацию, лимиты и логи. Команды часто делают наоборот и потом неделями чинят исключения.
Сделайте первый проход небольшим. Выберите маршруты, у которых и так самая понятная аудитория. Перенесите смешанные маршруты в отдельные ingress-объекты или controller. Дайте каждой дорожке базовую политику аутентификации и ограничений запросов. Отправляйте логи в отдельные dashboards или indexes, чтобы support мог быстро их читать.
Затем тестируйте реальный трафик, а не только конфигурационные файлы. Прогоните один партнёрский сценарий целиком, например API-запрос с теми же заголовками, которые отправляет партнёр. Прогоните и один внутренний сценарий, например доступ к админскому инструменту из офисной сети или через VPN. Проверьте четыре вещи: запрос доходит до нужного backend, аутентификация работает как ожидается, лимиты не мешают нормальному использованию, а логи содержат достаточно деталей, чтобы разобрать плохой запрос за минуты.
Если на бумаге что-то кажется неясным, в продакшене это будет ещё хуже. Переименуйте маршруты, уберите старые catch-all-правила и запишите, кто владеет каждой дорожкой. Такая небольшая уборка часто экономит часы во время инцидентов.
Если вам нужен второй взгляд перед запуском, Oleg Sotnikov из oleg.is работает со стартапами и небольшими компаниями как Fractional CTO и advisor. Он помогает командам выстроить архитектуру, инфраструктуру и операционные границы, а короткий обзор может поймать ошибки в аутентификации или логировании до того, как они превратятся в шум в продакшене.
Часто задаваемые вопросы
Почему один общий ingress так быстро превращается в хаос?
Потому что один общий ingress размывает смысл. Публичным пользователям, партнёрам и сотрудникам нужны разные аутентификация, лимиты и логи, поэтому каждое исключение делает конфигурацию сложнее для чтения и легче для поломки.
Какой самый простой вариант разделения ingress подходит большинству команд?
Начните с трёх дорожек: public, partner и internal. Дайте каждой свою точку входа и свой ingress-объект, а внутренний трафик держите подальше от публичного входа.
Лучше разделять по хосту или по пути?
Выбирайте отдельные хосты, если аудитории разные. Пути могут работать какое-то время, но общие деревья путей почти всегда приводят к переписываниям, утечкам правил и catch-all-правилам, которые затрагивают не тех клиентов.
Нужно ли мне несколько ingress controller?
Добавляйте второй controller только тогда, когда нужна жёсткая изоляция. Отдельные сетевые границы, более строгие требования комплаенса или разная ответственность за эксплуатацию оправдывают дополнительные элементы; большинству команд достаточно одного controller и отдельных ingress-объектов.
Где лучше размещать правила аутентификации?
Ставьте аутентификацию на уровне дорожки прямо в ingress, а проверки внутри сервиса оставляйте там, где им место. Так у каждой аудитории будет один понятный контрольный пункт, и сломанные запросы будут отсекаться раньше.
Чем должны отличаться лимиты для публичного, партнёрского и внутреннего трафика?
Ориентируйтесь на поведение клиента, а не на одно общее число для всего приложения. Для публичных endpoints обычно нужны более жёсткие ограничения по IP, для партнёрского трафика — квоты по клиенту, а внутреннему трафику всё равно нужны защитные рамки, чтобы один плохой скрипт не перегрузил кластер.
Что стоит логировать для каждой дорожки?
Для каждого запроса записывайте request ID, название дорожки, тип клиента, результат аутентификации и финальное решение. А затем добавляйте детали, зависящие от дорожки, например partner ID или роль пользователя, чтобы команда могла разбирать сбои без догадок.
Как защитить внутренние или админские маршруты?
Держите админские и внутренние маршруты за частной сетью, VPN, офисными IP-диапазонами или приватным load balancer. Затем добавьте сверху корпоративный SSO, чтобы маршрут никогда не находился на том же уровне доступности, что и клиентский трафик.
Какие ошибки вызывают проблемы после запуска?
Команды часто страдают из-за wildcard-хостов, скопированных аннотаций и смешанных логов. Если маршруту нужны другая аутентификация, другие лимиты или другой объём аудита, разделите его заранее, а не чините исключения позже.
Как проверить разделение до продакшена?
Перед запуском отправьте реальные запросы через каждую дорожку и специально вызовите несколько ошибок. Проверьте, что каждый запрос попадает в нужный backend, аутентификация отклоняет нужный трафик, лимиты не мешают нормальной работе, а логи попадают в правильный поток.


