Проверки drift Terraform в GitLab CI, которые ловят правки через консоль
Проверки Terraform drift в GitLab CI помогают командам замечать правки через консоль до того, как они расползутся, быстро разбирать различия и приводить state и код в порядок.
Содержание
Как drift выглядит в повседневной работе
Drift редко начинается с большой ошибки. Обычно всё начинается с того, что кто-то открывает облачную консоль, чтобы быстро исправить одну маленькую проблему.
Разработчик увеличивает размер инстанса перед запуском. Специалист по эксплуатации добавляет входящее правило, чтобы подключился подрядчик. Основатель меняет DNS-запись во время ночного инцидента. Каждое изменение кажется временным, и почти все планируют потом всё подчистить.
Потом обычно так и не наступает.
Вот почему drift в инфраструктуре как код так раздражает. Система продолжает работать, поэтому никто не чувствует боль сразу. Нет pull request, нет ветки обсуждения, и часто нет заметки в тикете. Проходит неделя, потом три, и ручное изменение начинает выглядеть нормой.
Обычно примеры скучные. Для теста добавляют правило security group. Базе данных на время загруженной недели дают больше места. Кто-то меняет переменную окружения в облачной панели. Во время сбоя меняют лимит autoscaling. В managed-сервисе переключают настройку, чтобы остановить алерты.
Одно изменение не выглядит серьёзным. Нескольких таких изменений в staging и production уже хватает, чтобы код начал врать.
Именно тогда доверие ломается. Файлы Terraform описывают одну конфигурацию. В облачном аккаунте уже другая. Никто не понимает, какая версия отражает реальное решение.
После этого ревью становятся запутанными. В pull request виден Terraform plan с неожиданными изменениями, но у reviewer нет контекста. Terraform удаляет плохой hotfix или стирает настройку, от которой теперь зависит production?
Даже внимательные команды начинают гадать. Один человек approves, потому что diff выглядит безобидно. Другой блокирует его, потому что plan кажется рискованным. Оба реагируют на одну и ту же проблему: код перестал совпадать с реальностью.
Пожара нет, но обычная работа замедляется. Вместо вопроса «хорошее ли это изменение» команде сначала приходится разбираться, что уже произошло.
Почему правки через консоль ломают доверие к коду
Правки через консоль обычно появляются под давлением, а не из-за халатности. Сервер перегрелся, очередь выросла, срок поджимает — и кто-то меняет одну настройку в AWS, GCP или другой панели, потому что так быстрее, чем открывать merge request.
Сама правка — не главная проблема. Настоящая проблема начинается тогда, когда Terraform всё ещё описывает старое состояние.
Маленькое изменение может оставить за собой длинный хвост путаницы. Если инженер увеличил размер базы данных в консоли во время инцидента, следующий Terraform plan может попытаться снова уменьшить его, проигнорировать связанное изменение или спрятать важную разницу в шумном diff. И тогда команде приходится останавливаться и задавать базовый вопрос: какой версии доверять?
Сомнения быстро расходятся дальше. Ревью замедляются, потому что каждый plan требует дополнительной проверки. Релизы начинают казаться рискованными, потому что обычный apply может случайно вернуть старую настройку. Откаты тоже усложняются, потому что код уже не отражает то, что реально работает в production.
Drift ещё и оставляет рискованные изменения на виду. Правило с публичным IP, открытое всего на час, может простоять неделями. Более крупный инстанс может каждый день увеличивать расходы. Удалённый alert может оставить сервис тихо падать, пока пользователи не начнут жаловаться.
Многие команды сначала не замечают этого, потому что приложение всё ещё работает. Именно это ложное чувство контроля и делает правки через консоль в Terraform опасными. Будущие изменения становятся менее предсказуемыми, и небольшие команды чувствуют это быстрее всего. Когда один человек одновременно отвечает за продукт, поддержку и инфраструктуру, одна ad hoc правка может съесть половину дня.
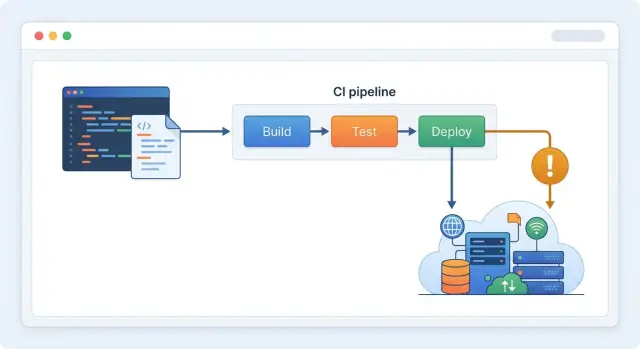
Именно здесь помогают drift-проверки Terraform в GitLab CI. Они ловят несоответствие заранее, до того как infrastructure code превратится в историю, которой никто до конца не верит.
Что на самом деле делает drift-check в GitLab
Terraform лучше всего работает тогда, когда совпадают три версии правды: код в репозитории, state-файл и живые ресурсы в вашем облачном аккаунте.
State-файл — это память Terraform. Он хранит сведения о том, что Terraform создал или изменил в последний раз. Если кто-то меняет правило security group в облачной консоли, живой ресурс меняется первым. Код и state по-прежнему описывают старую конфигурацию. Этот зазор и есть drift.
Проверка инфраструктуры в GitLab CI даёт вам регулярное место, где можно искать этот зазор. Вместо того чтобы ждать следующего большого изменения инфраструктуры, pipeline запускает terraform plan в чистой задаче. Команды часто делают это на merge request, чтобы каждое изменение инфраструктуры начиналось с быстрой проверки реальности. Многие запускают такую проверку и по расписанию, потому что ручные правки не ждут следующего merge.
Во время drift-проверки terraform plan делает больше, чем просто читает ваши .tf-файлы. Он обращается к provider, читает текущие настройки ресурсов, обновляет представление Terraform об этих ресурсах и сравнивает результат с кодом. Он сам ничего не меняет. Он лишь показывает, что сделал бы Terraform, если применить его прямо сейчас.
Этого достаточно, чтобы ответить на важные вопросы. Кто-то вручную поменял живой ресурс? Ресурс исчез или изменился вне Terraform? Совпадает ли текущее состояние с кодом в Git? Будет ли Terraform что-то обновлять, заменять, пересоздавать или удалять?
Если plan показывает неожиданные изменения, на этом нужно остановиться и навести порядок. Иногда вы импортируете недостающий ресурс. Иногда откатываете правку через консоль. Иногда обновляете код, потому что ручное исправление оказалось правильным решением. Суть в том, чтобы решить всё, пока изменение ещё свежо, а не через две недели, когда уже никто не помнит, зачем это было сделано.
Для большинства стартапов достаточно ежедневной проверки по расписанию. Если в консоль всё ещё заходят несколько человек, запускайте её чаще.
Как настроить задачу по шагам
Drift-check лучше всего работает как отдельная задача CI. Не смешивайте её с apply, тестами и форматированием, чтобы результат было легко читать. Когда эта задача падает, команда должна быстро понимать только одно: что-то изменилось вне Terraform.
Начните с terraform init в CI, используя тот же backend, что и в обычном рабочем процессе. Параметры backend и облачные credentials берите из переменных GitLab CI, а не из захардкоженных значений в репозитории. Если CI смотрит не в тот state или не в тот аккаунт, проверка расскажет вам не ту историю.
Затем запустите plan с подробными кодами выхода. Для drift-проверок -refresh-only сохраняет сигнал чистым, потому что Terraform сравнивает реальную инфраструктуру с текущим state и кодом, не смешивая это с новыми запланированными изменениями из вашей ветки.
drift_check:
stage: validate
image: hashicorp/terraform:1.6
rules:
- if: '$CI_PIPELINE_SOURCE == "schedule"'
- if: '$CI_PIPELINE_SOURCE == "merge_request_event"'
script:
- terraform init -input=false
- terraform plan -refresh-only -input=false -detailed-exitcode -out=drift.tfplan || export TF_EXIT=$?
- test "${TF_EXIT:-0}" = "0" -o "${TF_EXIT:-0}" = "2"
- terraform show -no-color drift.tfplan > drift.txt
- exit ${TF_EXIT:-0}
artifacts:
when: always
paths:
- drift.tfplan
- drift.txt
Коды выхода простые. 0 означает, что Terraform не нашёл изменений. 2 означает, что drift найден. 1 означает ошибку задачи, так что сначала исправьте pipeline, прежде чем доверять результату.
Сохраняйте и бинарный файл plan, и текстовую версию как artifacts. Бинарный файл пригодится, если кто-то захочет посмотреть его позже. Текстовый файл даёт reviewer-ам что-то, что можно быстро прочитать в выводе pipeline.
Запускайте эту задачу и по расписанию, и на merge request. Плановые проверки ловят правки через консоль, которые случаются в случайный вторник после обеда. Проверки на merge request ловят drift до того, как кто-то наложит на него ещё больше кода инфраструктуры.
Первую версию держите простой. Одна ежедневная drift-проверка по утрам ловит большинство неожиданных правок. Если ваша платформа более загружена и несколько человек всё ещё меняют облачные настройки, запускайте её чаще.
Как выбрать правила для fail, warn и cleanup
Обычно лучше работает, когда команды разделяют drift по окружениям, а не применяют одно правило ко всему.
Несовпадение тега в dev-стеке раздражает, но это не то же самое, что ручное изменение production-сети или правил доступа. Production, общая инфраструктура, secrets, IAM, публичная сеть и всё, что связано с расходами или безопасностью, должны сразу ронять pipeline. Короткоживущие окружения вроде demo-стеков или временных test-веток могут ограничиться предупреждением.
У каждого окружения должен быть свой владелец. Не оставляйте очистку drift тому, кто заметил его первым. Отдайте dev и staging инженеру или команде, которая использует их каждый день. Production назначьте конкретному человеку, который может approve-нуть исправления. Если стеком помогает управлять внешний Fractional CTO, назначьте ещё и внутреннего backup. Когда этот человек offline, кто-то всё равно должен отвечать за дальнейшие действия.
Когда появляется drift, допустимы только два исхода. Либо вы обновляете Terraform, чтобы код совпал с реальным изменением, либо откатываете ручную правку, чтобы реальность совпала с кодом. Не оставляйте третий вариант, где все соглашаются починить это потом. Именно так drift в инфраструктуре как код превращается в фоновый шум.
Срочные правки через консоль должны иметь срок действия, а не бессрочный пропуск. Если кто-то меняет настройку во время инцидента, задайте короткий дедлайн на очистку. Для многих команд хорошим стандартом будет 24 часа. Инцидент может оправдать правку, но он не оправдывает то, что она неделю висит без документации.
Достаточно простой политики. Разрешайте ручные изменения только во время инцидента или согласованного maintenance. Записывайте, кто сделал изменение и зачем. Устанавливайте срок действия исключения. Открывайте merge request, чтобы зафиксировать изменение в коде или откатить его. Закрывайте исключение только после того, как drift-check снова проходит.
Чёткие правила всегда лучше, чем сложная логика в pipeline.
Простой пример для стартапа
Представьте стартап из пяти человек с одним production-окружением. Команда использует Terraform для сети, базы данных и правил firewall. В обычные дни такая схема кажется достаточно маленькой, чтобы управлять ею без особой церемонии.
Но потом основателю нужен быстрый доступ для подрядчика, который помогает с проблемой клиента. Вместо того чтобы ждать инженера, основатель открывает облачную консоль и добавляет новый IP-адрес в правило firewall. Приложение продолжает работать, подрядчик подключается, и все идут дальше.
Проблема начинается на следующий день. Terraform всё ещё считает старое правило источником правды, а в production уже есть что-то другое.
Ночной drift-job в GitLab CI ловит это. Pipeline ничего не применяет. Он только проверяет текущее состояние и сравнивает его с кодом Terraform. В 2 часа ночи задача падает и показывает, что правило firewall в production разрешает один лишний IP, которого нет в репозитории.
Этого достаточно, чтобы команда быстро среагировала. Если правка через консоль решила реальную текущую задачу, они добавляют правило в Terraform и коммитят его. Если основателю нужен был только временный доступ, IP удаляют из консоли и снова запускают проверку.
Главное здесь — скорость. Они исправляют несоответствие до следующего deploy, поэтому Terraform не пытается неожиданно что-то отменить или заменить.
Такой процесс прост и хорошо масштабируется. Оставляйте экстренный доступ только на время решения проблемы. К следующему рабочему дню либо зафиксируйте изменение в Terraform, либо откатите его в консоли. Требуйте чистый drift-check перед следующим production-deploy.
Одна маленькая правка через консоль остаётся маленькой, потому что команда разбирается с ней, пока контекст ещё свежий.
Ошибки, которые создают лишний шум
Drift-check должен сообщать что-то полезное. Слишком многие команды приучают себя игнорировать его, потому что задача падает по грязным причинам, не имеющим отношения к реальному drift.
Одна частая ошибка — использовать один и тот же набор переменных для всех окружений. Dev, staging и production редко долго остаются одинаковыми. Размеры инстансов меняются, feature flags отличаются, правила именования расходятся. Если один общий набор кормит все plan, pipeline начнёт считать ожидаемые различия ошибками. Дайте каждому окружению свои переменные и сделайте эти различия явными.
Ещё одна шумная привычка — добавлять ignore-правила только ради зелёного pipeline. Некоторые поля действительно шумные, но у каждого ignore-правила должна быть письменная причина. Если никто не может объяснить, почему поле исключено, уберите исключение и устраните настоящую проблему. Широкие ignore-правила только облегчают сокрытие правок через консоль.
Важна и ответственность. Когда drift-job падает, а за очистку никто не отвечает, сбой превращается в обои. Красный pipeline, который висит три дня, учит команду, что drift не важен.
Смешивание drift-проверок с apply-задачами создаёт ещё одну путаницу. Drift-check должен отвечать на один вопрос: совпадает ли живая инфраструктура с кодом? Apply-задача делает другое. Когда оба действия происходят на одном шаге, люди не могут понять, нашёл ли pipeline проблему или сам изменил окружение.
Cleanup тоже не может быть необязательным. Если кто-то изменил security group в облачной консоли, команда должна либо зафиксировать это изменение в Terraform, либо откатить его. Если оставить несоответствие на месте, код перестаёт быть надёжным.
Исправление несложное. Используйте отдельные переменные для каждого окружения. Добавляйте ignore-правила только тогда, когда можете объяснить их. Назначайте владельца каждому упавшему drift-job. Запускайте drift-проверки и apply-задачи на разных этапах. Быстро убирайте подтверждённый drift.
Команды, которые так делают, обычно видят меньше алертов, а те алерты, которые остаются, действительно стоит читать.
Проверки перед merge
Drift-job полезна только если она ведёт себя как ваш настоящий apply-job. Если проверка запускается с другими переменными, другим state backend или устаревшими secrets, она может пропустить реальные проблемы или выдать шум. Именно так команды перестают доверять результату.
Drift-проверки Terraform в GitLab CI должны использовать те же входные данные, что и обычные изменения инфраструктуры. Drift-job должна читать те же файлы переменных, те же secrets и то же workspace или имя окружения. Если production использует один набор значений, а drift-job незаметно использует другой, plan описывает не ту систему.
Прежде чем полагаться на проверку, убедитесь в нескольких базовых вещах. Drift-job должна загружать те же переменные и secrets, что и apply-job. Она должна указывать на правильный remote state backend для этого окружения. Pipeline должен запускаться достаточно часто, чтобы ловить правки через консоль до того, как они накопятся. За каждый alert должен отвечать реальный человек, и именно он должен закрывать его. Команда должна протестировать путь очистки в безопасном окружении до того, как production заставит принимать решение.
Мелкие несоответствия могут съесть часы. Если staging-job читает один backend, а production drift-check по ошибке читает другой, pipeline остаётся зелёным, пока реальный production-аккаунт уходит всё дальше в drift. Команда замечает это только тогда, когда следующий apply хочет заменить больше, чем ожидалось.
Правило ответственности важно не меньше, чем код. Если drift-alert пришёл в понедельник, в понедельник же кто-то должен решить, кто и как его исправит. Хорошие команды не оставляют его в чате на неделю в надежде, что он как-нибудь сам разберётся.
Следующие шаги для более чистого Terraform-процесса
Начните с малого. Выберите одно окружение, обычно staging, и сначала запустите drift-check там. Если команда сможет держать одно окружение чистым несколько недель, перенести тот же процесс в production станет намного проще.
Цель проста: ваш код и ваша реальная инфраструктура должны совпадать. Когда этого нет, люди тратят время на догадки, какая версия говорит правду.
Небольшой запуск обычно работает лучше, чем большой пересмотр политики. Сначала запустите drift-проверки Terraform в GitLab CI на одном окружении. Решите, кто исправляет drift и как быстро. Запишите, какие правки через консоль никогда не разрешены. Раз в неделю пересматривайте результаты, пока шум не снизится.
Держите playbook по очистке достаточно коротким, чтобы им можно было пользоваться под давлением. Хорошая версия помещается на одну страницу: подтвердить drift, проверить, была ли живая правка намеренной, либо импортировать её в код, либо удалить, затем перезапустить pipeline. Если playbook длиннее, чем сама правка, люди будут его пропускать.
Старые привычки обычно снова и снова приводят к тому же drift. Кто-то меняет security group в консоли, потому что так быстрее. Кто-то увеличивает размер базы во время инцидента и потом забывает обновить Terraform. Кто-то кликает настройку в панели, потому что pipeline красный и прямо сейчас нужно сделать его зелёным. Прямо называйте эти привычки и заменяйте их правилом, которое команда действительно сможет соблюдать.
Если вашей команде нужна внешняя помощь с настройкой этого процесса, Oleg на oleg.is занимается именно такой работой как внешний CTO на частичной занятости и startup advisor. Он помогает небольшим командам выстроить GitLab CI, Terraform и lean-процессы инфраструктуры без превращения всего этого в ещё один слой администрирования.
Когда этот процесс работает, drift перестаёт быть постоянной загадкой. Он становится маленькой, заметной задачей на очистку, а ваш infrastructure code остаётся заслуживающим доверия.
Часто задаваемые вопросы
Что такое drift в Terraform?
Terraform drift означает, что ваш код .tf, state Terraform и живые облачные ресурсы больше не совпадают. Обычно это начинается, когда кто-то меняет настройку в облачной консоли и потом не обновляет код.
Почему правки через консоль создают проблемы, если production всё ещё работает?
Потому что приложение может продолжать работать, а код при этом рассказывает неверную историю. Следующий terraform plan или apply может неожиданно откатить hotfix, оставить рискованную настройку или скрыть важное изменение в шумном diff.
Что на самом деле делает drift-check в GitLab CI?
Он запускает terraform plan в CI и сравнивает ваш код с реальной инфраструктурой. Сама задача ничего не меняет — она лишь показывает, менял ли кто-то живые ресурсы вне Terraform.
Зачем использовать terraform plan -refresh-only для drift-проверок?
Используйте -refresh-only, когда нужен чистый сигнал о drift. Этот режим показывает разницу между Terraform и реальной инфраструктурой, не смешивая drift с новыми изменениями из ветки.
Что означают коды выхода Terraform в drift-задаче?
0 означает, что Terraform не нашёл изменений. 2 означает, что найден drift. 1 означает сбой задачи, поэтому сначала исправьте pipeline или доступы, а уже потом доверяйте результату.
Как часто нужно запускать drift-проверки?
Для большинства небольших команд достаточно запускать проверку раз в день и на каждый merge request. Если несколько человек всё ещё трогают консоль или у вас часто бывают инциденты, запускайте её чаще.
Drift-проверки должны ломать pipeline или только предупреждать?
В production, общей инфраструктуре, IAM, secrets, публичной сети и всём, что связано с безопасностью или расходами, pipeline должен падать сразу. В короткоживущих dev- или demo-окружениях можно ограничиться предупреждением, если за очистку всё равно кто-то отвечает.
Что делать, если drift-check нашёл изменения?
Сразу решите, было ли живое изменение правильным. Затем либо обновите Terraform, чтобы он совпал с ним, либо откатите правку через консоль, чтобы реальность совпала с кодом.
Как не дать drift-алертам превратиться в шум?
Держите drift-задачу отдельно от apply, используйте тот же backend и те же переменные, что и в обычном процессе, и избегайте широких ignore-правил. У каждого окружения должны быть свои входные данные, а у каждого alert-а — свой владелец, иначе pipeline превратится в фоновый шум.
Как небольшой команде лучше всего запустить это впервые?
Начните с одного окружения, обычно со staging, и запустите там простую проверку по расписанию. Когда команда начнёт быстро закрывать drift и поддерживать это окружение в порядке, переносите тот же процесс в production.


