Проверка затрат на внедрение ИИ: где появляются новые счета
Проверка затрат на внедрение ИИ должна отслеживать повторные запуски, хранение, время проверяющих и работу поддержки, чтобы команды видели, куда на самом деле ушли деньги после запуска.
Содержание
Почему экономия от ИИ сначала может выглядеть неверно
Первые цифры часто рассказывают неправильную историю.
Команда внедряет ИИ, несколько рутинных задач занимают меньше времени, и нагрузка на зарплатный фонд снижается. На первый взгляд это очевидный выигрыш. Но зарплата — это только одна строка в счете.
В большинстве случаев ИИ не убирает расходы. Он их переносит. Вместо того чтобы платить только за часы сотрудников или подрядчиков, вы начинаете платить за вызовы модели, неудачные запуски, хранилище, мониторинг, время на проверку и исправления, когда результат уже почти готов, но еще не подходит.
Именно поэтому первые месяц-два могут выглядеть запутанно. В одном столбце цифры быстро падают. Несколько небольших столбцов растут медленнее. Если никто не объединяет эти новые расходы, экономия выглядит больше, чем есть на самом деле.
Небольшая команда может почувствовать это почти сразу. Допустим, продуктовая команда использует ИИ, чтобы готовить ответы для поддержки, писать тест-кейсы и делать краткие выжимки из отзывов клиентов. В месяц они могут сэкономить 30 часов ручной работы. Но одновременно начинают платить за повторные запуски модели, больший объем логов и файлового хранилища, проверку сотрудниками перед отправкой и дополнительную работу инженеров над редкими случаями.
Ни одна из этих статей сама по себе не выглядит большой. Но вместе они могут съесть значительную часть экономии на труде.
Время тоже мешает это заметить. Изменения в зарплатном фонде видны быстро, если команда сокращает часы подрядчиков или замедляет найм. Новые расходы на ИИ часто появляются позже, когда растет использование. Счета за хранение увеличиваются, потому что команды сохраняют промпты, результаты, скриншоты и журналы аудита. Время на проверку растет, когда тем же workflow начинают пользоваться разные отделы. Небольшие списания тихо складываются в крупную сумму.
Это не значит, что запуск провалился. Обычно это значит, что взгляд на затраты слишком узкий. Деньги не исчезли. Они просто распределились между инструментами, инфраструктурой и проверкой людьми.
Команды, которые замечают это раньше, принимают более удачные решения. Они перестают спрашивать только: «Снизился ли фонд оплаты труда?» — и начинают спрашивать: «Куда ушла работа и что теперь стоит денег, хотя раньше не стоило?» Такой вопрос дает гораздо более ясную картину.
Куда на самом деле уходят деньги
Изменения в зарплатном фонде заметнее всего, поэтому команды в первую очередь смотрят именно на них. Но более полезная проверка начинается с небольших расходов, которые растут на фоне.
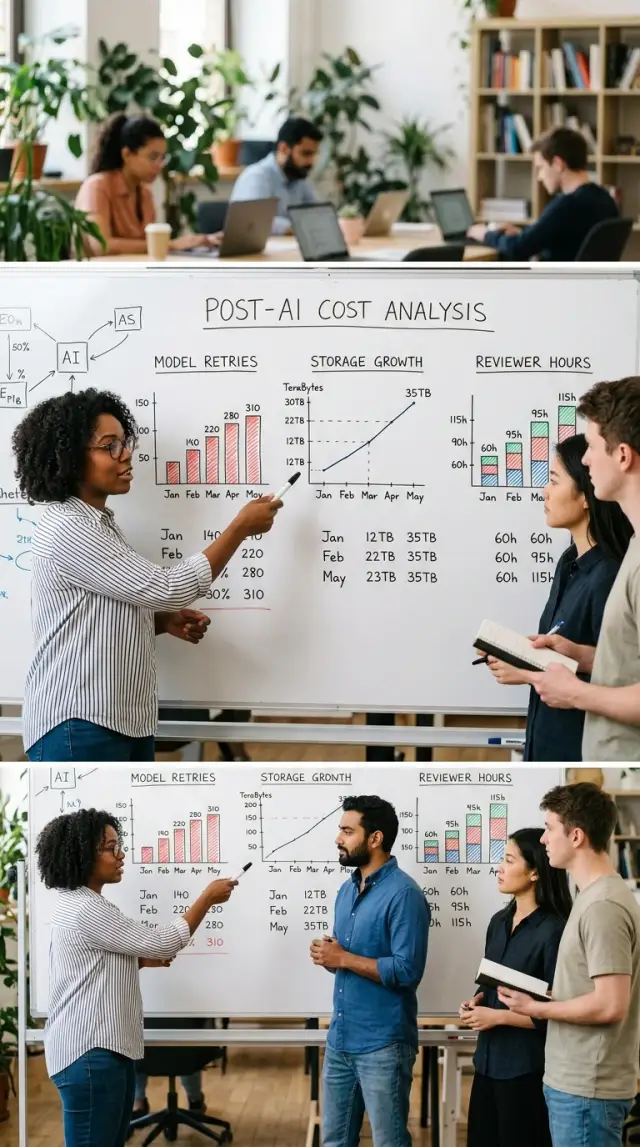
Первое место — вызовы модели. Один запрос может казаться дешевым, но в реальном процессе часто появляются повторные попытки, более длинный контекст, резервные модели и тестовые запуски разработчиков. Один запрос от клиента может привести к пяти или даже десяти вызовам, если первый ответ не прошел правило, превысил лимит времени или потребовал второй проход.
Хранилище тоже растет быстрее, чем многие ожидают. Вы можете сохранять исходные файлы, промпты, результаты, логи, скриншоты, embeddings и резервные копии для каждого запуска. Если команда хранит все ради отладки, аудита или поддержки, хранилище превращается в стабильный ежемесячный счет, а не в разовую статью запуска.
Расходы на людей не исчезают, а меняют форму. Кто-то все еще проверяет странные ответы, исправляет сломанное форматирование, обрабатывает исключения и разбирает тикеты после неудачного результата. Эти часы проверяющих легко не заметить, потому что они размазаны по продукту, поддержке и операциям, а не лежат в одной очевидной бюджетной строке.
Слой поддержки добавляет еще один набор затрат. Когда ИИ касается клиентских процессов, команды часто подключают отслеживание ошибок, дашборды использования, оповещения, фильтры контента и контроль доступа. Все это нужно. Но все это тоже должно попасть в бюджет ИИ-операций.
Представьте стартап, который автоматизирует первые черновики ответов поддержки и экономит 30 часов сотрудников в неделю. Потом он замечает более высокие счета за модель из-за повторных запусков, больший счет за хранение из-за сохраненных переписок и частичного проверяющего, который просматривает рискованные ответы. Команда все равно остается в плюсе, но экономия оказывается совсем не там, где показывала первая таблица.
Составьте простую карту затрат
Большинство команд начинают со счета за ИИ. Но это многое упускает, потому что деньги обычно следуют за workflow, а не за одним инструментом.
Начните с задач, которые ваша команда уже выполняет с помощью ИИ. Пишите просто: черновики ответов поддержки, краткие итоги продажных звонков, поиск по документам, помощь с проверкой кода. Для каждого workflow сделайте отдельную строку. Если смешать все в одном счете от вендора, история быстро потеряется.
Обычной таблицы вполне достаточно. Чаще всего лучше работает одна строка на один workflow, а не одна строка на один сервис.
Для каждого workflow запишите, что его запускает, кто с ним взаимодействует до завершения, какие платные сервисы стоят за ним, как часто он запускается и что считается готовым результатом.
Передачи между участниками важнее, чем кажется. Запишите каждый шаг от начала до конца: человека, который просит результат, приложение, которое отправляет запрос, модель, которая отвечает, слой хранения, а также человека, который проверяет или исправляет результат. Если кто-то тратит хотя бы 10 минут в день на исправление плохих ответов, это тоже должно попасть в карту.
Платные сервисы тоже прячутся в тихих местах. API модели заметен. А вот счет за хранилище, логирование, транскрибацию, очередь, мониторинг и облачные задачи легко пропустить, потому что они приходят отдельными счетами. Но они все равно относятся к одному и тому же workflow.
Вот простой пример. Команда использует ИИ, чтобы кратко пересказывать звонки с клиентами. Один workflow включает хранение записи звонка, speech-to-text, промпт для модели, временное хранилище для сводки и руководителя поддержки, который проверяет итоговую заметку перед отправкой в CRM. Это уже пять затрат для одного workflow. Если разделить их по поставщикам, функция будет выглядеть дешевле, чем есть на самом деле.
Группируйте по workflow, а не по счету
Счета от поставщиков показывают, кто именно выставил вам оплату. Но они не показывают, окупилась ли работа.
Собирайте связанные затраты в одну строку, даже если они приходят из разных систем. Если один workflow использует поставщика модели, облачное хранилище и проверяющего, объедините их. Так вы получите стоимость одного полезного результата — а это уже показатель, с которым можно работать.
Такая карта еще и сильно упрощает последующие проверки. Когда счет резко вырос, можно задать прямой вопрос: какой workflow вырос и почему? Это гораздо полезнее, чем смотреть на более длинный счет от одного поставщика.
Отслеживайте повторные попытки и неудачные запуски
Запуск, который провалился один раз и сработал со второй попытки, все равно стоит как два запуска. Команды часто отчитываются только о завершенных задачах, а потом удивляются, почему счет вырос. Обычно именно количество повторов объясняет разницу быстрее, чем цифры по зарплатам.
Считайте повторные попытки на каждую задачу, а не только общее число API-вызовов. Черновик ответа для поддержки, парсер счетов или бот для проверки кода могут выглядеть дешевыми, если взять один удачный пример. Реальная стоимость становится видна, когда той же задаче нужны три попытки, потому что первый ответ превысил лимит времени, уперся в rate limit или не попал в формат, который ожидало приложение.
Разделяйте повторы пользователя и повторы системы. Повторы пользователя обычно означают, что ответ был слабым, размытым или не по теме. Повторы системы указывают на проблемы приложения: например, на плохие настройки тайм-аута, хрупкий парсинг или очередь, которая снова запускает ту же задачу после неясной ошибки. Если смешать это в одной цифре, вы потеряете причину расходов.
Длинные промпты заслуживают отдельной проверки. Задача, которая повторяется с промптом на 9 000 токенов, сжигает деньги гораздо быстрее, чем короткий запрос. Так часто бывает, когда приложение каждый раз добавляет полную историю чата, старые инструкции или повторяющийся контекст.
Неудачные задания могут запускать работу не только по счету модели. Сбой задачи извлечения может привести к повторному запуску, созданию еще одного файла и ручной доработке результата проверяющим. Один плохой цикл одновременно увеличивает расходы на вычисления, хранение и труд людей.
Простой журнал задач очень помогает. Фиксируйте ID задачи, число попыток, кто инициировал повтор, размер промпта или число токенов и причину сбоя.
Небольшая команда может заметить полезные закономерности уже за месяц. Если 12% запусков повторяются и большая часть относится к одному workflow, сначала исправьте именно его. Часто команды экономят больше, сокращая неудачные запуски, чем подбирая более дешевую модель, потому что перестают платить за работу, которую вообще не нужно повторять.
Следите за ростом хранилища и перемещением данных
Расходы на хранение растут тихо. Workflow с ИИ создают не только финальные ответы. Они также создают исходные загрузки, промежуточные файлы, логи, embeddings, кэшированные результаты, скриншоты, резервные копии и копии, которые перемещаются между инструментами. Именно это часто объясняет, почему счет продолжает расти, даже когда фонд оплаты труда снижается.
Начните с ежемесячного снимка. Сначала посчитайте общий объем исходных файлов, а затем отслеживайте, насколько растет каждая связанная папка после появления нового workflow. Команда может загрузить 50 ГБ исходных файлов за месяц, а потом обнаружить уже 200 ГБ после OCR, разбиения текста на фрагменты, embeddings, логов и бэкапов, которые наслоились сверху.
Полезная проверка хранилища смотрит на пять вещей: исходные файлы и пользовательские загрузки, логи и дампы ошибок, embeddings или векторные индексы, кэши и сгенерированные файлы, а также резервные копии и архивы.
Срок хранения так же важен, как и рост. Многие команды хранят каждый результат навсегда, потому что удаление кажется рискованным. Но это быстро становится дорогим. Если процесс повторяется трижды и сохраняет каждый результат, вы можете платить за хранение неудачного вывода, который больше никогда никто не откроет.
Перемещение данных добавляет еще один счет. Когда один инструмент отправляет файлы другому, вы можете платить за передачу, за API или за то и другое. Дубли тоже накапливаются. Один и тот же набор данных может одновременно лежать в хранилище приложения, очереди обработки, векторной базе, аналитическом экспорте и резервной копии.
Вот распространенный сценарий. Команда поддержки загружает записи звонков, преобразует их в текст, хранит расшифровки для поиска, отправляет фрагменты в embedding store, а затем каждую ночь делает резервную копию всего пайплайна. Исходные 20 ГБ незаметно превращаются в 60 ГБ и больше.
Раз в месяц задавайте несколько вопросов. Какие файлы удаляются автоматически? Какие копии существуют только потому, что два инструмента синхронизируют одни и те же данные? Включают ли бэкапы кэши, которые можно восстановить заново? Переезжают ли задания между регионами или вендорами?
Когда рост хранилища лежит на одной таблице с затратами на модель и труд людей, неожиданности со счетами ловить гораздо легче.
Считайте время проверяющих и ручную доработку
После автоматизации команды часто смотрят только на то, что писать стало быстрее, и пропускают более широкую картину. Если люди тратят время на проверку черновиков, исправление ошибок и обработку странных случаев, которые ИИ не смог решить, это время по-прежнему стоит денег.
Начинайте с минут, а не с впечатлений. Попросите каждого проверяющего фиксировать, сколько времени он тратит на результат, сгенерированный ИИ, от первого прочтения до финального утверждения. Держите все просто. Достаточно общей таблицы с типом задачи, временем проверки, временем на исправления и итоговым статусом.
Небольшие правки тоже важны. Если маркетолог тратит 3 минуты на проверку сводки по продукту, это одно. Если он тратит 12 минут на переписывание половины текста, потому что тон не тот или факты неверны, это уже доработка. Доработка должна входить в итоговую стоимость так же, как и использование модели.
Крайние случаи заслуживают отдельной строки. Команды часто не замечают дополнительное время, которое уходит на нестандартные вопросы клиентов, исправление неаккуратного форматирования или правку текстов, которые на вид нормальные, но упускают важную деталь. Такие случаи бывают редкими, но часы они съедают быстро.
Короткий журнал проверки должен фиксировать минуты проверки на задачу, минуты на исправления или переписывание, отклоненные результаты, крайние случаи, которые обработал человек, и ручное время на ту же задачу, измеренное один-два раза в месяц.
Последнее сравнение очень важно. Нужен чистый взгляд на работу с ИИ и на полностью ручную работу. Если до ИИ задача занимала 18 минут, а теперь — 11 минут вместе с проверкой, вы сэкономили 7 минут. Если теперь она занимает 20 минут, потому что сотрудники постоянно исправляют слабые черновики, вы добавили расходы, даже если объем вырос.
Используйте реальные примеры, а не только средние значения. Стартап может увидеть, что ИИ за секунды пишет первые ответы поддержки, а операционный руководитель при этом все равно тратит 90 минут в день на проверку чувствительных случаев. Это время проверки — часть workflow, а не исключение.
Хорошие данные по проверке также подсказывают, что именно нужно исправить. Возможно, нужен более точный промпт, более жесткий шаблон или правило, которое сразу отправляет некоторые запросы человеку. Когда время на проверку снижается, экономия становится реальной.
Проводите ежемесячную проверку
Ежемесячные проверки лучше работают, когда их объем небольшой. Выберите один workflow, например черновики ответов поддержки или парсинг счетов, и разберите один полный месяц вместо того, чтобы пытаться измерить вообще все сразу.
Узкий срез дает более чистые цифры. Обычно легче заметить лишние расходы, когда сравниваешь один workflow сегодня с тем же процессом до появления ИИ.
Используйте одну таблицу и каждый месяц заполняйте в ней одни и те же категории: зарплатное время всех, кто касается workflow, включая проверку и исправления; счета за инструменты, модели, API и сервисы автоматизации; расходы на хранилище, базы данных и передачу данных, связанные с workflow; затраты на поддержку из-за неудачных запусков или плохих результатов; и старую ручную стоимость рядом с новой.
Лучше всего это работает, когда вы используете реальные данные, а не догадки. Берите счета из финансов, логи использования из ваших ИИ-инструментов и оценки времени у людей, которые реально выполняют работу. Если кто-то потратил 6 часов на исправление неаккуратных результатов, считайте эти 6 часов. Скрытый труд — это все равно труд.
Затем сравните новый workflow со старым ручным процессом простыми словами. Если ручная версия стоила $4 200 в месяц, а ИИ-версия стоит $3 900, сначала это выглядит хорошо. Но если хранилище удвоилось, повторы продолжают расти, а один проверяющий тратит 18 часов в месяц на чистку результатов, экономия очень тонкая и в следующем квартале может исчезнуть.
После этого по каждой статье сделайте четкий вывод. Оставьте то, что экономит время без лишней доработки. Уберите все, что дает небольшое удобство, но стабильно увеличивает расходы. Пересоберите workflow, если один слабый шаг создает повторные вызовы модели, плохие результаты или слишком много проверок.
Хорошая ежемесячная проверка заканчивается двумя-тремя действиями, а не длинным отчетом. Если вы не можете назвать следующий шаг, значит, проверка была слишком общей.
Простой пример небольшой команды
Возьмем команду поддержки из восьми операторов и одного руководителя. Они внедряют ИИ, чтобы писать черновики ответов на частые вопросы вроде возвратов, сброса пароля и статуса заказа. На бумаге первый месяц выглядит отлично. Каждый оператор обрабатывает больше обращений в день, а время ответа сокращается.
Сюрприз появляется на более сложных тикетах. Когда клиент пишет длинную жалобу, смешивает несколько проблем в одном сообщении или просит исключение, первый черновик часто не попадает в суть. Команда запускает промпт снова, правит ввод или переключается на вторую модель. Тикет, который раньше требовал одного прохода человека, теперь съедает три или четыре вызова модели, прежде чем кто-то отправит ответ.
Время руководителя тоже меняется. До ИИ он проверял небольшую выборку ответов. После ИИ он просматривает гораздо больше рискованных случаев: возвраты, рассерженных клиентов и все, где есть юридический или платежный язык. Это легко превращается в 8–10 дополнительных часов в неделю. Зарплатный фонд почти не упал. Он просто переместился.
Хранилище тоже незаметно разрастается. Команда сохраняет промпты, черновики, финальные ответы и полные расшифровки, чтобы потом разбирать ошибки и улучшать промпты. Сначала это кажется дешево. Но через шесть месяцев архив оказывается намного больше, чем ожидалось, особенно если там еще лежат вложения и все версии черновиков.
Ежемесячный срез может показать, что время обработки у операторов стало на 20% быстрее, вызовов модели стало на 35% больше из-за повторов, руководитель тратит на проверку 10 часов в неделю, а объем сохраненных данных по перепискам вырос втрое.
Именно поэтому для реальной проверки затрат недостаточно одной строки с зарплатой. Эта команда действительно сэкономила время, но новые счета пришли в использовании модели, контроле и хранении. Если смотреть только на скорость операторов, можно решить, что внедрение дешевле, чем оно было на самом деле.
Ошибки, которые скрывают реальные расходы
Счет за модель привлекает внимание первым, потому что он новый, его легко выгрузить и легко обвинить. Но чаще всего это только часть общей суммы. Серьезная проверка должна смотреть на работу вокруг модели, а не только на саму модель.
Одна из частых ошибок — считать цену токенов полным бюджетом. Если workflow вызывает модель три раза, дважды повторяет попытку, сохраняет каждый результат, а потом отправляет человека исправлять ответ, плата за модель — это только одна строка в гораздо более длинной цепочке. Дешевые промпты все равно могут создавать дорогие операции.
Время сотрудников часто не замечают по простой причине: зарплата уже есть. Но расходы на зарплату не исчезают только потому, что никто не оформил новый заказ. Если сотрудники поддержки тратят по 30 минут в день на исправление ответов, сгенерированных ИИ, или менеджер продукта проверяет каждый сводный отчет перед отправкой, это время должно попасть в бюджет ИИ.
Менеджеры часто не видят и свою собственную работу. Они утверждают промпты, успокаивают недовольных клиентов, отвечают на необычные вопросы и решают, когда плохой результат нужно переделать вручную. Ничего из этого не видно на панели вендора, но это по-прежнему стоит денег.
Хранилище — еще одна тихая утечка. Команды сохраняют каждый промпт, результат, скриншот, трассировку и debug-лог, потому что так кажется безопаснее. Через несколько месяцев эта привычка может заметно увеличить счета за облачное хранилище, резервные копии и передачу данных. Старые логи еще и замедляют поиск, а уборка становится сложнее.
Несколько ранних сигналов обычно появляются довольно быстро:
- Счет за модель не меняется, а общие операционные расходы продолжают расти.
- Команды поддержки и ops все чаще «просто проверяют» результаты ИИ.
- Объем хранилища растет каждую неделю, хотя поток клиентов остается стабильным.
- Менеджеры тратят на разбор исключений больше времени, чем планировали.
Небольшие команды чувствуют это быстро. Основатель может подумать, что ИИ сэкономил одну оплату подрядчика, а потом потерять ту же сумму на дополнительной проверке, более высоких счетах за хранение и ручной доработке. Если не считать эти часы и системы, экономия на бумаге выглядит лучше, чем в реальной жизни.
Ежемесячный чек-лист, который действительно помогает
Ежемесячная проверка работает лучше всего, когда она скучная и повторяемая. Открывайте один и тот же отчет каждый месяц, сравнивайте его с предыдущим и ищите изменения там, где обычно прячутся новые расходы.
Начните с неудачных запусков. Если число повторов выросло, счет может увеличиться даже при почти неизменном использовании. Изменение промпта, нестабильная интеграция или тайм-аут модели могут превратить одну задачу в три оплачиваемых запуска.
Затем посмотрите на время людей. Часы проверяющих должны снижаться, если workflow действительно работает хорошо. Если они стоят на месте или растут, инструмент, возможно, создает лишнюю доработку вместо экономии времени. Команда, которая тратит на написание на 6 часов меньше, но на проверку результатов на 8 часов больше, не сократила расходы. Она их просто перенесла.
Сохраненные данные заслуживают того же внимания. Workflow с ИИ часто хранят промпты, результаты, логи, файлы, embeddings и резервные копии гораздо дольше, чем это реально нужно. Если хранилище продолжает расти, спросите, что еще действительно полезно, а что можно удалить, сжать или отправить в архив.
Используйте этот короткий чек-лист каждый месяц:
- Сравните число повторов не с общим числом запросов, а с количеством завершенных запусков.
- Проверьте, снизилось ли время на проверку и QA, осталось ли прежним или выросло.
- Посмотрите на файлы, логи и векторные данные и удалите то, что больше не приносит пользы.
- Задайте каждому workflow простой вопрос: он экономит больше денег, чем стоит?
- Отметьте любой workflow, который все еще выглядит запутанным после двух циклов проверки.
Если картина все равно остается неясной, поможет внешний взгляд. Человек, который много лет смотрит на архитектуру программного обеспечения, инфраструктуру и AI operations, часто быстро замечает, куда ушли расходы, а не просто упали ли они. Oleg Sotnikov на oleg.is занимается такой работой со стартапами и небольшими бизнесами, и свежий взгляд нередко помогает найти простые изменения, которые одновременно сокращают повторные запуски, рост хранилища и время на проверку.
Часто задаваемые вопросы
Почему у нас снизился фонд оплаты труда, а общая стоимость ИИ почти не изменилась?
Потому что ИИ часто не убирает расходы, а переносит их. Вы можете сэкономить на рабочих часах, а потом начать больше тратить на вызовы модели, хранение, мониторинг и проверку. Сложите все эти расходы в одну строку по одному workflow, прежде чем оценивать экономию.
Какие скрытые затраты обычно не замечают после внедрения ИИ?
Чаще всего команды сначала пропускают повторные запуски, время на проверку и объем хранимых данных. Эти расходы сначала кажутся небольшими, но растут по мере того, как workflow начинает использовать больше людей.
Как отслеживать затраты на ИИ, если используется несколько инструментов?
Считайте затраты по workflow, а не по счету. Сведите в одну таблицу триггер, все платные сервисы и всех людей, которые касаются результата. Так вы увидите стоимость одного готового результата, а не набор разрозненных списаний.
Нужно ли учитывать неудачные запуски, если задача в итоге сработала?
Да. Если задача дважды провалилась и сработала только с третьей попытки, это три запуска, а не один. Фиксируйте попытки, размер промпта и причину сбоя, чтобы понимать, откуда начинается лишний расход.
Почему хранилище так быстро растет в workflow с ИИ?
ИИ-работа создает не только финальные ответы. Команды хранят загрузки, промпты, результаты, логи, embeddings, кэши и резервные копии, и каждая копия добавляет к счету. Лучше заранее задать правила хранения, чтобы старые debug-данные и неудачные запуски не копились бесконечно.
Как измерять время на проверку и доработку?
Используйте простой журнал с минутами на проверку, минутами на правки и количеством отклоненных результатов для каждого типа задачи. Затем сравните это со старым временем на ручную работу. Если люди тратят почти столько же времени на исправления, сколько раньше на выполнение задачи с нуля, экономия получается очень слабой.
Как часто нужно пересматривать операционные расходы на ИИ?
Проверяйте один workflow в месяц. Каждый раз используйте одни и те же категории: время на работу людей, использование модели, хранение, проблемы поддержки и старую ручную стоимость. Небольшая, повторяемая проверка рано замечает дрейф затрат.
Как понять, что ИИ-workflow себя не окупает?
Следите за ростом повторных запусков, за тем, остаются ли часы проверки на том же уровне, и за хранилищем, которое растет, хотя качество результата не улучшается. Если workflow требует постоянной доработки, он экономит меньше, чем показывает первая панель.
Нужен ли специальный софт для нормальной проверки затрат?
Нет. Для большинства небольших команд достаточно общей таблицы и базовых логов использования. Начните с одной строки на каждый workflow и заполните ее реальными цифрами из счетов, журналов задач и времени сотрудников.
Может ли Oleg помочь проверить наши расходы на ИИ?
Да. Oleg Sotnikov работает со стартапами и небольшими бизнесами над AI operations, архитектурой программного обеспечения и инфраструктурой. Он может посмотреть, куда ушли деньги, найти лишние расходы в повторных запусках и хранении данных, а также предложить более простые и дешевые в работе workflow.


