Проверка данных во время выполнения в TypeScript для более безопасных API-границ
Валидация во время выполнения в TypeScript останавливает плохой API-ввод до того, как он распространится дальше. Узнайте, где лучше использовать Zod или Valibot, что проверять в первую очередь и каких ошибок избегать.
Содержание
Где TypeScript перестает вас защищать
TypeScript помогает вам во время написания кода. Он проверяет формы данных, предупреждает о пропущенных полях и ловит множество ошибок еще до релиза. Но как только приложение запущено, эти проверки больше не защищают входящие данные.
Реальный API-запрос не интересует, что написано в ваших типах. Старое мобильное приложение, сломанная форма, скрипт или сторонний сервис могут отправить null там, где вы ожидали текст. Могут прислать "42" вместо 42 или добавить лишние поля, которые ваш код вообще не планировал обрабатывать.
Браузерные формы создают больше таких проблем, чем команды обычно ожидают. Многие значения приходят строками, даже если на экране они выглядят как числа, даты или булевы значения. Поле цены, ID пользователя или чекбокс часто нужно преобразовать, прежде чем приложение сможет ему доверять.
Именно поэтому валидация во время выполнения в TypeScript так важна. Редактор может считать, что age — это число, а email — обязательное поле. Но в реальном payload все равно могут оказаться "", null, "twelve" или целый вложенный объект там, где должно быть простое значение.
Первая ошибка часто проявляется далеко от самого запроса. Один непроверенный payload может засорить логи странными структурами, протолкнуть неверные значения в биллинг или исказить отчеты на недели. Позже баг кажется случайным, но обычно он начинается на границе, где в систему попали недоверенные данные.
Небольшой пример хорошо это показывает. Форма регистрации отправляет planId: "3" и marketingOptIn: "on". TypeScript не остановит такие значения во время выполнения. Если код примет их без проверки, это несоответствие может попасть в строки базы данных, аналитические события и админские экраны еще до того, как кто-то заметит проблему.
TypeScript по-прежнему очень полезен. Он отлично ловит ошибки разработчика. Просто он не умеет сам проверять живой ввод, а именно на границах API это ограничение проявляется быстрее всего.
Как плохие данные проникают в систему
Большинство сломанных payload-ов приходит не из вашего собственного кода. Они появляются там, где ваши типы не путешествуют вместе с данными: HTTP-запросы, вебхуки, очереди, запланированные задачи и конфигурация из переменных окружения.
Публичный API открыт для кода, который вы не писали. Это может быть мобильное приложение старой версии, скрипт, написанный клиентом, или кто-то, кто вручную тестирует ваш endpoint с JSON. Ваши типы TypeScript не мешают никому отправить age: "unknown", email: null или пропущенный userId.
Сторонние системы добавляют еще один уровень риска. API может переименовать поле, перестать его отправлять или превратить число в строку почти без предупреждения. Вебхуки еще капризнее. Они часто приходят с задержкой, не по порядку или без необязательных свойств. Если ваш код полагается на старую структуру, плохие данные просачиваются внутрь и потом расходятся по логам, очередям и базе данных.
Два источника особенно часто застают команды врасплох:
- Сообщения из очередей и cron-задачи часто несут старые формы payload-ов еще долго после изменений в приложении.
- Переменные окружения всегда приходят строками, даже если вы ожидаете число, булево значение или JSON-объект.
Небольшой пример хорошо это показывает. Допустим, ваш поток регистрации ожидает planId как число, а marketingOptIn как булево значение. Браузер отправляет "2" и "true", позже вебхук не присылает marketingOptIn, а повторная задача воспроизводит payload прошлой недели с plan вместо planId. Каждый ввод выглядит достаточно близко к правильному, чтобы пройти поверхностную проверку. Через несколько часов у вас уже есть пользователи не на том тарифе, и непонятно, почему так вышло.
Вот почему валидация во время выполнения в TypeScript так важна на границе. Считайте любой внешний ввод недоверенным, пока вы не распарсите его и не докажете его форму. После этого остальная часть приложения становится куда предсказуемее.
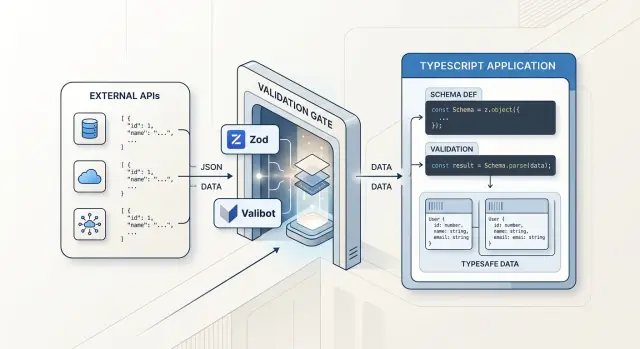
Что делает runtime validation
TypeScript проверяет код, который вы пишете. Он не проверяет JSON, который только что пришел из браузера, вебхука или стороннего API. В этот момент безопасный тип — не UserSignup и не Invoice. Это unknown.
валидация во время выполнения в TypeScript закрывает этот разрыв. Схема описывает, что приложение примет: обязательные поля, допустимые форматы, диапазоны чисел, длину строк, значения enum и вложенные объекты. Затем приложение один раз парсит ввод по этой схеме — прямо на границе, где данные входят в систему.
Если парсинг не удается, запрос останавливается здесь же. Вы возвращаете понятную ошибку, логируете, что пошло не так, и не пускаете плохой ввод дальше по коду. Бизнес-логика никогда не должна разбираться с email: 42, пустым паролем или неожиданными полями, которых вообще быть не должно.
Если парсинг успешен, результат лучше, чем просто «скорее всего правильно». У вас появляются чистые, типизированные данные, которым может доверять остальная часть приложения. Это важно, потому что так исчезает необходимость дублировать защитные проверки в каждом сервисе и обработчике. Вместо бесконечных typeof, проверок на null и запасных веток по всему проекту вы один раз делаете жесткую проверку.
Простой пример — запрос на регистрацию. API получает тело запроса от клиента. Схема проверяет, что email — строка в правильном формате, name присутствует, а age — число, если поле есть. Она также может отклонить или убрать поля вроде isAdmin, которыми клиент никогда не должен управлять. После этого код создания пользователя получает только те поля, которые ожидает.
Именно здесь и нужны инструменты вроде Zod или Valibot. Они не заменяют TypeScript. Они защищают то место, где TypeScript еще не видит реальные данные, а затем возвращают безопасную структуру остальной части приложения.
Где место Zod или Valibot
TypeScript останавливается на сетевой границе. Когда данные приходят из браузера, другого сервиса, вебхука или очереди, ваши типы не проверяют реальный payload. Нужна валидация во время выполнения в TypeScript в тот момент, когда неизвестные данные входят в приложение.
Размещайте Zod API validation или схемы Valibot в самом первом обработчике, который получает ввод. Парсите данные до того, как вызовете бизнес-логику, коснетесь базы данных или отправите событие. Если в запросе есть JSON-тело, route param и query params, проверяйте все три. Команды часто валидируют body и забывают про id, page или sort, а они ломаются не менее легко.
Хорошее правило простое: сырой ввод остается на границе. Распарсенные данные идут внутрь.
Это относится не только к пользовательским запросам. Сторонние API могут прислать пропущенные поля, неправильные типы или неожиданные изменения структуры. Если сервис для биллинга возвращает объект тарифа, проверьте этот ответ, прежде чем приложение обновит доступ, сохранит его или покажет пользователю. Не позволяйте «доверенным» внешним данным обходить те же проверки.
Вебхуки требуют того же подхода. Парсите payload сразу после получения, а потом решайте — принять его, отклонить или отложить на проверку. Если worker сначала сохраняет или пересылает сырой webhook data, одно плохое событие может распространиться в базу данных, аналитику и последующие задачи.
Обычно схемы нужны здесь:
- HTTP-обработчики для тел запросов
- Route params и query params
- Обертки для сторонних клиентов
- Приемники вебхуков
- Потребители внешних сообщений или задач
Держите валидацию как можно ближе к каждой точке входа, а не стройте один общий парсер где-то далеко от источника. Так легче отследить ошибки. Обработчик регистрации должен отвечать за парсинг регистрации. Вебхук биллинга должен отвечать за парсинг событий биллинга.
Такой подход держит плохие данные маленькими и локальными. Один запрос падает сразу и с понятной ошибкой, вместо того чтобы потом заставлять вас разгребать полусломанные записи.
Как добавить валидацию на API-границе
Команды часто сначала делают одну и ту же ошибку: размещают схемы глубоко внутри приложения, уже после того, как плохой ввод успел затронуть бизнес-логику. Лучше сразу проверять у двери. Если сырые данные приходят извне вашего кода, валидируйте их до того, как что-то еще их прочитает.
Начните со списка всех мест, где внешние данные входят в систему. Обычно их больше, чем просто публичные API-роуты.
- JSON-запросы от web или mobile-клиентов
- Вебхуки от платежных, авторизационных или почтовых провайдеров
- Админские формы и внутренние инструменты
- CSV-импорты, очереди сообщений и запланированные задачи
После этого выберите одну точку входа. Возьмите endpoint, который ломается чаще всего, создает больше всего обращений в поддержку или отправляет грязные записи в базу данных. Небольшая победа на одном шумном маршруте лучше, чем большой план, который так и не доходит до релиза.
Используйте Zod или Valibot, чтобы описать payload, который вам нужен сегодня, а не идеальный payload, который вам хотелось бы иметь потом. Сделайте первую схему узкой и честной. Если поле сейчас необязательное, отметьте его как optional. Если число приходит строкой и вы действительно принимаете это, так и скажите в схеме, а не притворяйтесь, что ввод чище, чем есть на самом деле.
Затем парсите сырой ввод до того, как вызовете сервисы, вспомогательные функции или базу данных. На практике валидация во время выполнения в TypeScript должна происходить в самом начале обработчика, сразу после чтения тела запроса. Если парсинг не удался, остановитесь здесь.
Простой поток выглядит так:
- Прочитать сырое тело запроса.
- Распарсить его одной схемой.
- Вернуть понятную ошибку 400, если парсинг не удался.
- Передавать только распарсенные данные остальной части приложения.
Сообщения об ошибках делайте простыми. Подскажите клиенту, какие поля не так и почему, но не выкладывайте stack trace или секретные значения. В логах оставляйте достаточно деталей для безопасной отладки: request id, route, имена полей и ошибку валидации. Не логируйте пароли, токены и полные персональные данные.
Этот подход скучный специально. Именно поэтому он работает. Одна проверенная граница может остановить длинную цепочку плохих данных, странных багов и поздней очистки базы.
Простой пример с запросом на регистрацию
Эндпоинт регистрации кажется безобидным, пока браузер не отправит значение, которого код не ожидал. Частый случай — age: "27". Форма отправила строку, а ваш тип TypeScript по-прежнему говорит, что age — число.
Этот разрыв важен, потому что TypeScript проверяет ваш код, а не сырой запрос из сети. Если кто-то пишет const input: SignupInput = req.body, редактор ничего не скажет. А сервис дальше ведет себя так, будто age уже чистое число.
type SignupInput = {
name: string;
email: string;
age: number;
};
const body = {
name: "Maya",
email: "[email protected]",
age: "27",
};
const result = SignupSchema.safeParse(body);
if (!result.success) {
return { status: 400, errors: result.error.flatten() };
}
createUser(result.data);
В Zod схема SignupSchema может отклонить запрос, если age на границе API должен быть настоящим числом. Она также может намеренно преобразовать значение, если это соответствует вашим правилам. Например, можно принять значение из формы как текст, привести его к числу, а потом проверить, что это целое число и что пользователь достаточно взрослый для регистрации.
Valibot делает ту же работу, но немного в другом стиле. Дело не в названии библиотеки. Дело в том, что именно схема решает, что попадает в приложение.
После парсинга слой сервиса получает чистые поля: name, email и age в ожидаемой форме. Вот где валидация во время выполнения в TypeScript действительно оправдывает себя. Странный ввод останавливается на границе.
Без этого шага плохие данные продолжают двигаться дальше. Аналитика может считать "27" и 27 разными значениями. Правила биллинга или ценообразования могут сравнивать строки вместо чисел. Маленькая ошибка формы превращается в баг в трех местах.
Схема на границе запроса обходится дешевле. Одна проверка, одно понятное правило, и остальной код может оставаться простым.
Как выбрать между Zod и Valibot
Большинство команд спокойно работают с любой из этих библиотек. Лучший выбор зависит от того, что болезненнее: более долгое знакомство или больший размер бандла.
Zod обычно проще выбрать, когда команде важно быстро двигаться. У него больше примеров, больше туториалов и стиль, который многим TypeScript-разработчикам уже знаком. Если новый сотрудник придет на следующей неделе, он, скорее всего, быстро прочитает схему Zod и начнет работать почти без настройки.
Valibot больше подходит, когда важен вес в браузере. Если вы валидируете много форм на клиенте, меньший размер бандла помогает страницам загружаться быстрее и делает интерфейс отзывчивее на слабых устройствах. На сервере разница может быть не так заметна, но в пользовательском приложении она имеет значение.
Хорошо работает простое правило:
- Выбирайте Zod, если важнее скорость команды и простое подключение.
- Выбирайте Valibot, если размер клиентского бандла действительно важен.
- Используйте одну библиотеку по всему проекту, если нет серьезной причины разделять их.
Последний пункт экономит больше нервов, чем кажется. Когда одна команда использует Zod в API, а другая Valibot во frontend, начинают расползаться мелкие различия в правилах парсинга. Поле, которое обрезает пробелы в одном месте, может упасть в другом. Именно так валидация во время выполнения в TypeScript начинает мешать, а не помогать.
Делить одну и ту же схему между сервером и клиентом может быть разумно, но только когда обе стороны действительно нуждаются в одних и тех же правилах. Хороший пример — форма регистрации. Можно разделить проверки формата email, длины пароля и обязательных полей. Но серверные проверки должны оставаться на сервере. Поиск в базе, правила антифрода, лимиты запросов и проверки прав доступа не должны попадать в общий клиентский пакет.
Если команда все еще сомневается, выберите инструмент, которым люди действительно будут пользоваться каждый день без раздражения. Немного больший бандл часто вполне оправдан, если он дает меньше ошибок и быстрее проходят ревью. С другой стороны, если вы делаете frontend-heavy продукт и считаете каждый килобайт, Valibot — разумный выбор.
Ошибки, из-за которых плохие данные распространяются
Многие команды валидируют все в UI, а затем доверяют всему, что доходит до сервера. Это работает ровно до тех пор, пока кто-то не обойдет форму, не отправит запрос напрямую или старый клиент продолжит слать неправильную структуру. TypeScript не может защитить эту границу сам по себе, потому что сеть передает обычный ввод, а не доверенные типы.
Query params часто игнорируют, потому что они кажутся мелочью. Но это все равно ввод. Значения вроде ?page=abc, ?limit=-1 или ?sort=[object Object] могут попасть в запросы к базе данных, логи, правила кеширования или аналитику. Маленькие поля вызывают очень реальные баги.
Еще одна частая ошибка — преобразовывать данные до валидации. Команды сначала обрезают пробелы, приводят типы, переименовывают или объединяют поля, а уже потом валидируют очищенный результат. Так исходная проблема скрывается. Если age пришло как "twelve", а код превратил это в NaN до запуска схемы, вы потеряли самый понятный текст ошибки и усложнили отладку.
Неизвестные поля тоже наносят тихий урон. Запрос может включать лишние свойства, которых никто не просил, например role, debug или старый флаг клиента. Если парсер их принимает, этот мусор может попасть в хранилище, payload-ы событий или внутренние вызовы функций. Потом кто-то видит поле и думает, что оно поддерживается.
Эти ошибки встречаются очень часто:
- проверка только браузерной формы
- пропуск headers и query params
- приведение типов до проверки
- разрешение лишних полей по умолчанию
- одна огромная схема, которую никто не хочет трогать
Последний пункт опаснее, чем кажется. Команды начинают с огромной схемы, призванной покрыть все варианты запросов. После нескольких изменений люди перестают ее обновлять, потому что это кажется рискованным и медленным. Тогда схема превращается в декорацию. Она есть, но уже не соответствует тому, что реально принимает код.
Лучше выработать скучную и строгую привычку. Проверяйте сырой ввод на каждой API-границе. Держите схемы маленькими и рядом с роутом или обработчиком, который их использует. Отклоняйте неизвестные поля, если у вас нет четкой причины этого не делать. На практике валидация во время выполнения в TypeScript работает лучше всего тогда, когда она ловит плохой ввод рано, до того как парсинг, маппинг и сохранение сделают источник ошибки труднонаходимым.
Быстрая проверка перед релизом
Большинство багов из-за плохого ввода сначала кажутся мелкими. Пропущенное поле, лишнее свойство, число, отправленное строкой. Потом payload проходит через API-границу, доходит до бизнес-логики и превращается в гораздо более сложную проблему для поиска.
Короткая предпубликационная проверка ловит многое из этого. Она также показывает, действительно ли ваша валидация во время выполнения в TypeScript защищает те места, которые TypeScript сам не видит.
Проверьте этим списком каждый request handler, webhook, consumer очереди и callback от стороннего сервиса:
- Парсите каждый внешний payload сначала как
unknown. Не доверяйте телу запроса, query params, headers или данным партнера только потому, что редактор показывает тип. - Решите, что делать с полями, которые вы не поддерживаете. Отклоняйте их, когда важен строгий ввод, или удаляйте, если лишние данные безвредны.
- Возвращайте сообщения об ошибках, которые помогают отправителю исправить запрос. Скажите, какое поле не прошло проверку и почему, но не показывайте stack trace или внутренние детали схемы.
- Специально тестируйте сломанные payload-ы. Отправляйте пустые тела, неверные типы, лишние поля, битый JSON и значения, которые почти похожи на правильные.
- Логируйте ошибки валидации так, чтобы команда могла ими пользоваться. Сохраняйте route, request ID и путь к полю, но никогда не логируйте пароли, токены или полные персональные записи.
Один из моментов, который команды часто пропускают, — это единообразие. Если один endpoint удаляет неизвестные поля, а другой отклоняет их, клиенты быстро путаются. Для каждого класса endpoint-ов выберите правило и придерживайтесь его.
На сообщения об ошибках тоже стоит взглянуть еще раз. «Invalid input» слишком расплывчато. «email must be a valid email address» дает отправителю то, что он может исправить с первой попытки.
Если команда выпускает код быстро или использует AI-assisted code, эти проверки становятся еще важнее. Быстрая генерация кода может создать правильные типы, но все равно пропустить некрасивый реальный ввод.
Перед релизом сделайте последний ручной тест с плохим payload. Если схема его ловит, API возвращает чистую ошибку, тест покрывает случай, а лог остается полезным и не раскрывает приватные данные, значит все в хорошем состоянии.
Что делать дальше
Большинству команд не нужен большой рефакторинг. Им нужна карта. Соберите на одной странице все места, где внешние данные входят в систему: публичные API-роуты, вебхуки, админские формы, CSV-импорты, consumer-ы очередей и задачи, которые ходят в другие сервисы. Затем отметьте те несколько границ, которые создают больше всего обращений в поддержку или самых неприятных багов.
Начните с одной из них, а не со всех сразу. Запрос на регистрацию — хороший первый выбор, если плохой ввод создает дубликаты аккаунтов, сломанные письма или грязные записи пользователей. Если партнерский API постоянно меняет типы полей, начните с него. Лучшая первая схема — та, которая связана с реальной и раздражающей проблемой.
Если вы уже используете схемы Zod или Valibot, перенесите их как можно ближе к границе. Парсите payload до того, как с ним начнет работать логика приложения. Вот где валидация во время выполнения в TypeScript действительно окупается. Она останавливает плохие данные у двери вместо того, чтобы заставлять остальной код гадать.
Простой план внедрения выглядит так:
- выберите один рискованный endpoint или webhook
- добавьте схему рядом с обработчиком
- сразу отклоняйте или очищайте payload
- логируйте причину, если парсинг не удался
- через несколько дней проверьте эти ошибки
Эти логи расскажут больше, чем догадки команды. Паттерны проявятся быстро. Возможно, пользователи постоянно присылают пустые имена, старый клиент все еще отправляет строки вместо чисел, или одно поле чаще, чем ожидалось, приходит как null. Если один и тот же payload продолжает падать, ужесточите схему, улучшите сообщение об ошибке или осознанно поддержите старый формат.
Сделайте это один раз, а потом повторите на следующей рискованной границе. Маленькие шаги работают лучше, чем широкий план очистки, который никто не заканчивает.
Если данные проходят через несколько сервисов, а границы размыты, может помочь внешний аудит. Oleg Sotnikov делает такую работу как Fractional CTO и startup advisor, помогая командам правильно расставлять валидацию, снижать нагрузку на поддержку и не давать плохим данным расползаться по стеку.
Практическая цель на эту неделю: выпустить одну схему, собрать отклоненные payload-ы и использовать их, чтобы решить, какой должна быть вторая схема.


