Операционная простота для стартапов: выбирайте ставки, которые окупаются
Операционная простота помогает маленьким командам выпускать фичи быстрее, исправлять баги и избегать архитектурных решений, которые добавляют работы до появления реальной проблемы.
Содержание
Почему маленьким командам сложно справляться с ранней сложностью
В небольшой команде стартапа редко есть фиксированные роли. Тот же человек утром пишет код, после обеда проверяет продакшен, отвечает клиентам и перед сном чинит биллинг. Каждый лишний слой в стеке обходится дороже, чем на аккуратной архитектурной диаграмме.
Сложные системы требуют регулярного ухода. Вторая база данных, очередь, кастомный админ-инструмент или отдельный аналитический пайплайн каждый по отдельности могут звучать разумно. Собранные вместе они создают работу, которая никогда не заканчивается: дополнительные шаги деплоя, больше логов для поиска, больше алертов, секретов, бэкапов и обновлений.
Именно тогда ранние архитектурные решения начинают вредить. Стоимость — не в первоначальной настройке, а проявляется через несколько недель, когда мелкая ошибка проходит через три сервиса, и никто не помнит, что изменилось первым.
Кастомные инструменты дают ту же проблему. Команды строят внутренние дашборды, самописные раннеры задач или скрипты синхронизации, чтобы сэкономить время. Иногда это работает. Часто это превращается в приватный продукт внутри компании, и кто‑то должен им владеть вечно. Если этот человек ещё и делает бэкенд, операции и поддержку, инструмент становится налогом.
Отладка в нагруженном стеке быстро ухудшается. Простая ошибка может скрываться за повторными попытками, очередями, вебхуками, кэшем и фоновыми задачами. То, что могло бы занять 15 минут, превращается в полдня охоты по логам. Маленькие команды чувствуют это сильнее, потому что у них меньше непрерывного времени и меньше лишних рук.
Выживающие бережливые команды обычно снова и снова принимают один и тот же скучный выбор: держать число движущихся частей низким, пока реальный трафик или реальная боль не заставят изменить. Так выглядит операционная простота для стартапов на практике. Она защищает время, фокус и сон.
Как выглядит «достаточно просто»
Операционная простота обычно означает выбор настройки, которая решает сегодняшние задачи с наименьшим числом движущихся частей. Если четыре человека могут понять её, запустить и починить в 2 утра — скорее всего, это достаточно просто.
Для многих ранних продуктов одной кодовой базы достаточно. Один репозиторий делает изменения видимыми, упрощает тестирование и снижает вероятность того, что одна маленькая фича превратится в работу по трём сервисам. Команды разделяются слишком рано, потому что микросервисы выглядят аккуратно на бумаге. На практике одно приложение с понятными модулями обычно быстрее в разработке и намного проще в отладке.
То же самое касается данных. Одна база данных покрывает больше, чем нужно большинству новых приложений. PostgreSQL сам по себе может обслуживать пользовательские данные, фоновые задачи, таблицы отчётов и даже простой очередь довольно долго. Redis, Elasticsearch и вторая база могут подождать, пока в приложении не появится реальное узкое место, а не воображаемое.
Инфраструктуру тоже часто пересобирают слишком рано. Один облачный регион достаточен для многих новых приложений, особенно когда первая цель — стабильный продукт и низкий счёт. Мульти-регионные настройки звучат безопасно, но усложняют деплои и отладку и добавляют возможности для рассинхронизации данных. Если большинство пользователей в одном рынке, держите приложение близко к ним и сделайте бэкапы скучными и надёжными.
Деплои должны оставаться простыми. Каждый в команде должен знать, как код попадает из ветки в прод, какие проверки запускаются первыми и как откатиться. Прямой путь деплоя с коротким чеклистом лучше хитрой конвейерной схемы, которую понимает только один человек. Если релиз требует отдельной встречи — процесс уже слишком тяжёлый.
Обычно простая настройка имеет четыре признака:
- Одно основное приложение, которое вся команда может запустить локально
- Одна база данных, где хранится почти всё
- Один регион с бэкапами и базовым мониторингом
- Один процесс деплоя, которому может следовать любой инженер
Проверьте это одним вопросом: если один инженер уходит на неделю, сможет ли команда продолжать доставлять без страха? Если да — настройка, вероятно, достаточно проста. Если же отсутствие одного человека превращает деплои, изменения данных или инфраструктуру в догадки — система несёт лишний вес.
Дизайнерские ставки, которые окупаются сейчас
Большинству стартапов не нужно больше серверов. Им нужно меньше сюрпризов.
Лучшие ранние архитектурные ставки уменьшают ежедневное трение. Они помогают маленькой команде доставлять фичи, быстро исправлять баги и спать ночью.
Начните с чётких границ внутри одного приложения. Держите биллинг, аутентификацию, уведомления и админ‑код разделёнными логически, даже если они живут в одной кодовой базе. Так вы получите чистую ответственность и меньше случайных побочных эффектов без накладных расходов на несколько сервисов.
Затем инвестируйте в скучные вещи. Хорошие логи, протестированные бэкапы и надёжный трекер ошибок чаще перевешивают модные планы масштабирования. Если платёжная задача падает в 2 часа ночи, нужно знать, что произошло, кого это коснулось и как восстановить ситуацию. Базовая настройка трекинга ошибок, такая как Sentry, читаемые логи и отработка восстановления из бэкапа принесут больше доступности, чем сложный распределённый дизайн, который никто полностью не понимает.
Очереди тоже имеют смысл рано, но только для медленных задач. Используйте их для писем, конвертации файлов, генерации отчётов или повторных попыток вебхуков. Не пропускайте через фоновые воркеры каждый запрос только потому, что это кажется продвинутей. Если задача быстрая и видна пользователю — держите её в приложении.
Автоматизированные проверки тоже могут быть небольшими. Не нужен гигантский конвейер. Начните с нескольких проверок, которые ловят очевидные поломки:
- Запуск тестов
- Проверка форматирования и линтеров
- Однократная сборка приложения
- Блокировка слияний при провале этих проверок
Этот маленький барьер экономит реальное время. Он ловит сломанный код до того, как он попадёт в прод, и сокращает петлю «у меня работает», которая замедляет маленькие команды.
Если вы выбираете между второй кластеризированной базой данных и отработкой восстановления из бэкапа — сделайте упражнение по восстановлению. Если между микросервисами и улучшенными алертами — выберите алерты. Ранние архитектурные решения должны в первую очередь уменьшать затраты на поддержку. Проблемы масштаба могут подождать, пока станут реальными.
Ставки, которые добавляют работу слишком рано
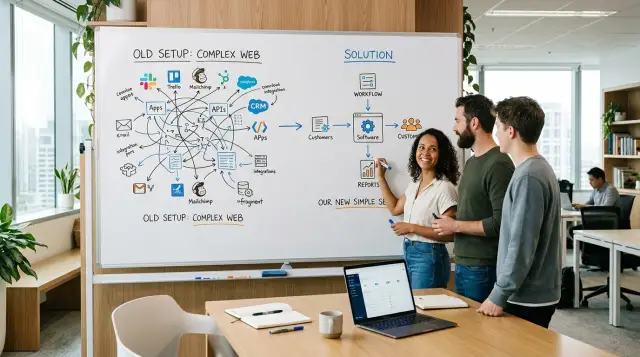
Много ранней архитектурной работы кажется умной, потому что она похожа на то, как строят большие компании. Для маленькой команды многие такие ставки превращаются в рутину ещё до того, как решат реальную проблему.
Микросервисы — классический пример. Если одна команда всё ещё понимает продукт целиком, разделение на сервисы часто добавляет правила деплоя, API‑контракты, трассировку запросов и конфликты версий. Этот обмен имеет смысл позже, когда владение становится разрозненным или какая‑то часть требует совсем иного графика релизов. До этого это в основном добавляет репозиториев, логов и алертов, локальной настройки и ещё больше соединительной логики между простыми пользовательскими действиями.
Мульти‑региональные настройки пахнут так же, когда ни один клиент не почувствовал разницы. Если пользователи довольны временем отклика и у вас нет жёстких обещаний по аптайму, один стабильный регион с бэкапами, мониторингом и планом восстановления часто достаточно. Несколько регионов кажутся безопасными, но они усложняют синхронизацию данных, деплои и дают больше возможностей для рассогласования окружений.
Шины событий тоже приходят слишком рано. Если пользователь кликает кнопку и приложению нужно просто сохранить данные, обновить одну запись и вернуть ответ, обычный поток запроса легче понять и отладить. Шина начинает окупаться, когда работа действительно выполняется в фоне или когда несколько независимых частей нуждаются в одном и том же событии. До этого вы платите за повторные попытки, дублирование обработки, очереди «мертвых» сообщений и проблемы с порядком сообщений без ощутимого выигрыша.
Кастомные внутренние платформы могут потратить месяцы так же. Команды строят свои инструменты деплоя, слой аутентификации, админ‑панели или внутренние фреймворки, потому что это кажется инвестицией. Часто управляемый инструмент уже хорошо решает скучную часть, и это важнее оригинальности на этом этапе.
Это частая уборка в консультировании стартапов: убрать слои, которые казались умными на потом, но в основном повышали стоимость поддержки сейчас. Если выбор не экономит время в этом месяце, не уменьшает боль пользователей или не помогает доставлять безопаснее — отложите его.
Как выбрать следующий архитектурный шаг
Следующий шаг должен решать боль, которую вы можете назвать, а не страх перед будущим масштабом. Если никто в команде не может указать на проблему за последние 30 дней, скорее всего, вам не нужна архитектурная смена.
Запишите боль в одном простом предложении. «Деплои падают два раза в неделю» — полезно. «Нам нужно быть более масштабируемыми» — нет.
Потом измерьте стоимость, прежде чем трогать систему. Посчитайте потерянные часы, расходы в облаке, тикеты поддержки или пропущенные релизы. Маленькие команды часто обнаруживают, что реальная проблема — скучная. Одна медленная задача тестов может тратить больше времени, чем дизайн базы данных. Один шумный алерт сжигает больше внимания, чем отсутствующая очередь.
Выберите наименьшее изменение, которое убирает большую часть боли. Если одна фоновая задача блокирует веб-запросы, вынесите только эту задачу в очередь сначала. Если отчёты замедляют основную базу, попробуйте лучшие запросы, кэширование или плановые экспорты, прежде чем добавлять ещё одну базу.
Обратимость важнее идеальности. Предпочитайте изменения, которые можно отменить за несколько недель без переписывания. Флаг фичи, один вынесенный воркер или управляемый сервис с понятным экспортом обычно безопаснее глубокой переработки. Маленькие команды учатся быстрее, когда оставляют себе выход.
Назначьте дату ревью до начала. Две‑четыре недели часто достаточно. Проверьте те же метрики снова. Уменьшилось ли время деплоя? Упали ли инциденты? Остался ли счёт примерно тем же? Если боль ушла — остановитесь. Если боль только сместилась — сделайте ещё одно небольшое изменение.
У команды из четырёх человек не должно быть много правил, но должно быть одно: исправляй узкое место этого месяца самой дешёвой обратимой мерой.
Простой пример от команды из четырёх человек
Команде SaaS из четырёх человек не нужен модный диаграммник. Нужен работающий продукт, процесс деплоя, которому люди доверяют, и настройка, которую можно починить, не потеряв выходные.
Команда начинает с одного приложения, одной базы PostgreSQL и одного репозитория. Приложение обрабатывает запросы, хранит данные и выполняет простую фоновую работу в одной системе. Локальная настройка остаётся простой. Продакшен остаётся скучным. Это хорошо.
Через несколько месяцев клиенты начинают просить большие отчёты. Один отчёт занимает 30–60 секунд и блокирует приложение. Сначала проблему видит поддержка, потому что пользователи думают, что продукт завис.
Теперь боль конкретна, и команда делает одно фокусированное изменение. Они добавляют очередь задач для генерации отчётов. Приложение сохраняет задачу, воркер подхватывает её, и пользователь получает результат, когда он готов. Запросы остаются быстрыми. Отчёты работают. Команда решает одну реальную проблему, не перестраивая всё.
Команда также оставляет один стейджинг вместо трёх сред для непродакшена. Для четырёх человек дополнительные окружения кажутся аккуратными, но часто создают рассогласование. Кто‑то забывает изменить конфиг, скрипт посева устаревает или тест проходит в одном месте и падает в другом. Один staging ловит большинство проблем релиза и сокращает много еженедельной уборки.
Команда сопротивляется ещё одному частому желанию. Биллинг, аутентификация, отчёты и админ‑инструменты остаются в одном сервисе довольно долго. Разделение само по себе не плохо, просто каждое дополнительное подразделение добавляет деплой, ещё одну трассу логов, ещё один алерт и ещё одну вещь для отладки ночью.
Только позже одна область отделяется. Отчёты меняются почти каждый день, в то время как остальная часть приложения остаётся стабильной. Тогда выделение отчётов в отдельный сервис окупается: цикл релизов упрощается, а остальная часть продукта остаётся тихой.
Добавляйте части, когда боль реальна и повторяема, а не когда архитектурная картинка выглядит чище.
Ошибки, которые создают поддержку без выгоды
Много стартап‑боли происходит из работы, которая красиво смотрится на диаграмме, но через полгода вызывает отвращение. Обычная ошибка — копирование решений компаний с 50 инженерами, платформенной командой и круглосуточной поддержкой.
Маленькая команда не получает дополнительных очков за то, что запускает тот же стек, что и известная технологическая компания. Она просто получает больше дашбордов, больше сервисов для патчинга и больше мест, где прячутся тихие баги.
Одна распространённая ошибка — готовиться к трафику, которого нет. Команды добавляют очереди сообщений, отдельные базы, дополнительные регионы, сложные слои кэширования и внутреннюю аутентификацию между сервисами, ещё не зная настоящего узкого места. Если 95% запросов работают нормально на одном приложении и одной базе, модная настройка в основном приносит алерты и работу на выходных.
Ещё одна ошибка — добавлять инструменты из‑за того, что категория звучит полезно. Команда ставит фичер‑флаги, движки рабочих процессов, шины событий, несколько продуктов мониторинга и три набора проверок сборки для одного и того же. Потом нет владельца. Когда инструмент никому не принадлежит, он быстро превращается в беспорядок. Обновления пропускаются. Правила устаревают. Ложные сигналы накапливаются.
Рерайты дают ту же трату. Команды говорят, что кодовая база не масштабируется, когда на самом деле одна страница медленная или одна задача падает под нагрузкой. Пара измерений обычно отвечает на вопрос быстрее, чем переписывание.
Следите за этими признаками:
- Время на настройку растёт, а проблемы клиентов не уменьшаются
- Только один человек понимает деплой
- Новые инструменты создают рутину, которую никто не просил
- Опасения производительности основаны на догадках, а не на цифрах
Сначала купите уверенность. Измерьте медленный эндпоинт. Почините шумную задачу. Уберите лишний сервис, который ничего не решает. Такая работа окупается сейчас и оставляет систему понятной даже в утомлённый вторник вечером.
Быстрые проверки перед добавлением сложности
Маленькая команда платит за каждую дополнительную движущуюся часть дважды: сначала при её создании, потом когда нужно присматривать за ней в 2 часа ночи. Поэтому простая архитектура обычно выигрывает у хитрой на ранних стадиях.
Прежде чем добавить новый сервис, очередь, слой деплоя или AI‑воркфлоу, задайте четыре простых вопроса:
- Появляется ли эта проблема почти каждую неделю, или вы решаете воображаемую будущую проблему?
- Если кто‑то один отсутствует, смогут ли двое запустить это, отладить и восстановить?
- Уберёт ли это изменение реальную работу, боль поддержки или простои в ближайшие 90 дней?
- Если оно упадёт, можно ли его выключить и вернуться к старой схеме без долгого инцидента?
Если на два вопроса ответ «нет», обычно умнее подождать.
Эта проверка кажется чрезмерно простой, но она ловит много плохих ставок. Команды добавляют контейнеры, брокеры, микросервисы или дополнительные окружения, потому что эти инструменты выглядят серьёзно. Потом один инженер уходит, другой в отпуске, и никто не помнит, какой секрет, задача или правило повторных попыток сломало релиз.
Конкретный пример упрощает оценку. Допустим, у команды одно приложение, одна база и стабильный трафик. Сборки занимают восемь минут. Релизы два раза в неделю. Поддержка управляемая. Разделение приложения на четыре сервиса сегодня не решит реальную боль. Быстрые автоматизированные проверки, лучшие логи и чистый путь отката скорее решат проблему.
Хорошая сложность имеет чек. Вы должны быть в состоянии показать сэкономленные часы, предотвращённые инциденты или предел, который вы уже достигли. Если вы не можете назвать счёт, который это снизит в этом квартале, не добавляйте.
Когда рост всё же заставляет менять архитектуру
Рост обычно ломает те части, которые вы игнорировали, потому что они работали при низком трафике. Это не значит, что нужно перестраивать всё. Добавьте один слой, измерьте его под реальной нагрузкой и держите остальную систему скучной, пока не получите доказательств, что нужно больше.
Обычная ошибка — перепрыгнуть с одного приложения и одной базы сразу на очереди, разделение сервисов, второй регион и новую систему мониторинга в тот же месяц. Маленькие команды платят за это сном, а не только счётом. Каждая новая часть добавляет алерты, режимы отказа и ещё одну вещь, которую кто‑то должен понимать в 2 утра.
Запишите триггерные точки до изменения дизайна. Сделайте их достаточно конкретными, чтобы команда могла действовать без споров:
- Выделяйте сервис только тогда, когда какая‑то часть меняется намного чаще остальных или когда деплои постоянно блокируют друг друга
- Добавляйте реплику только для чтения, когда нагрузка остаётся высокой после оптимизации запросов и кэширования
- Открывайте второй регион только когда пользователи в другой географии реально чувствуют задержку или требования по доступности это требуют
- Переносите работу в фоновые задачи, когда медленные задачи вредят запросам, а не потому, что «вдруг может пригодиться»
Держите числа видимыми. Отслеживайте ежемесячные расходы, объём алертов, шум пейджера и сколько времени команда тратит на операции каждую неделю. Если новый слой снижает время ответа на 20%, но удваивает on‑call‑работу, такая замена может быть вредна для команды из четырёх человек.
Полезно иметь правило отката. Если новый кэш, очередь или регион не решают ожидаемую проблему в коротком тестовом окне — убирайте. Команды редко жалеют об удалении неиспользуемой сложности.
Если накладные расходы начинают расти быстрее, чем продуктовая работа, внешний обзор может помочь. Oleg Sotnikov делает такую fractional CTO‑работу на oleg.is, фокусируясь на архитектуре, инфраструктуре и практической AI‑автоматизации для маленьких компаний. Короткий обзор перед следующим разделением обычно дешевле, чем месяцы очистки после него.
Часто задаваемые вопросы
Нужны ли ранним стартапам микросервисы?
Обычно нет. Одна аппликация с чёткими внутренними модулями даёт маленькой команде более быструю доставку, проще деплои и отладку. Разделяйте сервисы позже, когда какая‑то часть развивается заметно быстрее или постоянно блокирует релизы для остальных частей продукта.
Когда одной базы данных достаточно?
Для многих новых продуктов одна база PostgreSQL справляется гораздо лучше, чем ожидают. Держите её, пока реальные метрики не покажут узкое место — например медленные отчёты, которые не решаются оптимизацией запросов и кэшированием.
Стоит ли сначала держать всё в одном репозитории?
Начните с одного репозитория, если одна команда всё ещё понимает весь продукт. Это делает изменения видимыми, сокращает «склейку» между сервисами и упрощает локальную настройку.
Когда нам стоит добавить очередь задач?
Добавляйте очередь, когда медленная работа начинает мешать пользовательским запросам. Генерация отчётов, отправка писем, конвертация файлов и повторные попытки вебхуков хорошо подходят для очередей, тогда как быстрые действия, видимые пользователю, обычно должны выполняться в приложении.
Достаточно ли для стартапа одного облачного региона?
Большинство небольших стартапов долгое время работают адекватно в одном регионе. Выберите расположение ближе к вашим пользователям, убедитесь, что бэкапы надёжны, и добавляйте второй регион только когда задержки или требования по доступности это диктуют.
Что стоит автоматизировать в CI/CD в первую очередь?
Держите pipeline маленьким и полезным. Запускайте тесты, проверяйте формат и линтеры, один раз собирайте приложение и блокируйте слияния, если эти проверки не проходят.
Как понять, стоит ли добавлять новый инструмент или сервис?
Запишите боль в одном простом предложении и измерьте её. Если инструмент не сэкономит время, не снизит нагрузку поддержки и не уменьшит инциденты в ближайшие месяцы — подождите.
Какие признаки того, что архитектура становится слишком сложной?
Следите за ростом времени на настройку, неясными деплоями и инструментами без владельцев. Если один человек понимает продакшен в одиночку или небольшая ошибка заставляет команду перебираться через несколько систем, стек стал слишком тяжёлым.
Когда стоит вынести часть приложения в отдельный сервис?
Выносите часть в отдельный сервис, когда она приносит повторяющуюся боль сама по себе. Хороший пример — отчёты: если они часто меняются, выполняют долгие задачи и мешают остальной части приложения, выделение в отдельный сервис оправдано.
Когда маленькой команде стоит попросить внешнюю архитектурную помощь?
Привлекайте внешнюю помощь, когда команда спорит об архитектуре чаще, чем выпускает фичи, или когда операционная работа съедает время продуктовой разработки. Короткий ревью fractional CTO часто находит лишние траты и помогает сделать одно небольшое обратимое изменение вместо полной переписьки.
Стоит ли нам просить обзор архитектуры перед разделением сервисов?
Краткий обзор поможет определить узкие места, правила отката и приоритеты — обычно выгоднее короткой корректировки, чем месяцы очистки после большого разделения.


