Prometheus remote write vs local retention: более дешёвая история хранения
В споре Prometheus remote write vs local retention важны стоимость хранения, скорость запросов и объём операционной работы. Сравните обе модели, пока рост метрик не превратился в бюджетную проблему.
Содержание
За что вы на самом деле платите
Счёт редко начинается с фразы «слишком много метрик». Он начинается тогда, когда одна метрика превращается в огромное количество временных рядов, потому что у labels всё время появляются новые значения. Счётчик HTTP-запросов безобиден, если у него есть labels вроде method и status. Но добавьте tenant_id, pod, region, build_sha или, хуже всего, user_id, и число series быстро пойдёт вверх.
Поэтому решение в споре Prometheus remote write vs local retention — это не только вопрос, где лежат данные. Вы платите за то, сколько уникальных series создаёте, как долго их храните и насколько тяжело Prometheus приходится работать, когда кто-то открывает dashboard посреди инцидента.
Более длинная история каждый день умножает объём хранения. Если держать те же данные 180 дней вместо 30, диск не просто немного заполняется. Он продолжает расти, пока старые blocks наконец не начнут удаляться по сроку. Команды часто упускают это из виду, потому что первый месяц выглядит нормально. Проблемы появляются позже, когда трафик, сервисы и количество labels растут одновременно.
Медленные запросы добавляют ещё одну статью расходов, которой никогда не бывает в cloud invoice. Когда график открывается 15 секунд, инженеры просто ждут. Во время аварии такая задержка бьёт сильнее, чем счёт за хранилище. Dashboards, которые сканируют большие диапазоны времени по шумным labels, могут превратить обычную проверку в медленный поиск.
У растущего SaaS-приложения эта схема видна особенно хорошо. Сначала команда собирает базовые метрики API, базы данных и хостов. Потом добавляются автоскейлящиеся workers, больше регионов, job-метрики на уровне клиентов и краткоживущие pods. Трафик может вырасти всего в два раза, но active series нередко растут куда быстрее, потому что каждое новое значение label комбинируется с остальными.
Именно поэтому рост storage и кардинальности обычно идёт вместе. Больше клиентов — больше tenant labels. Больше релизов — больше pod и version labels. Больше фоновых задач — больше queue и worker labels. Если никто не обрезает этот набор, одновременно растут расход диска, давление на память и время запросов.
Настоящий вопрос о затратах звучит не так: «Нужна ли нам более длинная история?» Он ближе к такому: какие данные остаются полезными достаточно долго, чтобы оправдать количество их series? Короткий retention с грязными labels всё равно может быть дорогим. Более чистая стратегия labels с длинной историей может оставаться разумной гораздо дольше.
Команды, которые справляются с этим хорошо, рассматривают кардинальность и retention как одно решение, а не как две отдельные настройки. Так счёт за хранение становится спокойнее, а Prometheus — надёжнее в моменты, когда что-то ломается.
Как работает длинное локальное хранение
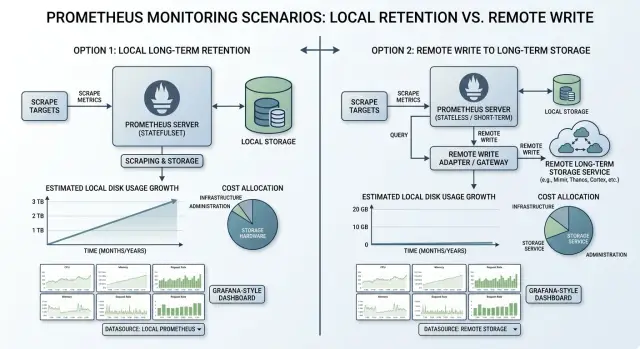
При long local retention Prometheus хранит свежие данные и старую историю на тех же дисках, которые использует каждый день. Ничего не переносится в отдельное хранилище. Scrape-запросы продолжают приходить, write-ahead log записывает новые samples, а потом Prometheus компактизирует эти данные в blocks, которые остаются на диске до тех пор, пока retention-limit не удалит их.
Плюс очевиден. Запросы по локальным данным обычно быстрые, и если график выглядит странно, проверять нужно только одно место. Для небольшой команды такая простота важна. Один узел Prometheus с разумным окном retention часто проще обслуживать, чем раздельную схему с дополнительными компонентами хранения.
Где команды чаще всего ошибаются — так это в планировании диска. Локальное хранилище нельзя рассчитывать на спокойные часы. Его нужно размерить под самый загруженный период, который система должна пережить. Скачок трафика, шумный релиз, дополнительные контейнеры или одно неудачное изменение label могут создать гораздо больше series, чем показывает средний дневной уровень. Если такой пик длится шесть часов, диску всё равно нужно это выдержать.
Реалистичный запас по диску включает больше, чем просто сырые samples. Нужен запас под retained TSDB blocks, рост WAL между compaction, временное место при пересборке blocks и достаточный резерв на перезапуски, задержки и плохие дни.
Compaction легко не замечать, пока сервер не становится занятым. Prometheus переписывает данные в фоне, и для этой работы нужно место на диске. WAL тоже растёт быстрее во время всплесков ingestion или если compaction отстаёт. Сервер может выглядеть здоровым при обычной нагрузке, а потом внезапно упереться в нехватку места в неделю активного релиза.
Вот почему длительное локальное хранение часто обходится дороже, чем кажется сначала. Старые метрики лежат на тех же дисках, которые обслуживают сегодняшний ingestion и сегодняшние запросы. Каждый лишний день истории конкурирует с живой записью. Если вы хотите 90 или 180 дней локально, вы платите за storage, достаточный не для среднего, а для пикового времени.
Читать локальную историю — самая простая часть. Сложнее восстановление. Когда диски переполняются, Prometheus может перестать принимать новые samples, плохо перезапуститься или вынудить вас удалить данные только ради запуска. Long local retention хорошо работает, когда окно истории умеренное и предсказуемое. Оно становится неудобным, когда один локальный узел превращается в долгосрочный архив.
Как remote write меняет расходы и работу
Remote write меняет саму форму задачи. Вместо того чтобы заставлять Prometheus хранить много месяцев данных на локальном диске, вы оставляете рядом короткое окно и отправляете остальное в другое хранилище метрик.
Такое разделение часто работает хорошо. Команда получает быстрые запросы за последние дни или недели — именно там проходит большая часть работ по инцидентам, — а старые данные лежат в месте, рассчитанном на долгосрочное хранение.
Самый дешёвый вариант — не всегда тот, у которого ниже цена диска. Remote write может снизить давление на локальное хранилище, но добавляет расходы, которых нет в простой односерверной схеме. Обычно счёт появляется в четырёх местах: удалённое хранилище для ingested samples и истории, сетевой трафик между Prometheus и удалённым backend, стоимость запросов или кластера в долгосрочном хранилище и время команды на обслуживание ещё одного сервиса.
Именно последняя часть часто удивляет людей. Локальная схема проще для понимания. Но как только появляется remote write, нужно следить за очередями, retry, потерянными samples, аутентификацией и тем, читают ли dashboards локальные данные, удалённые данные или оба источника.
При этом оставлять свежие данные локально всё равно полезно. Во время аварии обычно сначала задают короткие вопросы: что изменилось за последний час, когда выросла ошибка, какой node заполнил диск, какой deploy всё сломал. Локальные данные отвечают на них быстрее и с меньшим количеством деталей.
Работа с длинной историей выглядит иначе. Запрос на 30 или 180 дней может попасть в гораздо более крупное хранилище, просканировать больше series и вернуться медленнее, чем ожидает команда. Протестируйте те запросы, которыми вы действительно пользуетесь, прежде чем принимать модель retention. Не проверяйте один удобный график и не думайте, что всё остальное будет таким же.
Используйте реальные примеры. Откройте dashboard на 90 дней. Сравните сервис сегодня с тем же сервисом три месяца назад. Запустите график затрат или capacity за весь квартал. Если эти представления медленные, люди перестают пользоваться той историей, за которую заплатили.
Для многих растущих команд разумная схема выглядит так: короткий local retention для быстрого реагирования на инциденты и remote write для старой истории, к которой обращаются реже. Это облегчает Prometheus, но только если дополнительное хранение и дополнительная операционная работа остаются под контролем.
Как оценить счёт на 12 месяцев
Большинство команд начинают с размера диска и на этом останавливаются. Но это не главный фактор. В споре Prometheus remote write vs local retention счёт обычно сначала определяют две цифры: samples per second и active series.
Для оценки используйте два временных окна. Возьмите один спокойный месяц, который отражает обычный трафик, и один пиковый месяц с релизами, всплесками нагрузки или дополнительными pods. Если считать только спокойный месяц, итог за год окажется занижен.
В каждом окне зафиксируйте среднее и пиковое число samples per second. Затем посмотрите на labels, которые умножают количество series. Pod name, customer ID, endpoint, container и status code могут очень быстро превратить одну метрику в тысячи series. Если вы ожидаете рост хотя бы по одному из этих labels, учитывайте его сразу, а не предполагаете, что всё останется на месте.
Разделите расходы на несколько простых корзин:
- local SSD или block storage для данных Prometheus
- charges за remote storage для ingestion, retention и чтения запросов
- сетевой трафик, вызванный remote write
- backups или snapshots, если вы храните копии локальных данных
- время инженеров на обновления, сбои и изменения retention
Последнюю строку легко недооценить. Длительное локальное хранение часто означает более крупные диски, более долгие rebuild и более болезненное восстановление, когда узел выходит из строя. Remote write убирает часть этой работы с Prometheus, но за настройку очередей, проверку потерянных samples и периодические изменения запросов всё равно приходится платить.
Хорошо работает простая месячная модель. Оцените спокойный месяц и пиковый месяц отдельно, а потом умножьте на то, сколько раз каждый сценарий встречается за год. Десять спокойных месяцев плюс два напряжённых гораздо лучше, чем двенадцать одинаковых средних месяцев.
Например, если в спокойный месяц нагрузка составляет 120000 samples per second, а в месяц запуска доходит до 280000, не сводите это к одному мягкому числу. Посчитайте оба варианта. Рост storage, передачи данных и active series редко идёт ровной линией, особенно когда во время пиков появляются дополнительные pods или customer labels.
Если нужен быстрый сравнительный ориентир, посчитайте cost per million samples и cost per 100000 active series для каждого варианта. Так проще заметить неверные допущения. Локальное хранение может выглядеть дешёвым, пока не появятся backups и часы инженеров. Remote write может казаться простым, пока network traffic и шумные labels не раздуют ingest bill.
Грубая оценка уже достаточно полезна, чтобы выбрать направление. Если оба варианта выглядят близко, сначала наведите порядок в labels, а потом покупайте больше истории. Удаление шумных series часто экономит больше денег, чем смена места хранения.
Простой пример на росте SaaS-приложения
Представьте команду SaaS с одним сервером Prometheus и 15 днями локальной истории. На раннем этапе это решение кажется отличным. У приложения есть несколько сервисов, база данных, очередь и базовые Kubernetes-метрики. Диск используется спокойно, запросы быстрые, и никто особенно не думает о retention.
Через шесть месяцев у продукта становится больше клиентов, больше pods и больше labels на каждой метрике. Команда добавляет labels namespace, pod, container и deployment, чтобы было проще разбираться в проблемах. Ещё они добавляют tenant-метрики, чтобы support мог замечать медленных клиентов. Трафик удваивается, но число series растёт намного быстрее, потому что каждая новая комбинация labels создаёт дополнительные временные ряды.
Обычно картина выглядит так: трафик растёт в 2 раза, а active series — с примерно 150000 до 600000. Это часто застаёт команды врасплох. Они ожидали более высокий счёт из-за роста бизнеса. Но не ожидали, что метаданные начнут нагружать storage сильнее, чем пользовательский трафик.
Теперь им нужны 90 дней истории для проверки трендов и разбора инцидентов. Если хранить всё локально, математика быстро становится неудобной. Переход с 15 дней на 90 дней — это не небольшой шаг. Это примерно в шесть раз больше истории на том же сервере Prometheus, плюс дополнительный запас под compaction и всплески. Узел, который раньше казался безопасным на нескольких сотнях гигабайт, внезапно может потребовать больше терабайта быстрого диска.
При 15 днях локально и remote write Prometheus-сервер остаётся заметно меньше. Свежие данные всё ещё лежат локально для быстрых операционных запросов, а старая история уходит в backend, созданный для долгосрочного хранения метрик. Команда всё равно платит за retention, но обычно избегает первой срочной проблемы: немедленной покупки и подключения ещё большего объёма локального SSD.
Это важно, потому что проблема с диском превращается в операционную задачу ещё до того, как полностью проявится долгосрочный счёт. Локальное хранение на 90 дней может потребовать срочного апгрейда storage, более крупных nodes и более аккуратной работы с backups и recovery. Remote write добавляет собственный счёт и настройки, но часто даёт время и помогает основному серверу Prometheus оставаться стабильным.
Именно здесь часто появляется честный ответ: если количество series растёт быстрее, чем трафик, длительное локальное хранение становится болезненным раньше. Remote write не исправляет кардинальность, но обычно откладывает момент, когда локальные диски становятся проблемой этой недели.
Ошибки, из-за которых дорогими становятся оба варианта
Чаще всего перерасход начинается с одной привычки: хранить данные «на всякий случай». Команды часто спорят о storage и забывают посмотреть на то, что именно они хранят. Такой порядок почти всегда приводит к проблемам. Скромная схема быстро становится дорогой, когда плохие метрики и плохие labels остаются на месяцы.
Одна из частых ошибок — оставлять все labels только потому, что один dashboard однажды их использовал. Labels вроде user_id, request_id, значения сессий или полные URL-пути могут взорвать число series за несколько часов. Команды добавляют их ради быстрого графика, а потом забывают убрать. Локальные диски заполняются, и счета за удалённое хранилище тоже растут.
Ещё одна ошибка — давать debug-метрикам тот же срок жизни, что и бизнес-метрикам. Выручка, регистрации, ошибки на checkout и latency сервисов часто заслуживают более долгого хранения. А вот per-worker debug counters, временные метрики миграций и одноразовые экспериментальные данные — обычно нет. Если всё хранится год, вы платите за production-уровень данных, которые уже никому не нужны через неделю.
Дорогие настройки по умолчанию, на которые стоит смотреть
- Отфильтровывайте шумные scrape jobs до того, как они попадут в долгосрочное хранилище.
- Раз в неделю проверяйте, какие labels создают больше всего новых series.
- Используйте разные правила retention для debug, infrastructure и business metrics.
- Проверяйте, какими dashboards и alerts люди реально пользуются.
- Тестируйте время replay и restore перед увеличением retention.
Remote write становится дорогим, когда команды пересылают целые scrape jobs без фильтрации. Болтливый exporter, краткоживущие контейнеры или development namespaces могут отправлять в долгосрочное хранилище огромный поток малоценных samples. Счёт растёт незаметно, потому что ingestion продолжается даже тогда, когда никто не читает эти данные.
Привычки к запросам тоже важны. Финансы обычно замечают storage первыми, но инженеры тоже платят — через более медленные запросы и большие индексы. Если никто не открывал dashboard с метриками перезапусков pods за полгода, не храните их так же, как данные о выручке. Короткий пересмотр запросов часто экономит больше, чем ещё одна настройка диска.
Последняя ошибка проявляется во время инцидентов. Команды меняют retention, не проверив restart replay, restore time или backfill speed. Более крупное локальное хранилище может дольше восстанавливаться после сбоя. Удалённая система тоже может медленно перестраиваться или rehydrate данные после переноса. Эта задержка стоит дорого, когда срабатывают alerts, а графикам никто не может доверять.
Лучшее правило простое: храните меньше данных и меньше времени, если только кто-то не может назвать вопрос, на который они отвечают. Такая привычка снижает расходы на хранение Prometheus быстрее, чем большинство изменений у вендора или в железе.
Быстрые проверки перед выбором
Большинству команд не нужен год быстрых локальных данных Prometheus. Им нужно несколько свежих дней для отладки и более длинная история для трендов, планирования и postmortem. Именно этот разрыв сильнее всего влияет на счёт.
Спросите инженеров, что они открывали за последние две недели. Если в основном это были запросы за последние 6–72 часа, длинное локальное хранение может оказаться пустой тратой. Быстрый SSD — это удобно, но дорого, если старые данные просто лежат там «на всякий случай».
Несколько коротких проверок обычно быстро проясняют выбор:
- Посчитайте, сколько запросов касается данных старше 7, 14 или 30 дней.
- Назовите команды, которым нужны графики по месяцам, и для чего они их используют.
- Проверьте, можно ли убрать шумные labels до того, как данные попадут в storage.
- Найдите series, которые растут быстрее всего, а не только общее число series.
- Решите, готова ли команда поддерживать ещё одну систему хранения без ежедневного трения.
Второй пункт легко упустить. Инженерам часто нужны детали за последние часы. Финансам, продукту и руководству обычно нужны более медленные, но широкие срезы по месяцам. Это разные задачи. Если длинные графики нужны только небольшой группе людей, remote write в более дешёвое долгосрочное хранилище часто логичнее, чем хранить всё локально для всех.
Очистка labels — ещё одна быстрая победа. Один label с высокой кардинальностью способен превратить разумную схему в шумную. Session IDs, request IDs, user IDs, сырые URL и неограниченные tenant tags могут резко увеличить расходы и локально, и в долгосрочном storage. Убирайте их заранее, если они не помогают ответить на реальный вопрос.
Не полагайтесь только на общее число series. Смотрите на самые быстрорастущие series по job, namespace, service или exporter. Одна команда может добавить новый шаблон метрик и тихо удвоить ваш счёт за месяц. Если вы понимаете, откуда начинается этот рост, можно исправить naming и labels ещё до выбора более длинного retention.
Операционная нагрузка тоже важна. Remote write не бесплатен только потому, что object storage дешёвый. Кто-то всё равно должен отвечать за remote backend, поведение запросов, пробелы в alerts, правила backfill и сценарии отказа. Если команда и так работает на пределе, более простая локальная схема с более коротким retention может оказаться лучше, чем дешёвая на бумаге, но тяжёлая в поддержке конструкция.
Самый дешёвый вариант обычно совпадает с реальными привычками к запросам, рано убирает лишние labels и не добавляет новую систему, которую команда забросит через три месяца.
Что делать дальше, чтобы схема стала дешевле
Начните с двух временных окон, а не с одного. Оставьте короткое локальное окно для оперативной отладки и более длинное окно для анализа трендов. Многим командам подходит примерно 7–14 дней в Prometheus для быстрых инцидентов, а затем более дешёвое место для 6–12 месяцев старых данных.
Такой раздел делает ежедневную работу проще. Когда alert срабатывает в 2 часа ночи, никто не хочет ждать медленные исторические запросы. Старая история тоже важна, но обычно она отвечает на вопросы планирования, а не на срочные.
Небольшой пилот лучше долгих споров. Возьмите реальные scrape-данные на одну-две недели и посмотрите, что происходит на самом деле. Предположения почти всегда ошибочны, особенно когда в картину входят churn series и шумные labels.
Во время этого теста отслеживайте несколько показателей:
- active series по job и по команде
- трафик remote write и ежедневный рост storage
- скорость запросов для свежих dashboards и старых отчётов
- compaction pressure, использование диска и памяти в Prometheus
- series с labels, которые резко раздувают количество
Проверьте кардинальность до того, как покупать больше диска. Дополнительное storage может на месяц-два скрыть плохой дизайн метрик, а потом счёт снова пойдёт вверх. Label вроде user_id, session_id или сырого пути запроса может сделать и локальное хранение, и долгосрочное хранение метрик намного дороже, чем ожидалось.
Зафиксируйте, кто за что отвечает. Один человек или одна команда должны утверждать дни retention. Кто-то должен владеть фильтрами метрик и правилами relabeling. Кто-то должен получать budget alerts, если storage или ingest выходят за нормальный диапазон. Если никто не отвечает за эти задачи, расходы тихо ползут вверх.
Рабочее правило простое: локальный Prometheus нужен для свежих инцидентов, а не для хранения всех метрик навсегда. Если команда часто сравнивает этот квартал с прошлым, храните эту историю там, где это дешевле. Если команда в основном разбирает сбои сегодняшнего дня, держите локальное окно коротким и чистым.
Самый дешёвый ответ обычно появляется из скучной дисциплины: меньше шумных labels, понятное разделение retention и пилот на реальных данных. Это лучше, чем покупать более крупные диски и надеяться, что проблема исчезнет сама.
Если цифры всё равно выглядят расплывчато, Oleg Sotnikov на oleg.is может вместе с вами посмотреть на расходы Prometheus, Grafana и инфраструктуры. Такой внешний разбор особенно полезен, когда реальная проблема не в storage как таковом, а в форме самих метрик, которые вы храните.
Часто задаваемые вопросы
Сколько данных стоит хранить локально в Prometheus?
Начните с 7–14 дней локально, если команда в основном разбирает свежие инциденты. Так недавние запросы остаются быстрыми, и не приходится сразу покупать большие SSD-тома.
Если людям часто нужно сравнивать месяцы или кварталы, лучше держать эту историю в удалённом хранилище, а не растягивать local retention слишком сильно.
Когда remote write становится более дешёвым вариантом?
Remote write имеет смысл, когда количество series продолжает расти, а история нужна длиннее, чем один Prometheus-node может удобно хранить у себя. Это также помогает, когда локальные диски уже на пределе во время релизов или скачков трафика.
Свежие данные оставляйте локально для инцидентов, а старые отправляйте наружу для отчётов по трендам и postmortem.
Поможет ли remote write решить проблему метрик с высокой кардинальностью?
Нет. Remote write меняет место хранения данных, но не убирает плохие labels и не уменьшает число series, которые вы создаёте.
Если labels вроде user_id, request_id, сырых путей или шумных pod values раздувают количество series, платить всё равно придётся за этот хаос. Сначала наведите порядок в labels.
Какие labels обычно делают хранение в Prometheus дорогим?
Следите за labels, которые постоянно получают новые значения. pod, container, tenant_id, build_sha, сырые URL и всё, что связано с пользователями или сессиями, могут очень быстро разогнать расходы.
Один шумный label может ухудшить и storage, и скорость запросов, поэтому убирайте малополезные labels до того, как они попадут в долгосрочное хранение.
Как оценить годовую стоимость?
Считайте два разных месяца: обычный и загруженный. Используйте samples per second, active series, локальный диск, remote ingest, чтение запросов, сетевой трафик и время инженеров.
Так оценка будет гораздо точнее, чем один усреднённый показатель. Пики почти всегда обходятся дороже спокойных периодов.
Будут ли долгие запросы медленнее при удалённом хранении?
Ожидайте, что недавние запросы останутся быстрее на локальных данных. Более старые запросы к удалённому хранилищу часто выполняются дольше, потому что им приходится просматривать больше данных и больше series.
Проверяйте именно те графики, которые команда реально открывает, а не один простой пример. Если 90-дневный dashboard кажется медленным, им перестанут пользоваться.
Должны ли debug-метрики храниться так же долго, как бизнес-метрики?
Дайте бизнес-метрикам более долгий срок хранения, если их используют для выручки, роста, capacity или разбора инцидентов. Debug-метрики и одноразовые метрики лучше удалять намного раньше, если только никто не может назвать вопрос, на который они отвечают.
Хранить всё одинаково долго — быстрый способ тратить лишние деньги.
Что нужно протестировать перед увеличением retention?
Перед изменением retention проверьте время перезапуска, рост WAL, нагрузку на compaction, время восстановления и скорость запросов. Эти проверки показывают, выдержит ли система пики и сбои.
Более длинное окно выглядит дешёвым на бумаге, пока полный диск или медленное восстановление не испортят вам тяжёлую неделю.
Может ли один Prometheus-server справиться с растущим SaaS-приложением?
Один сервер нормально работает, пока метрики чистые, а окно истории остаётся умеренным. Становится тяжело, когда множатся labels, pods часто меняются, а месяцы данных копятся на одной машине.
Когда локальный диск начинает мешать ingestion или восстановлению, лучше разделить свежую и долгую историю.
Какая самая простая и дешёвая схема подойдёт большинству команд?
Для большинства команд простая и недорогая схема — это короткое локальное хранение для живой отладки и удалённое хранилище для старых трендов. Добавьте к этому строгую очистку labels и регулярную проверку series.
Такая схема обычно лучше, чем покупать большие диски и надеяться, что расходы останутся на месте.


