Правила защиты веток, которые подходят вашей команде по мере роста
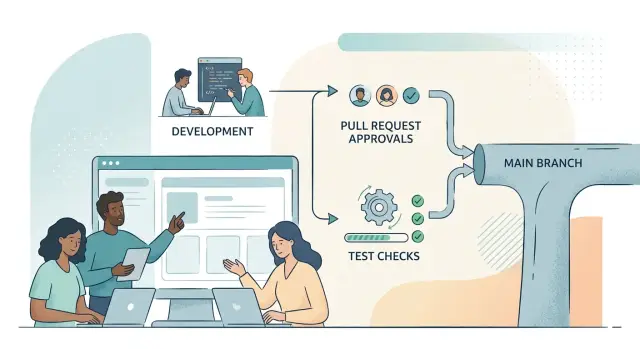
Правила защиты веток должны соответствовать тому, как работает ваша команда. Начните с простых проверок на `main`, затем добавляйте ревью, тесты и ограничения, когда появляются реальные проблемы.
Содержание
Почему командам нужны правила защиты веток
Стабильная ветка main экономит время каждую неделю. Без понятных правил один поспешный коммит может сломать тесты, задержать деплой или выпустить плохое изменение. Сначала ущерб кажется небольшим. Потом он растёт в течение недели через хотфиксы, откаты и время, потраченное на выяснение, что изменилось.
Большая часть этих проблем начинается в обычных моментах. Кто‑то пушит прямо в main, чтобы быстро исправить баг, и случайно добавляет лишнее изменение. Кто‑то другой сливает поздно, потому что никто не знает, кто должен проверять. Утром команда распутывает регрессии вместо того, чтобы работать над следующим фичем.
Когда рискованные слияния остаются без контроля, исправления накапливаются быстро. Один патч правит первую ошибку, затем другой — патч. Релизная работа становится грязной, и люди перестают доверять ветке, от которой зависят все.
Правила защиты веток снижают эту неопределённость. Они определяют, что может попасть в main, кто это утверждает и что должно пройти проверки заранее. Технические настройки важны, но не менее важна ясность. Люди тратят меньше времени на вопросы типа «можно ли сделать исключение» или «кто уже делал исключение на прошлой неделе».
Цель не в том, чтобы добавить трение. Цель — безопасность ветки main. Если main остаётся стабильным, разработчики могут спокойно тянуть свежий код, продуктовые команды планировать релизы увереннее, а саппорт видеть меньше предотвращаемых проблем после деплоя.
Малые команды чаще всего выигрывают первыми. Стартап с четырьмя инженерами и постоянными запросами от клиентов не нуждается в тяжёлом процессе. Ему нужна ветка, которой можно доверять. Защита main, требование pull request и несколько надёжных проверок перед слиянием уже предотвращают много ошибок при релизе.
Команды, которые пропускают эти базовые вещи, часто думают, что работают быстрее. Иногда это так, на день или два. Потом один небрежный merge сжигает половину спринта, и компромисс становится очевиден.
Начните с минимально безопасного базиса
Большинству команд не нужен длинный регламент с первого дня. Нужен короткий набор правил, который защищает ветку, на которую опирается вся команда.
Начните с ветки, которая влияет на релизы. Для многих команд это main или master. Если эта ветка остаётся чистой, откаты случаются реже, и никто не проводит полдня в догадках, какой коммит сломал сборку.
Хороший базис прост:
- защитите ветку
main - блокируйте прямые пуши для обычной работы
- требуйте pull request для каждого слияния
- сохраните один понятный путь для экстренных исправлений
Этого достаточно для многих команд, особенно небольших. Вам не нужны три ревьюера, страница исключений и проверки для каждого инструмента, если вы выпускаете несколько изменений в неделю.
Блокировка прямых пушей важна больше, чем кажется. Один поспешный коммит может обойти ревью, контекст и создать путаницу, которую унаследует вся команда. Pull request замедляет этот момент ровно настолько, чтобы кто‑то другой мог заметить пропущенную миграцию, рискованную правку конфигурации или заметку, которую стоило включить в релиз.
Вам всё равно нужен путь для экстренных случаев. Происходят инциденты в продакшене. Если сайт лежит и одному человеку нужно срочно поправить код, разрешите такой маршрут, но делайте его редким и очевидным. Команды обычно справляются с этим двумя простыми правилами: обход используйте только для реальных инцидентов и сразу после открытия исправления создавайте follow‑up pull request, чтобы зафиксировать изменение.
Держите всю систему легко запоминаемой. Если людям нужна диаграмма, чтобы запуллить маленький фикс — процесс слишком тяжёл. Хорошие правила можно объяснить примерно за минуту.
Настройте первые правила шаг за шагом
Большинству команд лучше иметь одну защищённую релизную ветку, чем кучу правил, разбросанных по разным веткам. Выберите ветку, которая идёт в продакшен, или ту, в которую вы мерджите перед каждым релизом. Для многих это main.
Начните с требования одобрения в pull request. Обычно одного одобрения достаточно на старте. Оно ловит больше проблем, чем многие ожидают, особенно мелкие, но дорогие ошибки: пропущенную конфигурацию, оставшийся debug‑код или поспешную правку контента, которая ломает тест.
Позже, когда команда станет больше или код будет нести больший риск, можно требовать два одобрения.
Далее — требуйте успешных проверок, но только для задач, которые вы уже запускаете и которым доверяете. Если у вас есть одна job для unit‑тестов и одна задача сборки, используйте их. Не включайте пять нестабильных проверок просто потому, что есть такая опция. Правила, которым люди не доверяют, превращаются в фоновый шум, и тогда никто не уважает процесс.
Полезно назначить одного человека, который может утверждать экстренные обходы. В маленькой команде это может быть техлид, инженерный менеджер или CTO. Один ответственный делает исключения редкими и понятными.
Опишите правила обхода простым языком. Короткая заметка в командной документации достаточна. Скажите, когда можно пропустить одобрение или проверки, кто может принять такое решение и что происходит после окончания инцидента. Если команда фиксит баг с оплатой прямо в main, например, всё равно нужно открыть последующий pull request, чтобы задокументировать изменение и проверить, не пропустили ли чего.
Это и есть баланс. Обычный путь ясен, и аварийный путь тоже.
Добавляйте ворота только после реальной боли
Больше правил по умолчанию не делает команду безопаснее. Часто они просто заставляют людей искать обходы. Маленьким командам обычно нужен ясный путь для слияний, а не стена из одобрений и проверок.
Каждое правило должно соответствовать проблеме, которую команда действительно почувствовала. Если никто не может назвать проблему, правило будет казаться случайным. Тогда люди начнут кликать одобрения не читая или ждать проверок, которым не доверяют.
Соотнесите каждое правило с реальным провалом
Если в main продолжают попадать очевидные ошибки, добавьте ревьюера. Один внимательный второй взгляд ловит многое.
Если в main попадает ломающий код и блокирует остальную работу, потребуйте небольшой набора автоматических проверок перед слиянием. Начните с базового: тесты, которые должны проходить, и, возможно, одна проверка сборки. Медленная обратная связь заставляет людей ненавидеть ворота, поэтому держите их компактными.
Если одна и та же часть кода часто вызывает проблемы, требуйте обзор владельца кода только для этой области. Логика биллинга, файлы деплоя и аутентификация — распространённые примеры. Вам не нужно ужесточать ревью по всему репозиторию, чтобы защитить рискованную его часть.
Большие pull request создают собственные проблемы. Ревьюеры бегло просматривают изменения, комментарии появляются слишком поздно, баги прячутся внутри больших переработок. Когда это повторяется, попросите людей разбивать работу на меньшие слияния или введите разумный лимит размера pull request.
Правила могут устаревать. Проверка, которую никто не понимает, шаг одобрения, который все обходят, или требование, не соответствующее рабочему процессу — должны исчезнуть. Мёртвые правила никого не защищают.
Простой подход работает хорошо: добавляйте одно правило для одной повторяющейся проблемы, наблюдайте пару недель и сохраняйте его только если оно действительно предотвращает ту же самую ошибку. Если правило создаёт задержки без пользы — убирайте его.
Простой пример из растущей команды
Представьте команду из трёх человек, выпускающую небольшой SaaS. Один работает с бэкендом, один — с фронтендом, третий занимается багами, поддержкой и мелкими изменениями продукта. Они общаются каждый день и двигаются быстро. Им не нужен тяжёлый процесс.
Их правила начинаются с одной цели: держать main пригодным для работы. Они защищают ветку, требуют одного одобрения и запускают базовую тестовую проверку перед слиянием. Это даёт страховочную сетку, не замедляя все правки.
Пока что этого достаточно. Большинство pull request небольшие. Люди знают кодовую базу, и ожидание дополнительных ревью стоило бы дороже, чем риск.
Потом два пятничных слияния идут не так. Первое ломает поток регистрации. Второе не кладёт продакшен, но изменяет поведение — саппорт замечает это в течение часа. В обоих случаях кто‑то слил в спешке, пытаясь закончить до уик‑энда.
Тогда команда меняет одно правило. Они блокируют прямые пуши в main.
Больше ничего не меняется. Осталось одно одобрение. Те же тесты. Новое правило целится в реальную проблему: поспешные слияния без паузы между написанием кода и деплоем.
Через несколько месяцев продукт растёт, и логика биллинга становится чувствительнее. Возвраты, изменения планов и сроки выставления счетов теперь влияют на доход, поэтому ошибки стоят дороже, чем мелкая проблема UI. Команда не ужесточает всё подряд. Они требуют обзор владельца кода только для файлов, связанных с биллингом.
Это работает. Изменения цен теперь проверяет человек, который лучше всего знает эту область, а обычная продуктовая работа остаётся быстрой.
И они на этом останавливаются. Два одобрения на каждый pull request превратят всё в ожидание. Дополнительные проверки будут дублировать то, что уже ловят тесты. Процесс остаётся достаточно строгим, чтобы защитить main, но не строже.
Часто задаваемые вопросы
С каких правил защиты ветки должна начать маленькая команда?
Начните с небольшого базиса. Защитите main, блокируйте прямые пуши для обычной работы, требуйте pull request и одну проверку перед слиянием.
Такой набор предотвращает многие поспешные ошибки, не замедляя слишком сильно небольшую команду.
Стоит ли блокировать прямые пуши в main?
Да, для обычной работы — блокируйте их. Прямые пуши позволяют одному поспешному коммиту обойти ревью и проверки, что часто приводит к проблемам релиза.
Оставьте один понятный обходной путь для реальных инцидентов и сразу после исправления откройте последующий pull request, чтобы задокументировать изменение.
Сколько одобрений действительно нужно?
Большинству небольших команд хватает одной проверки. Один внимательный ревьюер часто ловит пропущенные изменения конфигурации, отладочный код или правки, которым не хватает контекста.
Требуйте больше одобрений только когда растёт команда или повышается риск.
Какие проверки стоит требовать перед слиянием?
Требуйте только те проверки, которым вы уже доверяете. Сборка и небольшой набор тестов обычно дают достаточную защиту в начале.
Не включайте нестабильные или медленные задачи, пока вы их не почините. Люди игнорируют ворота, которым не доверяют.
Как должен выглядеть процесс экстренного хотфикса?
Сделайте путь для горячих фиксов коротким и очевидным. Назначьте одного человека, который может разрешить обход для реальной проблемы в продакшене, а затем задокументируйте изменение в последующем pull request.
Так исправления идут быстро, но исключения не становятся нормой.
Когда вводить обзор владельцев кода (code owner review)?
Добавляйте проверку владельца кода, когда одна часть репозитория постоянно вызывает дорогостоящие ошибки. Биллинг, авторизация, файлы деплоя и контроль доступа — частые кандидаты.
Вам не нужно ужесточать ревью по всему репозиторию, чтобы защитить один рискованный участок.
Как понять, что наши правила слишком жёсткие?
Наблюдайте за поведением команды в напряжённый день. Если слияния ждут недоступных людей, проверки падают по случайным причинам или люди постоянно ищут обходы — процесс слишком тяжёлый.
Хороший процесс кажется скучным и легко объясняется.
Как быстро должны работать CI-проверки?
Стремитесь к проверкам, которые выполняются примерно за 5–10 минут для обычной работы. Быстрая обратная связь позволяет команде двигаться и при этом ловить распространённые ошибки.
Если проверки занимают 40 минут, люди начнут их ненавидеть и пытаться обходить.
Когда имеет смысл ужесточать правила защиты веток?
Ужесточайте правила, когда боль начинает проявляться в реальной работе. Когда всё больше людей правят один и тот же код, после деплоев растёт количество обращений в поддержку, есть чувствительный код по биллингу или безопасности, или в компанию приходят новые сотрудники — тогда строгие ворота обычно экономят время.
В этот момент более жёсткие правила скорее помогают, чем мешают.
Как часто нужно пересматривать настройки защиты веток?
Пересматривайте настройки после нескольких релизных циклов или после болезненного инцидента. Задайте два прямых вопроса: предотвратила ли эта правило повторяющиеся ошибки и не замедляет ли она обычную работу слишком сильно?
Если правило не решает проблему — удалите его. Если оно слишком тормозит — упростите его.


