Правила таймаутов для вызовов инструментов агента, которые поддерживают работу
Правила таймаутов для вызовов инструментов агента помогают командам решить, когда повторять, подключать человека или остановиться, чтобы один медленный сервис не тормозил весь процесс.
Содержание
Почему медленные вызовы инструментов ломают весь агент
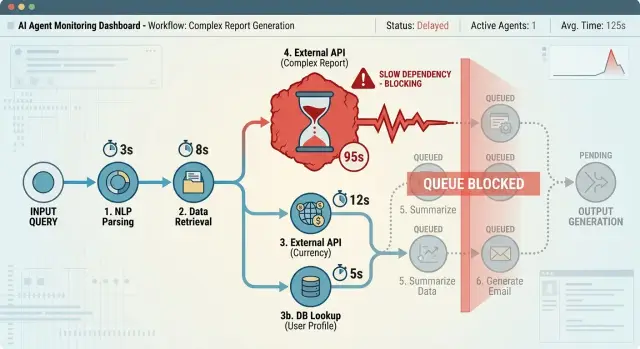
Агент почти никогда не делает только одно действие. Он вызывает инструмент, ждёт ответ, использует его для выбора следующего шага и продолжает работу. Когда какой‑то API висит 30–40 секунд, вся цепочка может застрять.
Такая задержка делает больше, чем просто замедляет одно действие. Она блокирует все последующие шаги, держит работника занятым и удлиняет ожидание остальных запросов. Один застрявший вызов может превратить здоровую очередь в пробку.
Пользователи это чувствуют сразу. Им не важно, ждёт ли агент биллинг, поиск или базу данных — они видят молчание. Когда ничего не происходит, доверие быстро падает. Кто‑то обновляет страницу, отправляет тот же запрос ещё раз или открывает второй тикет. Это добавляет нагрузки, пока первая задача всё ещё застряла.
Длительное ожидание также скрывает реальную проблему. Иногда инструмент вовсе не медленный — агент мог отправить неправильный ID клиента, использовать просроченный токен или запросить несуществующие данные. Если система продолжает ждать вместо таймаута, реальная ошибка остаётся скрытой. Тратится время, и логи сложнее анализировать.
Представьте саппорт‑агента, которому нужны детали заказа, чтобы ответить по возврату. Если сервис заказов висит, агент не может двигаться дальше, ясно объяснить задержку или решить, когда подключить человека. Клиент видит пустую паузу, а не продуманную последовательность действий.
Поэтому быстрый провал часто лучше тихого ожидания. Короткая, ясная остановка даёт системе возможность попытаться снова, сменить путь или передать дело человеку, прежде чем один медленный инструмент потащит всё вниз.
Установите временной бюджет для каждого шага
Таймауты работают лучше, когда вы задаёте их по шагам, а не как одно расплывчатое ограничение на всю задачу. Начните с простого инвентаря workflow: запросы к API, чтения из БД, поиски, чтение файлов, вызовы моделей и вебхуки.
Запишите шаги в том порядке, в каком агент их использует. Отметьте, какие из них напрямую блокируют пользователя. Шаг, который влияет на то, что видит пользователь на экране, должен иметь гораздо более жёсткий лимит, чем фоновая синхронизация или отчёт, который может завершиться позже.
Быстрые проверки должны иметь секунды, а не минуты. Проверка кэша, проверка разрешений или простой статус‑вызов обычно не должны занимать больше 2–5 секунд. Если это висит дольше, агент должен двигаться дальше, повторить по чётким правилам или использовать запасной вариант.
Более тяжёлым операциям можно дать больше времени, но только если результат стоит задержки. Разбор документа, объёмный поиск или скан кода могут заслуживать 20–30 секунд, если дают агенту информацию, недоступную иначе. Если шаг даёт лишь небольшое улучшение, держите бюджет коротким.
Простая отправная точка может выглядеть так:
- Немедленные пользовательские проверки: 1–5 секунд
- Внешние API: 5–15 секунд, с учётом реальной истории ответов
- Тяжёлый анализ или генерация: 15–45 секунд, когда это явно меняет результат
- Фоновые задачи: отдельные лимиты, чтобы они не блокировали текущую задачу
Также нужен общий бюджет для всего выполнения. Если у агента 60 секунд на весь процесс, он не может потратить 30 секунд на один медленный сервис и притворяться, что остальной workflow в порядке.
Общий предел заставляет расставлять приоритеты. Саппорт‑агент может потратить 3 секунды на проверку статуса аккаунта, 8 секунд на вытягивание недавних заказов и 12 секунд на поиск по прошлым тикетам. Если один вызов съедает половину бюджета, агент должен перестать пытаться добыть дополнительный контекст и ответить тем, что уже есть, или передать человеку.
Соотнесите повторы с типом ошибки
Политика повторов должна по‑разному относиться к временным сбоям и к ошибкам запроса. Если инструмент таймаутит, теряет соединение или возвращает 502/503, проблема может пройти сама собой — имеет смысл попытка повторно. Если агент отправил неправильное поле, пропустил обязательный параметр или запросил несуществующие данные, ещё одна попытка только зря потратит время и деньги.
Начинайте с типов ошибок, а не с общей единой политики для всех инструментов. Агент должен понимать, какие сбои временные, какие вызваны плохим вводом, а какие означают, что инструмент сейчас недоступен.
Повторяйте короткие проблемы: сетевые таймауты, сбросы соединений, лимиты 429 с понятной инструкцией ждать, 5xx ошибки сервера или кратковременные проблемы авторизации из‑за просроченных короткоживущих токенов. Останавливайтесь сразу, когда сбой вызван агентом: плохой ввод, неверные ID, отсутствующие поля, права доступа и несоответствие схемы обычно требуют исправления, а не ещё одной попытки.
Держите паузы между повторами короткими. Во многих случаях достаточно 2–5 секунд перед первой повторной попыткой, затем чуть более длинная пауза перед второй. После этого — стоп. Три быстрых отказа уже многое говорят. Десять попыток обычно превращают одну задержку в заблокированный workflow.
Платные инструменты и API с лимитами требуют ещё более строгих правил. Если каждая попытка стоит денег или убывает квота, ограничьте повторы одной‑двумя, если только шаг действительно важен. Проверка биллинга может подождать человека. Снятие денег никогда не должно выполняться повторно без чёткой идемпотентности.
Записывайте каждое решение о повторе. Храните имя инструмента, номер попытки, код ошибки, время ожидания и причину повторной попытки. Эта дорожка поможет настроить бюджеты, заметить шумные инструменты и понять, когда агент должен попросить помощи вместо ещё одной попытки.
Простой пример: если саппорт‑агент не может получить заказ из‑за 503 от commerce API, он может попробовать дважды с короткими паузами. Если номер заказа не проходит валидацию, агент должен попросить клиента подтвердить номер и прекратить повторы.
Знайте, когда агент должен просить о помощи
Плохая передача человеку обычно происходит слишком поздно. Если агент продолжает повторять до последней минуты, пользователь ждёт дольше, а человек, который возьмёт дело, получает более сложный кейс.
Попросите человека до того, как следующее действие может причинить вред. Это включает перевод денег, удаление данных, изменение доступа аккаунта, закрытие тикета или отправку клиенту утверждения, которое агент не может проверить. Если действие легко отменимо, ещё одна попытка может быть допустимой. Если действие может нанести реальный урон, остановитесь раньше.
Конфликтующие результаты — ещё один явный триггер. Когда один инструмент говорит «оплачено», а другой — «просрочено», агент не должен гадать. То же относится к общим фактам: статус аккаунта, адрес доставки или дата продления подписки. Короткое окно для повторной попытки поможет, когда системы обновляются с разной скоростью, но после этого дело должно перейти к человеку.
Некоторые случаи не про сбой, а про выбор. Если пользователю нужно выбрать между валидными опциями, спрашивайте его раньше, чем действовать по слабому предположению. Саппорт‑агент может предложить возврат или замену, но только клиент может решить, что он хочет.
Набор простых правил работает хорошо:
- Передавайте человеку немедленно, если следующее действие влияет на деньги, безопасность, соответствие требованиям или данные клиента.
- Передавайте, если два инструмента расходятся в одном и том же факте после разрешённого числа повторов.
- Передавайте, если пользователь должен выбрать между валидными опциями.
- Передавайте, если бюджет времени почти исчерпан, а у агента всё ещё нет одного надёжного ответа.
Заметка для хэнд‑оффа должна быть краткой и конкретной. Человеку не нужны все строки логов или полная цепочка рассуждений. Ему нужен запрос, заблокированный шаг, проверенные инструменты и точный конфликт или таймаут.
Например: "Клиент запросил отмену и возврат. Billing API вернул активную подписку. CRM вернул статус canceled. Агент повторил один раз. Возврат не отправлялся. Нужен человек для проверки перед изменением аккаунта."
Передача человеку лучше всего работает, когда триггер прост. Если агент не может понять, что правда, или не может действовать безопасно, он должен остановиться и передать дело дальше.
Знайте, когда агент должен остановиться
Агент, который никогда не останавливается, превращает один медленный сервис в полный провал workflow. Установите жёсткий конец для всей задачи, а не только для отдельных вызовов. Если у задачи лимит 60 секунд, а агент уже потратил 50, ещё одна попытка к сервису, который обычно занимает 20 секунд, — плохая ставка. Остановитесь и верните управление.
Повторяющиеся таймауты от одного и того же сервиса — ещё один сильный сигнал остановиться. Один таймаут может быть случайностью. Три подряд от одного API обычно означают, что сервис упал, перегружен или блокируется из‑за авторизации или сети. Ещё повторы только будут жечь время и деньги.
Агент должен также остановиться, когда отсутствие данных блокирует следующее безопасное действие. Если он не может найти ID клиента, номер заказа, состояние одобрения или совпадение аккаунта, не надо гадать. Гадание может обновить чужую запись, отправить неверный ответ или инициировать платёж не тому человеку.
Запасные варианты (fallback) требуют той же проверки. Если fallback даёт более простой, но всё ещё корректный результат, используйте его. Если fallback меняет факты, подставляет недостающие детали или совершает действие на слабых данных — остановитесь. Короткий неполный ответ лучше, чем уверенный, но неверный.
Когда агент останавливается, возвращайте простой статус вместо продолжения попыток. Кратко и конкретно укажите: какой шаг провалился, какой сервис таймаутнул, сколько было повторов и нужен ли человек.
Например: "Остановлено. Billing API таймаутил 3 раза за 45 секунд. Агент не смог подтвердить статус счёта, поэтому сообщение о возврате не отправлено. Нужен человек для проверки."
Хорошие правила таймаута не пытаются спасти каждый кейс. Они останавливают работу, когда дальнейшее ожидание скорее сделает результат медленнее, более грязным или неверным.
Стройте политику от конца workflow назад
Начните с полного workflow, а не с отдельных инструментов. Запишите крайнее допустимое время завершения для всей задачи, затем идите назад. Если задача должна закончиться за 2 минуты, каждый вызов инструмента должен умещаться в этот лимит с запасом на повторы, логирование и финальное решение.
Так вы избежите распространённой ошибки: дать каждой зависимости щедрый таймаут и обнаружить потом, что агент может провести пять минут, ожидая три медленных сервиса подряд.
Далее рассортируйте инструменты по типичному времени отклика. Кэш‑проверка или правило получают короткую «девичью» линию. Чтение из базы может получить чуть больше. Сторонний API или обработка документов — самое длинное окно, но и оно должно иметь предел. Не задавайте эти лимиты вслепую: используйте реальные тайминги из обычных и плохих прогонов.
Потом дайте каждому инструменту только два простых правила: одно про повтор и одно про остановку. Держите их простыми. Повторите один раз после сетевого таймаута, но остановитесь сразу при ошибке прав или плохом вводе. Если инструмент упал по причине, которую агент не может исправить, дополнительные повторы лишь создадут шум.
Добавьте одну точку передачи человеку, где требуется суждение. Обычно это место, где агент мог бы сделать рискованный выбор на основе частичных данных — одобрение возврата, доступ к аккаунту или любое клиентское действие, которое может навредить при ошибке. Одна чёткая точка передачи часто достаточно, чтобы сохранить систему безопасной, не замедляя её слишком сильно.
Перед релизом прогоните несколько «уродливых» тестов. Сделайте одну зависимость медленной, одну таймаутящуюся дважды, одну вернувшую неполные данные и одну с постоянной ошибкой. Затем доведите весь workflow до конечного дедлайна. Если агент всё ещё завершает аккуратно, просит помощи вовремя или останавливается без тряски, политика, вероятно, в порядке.
Пример простого support‑workflow
Саппорт‑агент получает новый тикет: «Платёж прошёл, но аккаунт всё ещё заблокирован». Он читает сообщение, получает ID клиента и проверяет запись аккаунта перед тем, как ответить.
Первый вызов идёт в сервис аккаунтов. Агент ждёт 2 секунды, потому что эта система обычно отвечает быстро. Если ответа нет, он повторяет один раз. Это разумный компромисс: короткие сетевые сбои случаются, и одна попытка часто решает проблему без значительной потери для очереди.
Если сервис аккаунтов отвечает, агент сравнивает данные по биллингу с заметками в CRM. Иногда эти системы расходятся: биллинг может показывать «оплачено», а в CRM есть заметка о том, что клиент просил отмену вчера. Агент не должен угадывать, кто прав. Он должен попросить человека и передать краткое резюме конфликта.
Следующий шаг — поиск в базе знаний. Агент может понадобиться внутренняя политика по возвратам или правила продления. Этот инструмент менее предсказуем, поэтому политика должна быть строже. Если поиск таймаутит дважды, агент должен прекратить эту ветку вместо бесконечных повторов.
В этот момент дело должно двигаться дальше. Короткий статус лучше, чем молчание:
- "Я проверил ваш аккаунт и нашёл несоответствие в биллинге."
- "Я не смог подтвердить политику в наших внутренних документах."
- "Нужен специалист поддержки для проверки этого случая."
Это даёт клиенту понятный ответ и даёт команде чистую передачу, вместо скрытой ошибки, застрявшей в workflow.
Распространённые ошибки, создающие застрявших или шумных агентов
Медленный вызов инструмента может навредить больше, чем явный провал. Когда инструмент зависает, агент часто продолжает ждать, повторяет в неподходящий момент или забивает логи расплывчатыми ошибками. Так полезный workflow превращается в хаотичный.
Одна распространённая ошибка — у всех инструментов одинаковый таймаут. Запросы к базе, платёжный API и парсер документов ведут себя по‑разному. Если дать всем по 30 секунд, какие‑то шаги завершатся слишком быстро, а другие будут тратить время после того, как пользователь уже перестал ждать.
Ещё одна ошибка — повторять только потому, что первый вызов таймаутнул. Надежда — это не политика. Если инструмент обычно отвечает за 2 секунды, а вдруг стал отвечать 25, вторая и третья попытки только нагромоздят работу. Хорошая политика повторов смотрит на задачу, инструмент и стоимость задержки, прежде чем пытаться снова.
Команды также забывают про сторону пользователя. Большинство людей примут короткую паузу, если задача важна. Мало кто согласится ждать минуту в тишине, пока одна зависимая система борется. Если агенту нужны данные клиента, чтобы ответить на тикет, зачастую лучше после чёткого лимита написать «Мне нужен человек» вместо того, чтобы держать клиента в ожидании результата, который может никогда не прийти.
Плохое логирование усугубляет всё это. Логи, говорящие только "request failed", не показывают, таймаутил ли инструмент, вернул ли он частичные данные или провалился после трёх повторов. Другой распространённый пробел — иметь лимиты по шагам, но не иметь общего бюджета для всего запуска. Даже разумные по‑шагу лимиты могут суммироваться в застрявшую сессию, когда много небольших задержек накладываются друг на друга.
Чёткие логи решают это быстрее, чем многие команды ожидают. Записывайте, какой инструмент таймаутил, сколько агент ждал, повторялся ли он и почему остановился. Если вы не видите этот путь в одном месте, застрявшие агенты будут появляться снова и снова.
Проверки перед продакшеном
Если ваша команда не может объяснить таймаут одной простой фразой, правило слишком сложно для продакшена. Каждый лимит должен отвечать на три простых вопроса: чего мы ждём, сколько будем ждать и почему это время имеет смысл для этой задачи?
Повторы должны быть так же легко объяснимы. Повтор нужен для известного случая ошибки, а не потому что "ещё попыток безопаснее". Если инструмент обычно падает одинаково после первой попытки, дополнительные повторы лишь тратят время и скрывают реальную проблему.
Перед релизом проверьте пять вещей:
- Может ли кто‑то объяснить каждый таймаут, не открывая код?
- Соответствует ли каждый повтор известному случаю ошибки?
- Возвращает ли агент понятный статус при остановке, например timed_out, blocked или needs_human?
- Видно ли человеку, какой инструмент таймаутил, сколько было повторов и что агент сделал дальше?
- Тестировали ли вы одну медленную зависимость в период высокой нагрузки, а не только в тихом режиме?
Последняя проверка ловит много проблем. Саппорт‑агент может выглядеть нормально утром, но застревать днём, когда растёт объём тикетов и один внешний сервис замедляется на пару секунд. Тестирование при низкой нагрузке промахивается.
Сделайте след таймаутов простым для чтения. Строка лога, трейса или событие дашборда должны показывать имя инструмента, время начала, время окончания, число повторов и финальный результат. Если команда уже использует Sentry или Grafana, поместите туда эти данные, чтобы человек на вызове не копался в сырых логах.
Когда агент останавливается, он должен ясно это сказать и вернуть полезный контекст. Молчание — худший исход. Человек должен в течение нескольких минут понять, что таймаутнуло и нужно ли пробовать снова, подключиться самому или оставить как есть.
Что делать дальше
Начните на бумаге, а не в коде. Опишите правила таймаутов простым языком, чтобы любой в команде мог их прочитать, оспорить и улучшить.
Хороший первый черновик прост: сколько агент ждёт, сколько раз повторяет, когда просит человека и когда останавливается. Если вы не можете объяснить эти четыре выбора в нескольких строках, политика, вероятно, слишком сложна.
Затем посмотрите реальные логи. Медленные вызовы часто остаются в workflow, потому что никто не проверяет, приводят ли они к улучшению результата. Если инструмент таймаутит на 45 секунд, но почти никогда не отвечает после 12 секунд, сократите ожидание. Это одно изменение может сэкономить удивительное количество времени в загруженной системе.
Используйте один workflow как тестовую площадку, прежде чем распространять шаблон повсюду. Триаж поддержки — хорошее место для старта: шаги видны чётко — классификация запроса, получение данных аккаунта, черновик ответа и передача человеку, если система застряла.
Практическое развертывание просто. Опишите правила простым языком, пересмотрите реальные сбои и задержки, сократите любой таймаут, который не приносит пользы, протестируйте политику на одном workflow неделю и только после этого копируйте паттерн.
Не стремитесь к идеальным настройкам в первый день. Стремитесь к меньшему числу застрявших запусков, меньше шумных повторов и чище передачам человеку. Команды обычно больше учатся на десяти реальных ошибках, чем на долгом планировании.
Если вам нужен внешний обзор, Oleg Sotnikov на oleg.is работает как Fractional CTO и советник для стартапов и небольших команд. Он помогает компаниям строить AI‑первое развитие и системы автоматизации, включая практичные правила таймаута, повторов и передачи человеку, которые подходят для реальной продакшен‑работы.
Лучшая политика — та, которую команда регулярно обновляет после столкновения с реальным трафиком.
Часто задаваемые вопросы
Какой таймаут ставить для вызова инструмента агента?
Начните со шага, а не с целого агента. Дайте быстрым проверкам, видимым пользователю, примерно 1–5 секунд, большинству внешних API — 5–15 секунд, а более тяжёлому анализу — 15–45 секунд, если он существенно меняет результат. Затем установите жёсткий предел для всего выполнения, чтобы один медленный сервис не «съел» весь бюджет.
Должен ли каждый инструмент использовать один и тот же таймаут?
Нет. Кэш-проверка, биллинговый API и парсер документов работают по-разному, поэтому им нужны разные лимиты. Если всем инструментам дать одинаковый таймаут, какие-то шаги завершатся слишком рано, а другие будут тратить время после того, как ответ перестал быть полезным.
Когда агент должен повторить неудачный вызов инструмента?
Повторяйте короткие временные сбои: таймауты, разрывы соединения, ошибки 502 или 503 и некоторые ответы с ограничением по частоте, где есть понятное время ожидания. Не повторяйте при ошибках ввода, отсутствующих полях, неверных ID, проблемах со схемой или правами, если агент сам причинил ошибку.
Сколько повторов — это слишком много?
В большинстве случаев остановитесь после одной-двух коротких попыток. Если один и тот же сервис таймаутит три раза подряд или задача близка к общему дедлайну, ещё одна попытка обычно делает workflow медленнее и грязнее, не улучшая результата.
Когда агент должен передать случай человеку?
Попросите человека до того, как следующее действие может причинить вред: перевод денег, изменение доступа к аккаунту, удаление данных, закрытие записи или любой случай, когда два инструмента расходятся во мнении и агент не может проверить, кто прав.
Что пользователь должен увидеть после таймаута?
Покажите понятный статус вместо молчания. Скажите, какой шаг заблокирован, пытался ли агент повторить вызов и нужен ли человек для проверки. Короткое честное обновление сохраняет доверие гораздо лучше, чем пауза в тишине.
Нужен ли общий таймаут для всего workflow?
Да. Лимиты по шагам помогают, но мелкие задержки суммируются и могут остановить сессию. Общий бюджет заставляет агента жертвовать менее важными шагами и аккуратно завершать работу, когда дальнейшее ожидание не поможет.
Что нужно логировать при таймаутах и повторах?
Логируйте имя инструмента, номер попытки, время ожидания, код ошибки и причину каждой попытки или остановки. Сделайте эту дорожку лёгкой для чтения в одном месте, чтобы команда могла заметить шумные инструменты, убрать плохие повторы и объяснить сбои без копания в сырых логах.
Какие ошибки создают застрявших или шумных агентов?
Обычно дают всем инструментам слишком большой таймаут, повторяют в надежде, что следующее сработает, и забывают ограничить весь workflow. Ещё одна проблема — расплывчатые логи вроде request failed, которые скрывают, повис инструмент, вернул частичные данные или упал навсегда.
Как тестировать правила таймаутов перед продакшеном?
Запускайте «грязные» тесты специально: сделайте одну зависимость медленной, одну таймаутящейся дважды, одну вернувшей неполные данные и одну с постоянной ошибкой. Если агент всё равно корректно завершает работу, запрашивает помощь вовремя и возвращает ясный статус — политика в порядке.


