Повторы задач Kubernetes и счёт за облако, который вы не замечаете
Повторы задач в Kubernetes могут тихо удваивать cloud-расходы. Узнайте, как ограничить повторы, удалить orphaned pods и alert'ить о зависшей бизнес-работе.
Содержание
Почему эта проблема быстро бьёт по счёту
Неудачная batch-задача редко падает один раз. В Kubernetes одна ошибка может запустить новый pod, потом ещё один, и так до тех пор, пока не закончится policy повторов. В конфиге это выглядит безобидно. В счёте за облако может означать, что вы оплатили одну и ту же неудачную работу три или четыре раза.
Каждый повтор снова запускает счётчик. Cluster может загрузить container image, зарезервировать CPU и memory, записать логи, открыть сетевые соединения и создать временное хранилище. Даже если задача падает за 20 секунд, эти расходы всё равно считаются. Если образ большой или cache на node холодный, потери быстро растут.
Проблема становится хуже, когда задачи запускаются по расписанию. Retry count 3 звучит умеренно, пока десятки batch-задач не сталкиваются с одним и тем же плохим input, истёкшим token или сломанным secret. Тогда одна тихая ошибка превращается в поток short-lived pod на всю ночь. Если включён autoscaling, эти повторы могут даже поднять дополнительные nodes ради работы, которая уже провалилась.
Один import, который запускается каждые 10 минут, за день может создать сотни лишних запусков pod, даже если повторов всего несколько. Поэтому даже небольшие лимиты на повторы могут разрастаться. Настоящая проблема не в одной задаче. Она в одной задаче, повторяющейся со временем.
Команды часто замечают счёт раньше, чем замечают pattern. Cloud dashboard показывает рост затрат на compute, хранение логов или network, но failed jobs легко пропустить, потому что каждый pod умирает быстро. Ни один pod по отдельности не выглядит серьёзно. Деньги утекают из-за постоянного churn.
Неудачные запуски создают и косвенные расходы. Они засоряют логи, перегружают monitoring и заставляют инженеров разбирать dead pods вместо того, чтобы чинить настоящую причину. Хороший контроль cloud-расходов начинается с остановки бесполезных повторов, потому что маленькая ошибка в конфиге в 23:00 может продолжать тратить деньги до утра.
Откуда именно берутся лишние расходы
Большинство команд сначала смотрят на CPU и memory. Но счёт часто растёт в промежутках между неудачными попытками.
Каждый retry создаёт новый pod, а этот pod начинает стоить денег ещё до того, как сделает что-то полезное. Node должен его запланировать, запустить контейнер, подключить storage, настроить сеть и записать логи. Если image большой или node пустовала, запуск может занять больше времени, чем сама задача. В некоторых Kubernetes batch-задачах десять коротких неудач стоят дороже, чем один длинный успешный запуск.
Policy повторов также растягивает waste во времени. Задача, которая падает, ждёт и пробует снова в течение двух часов, удерживает выделенные вычисления, продолжает наращивать логи и блокирует очередь. Даже если pod выходит быстро, окно повторов может удерживать мёртвую работу куда дольше, чем того заслуживает бизнес-задача.
Orphaned pods добавляют более тихий счёт. Они могут оставлять после себя файлы логов, временные volumes и занятые IP-адреса уже после того, как задача фактически провалилась. Команды обычно замечают это поздно, когда nodes выглядят занятыми сильнее, чем ожидалось, или storage растёт без видимой причины.
Оповещения тоже могут усугублять ситуацию. Если alert'ить по общему количеству pod, люди начинают преследовать симптом, а не зависшую задачу. Всплеск failed pods может будить команду всю ночь, пока один сломанный import или неверный формат сообщения продолжает повторяться в фоне. Исправление занимает больше времени, значит, дольше длится и waste.
Обычно утечки простые:
- время запуска каждого нового pod
- длинные окна повторов, которые удерживают мёртвую работу
- устаревшие pod, которые держат логи, storage или IP
- шумные оповещения, замедляющие уборку
Вот почему счёт может вырасти без увеличения клиентского трафика. Cluster занят повторением одной и той же неудачи.
Простой пример с ночным импортом
В 1:00 ночи batch-задача запускает ночной import из CSV-файла партнёра. Обычно она завершается за 15 минут, но однажды в одной записи оказывается сломанное поле даты, и parser останавливается на середине.
Команда ждёт одного неудачного запуска. Вместо этого Job повторяется снова и снова, потому что limit на повторы оставался без изменений месяцами. Каждый retry запускает новый pod, загружает тот же образ, читает тот же файл, пишет те же логи и сжигает ещё немного времени node, прежде чем наткнуться на ту же плохую строку.
К 3:00 ночи в cluster уже лежит небольшая куча failed pods от одного импорта. По отдельности они не выглядят драматично, поэтому такая проблема легко проскальзывает мимо занятых команд. Несколько лишних pod, несколько дополнительных потоков логов, ещё несколько минут CPU — всё это по отдельности кажется дешёвым.
К 9:30 кто-то исправляет плохую запись и запускает импорт снова. Новый запуск проходит успешно, и все идут дальше. Но старые failed pods остаются, потому что policy очистки их не удаляет, а лишний объём логов, который они оставили, никто не замечает.
Вот где счёт растёт незаметно. Расходы на compute увеличиваются из-за повторной работы, стоимость логов растёт с каждой неудачной попыткой, а storage может ползти вверх, если временные файлы или артефакты остаются на месте. Если тот же pattern появляется в нескольких задачах, waste быстро складывается.
Обычно finance не замечает это на следующий день. Они видят проблему в конце месяца, когда compute выше ожидаемого, а счета за логи выглядят ещё менее логичными. Инженеры помнят несколько ночных сбоев, которые казались мелочью, но invoice говорит другое.
Так orphaned pods превращаются из хозяйственной проблемы в денежную. Плохую запись исправили за минуты. А повторы, старые объекты и лишние логи продолжали списывать деньги ещё долго после того, как data issue исчезла.
Как ограничить повторы, не пропустив реальные сбои
Большинству задач не нужно много вторых шансов. Когда batch-задача падает по одной и той же причине, лишние повторы только увеличивают время на compute, объём логов и число pod. Limits на повторы должны подходить задаче, а не быть дефолтом, к которому никто больше не возвращается.
Начните с задач, которые повторяются чаще всего. Посмотрите на последние несколько недель и отсортируйте их по числу повторов, времени выполнения и стоимости. Обычно вы найдёте небольшую группу шумных задач, которая и делает основную часть ущерба.
Краткий разбор часто показывает два типа ошибок. Одни случайные и исчезают при следующем запуске, например краткий timeout сети. Другие — постоянные, например плохой входной файл, неверная schema или отсутствующий secret. Повторы помогают первой группе. Второй — почти никогда.
Для одноразовой batch-работы держите cap на повторы низким. Во многих случаях backoffLimit 1 или 2 достаточно. После этого помечайте задачу как failed и переставайте платить за ту же ошибку. Если другой controller или script снова создаёт задачу после последнего retry, исправьте и это, иначе limit всё равно не поможет.
Практичный старт простой:
- сначала разберите самые шумные задачи
- поставьте небольшой cap на повторы для повторяемых сбоев
- после последней попытки завершайте задачу как failed
- отправляйте такие ошибки на ручную проверку
- сначала протестируйте новый limit на одной задаче, прежде чем менять остальные
Ручная проверка звучит медленнее, но в итоге часто выходит и дешевле, и быстрее. Если у customer upload неверные столбцы, ещё пять попыток не исправят файл. Человек может один раз посмотреть ошибку, поправить input и запустить задачу заново без мусора.
Внедряйте это по одной задаче. Выберите задачу с частыми повторами, уменьшите limit, неделю смотрите на частоту сбоев и убедитесь, что реальные проблемы всё ещё замечаются. Потом переходите к следующей. Такой постепенный подход помогает избежать неожиданных простоев и сокращать cloud-счёт, не пряча настоящие ошибки.
Как очищать orphaned pods
Старые pod от задач могут лежать в cluster днями, даже если работа давно завершилась. Они засоряют dashboards, путают проверки on-call и в некоторых конфигурациях продолжают немного стоить через storage, логи или последующую автоматизацию, которая всё ещё их сканирует.
Начните с решения, какие pod должны исчезать и когда. Для большинства batch-задач успешные pod не нужно хранить вечно. Failed pod могут понадобиться чуть дольше, чтобы кто-то разобрал ошибку, но у них не должно быть бесконечной жизни без причины.
Начните с простого правила
Обычно простое правило работает лучше хитрого. Многие команды нормально живут с таким подходом:
- удалять successful pod через несколько часов
- хранить failed pod 1–3 дня
- держать дольше только ради audits или трудно воспроизводимых сбоев
Затем проверьте, какие pod переживают задачу, которая их создала. Если задача закончилась вчера, а pod до сих пор лежат, это уже не история, а отклонение. В cluster с частыми повторами такой pile растёт быстрее, чем ожидают.
Самый чистый вариант — TTL cleanup для завершённых Jobs. Он держит policy рядом с нагрузкой, так что cluster сам удаляет старые объекты. Если TTL вам не хватает, запустите периодическую задачу очистки, которая удаляет pod и Jobs по возрасту, namespace, label и status. Сначала держите правило узким. Слишком мягкая очистка раздражает. Неправильная — ломает отладку.
Перед удалением старых pod убедитесь, что вы сохраняете нужные логи. Сначала отправьте stdout, stderr и status задачи в logging system. Если нужен дополнительный контекст, сохраните события или короткое summary ошибки вне pod. Когда это уже настроено, удалять старые pod становится намного спокойнее.
Очень помогает небольшой стандарт именования и labels. Добавляйте для batch-задач labels команды, системы и класса хранения. Тогда cleanup-задача сможет чётко указать, какие failed pod хранятся 24 часа, а какие 7 дней.
Наблюдайте за результатом неделю. Посмотрите, сколько старых pod осталось, не потерял ли кто-то логи и не пришлось ли support или engineering восстанавливать удалённые данные. Потом при необходимости подправьте возрастные лимиты. Лучшее правило обычно скучное: оно молча убирает старые pod, и никто этого не замечает, кроме счёта.
Alert'ите по зависшей работе, а не по общему числу pod
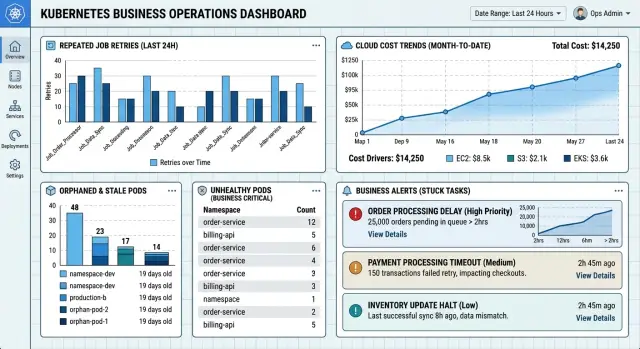
Большинство команд alert'ят по тому, что Kubernetes умеет считать: pod, restart, pending states. Это легко настроить, но часто это рассказывает не ту историю.
Людей не волнует, что существует 14 pod. Их волнует, что invoice sync не завершился до начала работы finance или что export отчёта не уложился в утренний дедлайн. Полезные Kubernetes-alert'ы начинаются с бизнес-задачи и окна её завершения.
Ночной import — хороший пример. Допустим, обычно он заканчивается к 2:15 ночи. Если в 2:30 он всё ещё работает или retries продолжают уводить его за это окно, работа зависла, даже если некоторые pod выглядят здоровыми. Это должно вызывать один alert на весь запуск задачи.
Сигналы по общему числу pod всё ещё нужны, но их стоит держать ниже по приоритету. Количество pod скачет и по безобидным причинам: параллельные запуски, медленный pull образа, изменения nodes или задержка очистки. Когда каждый pod создаёт отдельный page, люди перестают доверять системе. Тогда реальные сбои теряются в шуме.
Лучше работает один alert на один запуск задачи. Он даёт on-call человеку одну понятную проблему вместо кучи почти одинаковых сообщений от одного и того же failed run. Так и повторы легче оценивать. Один retry — нормально. Десять retries за 45 минут у одного и того же export отчёта — нет.
Полезное сообщение alert'а должно включать:
- название задачи, например invoice sync или report export
- время старта запуска
- текущий возраст задачи
- сколько было retries
- последнюю причину ошибки
Это маленькое изменение экономит время. Человек, который читает alert, за секунды понимает, задача просто медленная, зациклилась в retries или заблокирована чем-то внешним, например плохим upstream-файлом.
Если вы уже отслеживаете status задачи в приложении или workflow-слое, используйте его как основной сигнал, а pod metrics оставьте в поддержку. Небольшие команды обычно выигрывают от такой схемы. Они тратят меньше времени на погоню за безвредным pod churn и быстрее замечают работу, которая действительно грозит дедлайнами, повторной обработкой или более крупным счётом.
Ошибки, которые команды совершают
Обычно команды теряют деньги на batch-работе вполне обычными способами. Счёт немного растёт на каждом retry, на каждой записи логов и на каждом alert, который будит человека без серьёзной причины.
Распространённая ошибка — оставить настройки повтора по умолчанию и не проверить, подходят ли они под workload. Retry count, который кажется безобидным, может быстро умножить потребление compute, особенно если задачи каждый раз грузят большие images, поднимают соединения или обращаются к внешним сервисам на каждом запуске. Повторы — не бесплатная страховка. Это дополнительные запуски.
Ещё одна ошибка — повторять работу, которая провалилась из-за неправильного input. Если в CSV не хватает обязательного столбца, следующие пять попыток упадут по той же причине. Некоторые команды относятся к каждой ошибке как к временному сбою, даже когда задача совершенно ясно говорит, что данные плохие.
Команды также удаляют failed pods слишком рано. Им нужен чистый dashboard, поэтому они стирают доказательства до того, как кто-то посмотрит логи, exit code или последнее событие. Потом люди гадают, снова запускают задачу и снова платят, чтобы заново найти ту же проблему. Оставляйте неудачные запуски достаточно долго, чтобы из них можно было учиться.
Оповещения тоже создают проблемы. Некоторые команды page'ят на каждый failed pod. На первый взгляд это безопасно, но со временем приучает всех игнорировать pager. Одна бизнес-задача может создать несколько failed pods, прежде чем наконец завершится успешно или по тайм-ауту. Количество pod выглядит драматично, хотя влияние на бизнес может быть небольшим.
Перед тем как настраивать alerts, задайте несколько прямых вопросов:
- Завершилась ли бизнес-задача?
- Задача зависла или просто повторяется в нормальном limit?
- Сбой вызвали плохие данные?
- Логи растут быстрее, чем число задач?
Короткие задачи также могут скрывать расходы на storage. Команды следят за compute и забывают, что логи, артефакты и pull образов продолжают накапливаться. Иногда маленькие задачи стоят в лог-хранении больше, чем в CPU, потому что каждый retry снова и снова пишет один и тот же stack trace.
Если у вас много batch-задач, такие мелочи быстро складываются. Cap на повторы, простые проверки input и более спокойные alerts часто сокращают waste быстрее, чем ещё один раунд настройки cluster.
Короткий чеклист перед изменением настроек
Небольшие изменения в лимитах повтора и правилах очистки могут быстро сократить waste, но если гадать, можно и скрыть настоящие проблемы. Перед тем как что-то менять, решите, что вы хотите защищать в первую очередь: деньги, сроки доставки или нагрузку на support. У большинства команд важны все три пункта, поэтому короткий разбор сейчас экономит переделку потом.
Используйте этот чеклист для задач, которые запускаются каждый день, особенно для batch-работ, которые тянут данные, конвертируют файлы, отправляют отчёты или обращаются к внешним API.
- Начните с задач, которые могут быстрее всего сжечь деньги. Ищите запуски, которые стартуют часто, загружают большие images, используют много CPU или memory, либо на каждом retry обращаются к платным внешним сервисам.
- Разделите ошибки на две группы. Повторяйте короткие сетевые ошибки, временные rate limits и сбои nodes. Останавливайтесь на плохом input, сломанных credentials, отсутствующих файлах или ошибках в коде, которые будут падать одинаково каждый раз.
- Задайте понятное окно хранения для завершённых Jobs и pod. Держите их видимыми достаточно долго для отладки, но не настолько, чтобы старые объекты накапливались и путали людей.
- Решите, кто отвечает за alert, когда бизнес-работа зависает. Это должна быть команда, которая может устранить причину, а не просто заглушить страницу.
- Выберите метрики, которые будете смотреть после изменений, например успешные запуски, число retries на задачу, orphaned pods, среднее время выполнения и стоимость одного успешного запуска.
Простой тест помогает. Если ночной import обычно завершается за 12 минут, alert'ите, когда ни один успешный запуск не появился к бизнес-дедлайну. Это показывает, что работа зависла, а это важнее, чем просто число pod.
Что делать дальше
Не пытайтесь исправить все batch-задачи сразу. Выберите ту, которая будит людей, сжигает больше всего compute или падает так часто, что ей уже никто не доверяет. Одна шумная задача обычно уже показывает, тратит ли ваша retry policy деньги впустую.
Начните с небольшого набора изменений на неделю и оцените результат после одного полного цикла запуска:
- снизьте cap на повторы для этой задачи и посмотрите, что произойдёт
- добавьте автоматическую очистку завершённых и orphaned pods
- перепишите один alert так, чтобы он был завязан на пропущенный бизнес-результат, а не на общее число pod
Каждый шаг сокращает свой тип waste. Меньше retries — меньше повторных вычислений. Очистка pod делает cluster понятнее и снижает шум от storage. Alerts, ориентированные на бизнес, перестают гонять команду за безвредными перезапусками, пока реальная работа стоит на месте.
Возьмём простой случай: import отчёта обычно проходит со второй попытки, но раз в неделю ловит permission errors. При высоком cap на повторы задача может долбить одно и то же плохое состояние целый час. Снижение cap до двух или трёх попыток превращает тихую утечку денег в заметную проблему, которую можно исправить.
После этого сравните цифры до и после. Посмотрите на число retries, runtime и стоимость этой задачи за несколько дней. Если изменение помогло, повторите тот же подход на следующей шумной задаче.
Если вам нужен внешний взгляд, Oleg Sotnikov из oleg.is помогает стартапам и небольшим командам настраивать retry limits, правила очистки и дизайн alerts в рамках Fractional CTO и advisory по инфраструктуре. Иногда короткий разбор уже помогает увидеть waste, к которому команда просто привыкла.
Часто задаваемые вопросы
Почему одна неудачная Kubernetes-задача может так сильно увеличить счёт?
Каждый retry запускает новый pod и снова начинает начисление. Вы платите за pull образа, запуск, CPU, память, логи, сетевой трафик и иногда дополнительное хранилище, даже если задача быстро падает.
Какой limit на повторы подходит для batch-задач?
Для большинства одноразовых batch-задач лучше начинать с малого. backoffLimit 1 или 2 часто даёт достаточно попыток на краткий сбой, не заставляя платить за одну и ту же ошибку снова и снова.
Когда повторы действительно помогают?
Повторы полезны, когда проблема может исчезнуть сама, например при коротком сетевом тайм-ауте или временном лимите запросов. Останавливайтесь раньше, если задача падает из-за плохих данных, отсутствующих secret, неверных credentials или ошибки в коде, потому что следующий запуск упрётся в ту же стену.
Могут ли повторы вызвать autoscaling и увеличить расходы?
Да. Если повторы продолжают создавать новые pod, cluster может добавить nodes для работы, которая уже один раз провалилась. Так одна сломанная задача превращается в ещё большие расходы на вычисления без пользы для бизнеса.
Откуда берутся дополнительные расходы, кроме CPU и памяти?
Обычно рост идёт не только за счёт CPU и памяти. Свежие pod загружают образы, подключают storage, открывают сетевые пути и пишут логи, поэтому куча коротких сбоев может стоить больше, чем один обычный запуск.
Как очистить orphaned pods от job?
Если в вашей настройке есть TTL cleanup для завершённых Jobs, используйте его. Если нет, запустите небольшую периодическую очистку, которая удаляет старые Jobs и pod по возрасту, label, namespace и status.
Как долго держать failed pods?
В большинстве случаев успешные pod достаточно хранить лишь несколько часов. Failed pod обычно стоит держать 1–3 дня, чтобы инженеры успели посмотреть логи, а потом удалять, если только правила аудита или сложная ошибка не дают чёткую причину подождать дольше.
Нужно ли сохранять логи перед удалением старых pod?
Сначала сохраните логи, а потом удаляйте pod. Отправляйте stdout, stderr и статус задачи в вашу logging system, чтобы команда могла разбирать проблему позже, не держa старые объекты в cluster.
На что лучше alert'ить вместо количества pod?
Лучше alert'ить по бизнес-задаче, а не по общему числу pod. Один alert для задачи, которая не уложилась в окно завершения, работает лучше, чем поток страниц на каждый failed pod в одном и том же retry loop.
Что сделать в первую очередь, чтобы быстро сократить лишние расходы?
Выберите самую шумную задачу и меняйте по одному параметру за раз. Снизьте retry cap, добавьте автоматическую очистку завершённых pod и неделю наблюдайте за числом retries, временем выполнения и стоимостью успешного запуска.


