Как поэтапно модернизировать стек стартапа без бюджета на переписывание с нуля
Нужно модернизировать стек стартапа на скромном бюджете? Обновляйте авторизацию, биллинг и импорт данных по одному рубежу за раз, не замедляя выпуск новых функций.
Содержание
Почему переписывание с нуля тормозит небольшие команды
Полная перепись звучит аккуратно. Для небольшой команды это обычно превращается в две работы одновременно.
Старому продукту по-прежнему нужно внимание. Поддержка продолжает получать обращения. Ошибки всё еще нужно чинить. Отдел продаж всё так же просит интеграцию, которая закроет следующую сделку. И пока всё это происходит, той же команде нужно строить замену, переносить старые данные и разбираться с каждым странным краевым случаем, который нынешняя система собирала годами.
Такой разрыв быстро выматывает людей. Деньги часто заканчиваются раньше, чем новая система начинает казаться завершенной. Первые демо могут выглядеть лучше старого продукта, но в демо не видно странных деталей, от которых зависят реальные клиенты. Потом команды месяцами воссоздают поведение, которое, как им казалось, можно было просто оставить в прошлом.
Продуктовая работа не останавливается во время переписи. Биллинг всё так же ломается. Права доступа всё так же требуют обновления. Крупный клиент всё так же просит изменить админский доступ. Эти запросы отодвигают миграцию в сторону. Через пару недель команде снова приходится вспоминать, на чем она остановилась, прежде чем она сможет двинуться дальше.
Сроки срываются, потому что перепись скрывает объем работ до самого конца. Авторизация выглядит простой, пока не появляются сбросы пароля, истечение сессии, админские роли, журналы аудита и старые способы входа, которые всё ещё работают в продакшене. Биллинг кажется управляемым, пока не всплывают возвраты, неуспешные списания, налоги и смена тарифов. Импорт кажется легким, пока кто-то не загружает сломанный CSV с десятью годами плохих данных.
Со временем доверие падает. Основатели перестают верить оценкам. Инженеры устают дважды собирать одни и те же идеи. Клиенты слышат, что исправление будет «скоро», и начинают планировать работу с учетом задержек.
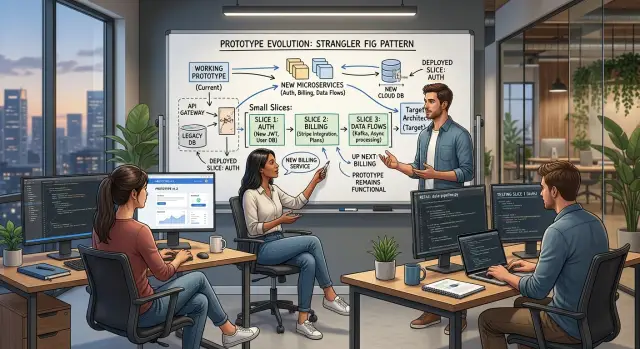
Небольшие команды обычно получают лучший результат, если меняют по одному рубежу за раз. Узкое обновление можно выпустить, проверить в деле и снизить риск до следующего изменения. Такой подход также хорошо совпадает с тем, как обычно работает Oleg Sotnikov: держать поставку в движении, не расползаться по объему и не ставить компанию на одну огромную замену.
Сначала выберите один рубеж
Команды застревают, когда пытаются одновременно менять авторизацию, биллинг и импорты. Все эти области близко связаны с пользователями и выручкой, но ломаются по-разному. Одно сфокусированное изменение дает реальную пользу и не останавливает остальную продуктовую работу.
Выберите рубеж, который чаще всего мешает выпускать продукт. Не смотрите на то, что кажется современным. Начните с того места, где команда теряет время каждую неделю.
Если проблемы со входом тормозят демо, поддержку и доступ админов, начните с авторизации. Если счета, продления или смена тарифов постоянно превращаются в аврал, начните с биллинга. Если новые клиенты не могут загрузить данные в продукт без ручной чистки, начните с импортов.
У хорошего первого рубежа есть несколько признаков. У него понятное начало и конец. За него может отвечать одна команда. Его можно протестировать, не затрагивая всё приложение. И старый путь можно оставить работать, пока новый доказывает свою надежность.
Число пользователей важно, но масштаб последствий важнее. Сломанный вход админа может затронуть меньше людей, чем вход обычного клиента, но при этом он способен заблокировать всю компанию. Неровный поток импорта может касаться только новых аккаунтов, но если каждая продажа зависит от того, что настройка сработает, его нужно поднимать выше в списке.
Лучшие рубежи легко описать одним предложением. Авторизация — это когда пользователь входит в систему и получает действующую сессию. Биллинг — это когда меняется тариф и система правильно это фиксирует. Импорт — это когда файл загружается, а на выходе получаются чистые записи. Если задачу нельзя описать так просто, рубеж всё еще слишком широкий.
Допустим, у вас небольшой SaaS-продукт, и инженеры каждую неделю тратят часы на исправление сломанных CSV-загрузок для новых клиентов. Биллинг устарел, авторизация запутана, но импорты прямо сейчас мешают выручке. Начните с них. Постройте новый путь импорта, протестируйте его на небольшой группе и пока не трогайте всё остальное, пока он не заработает.
Именно так на практике выглядит поэтапная модернизация. Один рубеж, один владелец, один выпуск, который можно проверить.
Нарисуйте текущий поток на одной странице
Прежде чем трогать код, нарисуйте текущий поток на одной странице. Держите схему простой. Неровная, но честная карта лучше, чем красивая диаграмма, которая скрывает болезненные места.
Начните с первого запроса и проследите его до самого сохранения данных. Если пользователь регистрируется, пройдите все шаги. Форма отправляет данные, приложение проверяет авторизацию, сервис биллинга создает клиента, бэкенд записывает данные, а задача может позже синхронизировать их в другую базу. Запишите каждый переход, даже тот, который кажется очевидным.
Небольшие команды часто пропускают работу, которая происходит за пределами основного приложения. Обычно именно там и скрываются сюрпризы. Отметьте каждый внешний сервис, каждый вебхук, каждую запланированную задачу, каждую загрузку из таблицы и каждое ручное исправление, которое кто-то делает в пятницу после обеда, когда что-то ломается.
На странице должны быть ответы на четыре простых вопроса:
- Что запускает поток?
- Кто или что трогает данные следующим?
- Куда в итоге попадают данные?
- Что происходит, если один из шагов ломается?
Особенно внимательно смотрите на изменения данных. Отмечайте каждый участок, где поле переименовывают, делят, округляют, меняют формат или копируют в другую систему. Также отмечайте, где меняется владелец данных. Email клиента может сначала появиться в вашем приложении, потом перейти в сервис авторизации, а затем стать биллинговыми данными где-то еще. Именно там чаще всего и начинаются дубликаты и трудные для поиска ошибки.
Поместите откат на ту же страницу, а не в чью-то голову. Если выпуск не пройдет, кто переключит трафик обратно? Какую очередь нужно поставить на паузу? Какие данные нужно почистить? Запишите ответ рядом с тем шагом, который может сломаться. Если нельзя описать откат в одной-двух строках, изменение, скорее всего, всё еще слишком большое.
Это упражнение особенно полезно, когда основатель работает с Fractional CTO. Оно превращает расплывчатое знание о системе во что-то, что вся команда может видеть и использовать. Иногда карта показывает, что настоящая проблема вовсе не в старом коде авторизации. Это может быть CSV-скрипт, которому никто не доверяет, биллинговый вебхук без плана повторной попытки или ручная заплатка, которую никто не записал.
Когда поток виден, можно заменить одну часть, не гадая, что она сломает.
Обновляйте по маленьким релизам
Большие замены на доске выглядят быстрыми. В продакшене они редко ощущаются так же. Держите старый путь живым и меняйте по одному краю за раз.
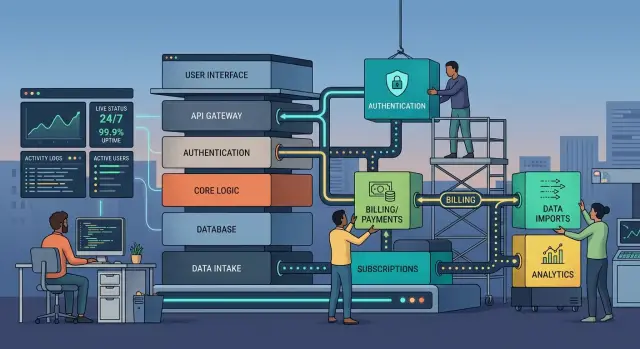
Сначала поставьте перед старым кодом стабильный интерфейс. Это может быть API-роут, потребитель очереди или тонкая внутренняя обертка. Остальная часть приложения должна обращаться к одному и тому же контракту, пока вы меняете то, что находится внутри.
Затем постройте новый сервис за тем же контрактом. Если вы заменяете авторизацию, поток входа должен возвращать ту же форму сессии. Если вы заменяете биллинг, приложение по-прежнему должно получать тот же статус подписки и те же события вебхуков. Продуктовой команде не нужен второй раунд изменений интерфейса только потому, что изменилась внутренняя проводка.
Осторожный запуск обычно прост:
- Оставьте старый путь по умолчанию.
- Отправьте небольшой кусок трафика на новый путь.
- Сравните оба результата для одних и тех же запросов.
- Следите за логами, неудачными заданиями и обращениями в поддержку.
- Увеличивайте трафик только тогда, когда проверки остаются чистыми.
Этот небольшой кусок очень важен. Начните с внутренних пользователей, тестового клиента или одной группы клиентов с низким риском. Часто достаточно и 5 %. Вам не нужен громкий запуск. Вам нужно доказательство, что новый путь ведет себя так же — или лучше — под реальной нагрузкой.
Именно на сравнении команды чаще всего экономят не там, где нужно. Проверяйте результат, но также проверяйте время выполнения, повторы, краевые случаи и то, что сообщают пользователи. Новый конвейер импорта может завершиться успешно, но тихо потерять один столбец. Новый сервис биллинга может правильно списать деньги, но не обновить лимиты тарифа. Логи поймают часть проблем. Остальное поймает поддержка.
Команды, которые работают экономно, часто предпочитают именно этот метод, потому что откат остается простым. Когда выпуск проходит, переведите на него чуть больше трафика. Когда не проходит — остановитесь, исправьте проблему и попробуйте снова. В моменте это может казаться медленнее. На практике это спасает от месячной уборки после неудачного переключения.
Авторизация, биллинг и импорты требуют разного подхода
Авторизация быстро подрывает доверие. Биллинг бьет по выручке. Импорты портят качество данных. Один план миграции не подходит для всех трех областей.
Когда вы меняете авторизацию, сохраняйте правила токенов, длину сессии, время обновления и поведение выхода из системы, пока новый путь не докажет свою надежность. Пользователь переживет медленную страницу один день. Но он не потерпит случайных выходов из аккаунта или неудачного входа с телефона после обновления браузера. Если вам нужна новая логика токенов, выпускайте ее под флагом и сразу следите за сбоями входа.
Биллингу нужна еще более осторожная работа, потому что маленькая ошибка либо продолжает списывать деньги, либо вообще останавливает списания. Сохраните полную историю подписок, счетов, повторных попыток, возвратов и неудачных платежей до того, как переключитесь на другого поставщика или перепишете логику биллинга. Многие команды копируют только «счастливый путь» и пропускают неприятные случаи: карта, которая не прошла вчера, повторная попытка, запланированная на завтра, или пользователь в льготном периоде. Эти случаи важны.
Импортам нужна защита другого типа. Не давайте сырым файлам писать прямо в основные данные. Помещайте загрузки в промежуточную зону, проверяйте столбцы и форматы и блокируйте плохие строки до того, как что-то станет постоянным. Один сломанный CSV за минуты может создать сотни неверных записей. Короткий экран проверки скучный, но разбор ошибок еще хуже.
Во всех трех областях нужен план на повторяющиеся события и частичные сбои. Платежные вебхуки могут прийти дважды. Задачи импорта могут остановиться на середине. Пользователь может нажать загрузку еще раз, потому что первый индикатор загрузки завис. Сделайте повторяющиеся события безопасными, храните понятный статус и заранее решите, когда команде нужно повторить попытку, откатить изменение или оставить результат как есть.
Поддержка должна узнать о выпуске раньше пользователей. Дайте ей короткую заметку: что пользователи могут заметить, какие ошибки ожидаемы во время переключения и когда по тикету нужна помощь инженеров.
Такая подготовка снимает путаницу. И еще она делает рискованный выпуск намного более управляемым.
Простой пример SaaS
Представьте небольшую B2B SaaS-команду, у которой одна повторяющаяся проблема. Клиенты загружают CSV-файлы с заказами, контактами или складскими остатками, а задача импорта каждую неделю ломается на каком-нибудь краевом случае, который старый код никогда не умел нормально обрабатывать. Команда не может остановить выпуск новых функций ради полной переписи, потому что отделу продаж по-прежнему нужны новые отчеты, а клиенты всё так же просят изменения в продукте.
Поэтому команда выбирает один рубеж и оставляет остальное как есть. Вместо того чтобы трогать все части приложения, она прячет старый импортёр за одним внутренним endpoint с понятным входом и выходом. Звучит как мелочь, но это многое меняет. Теперь приложение обращается к одной стабильной двери, даже если код за ней потом изменится.
Дальше команда строит новый импортёр, который использует тот же контракт. Он лучше разбирает файлы, логирует каждый шаг и возвращает более понятные ошибки. Никто не переводит всех клиентов сразу. Сначала команда пускает через новый путь один сегмент, например более новые аккаунты с более простым форматом файлов или один тариф с небольшим объемом загрузок.
Теперь оба пути можно сравнивать на реальных файлах, а не на догадках. Для каждой загрузки команда проверяет количество строк, неуспешные строки, обработку дублей и общее время обработки. Если старый импортёр говорит, что в файле было 9 842 валидные строки, а новый — 9 701, выпуск останавливают, пока кто-нибудь не найдет разницу. Такое сравнение бок о бок потом сильно экономит нервы.
Продуктовая работа всё это время продолжается. Работа над функциями идет дальше, потому что изменение импорта находится за одним рубежом и не расползается по всей кодовой базе. Поддержке тоже проще, потому что команда видит, где и почему упал каждый файл.
После двух спокойных циклов выпуска решение становится легче. Ошибки остаются низкими, время обработки — стабильным, а обращения в поддержку — редкими. Команда убирает старый путь импорта, оставляет endpoint и переходит к следующему слабому месту.
Ошибки, которые замедляют работу
Команды часто теряют время по простой причине: они перестают относиться к изменению как к операции и начинают относиться к нему как к уборке. Именно тогда сфокусированное обновление превращается в побочную работу без финальной точки.
Одна распространенная ошибка — переписывать соседние системы только потому, что они тоже выглядят старыми. Вы начинаете с авторизации, а потом кто-то хочет переделать роли пользователей, привести в порядок админ-панель и переименовать половину таблиц. Объем быстро растет, а исходная проблема остается на месте.
Другая ошибка — работать вслепую после запуска. Если пропустить метрики и полагаться на чутье, проблему обычно первой найдет клиент. Для авторизации смотрите на успешность входа и сбои сброса пароля. Для биллинга — на завершение оплаты, неуспешные списания и обращения в поддержку. Для импортов — на время выполнения, количество ошибок и дубликаты записей.
Когда вы меняете модели данных и пользовательские сценарии в одном и том же спринте, это тоже создает путаницу. Если вы одновременно переходите на нового поставщика биллинга и переделываете страницу цен, вы не поймете, что именно снизило конверсию. Держите одновременно только один подвижный элемент. Это ощущается медленнее, но зато экономит дни догадок.
Работу по дозаполнению старых данных игнорируют чаще, чем следовало бы. Команды откладывают чистку старых данных до недели переключения, а потом обнаруживают пропущенные поля, неверные временные метки или записи, которые не совпадают с новым форматом. Задача по дозаполнению — это часть миграции, а не фоновая административная работа.
Запасной путь важнее, чем многим кажется. Если убрать его слишком рано, один скрытый краевой случай может заблокировать вход, остановить продления или сломать импорты для целого сегмента клиентов. Оставьте старый маршрут на месте, пока новый не выдержит реальный трафик и грязные случаи, а не только демонстрацию в staging.
Безопасный шаблон прост: обновите один рубеж, измерьте результат, заранее дозаполните данные, некоторое время держите старый путь живым и убирайте его только после того, как показатели останутся стабильными.
Такая дисциплина помогает выпускать изменения, пока стек меняется под капотом.
Быстрые проверки перед каждым выпуском
Маленькие релизы помогают только тогда, когда вы быстро замечаете проблему. Перед тем как выкатывать изменение в авторизацию, биллинг или импорты, проверьте старый и новый путь на одном и том же входе и сравните результат. Страницы могут немного отличаться. Результат должен совпадать.
Эта проверка должна включать побочные эффекты, а не только то, что видно на экране. Если пользователь входит в систему, убедитесь, что запускается правильная сессия, открывается правильный аккаунт и не появляются лишние записи. Если клиент платит, убедитесь, что есть один счет, одно списание и одно письмо. Если запускается импорт, проверьте количество строк, пропущенные строки и сообщения об ошибках.
Короткая предрелизная проверка обычно ловит именно те сбои, которые больше всего подрывают доверие:
- Прогоните один тест старым путем и один — новым на одном и том же пользователе или образце файла.
- Посмотрите логи на предмет повторных попыток, тайм-аутов, дублирующихся событий вебхуков и повторяющихся задач.
- Сообщите поддержке окно выпуска, что пользователи могут заметить и какие симптомы означают «откатываемся сейчас».
- Проверьте, что переключатель отката работает через конфигурацию, маршрутизацию или флаг без выпуска нового кода.
- Пройдите один реальный пользовательский сценарий от начала до конца, а не только измененный экран.
Изменения в биллинге требуют особого внимания. В приложении поток оплаты может выглядеть нормально, а логи показывают вторую попытку списания после тайм-аута. Ошибки авторизации часто проявляются тише. Пользователь может войти, а потом застрять в цикле перенаправления или потерять доступ к нужному рабочему пространству. Изменения импорта часто проходят небольшие тесты, но ломаются на грязных реальных файлах с пустыми ячейками, странными датами или дублирующимися ID.
Шаг с поддержкой важен, потому что он сокращает путь к ответу. Если поддержка знает окно выпуска и вероятные симптомы, она сможет за минуты отличить проблему релиза от обычной ошибки, вместо того чтобы гонять клиента между командами.
Используйте один реальный сценарий каждый раз. Выберите настоящий путь, который проходит клиент: зарегистрироваться, подтвердить email, начать пробный период, оплатить, загрузить данные и увидеть результат. Если этот путь работает чисто, выпуск, вероятно, готов. Если где-то он выглядит шатко, подождите и сначала исправьте это.
Что делать дальше
Начните с одного рубежа и задайте ему двухнедельный срок. Выберите участок, который чаще всего болит и затрагивает меньше всего других систем. Для одной команды это может быть вход в систему. Для другой — передача в биллинг. Для третьей — CSV-импорт, который каждую неделю создает обращения в поддержку.
Если объем не помещается в две недели, уменьшите его еще раз. Небольшая победа, которая уходит в прод, лучше, чем умный план, который месяц лежит в документе.
Прежде чем кто-то начнет писать код, определите успех простыми словами, чтобы продукт, поддержка и финансы могли прочитать это за минуту:
- Пользователи могут пройти путь без ручной помощи.
- Команда может измерять ошибки и отказы уже в первый день.
- Финансы по-прежнему могут сопоставлять списания, возвраты или счета.
- Старый путь остается доступным, пока новый не докажет стабильность.
Этот короткий список решает сразу две задачи. Он не дает инженерам расползтись в большую перепись и дает неинженерам понятный способ одобрить изменение.
Рано поделитесь планом с теми, кто первым почувствует перемены. Продукт может подтвердить влияние на клиентов. Поддержка может указать на те случаи, о которых люди действительно сообщают. Финансы могут заметить проблемы с биллингом и отчетностью еще до того, как они затронут реальные аккаунты. Обзор на 20 минут сейчас может сэкономить неделю уборки позже.
Дальше следующий шаг должен оставаться скучным и конкретным. Выберите одного владельца, одно окно выпуска и один план отката. Для большинства команд этого достаточно, чтобы начать двигаться.
Если команда застряла между «починить как есть» и «переписать всё», помочь может внешний взгляд. Oleg Sotnikov занимается такой последовательностью работ в роли Fractional CTO для стартапов и небольших компаний, а oleg.is — это место, где он описывает эту консультационную работу. Полезная часть здесь редко в большем количестве кода. Она в том, чтобы выбрать порядок, который снижает риск, пока продукт, поддержка и выручка продолжают двигаться.
Запишите двухнедельную цель на одной странице и поставьте дату. Затем выпустите самое маленькое изменение рубежа, которое ваша команда сможет измерить к концу этого срока.
Часто задаваемые вопросы
Как понять, что нам нужны этапы, а не полная перепись?
Выбирайте поэтапный подход, если продукту всё еще нужны еженедельные исправления, поддержка и изменения по запросу продаж. Если одна и та же команда не может поставить эту работу на паузу на несколько месяцев, лучше менять по одной части, а не переписывать всё приложение целиком.
Что модернизировать первым: авторизацию, биллинг или импорты?
Начните с того участка, который чаще всего тормозит выпуск или мешает выручке. Если срывы входа мешают демо и поддержке — начните с авторизации. Если ломаются изменения тарифов и продления — с биллинга. Если новые клиенты застревают на очистке CSV — с импортов.
Насколько маленьким должен быть первый рубеж?
Первый рубеж должен быть достаточно маленьким, чтобы за него могла отвечать одна команда и объяснить его в одном предложении. Хорошая проверка такая: вы понимаете, что запускает процесс, какой результат нужен и как откатиться, если что-то пойдет не так.
Нужно ли вообще сначала рисовать текущий поток?
Да. Сначала нарисуйте текущий поток на одной странице, а уже потом трогайте код. Добавьте внешние сервисы, вебхуки, запланированные задачи и ручные исправления, потому что именно эти скрытые шаги чаще всего и создают самые неприятные сюрпризы.
Можно ли продолжать выпускать функции во время миграции?
Да, если вы ставите перед старым кодом стабильный контракт и не трогаете остальную часть продукта. Тогда команда может продолжать делать продуктовую работу, пока вы заменяете один путь с теми же входными и выходными данными.
Как тестировать новый путь, не рискуя всеми пользователями?
Оставляйте старый путь по умолчанию и сначала отправляйте на новый небольшой набор пользователей. Сравнивайте результаты, время выполнения, повторы, логи и обращения в поддержку на одних и тех же реальных запросах, прежде чем увеличивать трафик.
Почему изменения в авторизации так рискованны?
Потому что ошибки авторизации быстро ломают доверие: пользователи замечают их сразу. Сначала держите стабильными правила сессий, поведение токенов, время обновления и выход из системы, а после релиза сразу следите за ошибками входа и проблемами с перенаправлением.
Что обычно идет не так при миграции биллинга?
В биллинге много неприятных крайних случаев, которые команды часто пропускают: повторы, возвраты, льготные периоды и вчерашние неуспешные списания. Сохраните историю, проверьте дублирующиеся события вебхуков и убедитесь, что приложение фиксирует одно списание, один счет и правильный статус тарифа.
Как поступать с CSV и изменениями импорта данных?
Не давайте сырым файлам писать прямо в основные данные. Сначала помещайте загрузки в промежуточный этап, проверяйте столбцы и форматы, показывайте понятные ошибки по строкам и делайте повторную загрузку безопасной, чтобы один плохой файл не превращался в большую уборку для команды.
Когда небольшой команде стоит привлечь Fractional CTO?
Просите внешнюю помощь, когда команда снова и снова мечется между латанием и переписыванием, или когда никто не может назвать порядок работ и план отката. Fractional CTO может сузить рубеж, показать реальный поток и удержать поставку в движении без превращения проекта в бесконечную перепись.