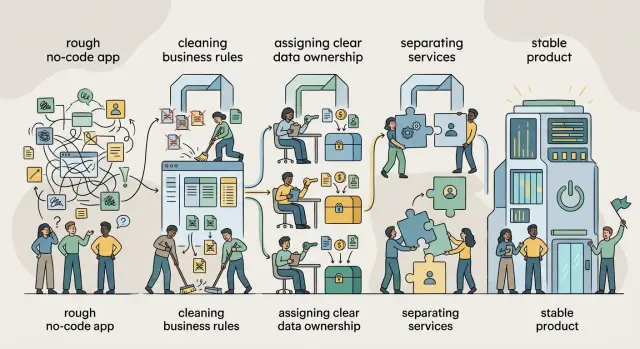
Плохие мастер‑данные: операционные затраты, которые возвращаются снова и снова
Некачественные основные данные превращают автоматизацию в бесконечную ручную уборку. Узнайте, как дубли клиентов, запутанные коды товаров и слабое владение данными съедают время и деньги.

Содержание
Почему плохие записи ломают повседневную работу
Плохие записи не остаются в таблице. Они проявляют себя в обычных задачах и превращают простую работу в медленную.
Клиент может существовать дважды: один раз как "North Star Foods" и снова как "Northstar Food Ltd." Отдел продаж считает их разными аккаунтами. Финансы выставляют счета одной записи и учитывают платежи по другой. Поддержка открывает тикеты под обоими именами, поэтому никто не видит полной истории в одном месте.
Это разделение меняет способ работы людей. Они перестают доверять системе и начинают проверять цепочки писем, старые счета и сообщения в чате перед любым действием. Пятиминутная задача превращается в двадцать минут. Команды называют это "просто перепроверкой", но это происходит весь день.
Данные по товарам ломаются так же. Продажи используют один код товара, финансы — другой, а поддержка помнит короткое имя из старой системы тикетов. Это один и тот же товар, но записи говорят обратное. Возвраты занимают больше времени. Отчеты по выручке кажутся неверными. Кто-то спрашивает: "Это действительно один и тот же товар?"
Как только возникает такое сомнение, отчеты теряют место в повседневной работе. Сотрудники экспортируют данные в побочные таблицы, добавляют ручные примечания и ведут частные таблицы сопоставлений, понятные только им. Система продолжает работать, но люди обходят её.
Плохие основные данные также делают автоматизацию менее полезной, чем кажется. Если рабочий процесс подтягивает дубли клиентов в биллинг, он быстрее отправит повторные напоминания. Если синхронизация передаёт путаные коды товаров из продаж в финансы, несоответствие распространится по другим инструментам. Работа не исчезает — она уходит дальше по цепочке, где её сложнее исправлять.
Вот почему плохие основные данные кажутся дорогими ещё до любых измерений. Люди тратят время на сопоставление имён, исправление отчётов, перепроверку заказов и объяснение странных итогов на совещаниях. Ничто из этого не создаёт бизнес — это ремонтная работа.
Хуже всего то, насколько это начинает казаться нормой. Как только команда ждёт, что данные будут неправильными, ручная очистка становится частью работы.
Где проявляются скрытые расходы
Плохие мастер-данные редко вызывают один драматический провал. Они создают десятки мелких задержек, которые люди проглатывают каждый день, поэтому стоимость легко не заметить.
Команда по заказам часто ощущает это первой. Клиент оформляет заказ под одним названием компании, а биллинг прикреплён к чуть другой записи. Прежде чем выставить счёт, кто-то проверяет адрес, налоговые данные, контактный email и историю оплат, чтобы решить, относятся ли записи к одному и тому же аккаунту.
Команды поддержки платят за ту же путаницу иначе. Агент ищет в CRM, в системе тикетов и в биллинге, а находит три профиля для одного клиента. Вместо решения проблемы за две минуты агент тратит десять, пытаясь понять, какая запись актуальна и каким заметкам можно доверять.
Закупщики сталкиваются с этим, когда коды товаров дрейфуют со временем. У одной позиции старый SKU в закупках, укороченное имя в учёте и метка поставщика в прошлых заказах. Повторный заказ должен занимать секунды, но кто-то редактирует названия, проверяет характеристики и подтверждает, что команда заказывает ту же деталь.
Финансы получают ту очистку, о которой никто не думал заранее. В конце месяца платежи не сходятся, кредиты остаются открытыми, и исключения накапливаются, потому что одна запись клиента или товара разбилась на несколько версий. Эти часы возвращаются при каждом закрытии месяца, даже если никто не вписывает их в бюджет.
Менеджеры видят ещё одну цену: разногласия в отчётах. Продажи считают один набор аккаунтов, поддержка видит другой, а финансы имеют свой итог. Когда числа не сходятся, люди перестают доверять отчетам и просят ручные проверки в таблицах.
Вот почему плохие основные данные продолжают стоить денег даже после запуска автоматизации. На бумаге процесс может идти быстрее, но исключения всё равно падают на чей-то стол. Пять дополнительных минут на заказ, тикет или повторную закупку выглядят несущественно по отдельности. За месяц это превращается в постоянную работу по очистке.
Простой пример из растущей компании
Представьте софтверную компанию из 25 человек, у которой только начинает расти отдел продаж. Продукт хорошо продаётся, все действуют быстро и допускают мелкие упрощения, кажущиеся безобидными.
Продажи импортируют лиды с вебинаров, сканов бейджей и старых email‑списков. Если менеджер не уверен, одинаковы ли "Anna Lee" с выставки и "A. Lee" из формы рассылки, он создаёт новую карточку клиента и идёт дальше.
Операции делают похожее с товарами. Официальный код годового плана может быть "PRO-ANNUAL", но люди вводят "PRO Y", "Annual Pro" или старое внутреннее прозвище — для экономии нескольких секунд в напряжённый день.
Пока никто не замечает. Заказы проходят. Счета отправляются. Беда начинается, когда биллингу нужно связать старые покупки, новые подписки, возвраты и историю поддержки.
Клиент пишет и просит возврат после двойного списания. Биллинг ищет по системе и находит три записи клиента, связанные с двумя email и одним названием компании. Одна запись имеет текущий код продукта, одна — старый код из импорта таблицы, а одна висит в CRM без биллингового ID.
Теперь на один возврат нужно три человека. Поддержка подтверждает, какой аккаунт действительно использует клиент. Финансы сравнивают счета в таблице. Кто-то из операций правит метки товара, чтобы биллинг мог отнести возврат к правильному плану. То, что могло занять пять минут, превращается в 40.
Команда пытается автоматизировать обходные процессы: напоминания о платежах, письма о неудачных списаниях и уведомления о продлении. Это помогает с чистыми записями. С грязными записями автоматизация создаёт лишнюю работу.
Одно напоминание уходит не на тот дубликат. Другому клиенту приходит уведомление о плане, которого у него уже нет, потому что старый код всё ещё живёт в биллинге. Сотрудники выгружают CSV, объединяют строки вручную, правят код, отправляют сообщение заново и где-то записывают исключение.
Так плохие основные данные становятся постоянным налогом. Автоматизация работает, но только после того, как люди снова и снова чистят одну и ту же кашу.
Как возникает этот беспорядок
Путаница редко начинается с одной большой ошибки. Чаще это дедлайн, таблица и фраза: "Почистим позже." Это одно упрощение превращается в ежедневную работу на месяцы.
Импорты часто — первое место, где появляются трещины. Команде нужно загрузить 20 000 клиентов или строк товаров перед запуском, поэтому они отключают проверки дублей, пропускают обязательные поля или принимают любой формат. Импорт проходит быстро. Очистка — нет.
Затем каждая команда начинает использовать свои правила именования. Продажи пишут "ACME Inc.", финансы — "Acme Incorporated.", поддержка укоротит до "ACME." Все три названия могут относиться к одному клиенту, но системы считают их разными. Коды товаров дрейфуют так же: одна команда использует "P-100", другая — "P100", а файл поставщика добавляет "P100-NEW."
Растущие компании часто застревают здесь, потому что после запуска никто не владеет мастер‑списком. Проектная команда задаёт первые правила и уходит. Новые сотрудники наследуют беспорядок и делают локальные правки, чтобы пройти день. Каждая правка помогает одному человеку и запутывает всех остальных.
Старые коды живут по странным причинам. Один отчёт в наследие всё ещё ждёт код прошлого года. Один экспорт клиентов нужен с прежним ID. Поскольку этот отчёт важен для кого‑то, бизнес поддерживает и старые, и новые значения в обращении. Каждая синхронизация и каждый новый инструмент снова и снова их переносит.
Шаблон обычно прост:
- Срочный импорт создаёт дубли клиентов.
- Команды по‑разному переименовывают одно и то же.
- Никто не утверждает одну официальную версию.
- Один старый отчёт блокирует очистку.
- Новое приложение копирует плохие значения повсюду.
Последний шаг делает проблему дорогой. CRM, биллинг, WMS и тенет служба поддержки могут идеально синхронизироваться и всё равно быть неверными. Хорошая автоматизация не исправит слабое владение данными: она разнесёт слабые правила быстрее, и тогда люди будут тратить утро на очистку, которой вовсе не должно было быть.
Лечите причину, а не симптом
Автоматизация сломанных записей просто перемещает работу по очистке дальше по цепочке. Если продажи, поддержка и финансы тянут данные из разных мест, каждая новая синхронизация создаёт лишнюю работу. Плохие мастер‑данные не остаются в базе — они проявляются в счетах, остатках, письмах о продлении и еженедельных отчётах.
Начните с записей, которые съедают больше всего человеческого времени. Обычно это дубли клиентов, неясные коды товаров или поля статуса, которые разные команды понимают по‑разному. Компания может тратить всего пять минут на каждое исключение, но 50 таких исключений в неделю незаметно съедают часы.
Выберите одну систему, которая владеет каждой записью клиента и каждой записью товара. Не каждое поле требует сложной политики. Держите правила простыми: один формат имен, один шаблон ID и один согласованный список статусов. Если товар списан — пометьте его одинаково везде. Если клиент сменил название — обновите главную запись, а не создавайте новую.
При очистке старых данных работайте небольшими партиями. Объедините 20 дублей, запишите причину слияния и проверьте следующий отчёт. Этот лог важнее, чем кажется: он превращает разовые правки в повторяемые правила, и следующая партия идёт быстрее и с меньшим количеством споров.
Те же правила применимы на краях: формы должны отвергать полузаполненные записи. Импорты должны помечать отсутствующие ID до загрузки. Синхронные задания должны останавливаться, когда записи не соответствуют согласованному формату. Если команды продолжают допускать плохие строки "только в этот раз", очистка кодов товаров станет постоянной обязанностью.
Рабочая последовательность проста:
- Найдите несколько типов записей, которые вызывают большинство исключений и жалоб.
- Выберите один источник для клиентов и один для товаров.
- Установите простые правила для названий, ID и значений статусов.
- Проводите слияния старых дублей малыми партиями и ведите короткий журнал решений.
- Проверяйте отчёты после каждого раунда и блокируйте те же ошибки на точках ввода.
Эта часть автоматизации не эффектна, но окупается быстро. Чистые входные данные снимают больше операционной боли, чем ещё один скрипт.
Кто владеет каждой записью и правилом
Плохие мастер‑данные обычно живут потому, что никто ими не владеет. Продажи правят имена клиентов, поддержка добавляет заметки, финансы правят биллинг, а продуктовая команда придумывает новые коды, когда застревает. Работа делается на неделю, а через месяц та же беда возвращается.
Назначьте одного владельца данных клиентов. Этот человек не обязан вручную вводить каждое изменение, но он должен иметь последнее слово по форматам названий, логике слияний, обязательным полям и критериям, когда запись считается новым клиентом, а когда — дублем. Если право принятия решения разделено между тремя командами, дубли будут расти.
То же для данных товаров. Один владелец должен утверждать новые коды, списывать старые и решать, как именуются варианты, наборы и региональные версии. Когда никто не контролирует список, очистка кодов становится ежемесячной привычкой, а не одноразовым исправлением.
Простое разделение работает хорошо:
- Владелец данных клиентов: определяет поля клиента, правила слияний и статусные правила аккаунта.
- Владелец данных товаров: утверждает коды товаров, правила именования и изменения категории.
- Операционный лидер: следит, чтобы отчёты, автоматизации и передачи между системами следовали этим правилам.
Сотрудникам также нужен простой способ сообщать о плохих записях. Сделайте это скучно и удобно: одна форма приёма, одна общая очередь или один отмеченный канал. Если люди должны гадать, куда отправлять проблему, они перестают её сообщать, и очистка ложится на того, кто заметил ошибку последним.
Правила утверждения не менее важны. Решите, кто может создать новый код, кто добавлять поле и кто менять определение поля. Даже небольшое изменение, например разделение одного поля "тип клиента" на три варианта, может сломать фильтры, счета и автоматизации.
Назначьте дату пересмотра, прежде чем всё снова дрейфанёт. Для динамичных команд — ежемесячно. Для более устойчивых — раз в квартал. Не ждите импорта с ошибками, паники в финансах или возмущённого клиента, чтобы выяснить, что правила сломаны.
Владение звучит скучно. Именно поэтому оно работает.
Ошибки, которые поддерживают цикл очистки
Новая синхронизация часто усугубляет проблему. Если имена клиентов, внутренние ID или коды товаров уже отличаются между системами, инструмент просто копирует рассогласование быстрее. Команды заняты, отчёты кажутся полнее, и кто‑то всё равно тратит пятницу на ручное сопоставление.
Ещё одна распространённая ошибка — позволять каждой команде хранить свою копию в таблице. Продажи хотят быстрый список, поддержка добавляет заметки в другой файл, финансы держат версию, согласованную со счетами. Через несколько месяцев никто не доверяет основной системе, потому что у каждой команды есть своя "лучше" версия.
Так плохие мастер‑данные превращаются в вечную очистку. В одной компании могут быть "Acme Ltd", "ACME Limited" и "Acme Europe" как три клиента. Они могут относиться к одному и тому же покупателю, но каждая команда видит свою версию и действует по‑разному.
Слияния записей также могут нанести новый вред, если никто не установил правил по истории. Оставить старый ID? Какой адрес оплаты считать главным? Переносить прошлые заказы на выжившую запись или оставить как есть? Если люди сначала сливают, а правила придумывают позже, они ломают аудит‑трейлы и путают финансы.
Странные случаи обычно остаются нетронутыми, пока дело не касается денег. Необычный SKU, клиент с двумя налоговыми ID, код товара с лишним нулём — такие записи выживают месяцами, потому что касаются лишь нескольких заказов сначала. Потом финансы закрывают период, итоги не сходятся, и начинается паническая очистка.
Несколько признаков, что цикл продолжается:
- Команды экспортируют данные, чтобы "почистить позже".
- Две системы используют разные ID для одной и той же записи.
- Люди сливают дубли по памяти, а не по правилам.
- Финансы находят исключения раньше, чем операции.
- Очистку записывают как квартальный проект.
Последняя ошибка — относиться к очистке как к весенней уборке. Эффект приятен неделю, а затем те же плохие входные данные создают ту же проблему заново. Данные требуют владения, правил именования и проверок в точке ввода или импорта. Если никто не владеет записью и правилом, следующая автоматизация только даст более аккуратно выглядящие дубликаты.
Короткий чеклист перед следующей автоматизацией
Прежде чем автоматизировать что‑то, остановитесь на десять минут и проверьте данные под этим процессом. Короткая пауза часто дешевле месяцев очистки.
Рабочий поток может двигать плохие данные быстрее, но не сделает их чистыми. Если дубли клиентов, смешанные коды товаров или свободные правила уже существуют, новая автоматизация будет ежедневно повторять ошибку.
Быстрая проверка:
- Проверьте, может ли один реальный клиент иметь только один активный ID. Старые записи могут оставаться для истории, но сотрудники должны знать, какая запись живая. Если два активных ID возможны, биллинг, поддержка и продажи разойдутся.
- Проверьте, имеет ли один товар только один продаваемый код. Команды часто хранят старые алиасы, внутренние SKU и канальные коды. Это приемлемо только если один код — продаваемый источник, а все остальные сопоставлены с ним.
- Проверьте, используют ли команды одинаковые названия статусов. Если продажи говорят "active", финансы — "open", а поддержка — "live", люди будут переводить это вручную. Автоматизации обычно ломаются на таком несоответствии.
- Проверьте, пересматривает ли кто‑то новые поля до запуска. Кажется, что лишнее поле безобидно, но оно создаёт новые места для конфликтующих значений. Один владелец должен утверждать поля, называть их ясно и решать, где хранится истина.
- Проверьте, могут ли сотрудники исправить ошибку в одном месте. Если нужно править пять систем, чтобы исправить один неверный адрес или код товара, процесс уже хрупок.
Эти проверки базовые, потому что проблемы тоже базовые. Компания может потратить недели на очистку кодов товаров, а затем потерять выигрыши из‑за новой формы с полем свободного текста без ревью.
Простое правило: каждый клиент, товар и статус нуждаются в одном доме, одном имени и одном владельце. Когда это ясно, автоматизация экономит время. Когда нет — люди становятся слоем интеграции, и это быстро становится дорого.
Что делать дальше
Выберите один еженедельный процесс, о котором люди жалуются без напоминаний. Ввод заказов, исправление счетов, обновления остатков или слияния CRM — хорошие стартовые точки: боль видна и легко посчитать.
Затем измерьте потери в течение двух недель. Отслеживайте, сколько часов люди тратят на сопоставление имён клиентов, исправление кодов товаров, повторное открытие тикетов и проверку, какая запись реальная. Добавьте стоимость задержек: просроченные счета, неверные отгрузки, пропущенные повторные контакты и недоверие к отчётам.
Простая табличка достаточна:
- Часы на ручные исправления
- Найденные дубли клиентов
- Совпадения кодов товаров
- Переработанные заказы, счета или тикеты
- Люди, вовлечённые в каждый цикл очистки
Не добавляйте ещё больше AI или workflow‑инструментов поверх плохих мастер‑данных с надеждой, что софт всё исправит. Автоматизация лишь быстрее повторяет ту же ошибку. Сначала почистите мастер‑записи, решите, какие поля важны, и удалите дубли и старые коды правилами, которые люди могут соблюдать.
Владение должно иметь имена, а не названия отделов. Один человек владеет правилами клиентских записей. Другой — правилами по товарам. Тимлид или операционный менеджер утверждают изменения, влияющие на downstream‑системы: биллинг, поддержку или учёт запасов.
Запишите эти правила, чтобы они пережили смену сотрудников. Держите их короткими. Опишите, когда можно создавать нового клиента, как работает слияние дублей, какой код товара официальный и кто подписывает изменение поля.
Если команда уже живёт в ручной очистке, внешняя помощь может сэкономить недели впустую. Олег на oleg.is работает с компаниями по AI‑first операциям и поддержке Fractional CTO; такой обзор потоков данных естественен для этой работы. Практический план очистки часто полезнее, чем покупка ещё одного инструмента.
Первая победа не обязательно должна быть большой. Если один цикл очистки экономит шесть часов в неделю и останавливает ошибки в счётах, люди это быстро заметят. Тогда следующий шаг легче утвердить и сложнее проигнорировать.
Часто задаваемые вопросы
Что считать master-данными?
Основные (master) данные — это общие записи, которыми команды пользуются в разных инструментах: аккаунты клиентов, коды товаров и статусы. Когда эти записи расходятся, команды начинают вручную исправлять ошибки.
Почему дубли записей клиентов создают столько лишней работы?
Дубли разбивают историю одного клиента на несколько записей. Sales, финансы и поддержка тогда проверяют письма, счета и заметки вручную перед любым действием, поэтому простые задачи занимают намного больше времени.
Почему автоматизация не решает проблему плохих мастер-данных?
Автоматизация просто распространяет те же неверные значения быстрее. Если исходная запись неверна, поток отправит неправильный счет, напоминание или отчет, не исправив основную проблему.
С чего стоит начинать очистку?
Начните с того, что вызывает наибольшее количество исключений. Обычно это дубли клиентов, путаные коды товаров или поля статуса, которые разные команды используют по‑разному.
Нужен ли единый источник правды для клиентов и товаров?
Да. Выберите одну систему, которая владеет каждой карточкой клиента, и одну — которая владеет карточкой товара. Остальные инструменты могут синхронизироваться с этим источником, но не должны придумывать собственные версии правды.
Как обращаться со старыми кодами товаров?
Держите один официальный продаваемый код и сопоставляйте к нему старые псевдонимы. Списывайте старые коды целенаправленно, а не позволяйте командам вводить то, что им удобнее.
Кто должен отвечать за правила очистки данных?
Назначьте реального человека, а не отдел, ответственным за правила очистки. Этот человек решает форматы названий, логику слияний, обязательные поля и критерии, когда запись считается новой, а когда — дублем.
Стоит ли объединять всё в один большой проект?
Делайте по‑этапно. Сливайте ограниченное число дублей, фиксируйте причину слияния и проверьте отчеты после каждого раунда.
Какие проверки добавить перед вводом новых данных?
Блокируйте плохие данные на входе: формы должны отклонять незаполненные записи, импорты — помечать отсутствующие ID, а синки — останавливаться, если формат нарушен.
Когда имеет смысл обратиться за внешней помощью?
Если команда каждую неделю вручную исправляет одни и те же вещи, отчеты постоянно не сходятся или нет договоренности по владельцам — пора привлекать внешнюю помощь. Fractional CTO или опытный советник может установить правила, сопоставить системы и остановить петлю вечной очистки.