План восстановления после пропущенного релиза для перезагрузки инженерной команды
Практический план восстановления после пропущенного релиза: сокращает объём, убирает блокировки и устанавливает правила принятия решений, чтобы команда могла выпустить продукт без дополнительных переработок.

Содержание
Что ломается после пропущенного релиза
Пропущенный релиз редко проваливается в одном месте. Он меняет представления команды о том, что реально, что важно и что ещё можно выпустить.
После сдвига даты люди часто остаются с прежним дедлайном в голове и прежним объёмом на доске. Продукт всё ещё требует полный набор фич. Инженерия всё ещё пытается сохранить всё. План говорит одно, ежедневная работа — другое, и путаница распространяется быстро.
Обычно отсюда и начинается восстановление. Проблема не только в самой задержке. Проблема в том, что никто публично не перезагрузил план.
Приостановите суету и назовите настоящую цель
Когда релиз сдвигается, команды часто реагируют, поднажав ещё сильнее. Это обычно только усугубляет следующую неделю. Работа продолжается, новые запросы продолжают появляться, и никто не может сказать, что должно выйти первым.
Начните с короткого окна перезагрузки. Заморозьте новые запросы на фичи на пару дней. Не обещайте лишних исправлений, если они не блокируют релиз. Это может казаться медленным, но часто это самый быстрый ход, потому что останавливает накопление задач.
Затем напишите одно предложение, которое определяет релиз. Держите его простым и проверяемым. Сильный вариант звучит так: «Этот релиз позволяет текущим клиентам создавать счета и отправлять их без ручных обходов.» Слабый вариант: «Этот релиз улучшает биллинг.» Если предложение расплывчато, объём снова разрастётся.
Также нужен один человек с окончательным словом по объёму. Не комитет. Не ветка в чате. Назначьте одного владельца — обычно продуктовый лидер, основатель или CTO — и сообщите это всем. Инженерам не стоит терять полдня на споры о том, достаточно ли мала просьба, чтобы втиснуть её в релиз.
Простой фильтр помогает. Оставляйте работу, которая требуется для выполнения предложения о релизе. Рассматривайте работу, которая явно снижает риск выхода. Переносите опционные вещи. Обрежьте всё, что никто не может объяснить.
Скажите команде точно, что изменилось, почему это изменилось и что теперь относится к следующему релизу. Поместите это сообщение в одном месте, простым языком. После пропущенной даты общая цель важнее мотивационных речей или ещё одной ночи сверхурочной работы.
Сократите объём, пока не останется один рабочий срез
После срыва многие команды совершают одинаковую ошибку. Они оставляют почти всё в спринте и надеются, что дополнительные усилия закроют пробел. Это редко работает. Более быстрый выход — уменьшить релиз до одной ясной цели и одного рабочего пути.
Сложите все открытые элементы на одной странице: баги, правки дизайна, QA, копирайт, аналитика, миграции, админские инструменты и все поздние идеи, которые просочились. Если работа разбросана по тикетам, чату и чьей‑то памяти, никто не сможет аккуратно её отрезать.
Большинство команд режут слишком мягко. Они убирают пару очевидных лишних вещей, а затем оставляют все сложные части. Восстановление работает лучше, когда план становится строгим. Если пользователи не могут получить главный результат в первый день, элемент, вероятно, стоит перенести.
Что остаётся в объёме
Оставляйте работу, которая позволяет пользователю начать и завершить основную задачу. Оставляйте работу, которая предотвращает провал на этом пути. Оставляйте юридические, биллинговые или поддержочные задачи, которые блокируют реальное использование. Перенесите полировку, редкие настройки и малоиспользуемые дополнения в следующий релиз. Если задача слишком велика — разбейте её на первую версию и доработку.
Простой пример делает это понятнее. Если вы запускаете инструмент отчётности, на день один может хватить регистрации, одного источника данных, одной панели и одного экспорта. Права пользователей, сложные фильтры, white‑label и идеальная мобильная верстка могут подождать. Пользователям обычно важнее получить первый полезный результат, чем видеть все запланированные функции.
Запишите каждое исключение в одном месте. Назовите элемент, объясните, почему он перенесён, и дайте ему бакет для следующего релиза. Это важно, потому что вырезанная работа любит пробираться обратно в спринт через боковые разговоры и благие намерения.
После того как вы записали сокращения — защищайте их. Если кто‑то хочет вернуть задачу, он должен убрать что‑то другого аналогичного объёма. Это правило сохраняет стабильность среза релиза.
Маленькое не значит слабое. Это значит, что команда может закончить, протестировать и объяснить то, что идёт в релиз, без догадок.
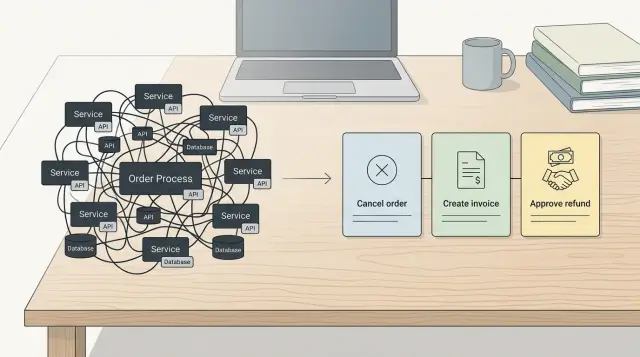
Уберите блокеры в цепочке зависимостей
Команды часто теряют ещё неделю после срыва, потому что продолжают давить на задачи, которые всё ещё не могут выйти. Одно зависшее согласование или ненадёжная интеграция может остановить десять других работ. Поместите всю цепочку на одну страницу, чтобы все видели, что стоит между «почти готово» и реальным релизом.
Начните со шагов вне самой сборки: внутренние согласования, интеграции третьих сторон, недостающие данные или контент, доступы к аккаунтам, действия поставщиков и ответы поддержки. Держите формулировки простыми. Если провайдер платежей должен одобрить аккаунт перед тестированием оплаты — запишите это. Если партнёр не прислал фид продуктов — запишите и это.
Затем выберите блокер, который замораживает больше всего работы. Обычно его стоит исправлять в первую очередь. Юридическое согласование, которое держит ценообразование, биллинг и письма для релиза, важнее трёх мелких багов на одном экране.
У каждого блокера должен быть один владелец и одна дата. Не давайте это «команде». Дайте это конкретному человеку, который будет преследовать проблему, обновлять доску и быстро поднять флаг, если срок сдвинется. Совместное владение звучит вежливо, но обычно означает, что никто не действует.
Если зависимость выглядит хрупкой — замените её ручным шагом для первого релиза. Это часто самый быстрый сброс. Человек может загрузить CSV, проверить записи вручную, отправить счета вручную или включить аккаунты для первых 20 клиентов. Это не идеально, но снимает затор.
Проверяйте блокеры каждый день
Проверяйте статус блокеров ежедневно и держите проверку короткой. Задавайте три вопроса: что изменилось, что всё ещё застряло и что кто‑то сделает сегодня.
Именно здесь план восстановления становится реальностью. Как только команда видит несколько внешних шагов, которые контролируют дату, люди перестают догадываться и начинают чистить путь.
Установите правила принятия решений, которыми команда действительно будет пользоваться
После срыва релиза большинству команд не нужно больше усилий. Им нужны правила, которые сокращают ежедневные споры. Перезагрузка распадётся, когда каждое изменение кажется срочным, а никто не знает, кто может дать добро или запрет.
Начните с объёма. Один человек должен утверждать изменения объёма, и все должны знать, кто это. Если трое людей могут добавлять работу, объём растёт в частных разговорах и к пятнице план ломается.
Целенаправленно держите небольшое число задач в работе. Если у каждого инженера по несколько активных задач, передачи становятся грязными, и блокеры скрываются. Простое ограничение работает лучше: одна основная задача на человека и одна мелкая доработка, если нужно. Это кажется строгим, но задержки проявляются раньше.
Блокерам тоже нужен таймер. Если разработчик задаёт вопрос по поведению продукта, доступу к данным, дизайну или другой команде, кто‑то должен ответить в течение одного рабочего дня. Ожидание три дня за «да/нет» — это способ превратить двухчасовую задачу в неделю дрейфа.
Держите текущий план, статус и изменения в одной доске. Не разбивайте это между чатом, документами и памятью. Если задача меняется, обновите доску в тот же день. Если задача блокирована, отметьте блокер простыми словами, чтобы никто не догадывался.
Несколько правил обычно закрывают большую часть хаоса:
- Только назначенный владелец может утверждать новый объём или менять приоритеты.
- У каждого человека небольшое количество активной работы.
- Продукт и инженерия отвечают на вопросы по блокерам в течение одного рабочего дня.
- Команда поднимает риск после второго срыва, а не после недели надежд.
Это последнее правило важнее, чем большинство признаются. Команды часто ждут пятого сигнала, потому что хотят избежать шума. К тому моменту дата уже вымышленна. Поднимите тревогу при втором промахе, проверьте причину и либо сократите объём, либо примите решение, либо уберите зависимость.
План перезагрузки на 7 дней
Перезагрузка работает лучше, когда неделя тиха, а не героична. Никаких спасательных бросков, никаких новых фич, никаких долгих споров. Выберите один срез релиза, назначьте владельцев, уберите самый большой блокер и протестируйте продукт так, как будут пользоваться им клиенты.
- День 1: Заблокируйте самую маленькую версию, которая может выйти. Дайте каждой задаче владельца. Если над задачей работают двое, никто её не владеет.
- День 2: Уберите единственный блокер, который замедляет всех остальных. Это может быть сломанная интеграция, недостающий доступ или решение от продукта/руководства.
- День 3: Завершите основной пользовательский путь от начала до конца. Пользователь должен зарегистрироваться, выполнить основное действие и увидеть результат без ручной помощи.
- День 4: Протестируйте на реальных аккаунтах, с реальными данными и обычными правами пользователя. Фейковые данные скрывают проблемы. Админский доступ скрывает ещё больше.
- День 5: Почините только те проблемы, которые блокируют релиз. Мелкие замечания по UI и уборка — в следующий цикл.
- Дни 6 и 7: Сверьте дату с вашими правилами принятия решений. Если продукт не проходит правила — сдвигайте дату и держите объём фиксированным.
День 3 — где команды часто соскальзывают. Кто‑то просит ещё одну настройку, ещё один крайний случай, ещё одну полировку. Отказывайте. Если основной путь всё ещё шаток на день 3, объём всё ещё слишком велик.
Используйте простые правила запуска. Основной путь работает. Саппорт может его объяснить. Мониторинг на месте. Команда знает, кто решает проблемы в день релиза. Если что‑то из этого отсутствует — вы не готовы.
Такая простая неделя может казаться слишком обычной. Это обычно хороший знак. После срыва побеждает скучная работа.
Простой пример небольшой продуктовой команды
Шестеро в SaaS-команде пропускают релиз нового биллингового потока. Они запланировали слишком много сразу: карточные платежи, ретраи, продвинутые отчёты, кастомные форматы счетов и синхронизацию с внешним финансовым инструментом. В финальную неделю копятся баги, документация для поддержки не готова, и никто не может договориться, что должно выйти первое.
Они перестают считать проект одной связкой. Команда записывает одну цель релиза: клиент может ввести данные карты, его спишут, и он получит корректный счёт. Если задача не поддерживает этот путь — она выносится из релиза.
Это решение обрезает больше, чем ожидали. Продвинутые отчёты уходят в следующий цикл. Кастомные форматы счетов — тоже. Они полезны, но не блокируют оплату клиента. Один инженер говорит, что синхронизация с финансами требует ещё недели тестов, поэтому команда убирает её и использует ручный экспорт первую неделю. Немного неаккуратно, но безопасно и понятно.
Основатель также меняет одну привычку, которая всё портило. Он перестаёт ежедневно менять объём в чате. Новые идеи идут в отдельный список, и команда смотрит их после релиза. Это правило быстро успокаивает комнату: инженеры перестают догадываться о завтрашних изменениях и начинают завершать работу.
К середине недели работа выглядит меньше и реальнее. Один чинит форму оплаты. Другой тестирует неудачные списания и письма о ретраях. Третий проверяет суммы в счётах и налоговые правила. Тимлид каждый день фиксирует три вопроса: может ли клиент заплатить, видит ли команда, когда платеж не прошёл, и справится ли поддержка первую неделю без дополнительных инструментов?
Они сначала выпускают путь оплаты. Клиенты могут купить, финансы сверять через ручной экспорт, у саппорта короткий плейбук по распространённым проблемам. Отчёты, кастомные шаблоны и полная интеграция с поставщиком выходят позже.
Именно так на практике часто выглядит восстановление: меньше драм, меньше движущихся частей и один рабочий путь, который заслуживает расширения.
Ошибки, которые приводят ко второму срыву
Команды часто срывают дедлайн второй раз по тем же причинам. Они воспринимают перезагрузку как проблему мотивации и пытаются её решить дополнительными усилиями. План ломается снова, когда люди продолжают менять работу, но ведут себя так, будто план стабильный.
Первая ловушка — дрейф объёма через маленькие сообщения. Основатель отправляет заметку, продажи добавляют просьбу одного клиента, поддержка просит один крайний случай — и команда тихо возвращает всё обратно. Кажется неважно по отдельности, но вместе они воссоздают раздутый релиз, который уже сорвался.
Скрытая работа — следующая проблема. Если решения живут в чате, приватных заметках или боковых звонках, никто не видит настоящий план. Инженеры начинают делать разные версии одной и той же фичи, тесты пропускают последние изменения, а продукт думает, что команда согласовала вещи, которых нет в бэклоге.
Перезагрузка также проваливается, когда старшие люди игнорируют новые правила. Если все должны резать объём, логгировать компромиссы и получать одобрение, то это должно касаться и самого опытного участника. Как только один лидер может перепрыгнуть очередь, процесс перестаёт быть процессом.
Переработки — ещё одно плохое решение. Они могут скрыть слабые решения на неделю‑две, но не убирают путаницу. Если команда не знает, какой путь пользователя главное поддерживать, длинные часы просто рождают больше недоделок и багов.
Типичный сценарий: команда вырезает пару фич и оставляет один срез релиза, заинтересованный стейкхолдер просит «маленькое» добавление и никто не говорит нет, инженеру отправляют приватное сообщение и он начинает работу вне доски, затем дату релиза объявляют до того, как основной путь прошёл тесты.
Последняя ошибка бьёт сильнее всего. Давление появляется, как только дата становится публичной, даже если чек-аут, регистрация или онбординг всё ещё ломаются в базовых тестах. Выбирайте дату после того, как основной путь работает сквозь все шаги, а не до этого.
Если хотите, чтобы перезагрузка удержалась — делайте всю работу видимой, применяйте правила ко всем и рассматривайте новые запросы как обмены, а не добавления. При поступлении нового пункта — что‑то другое уходит.
Быстрая проверка перед выбором новой даты
Новая дата должна появиться после ясности, а не после надежды. Если команда не может ответить на несколько простых вопросов на одной встрече — дата всё ещё догадка.
Начните с одного предложения, которое объясняет, что выйдет. Оно должно быть достаточно конкретным, чтобы саппорт, продажи, инженерия и руководство слышали одно и то же. Если каждая группа пересказывает план по‑разному, у вас ещё нет плана релиза.
Затем посмотрите на список задач без приукрашивания. У каждой оставшейся задачи должен быть владелец и срок. Совместное владение звучит вежливо, но скрывает задержки.
Объём тоже должен быть видимым, а не подразумеваемым. Проблема возникает, когда обсуждают новую дату, но никогда не пишут, что убрали из объёма. Запишите, что ушло, что осталось и что ждёт после релиза.
Риск зависимостей — там, где даты обычно рушатся. Проверьте, может ли одна заблокированная задача остановить весь релиз. Если да — либо разрушьте эту зависимость, либо выпустите без неё, либо сделайте временный обход. Дата, привязанная к одному хрупкому шагу, не является реальным обязательством.
У самого рискованного шага должен быть запасной вариант: ручной процесс, feature flag, постепенный релиз или уменьшенная версия фичи. Команды часто пропускают это как дополнительные усилия, но обычно это спасает релиз.
Краткий обзор должен подтвердить пять вещей:
- Релиз укладывается в одно чёткое предложение.
- У каждой задачи есть владелец.
- У каждой задачи есть срок.
- Все знают, что ушло из объёма.
- У самого рискованного шага есть запасной план.
Эта проверка часто полезнее ещё одной статусной встречи, потому что заставляет команду проверить, выживет ли план при обычных проблемах, а не при идеальных условиях.
Если вы всё ещё слышите фразы вроде «вроде бы всё ок» или «зависит от последней штуки», не выбирайте дату. Сначала исправьте план.
Следующие шаги после перезагрузки
Перезагрузка работает только если команда поддерживает её после первой спокойной недели. Здесь многие команды снова возвращаются к старым привычкам.
Держите короткий обзор объёма в календаре каждую неделю до релиза. Пятнадцати минут достаточно, если группа остаётся строгой. Проверьте, что вышло, что сдвинулось и что вы готовы сейчас вычеркнуть вместо долгих споров позже.
Запишите правила принятия решений и сохраните их для следующего релиза. Поместите их в одно место, которое все используют. Если команда дважды спорит о том же компромиссе, правило либо отсутствует, либо слишком расплывчато.
Несколько правил хорошо работают со временем:
- Ни одна новая фича не попадает в релиз без назначенного владельца.
- Любая зависимость без срока вырезается или заменяется.
- Блокеры важнее полировки.
- Если одна задача создаёт работу для трёх команд, разбейте её или уберите.
Повторяющиеся блокеры заслуживают больше внимания, чем единичная опоздавшая задача. Если согласования всегда тормозят — исправьте процесс согласований. Если передачи постоянно ломаются — поменяйте способ передачи. Если одна общая служба замедляет каждый релиз — перестаньте списывать это на неудачу и назначьте человека, который уберёт этот узкий горлышко.
Отслеживайте паттерны, а не драму. Небольшая заметка каждую неделю — что блокировало прогресс, как часто это происходило и кто владеет исправлением. Через месяц одни и те же имена и шаги обычно повторяются. Это показывает, где система слаба.
Внешняя помощь полезна, когда команда слишком погружена в проблему. Основатели часто тянут объём назад, инженеры защищают уже начатую работу. Нейтральный обзор может прорезать оба этих сопротивления. Oleg Sotnikov at oleg.is работает как фракционный CTO и может просмотреть объём, зависимости и правила доставки с практическим акцентом.
Если новая дата всё ещё держится на переработках — перезагрузка не закончена. Если она основана на меньшем объёме, чистых зависимостях и правилах, которым люди действительно следуют, у команды есть реальный шанс.
Часто задаваемые вопросы
Что нужно сделать в первую очередь после срыва релиза?
Остановите суматоху на пару дней. Заморозьте новые запросы на фичи, запишите одно чёткое предложение о релизе и назовите одного человека, который отвечает за объём. Это даёт команде одну цель вместо десяти полусуточных целей.
Как решать, что остаётся в объёме?
Оставьте только работу, которая позволяет пользователю завершить основную задачу, и ту, которая предотвращает отказ на этом пути. Полировку, редкие настройки и приятные мелочи перенесите в следующий релиз.
Кто должен принимать решения по объёму?
Окончательное решение по объёму должен принимать один человек. Чаще всего это продуктовый лидер, основатель или CTO. Если несколько людей могут добавлять работу, объём растёт в приватных разговорах и план снова рушится.
Стоит ли сохранять старую дату релиза?
Как правило — нет. Новую дату выбирайте только после того, как основной пользовательский путь полностью работает, на каждую оставшуюся задачу есть владелец, и у самой большой зависимости есть запасной план. Пока этого нет — дата остаётся предположением.
Как обращаться с зависимостями для релиза?
Соберите все блокеры на одной странице: согласования, действия поставщиков, недостающие данные и доступы. Исправьте блокер, который замораживает больше всего работы, назначьте ему владельца и срок, и используйте ручной обходной путь, если это помогает.
Подходит ли ручной обходной путь для первого релиза?
Да, если это помогает безопасно выпустить основной путь. Ручной экспорт, ручная настройка аккаунтов или проверка записей вручную дают время для полноценного автоматического решения, если поддержка и операции могут с этим справиться.
Какие правила помогают команде восстановиться после срыва?
Задайте несколько простых правил и соблюдайте их ежедневно. Только один назначенный человек может утверждать изменения объёма, у каждого человека должно быть немного активной работы, на вопросы по блокерам отвечают в течение рабочего дня, и команда поднимает риск после второго пропуска, а не после недели надежд.
Стоит ли использовать переработки, чтобы наверстать упущенное?
Переработки редко решают корень проблемы. Если команда всё ещё спорит о объёме или ждёт ответов по блокерам, больше часов лишь породят недоделанную работу и баги. Сначала сократите объём и разберите зависимости.
Что должно происходить в первую неделю перезагрузки?
Держите неделю спокойной и узкой. Заблокируйте на день самую маленькую версию, которая может уйти в прод, уберите главный блокер, завершите основной путь, тестируйте на реальных аккаунтах и данных, и исправляйте только то, что мешает релизу.
Когда стоит просить внешней помощи?
Подключайте внешнюю помощь, когда команда не может договориться по объёму, лидеры продолжают добавлять работу, или новая дата всё ещё держится на надежде. Нейтральный обзор CTO может срезать лишнее, выявить слабые зависимости и дать рабочие правила.