План на случай сбоя почтового провайдера для транзакционных продуктов
План на случай сбоя почтового провайдера помогает сохранить работу сбросов паролей, чеков и входа через очереди, резервную отправку, статус в приложении и простые проверки.
Содержание
Что идёт не так, когда почта затухает
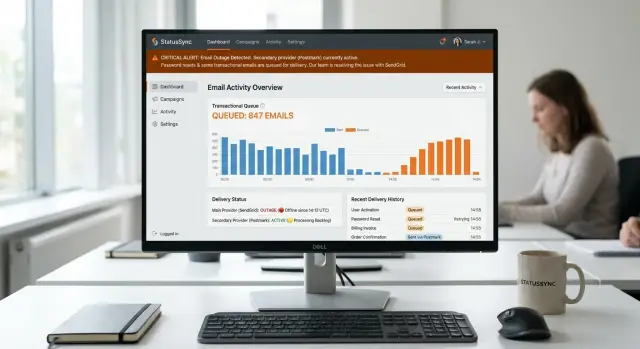
Большинство команд замечают проблему, когда перестают работать сбросы паролей. Пользователь нажимает «забыли пароль», ждёт, пробует снова и решает, что приложение сломано. Им всё равно, где именно ошибка — у вашего почтового провайдера, в DNS или в обработчике шаблонов. Они просто хотят войти обратно.
Дальше обычно ломаются магические ссылки и одноразовые коды, и это происходит в самый неподходящий момент. Новый клиент пытается войти перед демонстрацией. Коллега приглашает клиента в общий рабочий простор. Письма не приходят — и процесс останавливается на полпути. Конверсии падают ещё до того, как команда получает явное оповещение.
Симптомы редко указывают на одну причину. В понедельник утром один пользователь не может сбросить пароль. Через десять минут у торгового представителя не уходит приглашение. К обеду служба поддержки получает пять тикетов, которые по-разному описывают один и тот же сбой. Один пишет, что вход не работает. Другой — что система приглашений сломана. Третий — что письма исчезают.
Молчание усугубляет ситуацию. Если приложение пишет «письмо отправлено», а ничего не выходит из системы, пользователи продолжают повторять действия. Это создаёт дубли запросов, нагружает очередь и заполняет поддержку сообщениями «я не могу войти». Задержка почты начинает выглядеть как баг аутентификации.
Шаблон беспорядочный, но знакомый. Пользователи думают, что пароль перестал работать. Новые аккаунты не завершают настройку. Приглашения истекают прежде, чем их откроют. Поддержка присылает письма вручную и добавляет ещё больше шума.
Такая путаница тратит время. Инженеры проверяют код логина, хотя реальная ошибка вне приложения. Поддержка просит проверить спам, даже если сообщение вообще не дошло. Каждый отложенный сброс, приглашение или письмо с верификацией подрывает доверие.
Если вход, онбординг или восстановление зависят от почты, то почта — часть доступности продукта. Это не побочная система.
Решите, какие сообщения важнее
Когда почта замедляется или останавливается, не все сообщения должны бороться за одно и то же место в очереди. Одни письма удерживают людей в продукте; другие могут подождать часы без серьёзного ущерба. Разберите их заранее.
Начните с доступа к аккаунту. Сбросы паролей должны быть в приоритете, потому что пользователи запрашивают их, когда уже заблокированы. Ссылки для входа и одноразовые коды — в той же группе. Эти сообщения быстро устаревают, и позднее письмо по сути равно отсутствию письма.
Приглашения в аккаунт тоже заслуживают высокого приоритета, особенно в продуктах, где один человек приглашает коллег в общий рабочий пространство. Если приглашение приходит слишком поздно, настройка тормозит. Новый пользователь просит ещё одно приглашение, что создаёт больше почты и путаницы.
Простой порядок работает хорошо:
- Приоритет 1: сбросы паролей, магические ссылки, одноразовые коды, приглашения в аккаунт
- Приоритет 2: подтверждения заказов, чеки, оповещения о платеже, уведомления о безопасности
- Приоритет 3: обновления продукта, дайджесты, рассылки, промо
Чеки и подтверждения заказов должны уходить вскоре после писем, связанных с доступом. Люди ожидают подтверждение оплаты или заказа. Задержка тут создаёт тикеты в поддержку, тревогу о спорных операциях и иногда дублированные покупки, когда пользователь думает, что первая попытка не сработала.
Почта низкого приоритета должна ждать восстановления сервиса. Промо-кампании, последовательности nurture и не срочные обновления продукта не заслуживают пропускной способности во время сбоя. Отправлять промо, когда застряли сбросы паролей, выглядит небрежно.
Сопоставьте приоритеты с тем, как долго каждое сообщение остаётся полезным. Ссылка для сброса может истечь через 15 минут. Чек всё ещё полезен через час. Недельная рассылка может подождать до завтра.
Если эти правила задать заранее, команде не придётся спорить прямо в инциденте. Система отправит то, что нужно пользователям, а всё остальное подождёт.
Ставьте в очередь каждое сообщение
Многие планы на случай сбоя почты проваливаются в одной точке: приложение пытается отправить письмо прямо в ходе пользовательского запроса. Если провайдер медлит или упал, весь поток тормозит вместе с ним. Сбросы паролей, чеки и письма при регистрации могут застрять одновременно.
Очередь решает эту проблему. Когда приложению нужно отправить сообщение, оно сначала пишет задачу в очередь или таблицу базы данных, а затем сразу возвращает управление пользователю. Фоновый обработчик отправит письмо чуть позже.
Это небольшое изменение сохраняет отзывчивость приложения. Клиент может отправить форму сброса пароля и увидеть подтверждение за секунду, даже если почтовый провайдер начинает таймаутиться в фоне.
Что должна хранить очередь
Держите в одном месте детали сообщения и состояние доставки. Это делает повторы безопаснее и даёт поддержку одну запись для проверки при проблеме.
Обычно в задаче очереди нужно пять вещей:
- адрес получателя
- шаблон или тип сообщения
- данные, необходимые для рендеринга сообщения
- текущий статус: queued, sent, failed или delayed
- счётчик попыток и последний текст ошибки
Храните достаточно деталей, чтобы отправить точно то же сообщение, не заставляя приложение собирать его заново. Если вы поменяете шаблон позже, старые задачи в очереди должны соответствовать тому, что вызвал пользователь в момент запроса.
Очередь также даёт безопасное хранилище, когда провайдер начинает падать. Вместо того чтобы терять письма или блокировать действия пользователей, вы можете приостановить отправку, пометить задачи как отложенные и держать их готовыми к повторной отправке.
Простое правило помогает: пользовательское действие создаёт запись сообщения, а воркеры отправляют её. Держите эти задачи вне пользовательского запроса.
Прямая отправка кажется проще сначала. Но она остаётся простой ровно до первого сбоя. После этого очередь перестаёт быть лишней сантехникой и становится тем элементом, который сохранил спокойствие приложения в день, когда провайдер сломался.
Повторная отправка через второго поставщика
Второй поставщик помогает только если приложение быстро переключается и хранит одну чистую запись для каждого письма. Если основной сервис начинает таймаутиться или возвращать временные ошибки, подождите немного, а затем переместите сообщение к резервному, прежде чем запрос на сброс пароля станет устаревшим.
Держите окно первой повторной попытки коротким. Для транзакционной почты долгий таймаут ощущается как сбой. Частая схема — повторить у первого провайдера одну-две попытки за 30–90 секунд для временных проблем: таймаутов, ограничений по частоте или ошибок сервера. Если паттерн повторяется, отправьте следующую попытку через резервного.
Не переключайтесь из-за одной странной ошибки. У провайдеров бывают короткие глюки. Меняйте канал, когда видите кластер признаков, например:
- повторяющиеся 4xx-ошибки или таймауты в коротком окне
- резкий рост повторяемых ошибок для одного типа сообщений
- принятые API-вызовы без последующих событий доставки
- внутренние проверки, показывающие, что провайдер медленный или недоступен
Отслеживайте одну запись доставки от начала и до конца. Дайте каждому письму внутренний ID сообщения и прикрепляйте к этой записи все попытки у провайдеров. Храните статус, временные метки, ответы провайдеров и финальный результат вместе.
Эта запись предотвращает двойную отправку. Прежде чем резервный поставщик что-то отправит, воркер должен проверить, не доставил ли сообщение первый провайдер или не завершил ли пользователь действие. Это особенно важно для сбросов паролей, магических ссылок и одноразовых кодов: два валидных письма быстро путают людей.
Представьте запрос на сброс в 9:02. Первый провайдер дважды таймаутится в течение 45 секунд. Очередь помечает основной путь как нездоровый, отправляет ту же задачу второму провайдеру и фиксирует, что резервный отвечает за текущую попытку. Если позже придёт отложенный webhook от первого провайдера, система увидит общий ID и проигнорирует его.
И не спешите возвращать трафик на первого поставщика. Держите переключение, пока проверки не покажут стабильность в течение некоторого времени, затем возвращайте поток постепенно. Многие команды этого не делают и превращают короткий сбой в шумный час.
Показывайте пользователям, что происходит
Тихий сбой раздражает людей больше, чем медленный. Если письмо для сброса не приходит, пользователи начинают гадать. Они пробуют снова, меняют почтовый ящик или думают, что вход сломан.
Покажите проблему там, где это важно: на экране входа, форме сброса пароля и на страницах, где просят пользователя подтвердить действие по почте. Достаточно небольшой баннер. Сообщите, что почта задерживается, что запрос принят и сколько примерно придётся ждать.
Держите текст простой. «Письма для сброса пароля сейчас задерживаются. Новые запросы могут приходить до 10 минут.» Это лучше, чем расплывчатая ошибка или бесконечный спиннер. Если задержка затрагивает только часть писем, скажите и об этом.
После запроса сброса показывайте актуальный статус на странице подтверждения и давайте реальные следующие шаги. Скажите, когда проверить спам, сколько ждать и через какое время можно повторить отправку. Люди спокойнее, когда продукт даёт им таймлайн.
Кнопка повтора помогает, но только если вы контролируете её. Добавьте короткую задержку, например 60 секунд, и покажите обратный отсчёт. Без паузы напряжённые пользователи будут давить кнопку, создавать дубли и усложнять работу очереди. Если система уже переключилась на резервного провайдера, скажите об этом простыми словами, а не притворяйтесь, что ничего не изменилось.
Поддержке нужна такая же видимость. Когда пользователь открывает чат или отправляет тикет, агент должен видеть, здорова ли почта, задерживается ли она или используется другой провайдер. Ему также нужны данные о последней попытке отправки и времени следующей попытки. Тогда он сможет ответить чётко, а не просить пользователя «повторить попытку» пять раз.
Хороший статус выполняет четыре вещи: подтверждает, что запрос принят, объясняет задержку простыми словами, показывает, когда доступен повтора, и даёт поддержке те же факты, что и пользователю.
Этот тонкий слой видимости сильно сокращает повторные обращения при сбоях со сбросом пароля.
Простой поток при сбое от начала до конца
Надёжный поток при сбое кажется пользователю скучным — и именно этого вы хотите. В 8:05 кто-то нажимает «Забыли пароль» и ожидает помощи сразу. Ваше приложение должно принять запрос, создать токен сброса и записать задачу на отправку письма в очередь мгновенно.
Эта запись в очередь важнее первой попытки отправки. Если сообщение сохранено в очереди, приложение может продолжать работу, даже когда первый провайдер тормозит или перестаёт отвечать. Пользователь получает ответ от вашего приложения, а не тишину.
Простой таймлайн выглядит так:
- 8:05 — пользователь запрашивает сброс пароля; приложение сохраняет токен и задачу в очереди.
- 8:05:03 — приложение показывает короткую заметку вроде «Мы отправляем письмо для сброса сейчас.»
- 8:05:08 — первый провайдер таймаутится; воркер помечает попытку как неудачную.
- 8:05:09 — воркер отправляет ту же задачу резервному провайдеру, и тот принимает её.
- 8:05:15 — пользователь получает письмо и сбрасывает пароль без повторных действий.
Заметка в приложении легко упускается при планировании, но она экономит кучу боли службы поддержки. Без неё люди продолжают нажимать снова, запрашивают по три письма или думают, что продукт сломался.
Если резервный поставщик отправил письмо, приложение может тихо обновить заметку на «Письмо отправлено. Оно может прийти через минуту.» Если оба провайдера не справляются — скажите об этом. Сообщите, что вы всё ещё пытаетесь, или попросите повторить через несколько минут. Чёткие слова выигрывают у спиннера всегда.
Ещё одна деталь сохраняет чистоту: используйте один ID задачи для всей попытки. Это помогает безопасно повторять отправки и снижает шанс дублирующих писем, если первый провайдер ответит с опозданием.
Принимайте запрос, ставьте его в очередь быстро, переключайтесь при необходимости и держите пользователя в курсе, пока система делает свою работу.
Ошибки команд под давлением
Давление подталкивает команды к самому быстрому исправлению — и это часто создаёт второй сбой. Во время инцидента продукт всё ещё принимает действия пользователей. Сбросы паролей, магические ссылки, чеки и оповещения продолжают накапливаться.
Первая ошибка — отправлять письмо прямо из пользовательского запроса. Это выглядит просто, но превращает медленного провайдера в «сломанный экран». Пользователь запрашивает сброс, приложение ждёт ответа провайдера, пользователь нажимает снова, потому что кажется, что ничего не происходит. В итоге — дубли, запутанные пользователи и тикеты.
Более безопасный шаблон прост: сохраните запрос, поместите сообщение в очередь и сразу покажите пользователю понятный статус. Пусть фоновые воркеры занимаются доставкой, не блокируя поток сброса.
Ещё одна распространённая ошибка — слишком быстрые повторы. Видя ошибки, команды часто уменьшают задержки между повторами до нескольких секунд и бьют по тому же провайдеру снова и снова. Это увеличивает нагрузку на уже падающий сервис, приводит к лимитам и заполняет логи шумом.
Более спокойный подход работает лучше:
- распределяйте повторы с экспоненциальным бэкоффом
- останавливайте попытки после фиксированного числа попыток
- переключайтесь на другого поставщика только по понятным правилам отказа
- записывайте каждую попытку под одним и тем же ID сообщения
Второй поставщик приносит свою ловушку. Команды добавляют failover, но забывают о дедупликации. Тогда оба провайдера доставляют одно и то же письмо, или старый повтор доходит после того, как резерв уже сработал. Пользователи нажимают не ту ссылку, поддержка втягивается, и доверие падает. У каждого сообщения должен быть один стабильный ID, одна запись доставки и правила, помечающие поздние попытки как дубликаты.
Молчание усугубляет сбой
Некоторые команды скрывают проблему, чтобы не пугать пользователей. Это возвращается бумерангом. Если приложение молчит, люди продолжают нажимать кнопку сброса, просить коды и думать, что сайт сломан.
Говорите, что происходит простыми словами. Скажите, что письмо может прийти через пару минут, покажите, есть ли уже ожидающий запрос, и не позволяйте повторным кликам создавать новые отправки. Немного честности сокращает шум и даёт команде пространство, чтобы починить реальную проблему.
Протестируйте до запуска
План на бумаге мало что стоит. Прежде чем полагаться на него, намеренно вырубите основной почтовый провайдер в тестовой среде и посмотрите, как поведёт себя продукт.
Одна такая репетиция даёт больше, чем неделя обсуждений. Вы увидите, сохраняет ли очередь новые сообщения, вовремя ли стартуют повторы, и можно ли всё ещё проходить важные потоки: вход, подтверждение регистрации и сброс пароля.
Тестируйте отказ, а не только «счастливый путь"
Выключите основной провайдер полностью в одном тестовом прогоне. Не имитируйте лёгкую задержку, если реальный риск — жёсткий простой.
Отслеживайте каждый шаг по порядку. Приложение должно принять запрос, поместить сообщение в очередь, попытаться у основного провайдера, корректно провалиться и затем по правилам перейти на резерв. Логируйте каждый шаг с меткой времени, чтобы команда могла проследить одно сообщение от запроса до доставки.
Проверьте и пользовательскую сторону. На нужных экранах должен отображаться простой статус, когда почта задерживается. Человек, запросивший сброс пароля, не должен сидеть в неведении.
Частая проблема на этих тестах — оба провайдера отправляют одно и то же сообщение. Тестируйте это специально: используйте один запрос, отслеживайте один ID и подтвердите, что резерв отправляет только тогда, когда первый действительно провалился.
Убедитесь, что восстановление — скучное
Когда основной сервис возвращается, очередь должна сливаться плавно и ровно. Она не должна выбрасывать часы старой почты разом и не должна оставлять сообщения в бесконечном цикле повторов.
Короткий чеклист помогает:
- отключите основной провайдер и проследите одно сообщение от начала до конца
- спровоцируйте сброс пароля и подтвердите, что приложение показывает полезный статус
- убедитесь, что после перехода приходит только одно письмо
- восстановите сервис и наблюдайте, как очередь постепенно опустошается
- назначьте одного владельца инцидента, который следует ранбуку и принимает решения
Последний пункт важнее, чем команды обычно признают. Во время сбоя один человек должен владеть решениями, обновлениями статуса и ранбуком, чтобы все остальные могли чинить реальную проблему.
Следующие шаги для вашей команды
Начните со списка всех писем, которые ваша продукт отправляет в критичных ситуациях. Сбросы паролей, коды входа, чеки, предупреждения о платежах, приглашения и уведомления о безопасности не должны быть в одной корзине с рассылками и советами по продукту.
Ранжируйте их по боли пользователя и риску для бизнеса. Задайте простой вопрос: что ломается для пользователя в ближайшие 10 минут, если это письмо не уйдёт? Это даст более обоснованный приоритет, чем интуиция.
Вам также нужны читаемые состояния очереди. Если поддержка открывает запись пользователя, она должна видеть, находится ли письмо в очереди, отправлено, задерживается, повторяется через другого поставщика или окончательно провалено. Продуктовым командам нужен тот же взгляд при разборе инцидентов, иначе будут гадать вместо того, чтобы чинить.
Короткий список действий поможет начать:
- пропишите основные транзакционные почтовые потоки и расставьте их по приоритету
- добавьте читаемые статусы очереди в админку или панель поддержки
- определите, когда система переключается на резервного поставщика
- проводите ежемесячный дри́лл отключения и фиксируйте, что замедляло людей
Держите упражнение коротким. На 20 минут отключите основной провайдер в staging или другой безопасной тестовой среде и посмотрите, что происходит. Проверьте, ждут ли письма в очереди, вовремя ли стартует failover и показывает ли приложение пользователю понятный статус, а не оставляет его в тупике.
Это быстро выведет на поверхность узкие места. Поддержка может не понимать, что значит статус «в очереди». Инженеры — заметят, что повторы занимают слишком много времени. Продукт — увидит, что экран сброса ничего полезного не говорит при задержке почты.
Если команде нужен внешний взгляд, Oleg Sotnikov at oleg.is консультирует стартапы и малый бизнес по архитектуре продукта, инфраструктуре и практическому применению AI. Такой обзор помогает, когда нужен план отказа, который маленькая команда действительно сможет построить, запустить и поддерживать.
Сделайте первый проход на этой неделе, даже если он грубый. Список приоритетов, читаемые статусы и одна репетиция спасут пользователей сильнее, чем ещё один месяц благих намерений.
Часто задаваемые вопросы
Какие письма должны быть в приоритете при сбое?
Поместите в первую очередь сбросы паролей, магические ссылки, одноразовые коды и приглашения. Чеки, уведомления о платежах и сообщения о безопасности — во вторую. Рассылки, промо и дайджесты — подождут, пока сервис не вернётся в норму.
Должно ли приложение отправлять письмо в ходе пользовательского запроса?
Нет. Сначала запишите задачу в очередь или таблицу базы данных, сразу покажите пользователю статус, а отправку пусть выполняет фоновой обработчик. Это сохраняет отзывчивость входа, регистрации и оформления заказа, даже если провайдер тормозит.
Что должна хранить очередь писем?
Сохраняйте получателя, тип сообщения или шаблон, данные или отрендеренный контент, нужный для повторной точной отправки, текущий статус, счётчик попыток и последний текст ошибки. Храните все попытки в одной записи, чтобы поддержка и инженеры могли видеть полную историю.
Когда переключаться на резервного поставщика почты?
Повторите попытку у первого провайдера один или два раза в течение примерно 30–90 секунд для таймаутов, лимитов или ошибок сервера. Если ошибки продолжаются или события доставки перестали приходить, попробуйте следующий провайдер.
Как предотвратить дублирующие письма для сброса пароля?
Присвойте каждому письму внутренний ID сообщения и привязывайте все попытки у разных провайдеров к этой записи. Перед отправкой через резерв проверьте, не доставил ли первое письмо провайдер или не завершил ли пользователь действие.
Что должны видеть пользователи, когда почта задерживается?
Покажите короткую заметку на экране сброса, входа или подтверждения. Скажите, что запрос получен, почта задерживается и сколько может занять ожидание. Это сокращает повторные клики и шум в службе поддержки.
Стоит ли предлагать кнопку повтора?
Да, но с контролем. Введите короткую паузу, например 60 секунд, и покажите обратный отсчёт. Без задержки взволнованные пользователи будут много раз нажимать «Отправить повторно» и создавать дубли задач.
Что должна видеть служба поддержки во время сбоя почты?
Поддержке нужно видеть, находится ли письмо в очереди, задерживается, отправлено, повторяется через другого поставщика или окончательно провалено. Также полезны время последней попытки, последний текст ошибки и следующее время повтора, чтобы отвечать по фактам, а не просить пользователя снова попробовать.
Как протестировать план на случай сбоя перед запуском?
Выключите основной провайдер в тестовой среде и проследите один сброс пароля от запроса до доставки. Подтвердите, что приложение показывает статус, что приходит только одно письмо и что при восстановлении очередь очищается ровно.
Когда стоит возвращать трафик на основного поставщика?
Дождитесь устойчивых нормальных показателей, а не одной или двух удачных отправок. Возвращайте трафик постепенно и следите за задержками, отказами и лагом вебхуков. Резкое переключение назад может превратить короткий сбой в новый час шумных повторов.


